[논문리뷰] True Self-Supervised Novel View Synthesis is Transferable
ICLR 2026. [Paper] [Page] [Github]
Thomas W. Mitchel, Hyunwoo Ryu, Vincent Sitzmann
Adobe | PlayStation | MIT CSAIL
15 Oct 2025
Introduction
본 논문에서는 멀티뷰 geometry에 의존하지 않고 Novel View Synthesis (NVS)를 순수 머신러닝 문제로 접근할 수 있는지 묻는다. 이 질문에 답하기 위해서는 먼저 멀티뷰 geometry의 용어에 의존하지 않고 NVS이 무엇인지 알아야 한다. 이를 위해 저자들은 모든 NVS 모델의 핵심 속성으로 transferability를 식별하였다. Transferability는 한 시퀀스에서 추출한 카메라 포즈 세트를 사용하여 다른 장면에서 동일한 카메라 궤적을 렌더링할 수 있는 능력이다. 따라서 유효한 카메라 포즈 표현의 핵심 요구 사항은 SE(3) 표현으로 식별될 수 있다는 것이 아니라 장면 간에 동일한 카메라 궤적을 렌더링한다는 것이다.
이러한 통찰력을 바탕으로, 본 논문은 self-supervised NVS를 순수 머신러닝 문제로 접근하였다. 기존 방법들은 transferability가 있는 카메라 포즈를 추론하지 못하고, 대신 컨텍스트 프레임을 interpolation하는 경향이 있다. 이는 사용자가 임의의 장면에서 렌더링할 시점을 정의할 수 없도록 하므로 진정한 NVS라고 할 수 없다.
본 논문에서는 진정한 NVS가 가능한 최초의 self-supervised 모델인 XFactor를 제시하였다. XFactor는 쌍별 포즈 추정과 입력 및 출력에 대한 간단한 augmentation 기법을 결합하여 카메라 포즈를 장면 콘텐츠에서 분리하고 기하학적 추론을 용이하게 한다. 이는 두 가지 핵심 통찰력에 기반한다.
- Extrapolation을 수행하도록 설계된 2-view NVS 모델을 기반으로 부트스트래핑하여 모델의 interpolation을 방지한다.
- 동일한 시퀀스에 두 개의 inverse mask를 적용하는 등 카메라 움직임을 보존하면서 픽셀 콘텐츠 중첩을 최소화하는 방식으로 프레임 시퀀스를 augmentation하여 transferability를 실제 동영상과 호환되는 학습 objective로 구체화하였다.
XFactor는 3D inductive bias나 멀티뷰 geometry의 개념 없이 제약 없는 latent pose variable를 사용하여 transferability를 달성하였다. 그런 다음 2-view XFactor 모델을 멀티뷰 모델로 fine-tuning하여 transferability가 있는 고품질 NVS를 가능하게 하였다. 프레임 시퀀스가 주어지고 그중 하나를 레퍼런스로 선택하면 인코더를 사용하여 레퍼런스와 각 프레임 사이의 포즈를 추정함으로써 latent 궤적을 생성할 수 있다. 그런 다음 다른 동영상 시퀀스를 컨텍스트로 사용하면 렌더러가 새 장면에서 동일한 카메라 궤적을 재현한다.
Method
1. Novel View Synthesis as Latent Variable Modeling
NVS의 핵심 속성을 분리하기 위해 먼저 NVS를 latent variable model로 구성한다. 정적 장면의 이미지 시퀀스 \(\mathcal{I} = \{I_1, \ldots, I_n\}\)이 주어졌을 때, 기존의 NVS 방법들은 일반적으로 이를 컨텍스트 이미지 \(\mathcal{I}_C\)와 타겟 이미지 \(\mathcal{I}_T\)의 두 개의 서로 겹치지 않는 부분집합으로 분할한다. 이러한 방법들은 일반적으로 포즈 인코더, 장면 인코더, 렌더러의 세 가지 핵심 구성 요소로 분해될 수 있다. 포즈를 표현할 기준이 되는 레퍼런스 뷰 \(I_R \in \mathcal{I}_C\)가 주어지면, 포즈 인코더는 컨텍스트 이미지와 타겟 이미지를 latent 포즈 표현 집합으로 매핑한다. 장면 인코더는 컨텍스트 이미지와 해당 latent 포즈를 latent 장면 표현으로 변환한다.
\[\begin{equation} (\mathcal{Z}_C, \mathcal{Z}_T) = \textrm{PoseEnc}[\mathcal{I}_C, \mathcal{I}_T], \quad \mathcal{S} = \textrm{SceneEnc}[\mathcal{I}_C, \mathcal{Z}_C] \end{equation}\]렌더링 디코더의 역할은 타겟 포즈와 latent 장면 표현으로부터 타겟 이미지에 대한 예측을 합성하는 것이다.
\[\begin{equation} \tilde{\mathcal{I}}_T = \textrm{Render}[\mathcal{S}, \mathcal{Z}_T] \end{equation}\]그리고 이 모델은 autoencoding objective를 최소화하도록 학습된다.
\[\begin{equation} L = d_I (\mathcal{I}_T, \textrm{Render}[\mathcal{S}, \mathcal{Z}_T]) \end{equation}\]($d_I$는 이미지 거리 metric)
이 objective를 최소화하기 위해서는 모델이 동일한 시퀀스의 장면 및 포즈 표현을 사용하여 타겟 프레임을 렌더링할 수 있는 능력만 갖추면 된다.
이 프레임워크에서 중요한 보조 도구는 Oracle인데, 이는 단순히 프레임 시퀀스를 입력받아 SE(3)로 실제 카메라 포즈를 출력하는 알고리즘이다.
\[\begin{equation} \{g_1, \ldots, g_n\} = \textrm{Oracle} (\{I_1, \ldots, I_n\}) \in \textrm{SE}(3)^n \end{equation}\]일반적으로 Oracle로 COLMAP을 선택하지만, 본 논문에서는 robustness와 사용 편의성을 고려하여 VGGT를 선택했다.
LVSM, pixelSplat과 같은 feedforward oracle NVS 모델은 단순히 포즈 인코더와 Oracle가 같다고 정의하고 장면 인코더와 렌더러만을 학습하려고 하였다. 마찬가지로 NeRF 또는 Gaussian Splatting 기반의 단일 장면 oracle 모델은 렌더링 MLP의 가중치 또는 Gaussian 자체의 형태로 장면 표현 $\mathcal{S}^B$를 직접 최적화하려고 하였다. 이와 대조적으로, self-supervised NVS 모델인 RayZer와 RUST는 Oracle에 의존하지 않고 세 가지 모듈 모두를 end-to-end로 학습하는 것을 목표로 하였다. 그러나 앞서 설명한 NVS에 대한 기존 프레임워크는 진정한 NVS를 가능하게 하는 모델의 근본적인 속성인 transferability를 고려하지 않기 때문에 self-supervised 환경에 적합하지 않다.
2. True Novel View Synthesis is Transferable
NVS는 사용자가 제어 가능한 시점에서 장면을 렌더링하는 능력이다. 동일한 카메라 포즈가 항상 동일한 시점으로 렌더링되는 것이 중요하다. 모델이 이를 수행할 수 없다면 진정한 NVS 모델이 아니라 frame interpolator에 불과하다. 본 논문에서는 NVS를 latent variable model의 관점에서 볼 때, 제어 가능성은 transferability와 동일하며, 포즈 표현이 장면 간에 transfer된다는 속성으로 공식화될 수 있다고 제안하였다.
\(\mathcal{I}^A = \mathcal{I}_C^A \cup \mathcal{I}_T^A\)와 \(\mathcal{I}^B = \mathcal{I}_C^B \cup \mathcal{I}_T^B\)를 타겟 프레임 \(\mathcal{I}_T^A\)와 \(\mathcal{I}_T^B\)가 동일한 카메라 움직임을 공유하는 시퀀스라 하자. 즉
\[\begin{equation} \textrm{Oracle}[\mathcal{I}_T^A] = \textrm{Oracle}[\mathcal{I}_T^B] \end{equation}\]이다. 그러면 핵심 구성 요소로 이루어진 임의의 NVS 모델이 transferability를 가진 포즈 표현을 생성한다, 또는 진정한 NVS 모델이다라고 하는 것은 latent 표현과 렌더러가 다음을 만족한다는 것을 의미한다.
\[\begin{equation} \textrm{PoseEnc}[\mathcal{I}_C^A, \mathcal{I}_T^A] = (\mathcal{Z}_C^A, \mathcal{Z}_T^A), \quad \textrm{SceneEnc}[\mathcal{I}_C^B, \mathcal{Z}_C^B] = \mathcal{S}^B \\ \textrm{Render}[\mathcal{S}^B, \mathcal{Z}_T^B] \approx \mathcal{I}_T^B \end{equation}\]이 기준은 \(\mathcal{I}^A = \mathcal{I}^B\)일 때 autoencoding objective를 자동으로 만족시키며 제어 가능한 NVS의 핵심, 즉 한 장면의 카메라 궤적을 적용하여 다른 장면의 뷰를 합성하는 능력을 포착한다. 포즈 인코더가 Oracle인 기존의 feedforward 및 단일 장면 oracle NVS 모델 모두 자동으로 transferability를 가지며 (따라서 진정한 NVS가 가능), 이는 임의의 장면 표현 $\mathcal{S}^B$에 대해 다음이 성립하기 때문이다.
\[\begin{equation} \textrm{Render}[\mathcal{S}^B, \textrm{Oracle}[\mathcal{I}_T^A]] = \textrm{Render}[\mathcal{S}^B, \textrm{Oracle}[\mathcal{I}_T^B]] \approx \mathcal{I}_T^B \end{equation}\]3. Quantifying Transferability with True Pose Similarity (TPS)
저자들은 latent 포즈 표현의 transferability 정도를 정량화하기 위한 표준화된 metric인 True Pose Similarity (TPS)를 도입하였다. Oracle과 궤적 비교 metric \(d_{\textrm{SE}(3)^n}\)이 주어졌을 때 (ex. RRA, RTA, AUC), 길이가 같은 두 프레임 시퀀스 $\mathcal{I}^A$와 $\mathcal{I}^B$ 사이의 TPS를 각 시퀀스의 oracle 포즈 사이의 metric 값으로 정의한다.
\[\begin{equation} \textrm{TPS}(\mathcal{I}^A, \mathcal{I}^B) = d_{\textrm{SE}(3)^n} \left( \textrm{Oracle}[\mathcal{I}^A], \textrm{Oracle}[\mathcal{I}^B] \right) \end{equation}\]NVS 모델의 TPS를 이용한 transferability를 정량화하기 위해 임의의 두 시퀀스 \(\mathcal{I}^A = \mathcal{I}_C^A \cup \mathcal{I}_T^A\)와 \(\mathcal{I}^B = \mathcal{I}_C^B \cup \mathcal{I}_T^B\)를 고려해보자. 그런 다음 $\mathcal{I}^B$의 장면 표현 $\mathcal{S}^B$와 $\mathcal{I}^A$의 타겟 latent 포즈 \(\mathcal{Z}_T^A\)를 사용하여 두 번째 시퀀스에서 새로운 궤적을 렌더링하고, TPS를 활용하여 카메라 궤적이 일치하는지 측정한다.
\[\begin{equation} \textrm{TPS}(\mathcal{I}_T^A, \textrm{Render}[\mathcal{S}^B, \mathcal{Z}_T^A]) \end{equation}\]이 수치는 렌더링된 시점이 기하학적으로 일관성이 있는지 여부만을 측정할 뿐, 컨텍스트 시퀀스에 충실한지는 측정하지 못한다는 점에 유의해야 한다. 예를 들어, 이 metric은 \(\textrm{Render}[\mathcal{S}^B, \mathcal{Z}_T^A] \approx \mathcal{I}_T^A\)인 모델에 의해 조작될 수 있으므로, 충실도를 검증하기 위해서는 perceptual measure와 함께 사용해야 한다. 본 논문에서는 벤치마킹 목적으로만 Oracle 데이터를 사용했다.
4. Solving Two Principal Problems: Interpolation and Information Leakage
The Stereo-Monocular Model
RayZer와 RUST는 포즈 인코더와 렌더러가 여러 컨텍스트 뷰에 접근할 수 있다. 이러한 self-supervised 멀티뷰 모델을 학습시키면 latent 포즈를 사용하여 컨텍스트 뷰를 interpolation하여 타겟 뷰를 합성하는 방법을 인코딩하는 모델이 생성된다. 이러한 latent 포즈는 다른 장면으로 transfer되지 않는다. 왜냐하면 다른 장면은 다른 컨텍스트 뷰를 가지기 때문이다. 따라서 이는 사용자가 임의의 장면에서 렌더링할 뷰를 정의할 수 없도록 하므로 진정한 NVS라고 할 수 없다.
본 논문은 모델이 interpolation을 학습하는 대신 포즈에 대해 추론하도록 하기 위해, 항상 extrapolation을 사용해야 하는 stereo-monocular model을 기반으로 self-supervised 멀티뷰 NVS 모델을 부트스트래핑하는 방식을 제안하였다. 구체적으로, 컨텍스트 이미지와 타겟 이미지가 각각 하나씩만 있는 경우, 예를 들어 \(\mathcal{I} = \{I_1, I_2\}\)이고 \(\mathcal{I}_C = \{I_1\}\), \(\mathcal{I}_T = \{I_2\}\)인 경우를 고려해보자. 포즈 인코더는 2-view stereo 모델이 되고, 장면 인코더는 렌더러에 통합되며, 렌더러는 monocular 모델이 된다.
\[\begin{equation} \textrm{PoseEnc}[I_1, I_2] = Z_2, \quad \textrm{Render}[I_1, Z_2] = \tilde{I}_2 \end{equation}\]렌더러에 재구성을 위한 하나의 이미지만 제공함으로써 interpolation 경로를 제거하고 transferability를 가진 포즈 표현 학습에 최적화를 집중할 수 있다.
The Transferability Objective
Stereo-monocular model은 여전히 포즈 인코더가 상대적 포즈에 대한 순수한 기하학적 설명이 아닌 타겟 픽셀에 대한 정보를 인코딩할 수 있도록 허용한다. 렌더러는 완전한 NVS를 수행할 필요 없이 타겟 latent 포즈 정보에 숨겨진 픽셀 정보를 디코딩하여 편법을 사용할 수 있다.
본 논문에서는 픽셀 정보의 얽힘을 방지하기 위해 학습 objective를 transferability로 명시적으로 정의한다. 즉, 동일한 상대적 카메라 포즈를 공유하는 것으로 알려진 두 프레임 쌍 \(\mathcal{I}^A = \{I_1^A, I_2^A\}\)와 \(\mathcal{I}^B = \{I_1^B, I_2^B\}\)가 주어졌을 때, 첫 번째 시퀀스에서 추출된 상대적 포즈 정보가 두 번째 시퀀스의 타겟 이미지를 렌더링할 수 있어야 한다는 것이다.
\[\begin{equation} L = d_I (I_2^B, \textrm{Render}[I_1^B, \textrm{PoseEnc}[I_1^A, I_2^A]]) \end{equation}\]이를 transferability objective라고 부른다. 하지만 실제 데이터를 사용하여 학습시킬 때 이러한 쌍을 실제로 어떻게 얻을 수 있는지는 불분명하다.
이를 위해 저자들은 임의의 프레임 시퀀스 $\mathcal{I}$가 주어졌을 때, GT 카메라 포즈를 보존하는 두 개의 프레임별 augmentation을 사용하여, 동일한 카메라 움직임을 공유하지만 픽셀 정보는 매우 적은 두 개의 새로운 시퀀스를 생성하였다.
\[\begin{equation} \textrm{Oracle}[\textrm{Aug A} [\mathcal{I}]] = \textrm{Oracle}[\textrm{Aug B} [\mathcal{I}]] = \textrm{Oracle}[\mathcal{I}] \end{equation}\]이를 transferability objective와 결합하면 새로운 학습 절차가 생성된다. 실제로는 입력 쌍이 주어지면 전체 이미지를 덮는 두 개의 동일 영역 마스크를 무작위로 생성하고 이를 color jitter 및 blur와 결합하여 새로운 쌍을 생성한다. 그런 다음 transferability objective에 따라 포즈 인코더는 첫 번째 쌍에서 상대적 포즈 정보를 추출하고, 렌더러는 첫 번째 이미지를 컨텍스트로 사용하여 두 번째 쌍의 타겟 이미지를 렌더링한다.
5. XFactor: A Model for True Self-Supervised Novel View Synthesis
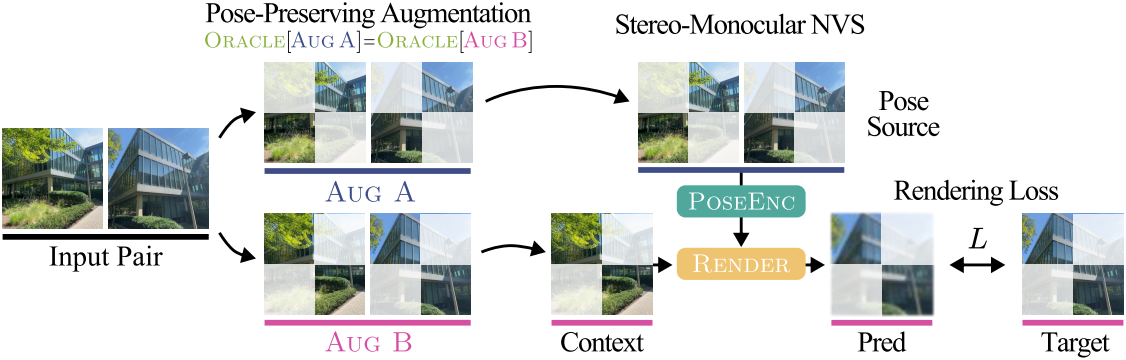
Stereo-monocular model과 transferability objective를 결합하면 XFactor가 생성된다. XFactor는 완전히 transferability가 있는 latent 포즈를 생성하며, 진정한 NVS를 달성하는 최초의 fully self-supervised 모델이다. 또한 XFactor는 어떠한 기하학적 또는 3D inductive bias 없이 이를 달성하며, 이는 그러한 설계 선택이 transferability가 있는 latent 포즈를 위한 필수 조건이 아님을 보여준다.
포즈 인코더와 렌더러는 모두 멀티뷰 VIT로 구현되었다. 이미지 거리 metric $d_I$는 GT 이미지 픽셀과 예측된 타겟 이미지 픽셀 간의 차이에 대한 L1 norm과 LPIPS loss의 선형 결합이며, LPIPS loss에는 0.5의 가중치를 부여한다. 학습 과정에서 각 batch 예제에 대해 patchify된 이미지 평면을 사분면으로 분할하고 이를 무작위로 두 그룹(각 그룹당 두 개씩)으로 나누어 augmentation mask를 생성한다. 이를 통해 이미지를 좌우 또는 상하로 균등하게 분할하는 마스크뿐만 아니라 대각선으로 분할하는 마스크도 생성할 수 있다. 또한 이미지 쌍이 마스킹되지 않을 확률이 약간 존재하며 (5%), 이 경우 해당 예제의 transferability objective는 시퀀스 내 autoencoding objective가 되어 모델이 전체 이미지를 분석할 수 있게 된다. Inference 시에는 augmentation이 적용되지 않는다.
Multi-View XFactor
저자들은 학습된 XFactor stereo-monocular model을 기반으로, 포즈 인코더와 렌더러를 fine-tuning하여 멀티뷰 모델로 확장하였다. 각 다중 프레임 시퀀스 \(\mathcal{I} = \mathcal{I}_C \cup \{I_T\}\)는 컨텍스트 이미지와 하나의 타겟 이미지로 구성된 두 개의 분리된 집합으로 나뉘며, 타겟 이미지는 랜덤하게 선택된다. 레퍼런스 이미지 \(I_R \in \mathcal{I}_C\)는 모든 포즈가 표현될 기준 시점을 나타내며, 다른 모든 프레임 중 최대 baseline이 가장 작은 프레임으로 선택된다. Augmentation 기법은 모든 프레임에 적용되지만, 기존과 동일하게 사용된다. 각 시퀀스에 대해 포즈 인코더를 쌍으로 적용하여 레퍼런스 프레임과 다른 모든 프레임 간의 상대적 포즈 latent를 예측한다. 그런 다음 렌더러를 사용하여 두 번째 시퀀스의 컨텍스트 프레임과 포즈, 그리고 첫 번째 시퀀스의 타겟 포즈를 기반으로 두 번째 시퀀스의 타겟 이미지를 렌더링한다.
Experiments
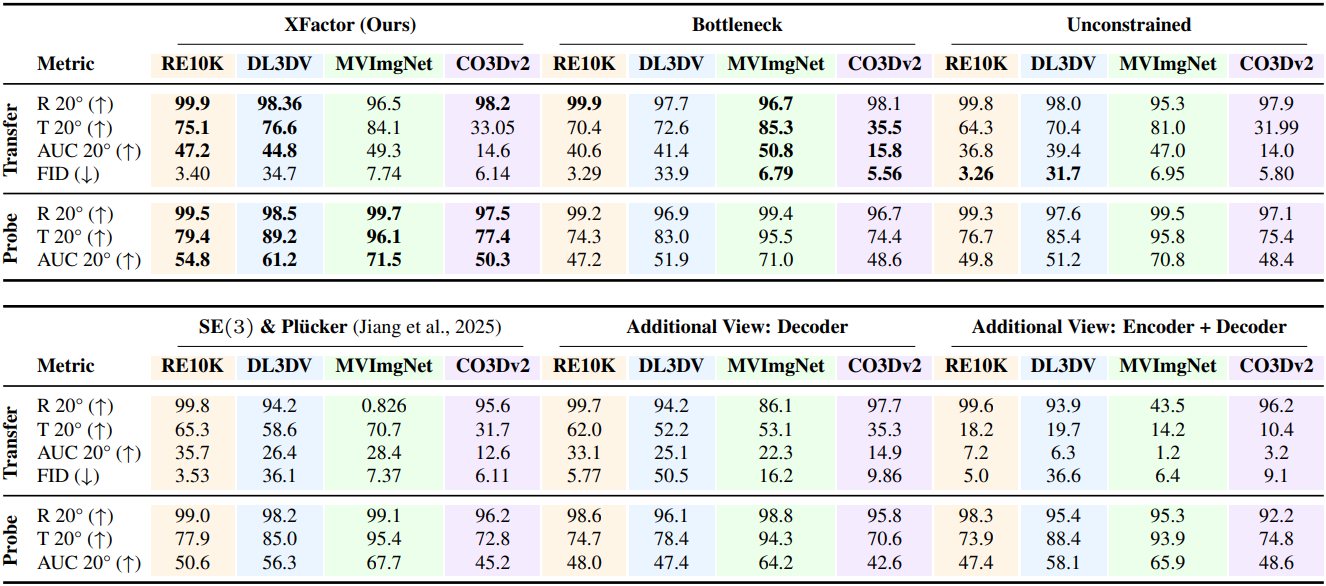
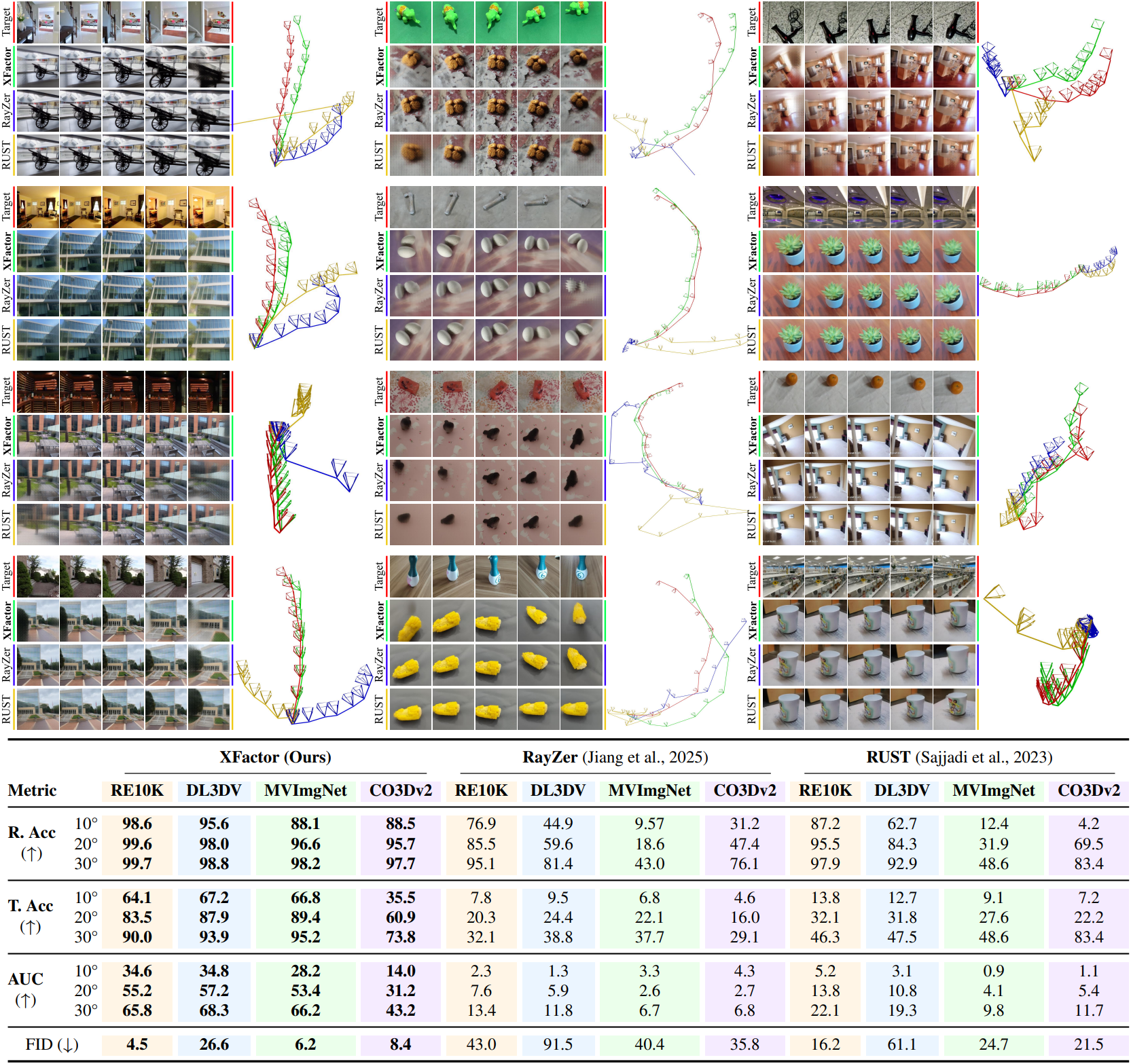
1. Transferability
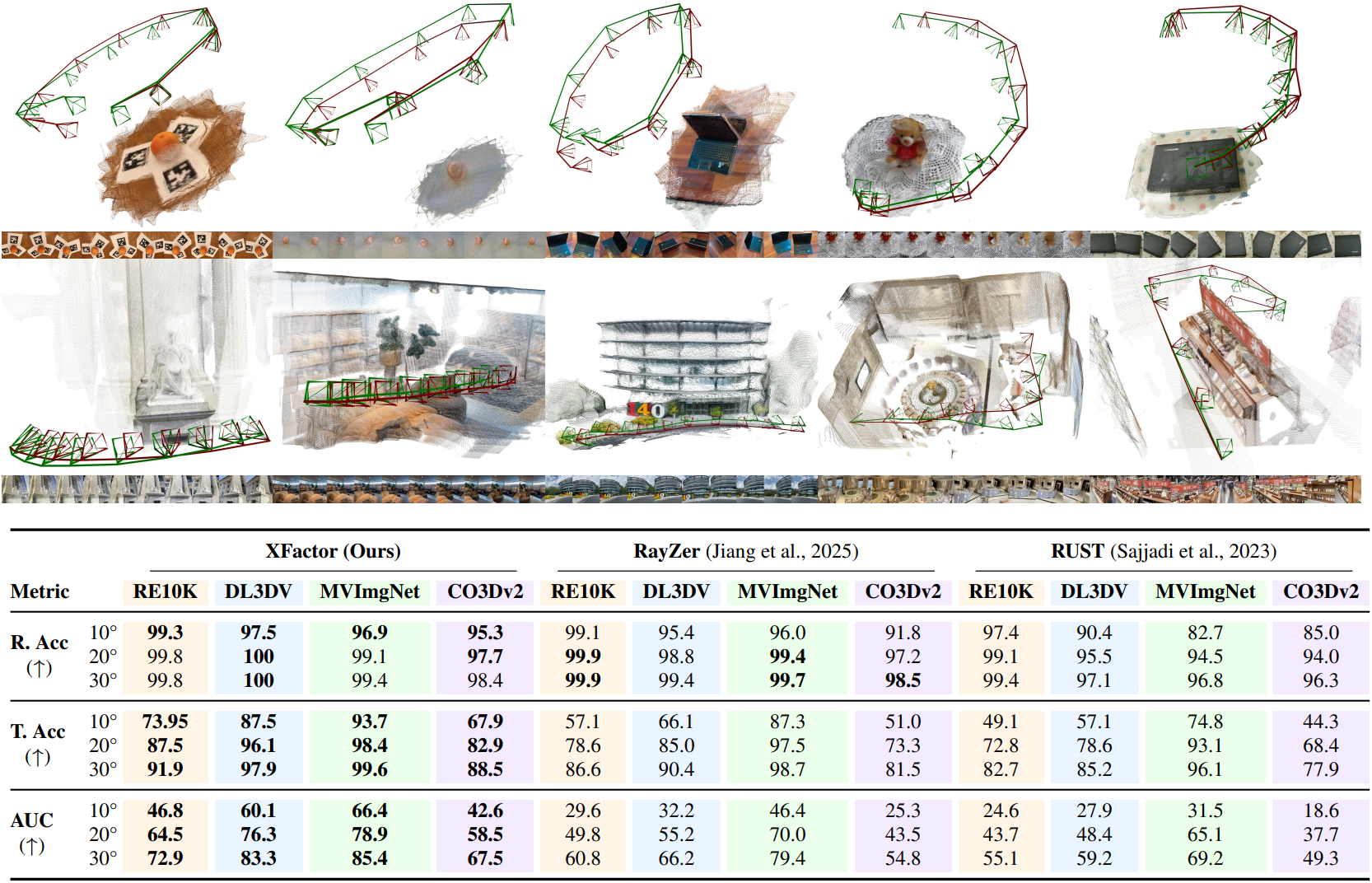
2. Pose probe
3. Ablations