[논문리뷰] ZipMap: Linear-Time Stateful 3D Reconstruction via Test-Time Training
CVPR 2026. [Paper] [Page] [Github]
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, Aleksander Holynski
Google DeepMind | Cornell University | MIT
4 Mar 2026
Introduction
본 논문에서는 대규모 이미지 데이터셋 복원을 위한 효율적인 feed-forward 모델인 ZipMap을 소개한다. ZipMap은 대규모 feed-forward transformer에 대한 기존 연구의 아키텍처 원칙과 Test-Time Training 기법을 결합하여 입력 데이터셋 수에 비례하는 선형 복잡도를 갖는 양방향 모델을 구현하였다. 이를 통해 대규모 이미지 데이터셋을 단 몇 초 만에 처리할 수 있다. 기존 연구와 달리, ZipMap은 비용이 많이 드는 SOTA 시스템과 동등하거나 그 이상의 정확도를 달성하면서 이러한 효율성 향상을 이루어냈다.
본 논문의 핵심은 Test-Time Training (TTT) layer를 사용하는 것이다. 모든 토큰에 걸쳐 비용이 많이 드는 global attention을 적용하는 대신, 전체 이미지 컬렉션을 단일 forward pass에서 압축된 hidden state (MLP의 fast weight)로 압축한다. 이러한 state 집계는 매우 효율적이고 글로벌하게 일관성이 유지되므로 대규모 이미지 컬렉션으로의 확장이 가능하다. 이러한 state 기반 표현은 실시간으로 새로운 시점에서 픽셀 단위로 정렬된 geometry와 외형을 생성하는 데 사용할 수 있는 implicit한 장면 표현 역할을 하며, 순차적인 스트리밍 방식으로 재구성을 수행하도록 쉽게 확장할 수 있다.
Method
효율적인 3D foundation model은 3D 장면을 효율적으로 재구성하는 동시에 쿼리 가능하고 영구적인 표현을 구축해야 한다. 본 논문에서는 이러한 두 가지 목표를 한 번의 forward pass로 달성하는 stateful feed-forward model인 ZipMap을 제안하였다. 동영상 또는 이미지 컬렉션에서 가져온 $N$개의 입력 이미지 \(\{I_1, \ldots, I_N\}\)이 주어졌을 때, 본 모델은 다음과 같은 두 가지 목표를 동시에 달성하였다.
- 효율적인 3D 재구성: 한 번의 feed-forward pass에서 카메라 포즈 \(\{\textbf{c}_1, \ldots, \textbf{c}_N\}\), depth map \(\{D_1, \ldots, D_N\}\), 포인트 클라우드 \(\{\textbf{p}_1, \ldots, \textbf{p}_N\}\)의 linear-time 양방향 재구성을 지원한다.
- Implicit한 장면 표현: 동일한 pass에서 모델은 자동으로 가중치를 조정하여 쿼리 가능한 implicit한 장면 표현을 생성한다. 타겟 카메라 조건 \(\textbf{c}_t\)가 주어지면 실시간으로 쿼리하여 해당 새로운 시점에서 생성된 colored pointmap을 생성할 수 있다.
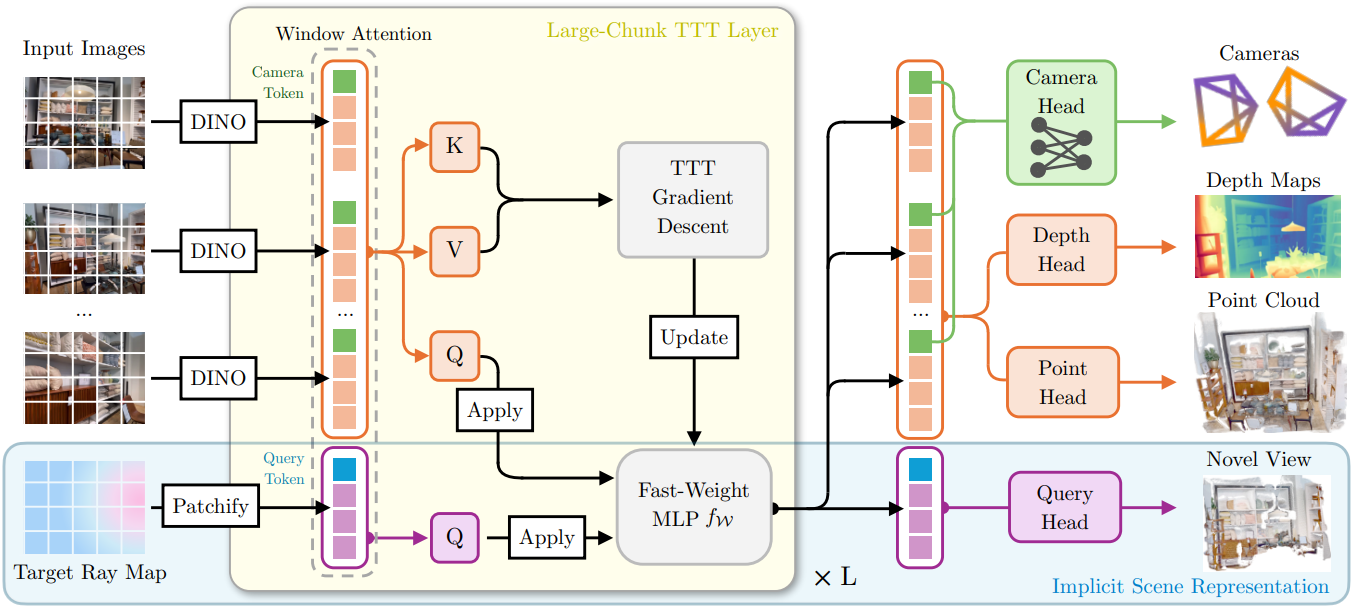
본 모델의 핵심은 효율적인 디자인이다. Feed-forward pass의 실행 시간은 입력 이미지 수에 따라 선형적으로 증가하며, VGGT나 $\pi^3$와 같은 모델이 제곱에 비례하여 증가하는 것과는 다르다. 이를 위해 global attention을 사용하는 대신, local window attention과 global large-chunk TTT block으로 구성된다. 토큰 버퍼를 지속적으로 증가시키는 표준 attention과 달리, TTT는 컨텍스트를 고정 크기의 fast weight 집합으로 압축하여 $\mathcal{O}(N)$ 양방향 재구성을 가능하게 하는 동시에 $N$에 관계없이 실시간으로 새로운 시점에서 쿼리할 수 있는 implicit한 장면 상태를 생성한다.
1. Input Tokenization
모델은 두 가지 유형의 입력을 처리할 수 있다. 하나는 장면 재구성을 위한 이미지 입력 $$\mathcal{I} = {I_1, \ldots, I_N}$$이고, 다른 하나는 모델 내에서 구성된 implicit한 표현을 조회하는 데 사용되는 타겟 ray map $T$이다.
먼저 사전 학습된 DINOv2 인코더를 사용하여 각 입력 이미지 $I_i$를 tokenize한다. 인코더는 2D feature map을 출력하며, 이를 패치 수준의 토큰 시퀀스로 flatten하여 주요 입력으로 사용한다. Ray map 입력 $T \in \mathbb{R}^{H \times W \times 9}$는 타겟 카메라의 extrinsic 및 intrinsic 파라미터로부터 계산된다. 각 픽셀은 ray 원점 \(\textbf{r}_o \in \mathbb{R}^3\), 방향 \(\textbf{r}_d \in \mathbb{R}^3\), 그리고 \(\textbf{r}_o \times \textbf{r}_d\)를 concat한 것이다. $T$를 겹치지 않는 패치들로 분할하고, 각 패치를 flatten한 후, linear layer를 사용하여 토큰 임베딩 차원으로 projection한다.
또한, VGGT와 마찬가지로 각 입력 이미지에 카메라 정보를 예측하는 데 사용될 카메라 토큰 하나와 레지스터 토큰 네 개를 할당한다. Ray map 입력의 경우, 카메라 토큰을 특수 쿼리 토큰으로 대체한다.
Tokenization 후, 이미지 토큰은 \(\{\textbf{x}_i\}_{i=1}^N\)이며, \(\textbf{x}_i \in \mathbb{R}^{p \times d}\)이고 $p = HW/P^2 + 5$이다 ($P = 14$). Ray map 토큰은 \(\{\textbf{t}_i\}_{i=1}^M\)이며, \(\textbf{t}_i \in \mathbb{R}^{p \times d}\)이다.
2. Feature Backbone
프레임별 tokenization 후, 모델의 backbone은 모든 프레임을 통합하여 글로벌 정보를 결합하고 입력 이미지의 카메라 위치 및 깊이와 같은 3D 정보를 추론한다. 본 논문에서는 모든 global attention을 large-chunk TTT layer로 대체하여 선형 비용의 backbone을 설계했다. 이 TTT layer는 모든 이미지 feature를 비선형 fast weight 함수로 압축한다. 모델의 backbone은 프레임별 local window attention과 global TTT layer를 번갈아 사용한다. 구체적으로, $L = 24$개의 block으로 구성되며, 각 block은 다음과 같은 요소로 이루어져 있다.
- Local Window Attention은 각 뷰 (이미지 또는 ray map)의 토큰에 대해 독립적으로 작동한다. Rotary positional encoding (RoPE)을 사용하는 표준 self-attention을 활용하여 각 뷰 내의 로컬 공간 관계를 포착한다.
- Global Large-Chunk TTT Layer는 모든 입력 이미지 토큰에 대해 비선형 fast weight 함수를 업데이트하여 글로벌 정보를 집계한다.
TTT block의 핵심은 SwiGLU-MLP로 구현된 컨텍스트에 맞춰 조정되는 fast weight 함수이다.
\[\begin{equation} f_\mathcal{W} (\textbf{x}) = \textbf{W}_2 \left( \textrm{SiLU}(\textbf{W}_1 \textbf{x}) \circ (\textbf{W}_3 \textbf{x}) \right) \end{equation}\]($\circ$는 element-wise multiplication, \(\mathcal{W} = \{\textbf{W}_1, \textbf{W}_2, \textbf{W}_3\}\)은 fast weight)
이러한 fast weight는 모든 입력 뷰의 토큰에 대해 한 번의 gradient descent step을 사용하여 조정되며, key-value reconstruction을 기반으로 하는 가상 TTT loss를 사용한다. 구체적으로, 각 토큰을 해당 query \(\textbf{q}_i\), key \(\textbf{k}_i\), value \(\textbf{v}_i\) 벡터 공간으로 projection한다. 모든 입력 이미지 토큰의 key-value 쌍은 가상 loss를 정의한다.
\[\begin{equation} \mathcal{L} (f_\mathcal{W} (\textbf{k}_i), \textbf{v}_i) = -f_\mathcal{W} (\textbf{k}_i)^\top \textbf{v}_i \end{equation}\]이는 fast weight 함수가 각 key 벡터와 해당 value 벡터 간의 매핑을 기억하도록 유도한다. 이 가상 loss는 3D reconstruction loss와는 무관하며, 컨텍스트 내 연관 메모리를 구축하기 위해 layer당 한 번씩 최적화된다.
이 가상 loss를 최적화하기 위해 먼저 이 loss의 fast weight gradient $\textbf{g}$를 계산한다.
\[\begin{equation} \textbf{g} = \nabla_\mathcal{W} \sum_{k=1}^{N \times p} \eta_i \mathcal{L} (f_\mathcal{W} (\textbf{k}_i), \textbf{v}_i) \end{equation}\](\(\eta_i\)는 각 토큰의 learning rate이며, 입력 토큰으로부터 간단한 linear layer로 예측됨)
Muon optimizer를 따라, gradient $\textbf{g}$에 Newton–Schulz orthonormalization을 적용하고, fast weight를 업데이트한 다음, 안정성을 유지하기 위해 L2 정규화를 수행한다.
\[\begin{aligned} \Delta &\leftarrow \textrm{NewtonSchulz} (\textbf{g}) \\ \hat{\mathcal{W}} &\leftarrow \| \mathcal{W} \| \cdot \frac{\mathcal{W} - \Delta}{\| \mathcal{W} - \Delta \|} \end{aligned}\]이렇게 업데이트된 fast weight은 장면에 대한 글로벌 정보를 인코딩한다. 그런 다음 각 토큰의 query \(\textbf{q}_i\)를 업데이트된 fast weight MLP \(f_\hat{\mathcal{W}}\)에 통과시켜 입력 이미지 토큰에 fast weight를 적용한다.
\[\begin{equation} \textbf{o}_i^\prime = f_{\hat{\mathcal{W}}} (\textbf{q}_i) \end{equation}\]업데이트된 \(f_{\hat{\mathcal{W}}}\)를 입력 query 토큰에 적용하는 것은 self-attention에서 모든 key-value 쌍을 쿼리하는 것과 유사하지만, 토큰 수에 대한 복잡도는 2차 함수가 아닌 선형 함수이다.
이러한 fast weight는 ray map $T$에서 얻은 ray map 토큰의 쿼리 \(\textbf{q}_k^t\)에 직접 적용될 수 있다. 이는 타겟 ray map 토큰을 사용하여 입력 이미지 토큰에 대해 cross-attention 하는 것과 유사한 역할을 한다. 이 연산은 타겟 ray map 토큰당 일정한 실행 시간을 가지며, fast weight를 업데이트하는 데 사용된 입력 뷰의 수와는 무관하다.
마지막으로, 가중치 \(\textbf{W}_g\)로 parameterize된 gated unit을 적용하여 최종 출력을 생성한다.
\[\begin{equation} \textbf{o}_i = \textrm{RMSNorm}(\textbf{o}_i^\prime) \cdot \textrm{SiLU} (\textbf{W}_g \textbf{o}_i^\prime) \end{equation}\]3. Streaming Reconstruction
모든 입력 뷰의 시각적 토큰을 사용하여 각 TTT layer를 한 번씩 업데이트함으로써 양방향 재구성을 수행할 수 있다. 뿐만 아니라, ZipMap은 fast weight을 온라인으로, 한 번에 하나의 뷰씩 업데이트하여 스트리밍 재구성으로도 확장할 수 있다. 이미지 스트림 \(\{I_1, I_2, \ldots\}\)에 대하여, 다음과 같이 TTT fast weight \(\mathcal{W}^{(t)}\)를 순차적으로 업데이트한다.
\[\begin{equation} \mathcal{W}^{(i)} \leftarrow \textrm{TTTUpdate} \left( \mathcal{W}^{(i-1)}; \{\textbf{k}_{t,i}, \textbf{v}_{t,i}\}_{i=1}^p \right) \end{equation}\]동일한 가상 key-value loss를 사용하지만, 현재 뷰의 시각적 토큰만을 사용하여 계산한다.
4. Prediction Heads
본 모델은 네 개의 prediction head를 가지고 있다. VGGT와 동일한 camera head 설계를 채택하여 입력 이미지의 카메라 토큰으로부터 카메라 파라미터 \(\textbf{c}_i \in \mathbb{R}^9\), 즉 4D rotation quaternion, 3D translation, 그리고 두 개의 intrinsic 파라미터를 예측한다. Point head, depth head, query head에는 DPT-style head를 사용한다.
각 입력 이미지 $i$에 대해 point head는 카메라 좌표계에서 로컬 pointmap \(P_i \in \mathbb{R}^{H \times W \times 3}\)를 예측한다. Depth head는 depth map $D_i \in \mathbb{R}^{H \times W}$와 $D_i$에 대한 신뢰도 맵 \(\Sigma_i \in \mathbb{R}^{H \times W}\)를 예측한다. Query head는 명시적인 장면 표현 없이 타겟 뷰 RGB 값 $I^t \in \mathbb{R}^{H \times W \times 3}$을 직접 예측하고, 추가적으로 타겟 depth map $D^t \in \mathbb{R}^{H \times W}$을 신뢰도 \(\Sigma^t \in \mathbb{R}^{H \times W}\)로 예측하여 geometry를 쿼리한다.
5. Model Training
Training Losses
여러 loss function의 합을 최소화하는 방식으로 모델을 학습시킨다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{point} + \mathcal{L}_\textrm{depth} + w_c \times \mathcal{L}_\textrm{cam} (+ \mathcal{L}_\textrm{color}^t + \mathcal{L}_\textrm{depth}^t) \end{equation}\]저자들은 VGGT의 구현을 따르고 $w_c$ 값을 5로 설정하였다. Query loss \(\mathcal{L}_\textrm{color}^t\)와 \(\mathcal{L}_\textrm{depth}^t\)는 fine-tuning 중에만 활성화되며, 입력값이 아닌 GT 타겟 이미지/깊이 값을 기준으로 정의된다.
Point loss
MoGe를 따라 scale-invariant local point reconstruction loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{point} = \underset{i,j}{\textrm{mean}} \left( \frac{\| \hat{s} \textbf{p}_{i,j} - \textbf{p}_{i,j}^\ast \|_1}{3 z_{i,j}^\ast} \right) \end{equation}\]\(\textbf{p}_{i,j} \in \mathbb{R}^3\)는 뷰 $i$에서 픽셀 $j$에 위치한 예측된 pixel-aligned point (로컬 카메라 좌표계 기준), \(\textbf{p}_{i,j}^\ast\)는 GT, \(z_{i,j}^\ast\)는 \(\textbf{p}_{i,j}^\ast\)의 $z$ 성분이다.
글로벌 스케일 $\hat{s}$는 다음과 같이 추정한다.
\[\begin{equation} \hat{s} = \underset{s}{\arg \min} \sum_{i,j} \frac{\| s \textbf{p}_{i,j} - \textbf{p}_{i,j}^\ast \|_1}{z_{i,j}^\ast} \end{equation}\]$\hat{s}$에 대한 최적화 문제는 ROE solver를 사용하여 해결된다.
Depth loss
동일한 scale factor $\hat{s}$를 사용하여 depth loss를 다음과 같이 계산한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = \underset{i}{\textrm{mean}} ( \| \Sigma_i \circ (\hat{s} D_i - D_i^\ast) \|_1 - \alpha \log \Sigma_i ) \end{equation}\]($\alpha = 0.2$)
Camera loss
먼저 첫 번째 이미지를 레퍼런스 뷰로 사용하여 카메라 파라미터에 대한 L1 loss를 적용하여 학습을 진행한다.
\[\begin{equation} \mathcal{L}_\textrm{cam} = \frac{1}{N} \sum_{i=1}^N \| \textbf{c}_i^\prime - \textbf{c}_i^\ast \| \end{equation}\](\(\textbf{c}_i^\prime\)는 예측된 translation을 $\hat{s}$로 스케일링)
그런 다음 레퍼런스 뷰를 제거하고 $\pi^3$의 affine-invariant camera loss로 전환한다. 레퍼런스 뷰를 제거하는 것이 표준 벤치마크에는 제한적인 영향을 미치지만, 긴 시퀀스 입력에서는 성능을 향상시킨다.
Smooth loss
또한, pointmap에 대한 normal loss와 local smoothness를 위한 depth gradient loss를 추가로 적용한다.
\[\begin{aligned} \mathcal{L}_\textrm{point-normal} &= \underset{i,j}{\textrm{mean}} (\textrm{arccos}(\textbf{n}_{i,j} \cdot \textbf{n}_{i,j}^\ast)) \\ \mathcal{L}_\textrm{depth-grad} &= \underset{i}{\textrm{mean}} (\| \Sigma_i \circ (\nabla (\hat{s} D_i) - \nabla D_i^\ast) \|_1) \end{aligned}\]Query loss
Implicit한 장면 state를 쿼리할 수 있도록 모델을 fine-tuning하기 위해 query loss \(\mathcal{L}_\textrm{color}^t\)와 \(\mathcal{L}_\textrm{depth}^t\)를 추가로 포함시킨다. 예측된 RGB와 GT 사이에서 \(\mathcal{L}_\textrm{color}^t = 10 \times (\textrm{MSE} + \textrm{LPIPS})\)로 정의하고, \(\mathcal{L}_\textrm{depth}^t\)는 $(D^t, \Sigma^t)$와 GT 깊이에 대한 \(\mathcal{L}_\textrm{depth}\)를 이용하여 정의한다.
Experiments
1. Benchmark Evaluation
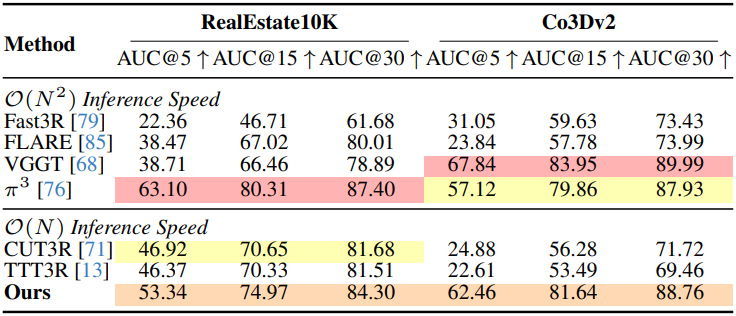
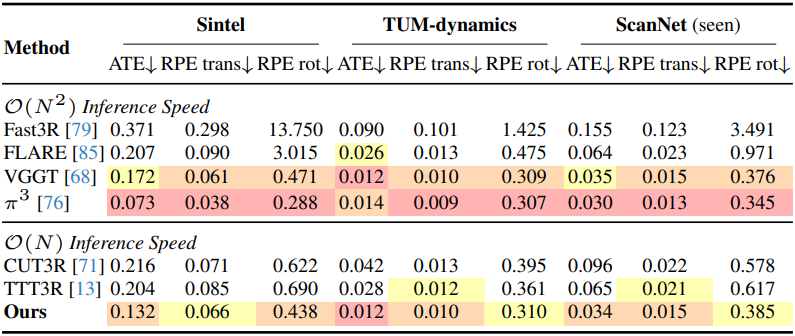
다음은 카메라 포즈에 대한 평가 결과이다.
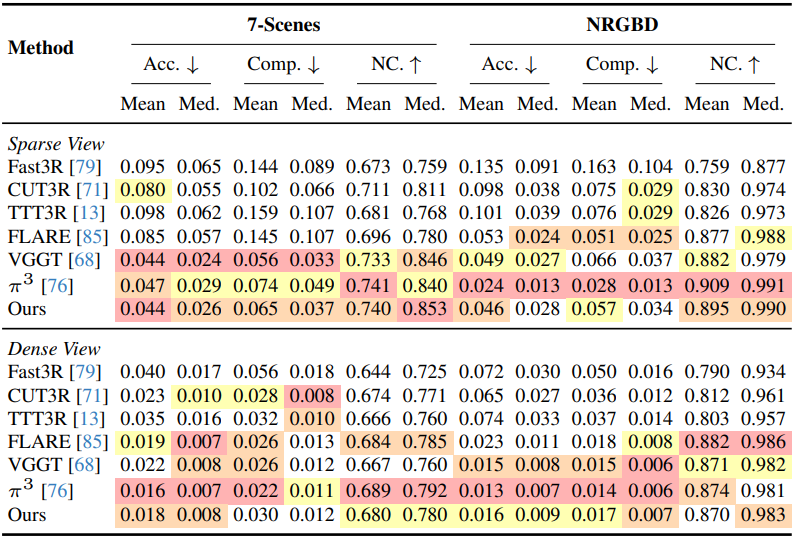
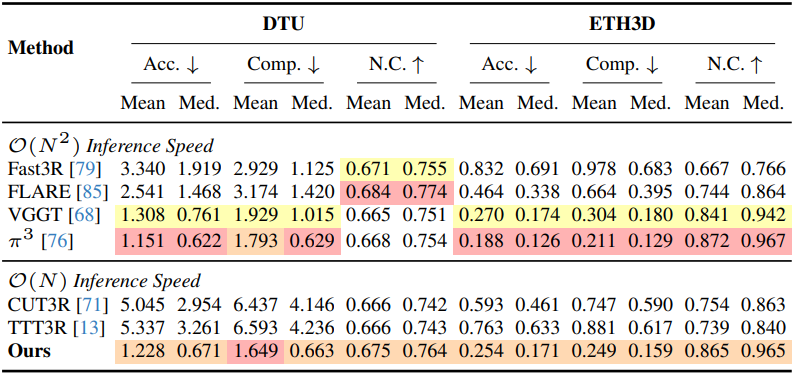
다음은 pointmap에 대한 평가 결과이다.
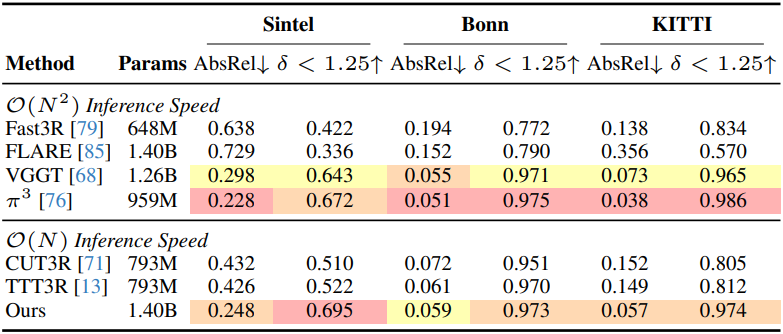
다음은 동영상 depth map에 대한 평가 결과이다.
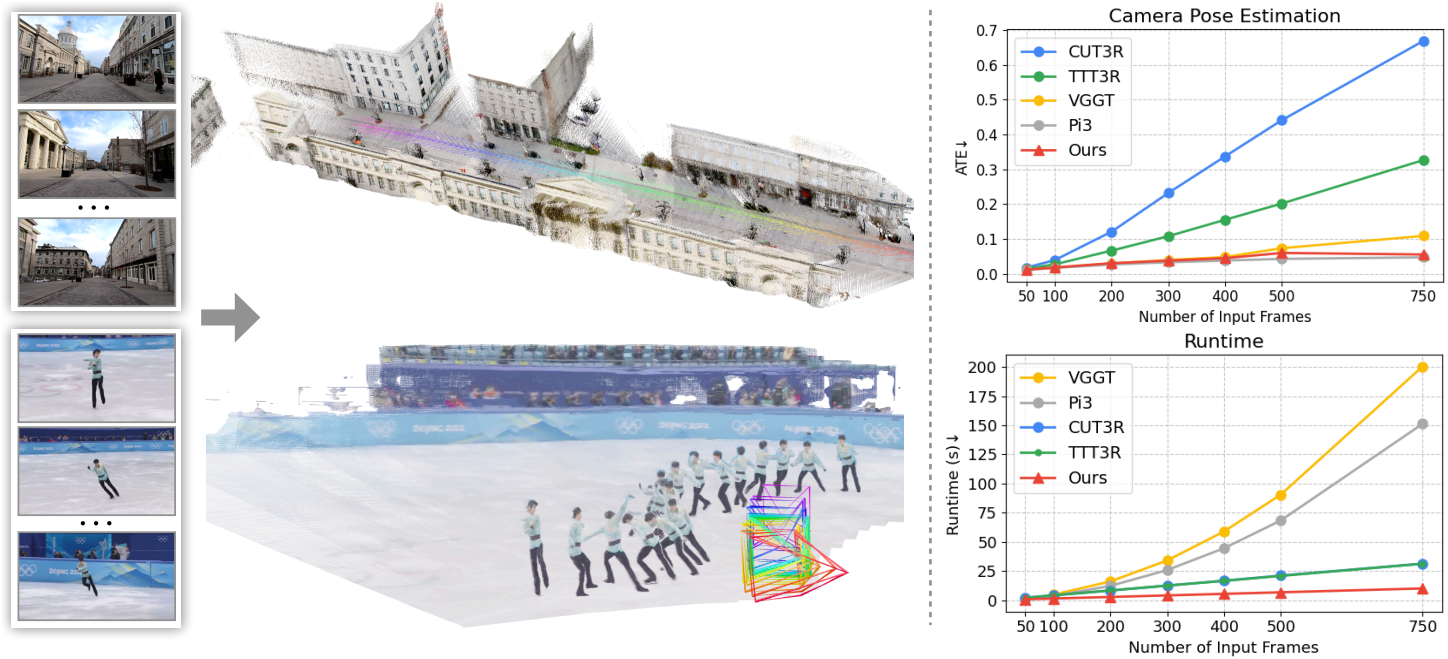
2. Efficiency and Scalability
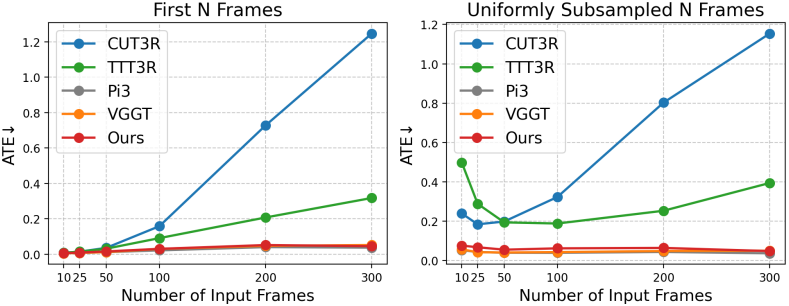
다음은 긴 시퀀스에 대한 카메라 포즈 평가 결과이다.
다음은 입력 이미지 수 $N$에 대한 inference 시간을 비교한 결과이다.

3. Ablation Studies
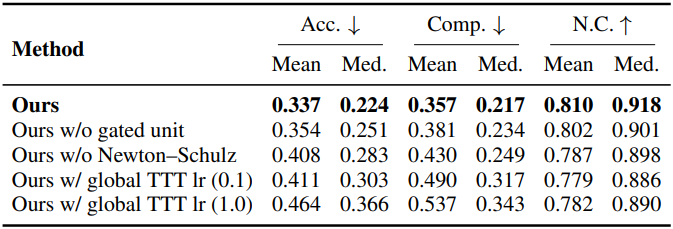
다음은 TTT에 대한 ablation study 결과이다.
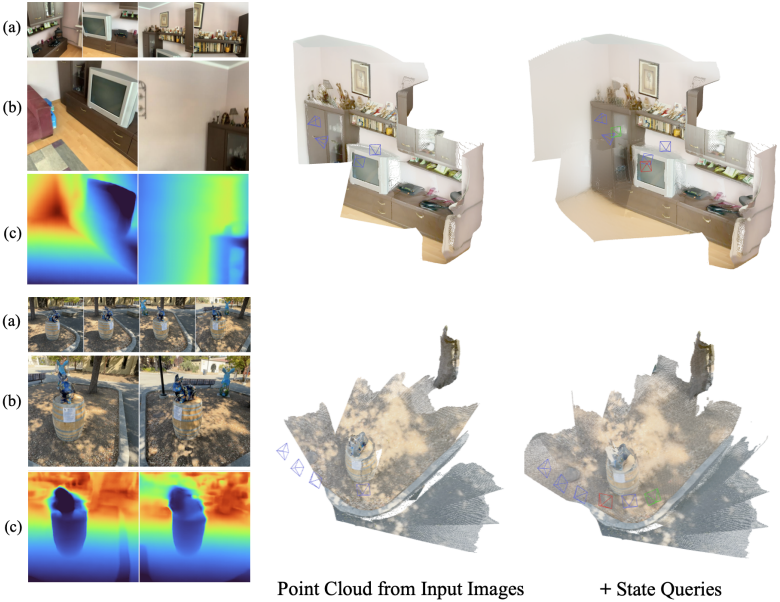
4. Implicit Scene Representation
다음은 장면 state를 쿼리하는 예시들이다.