[논문리뷰] STEM: Scaling Transformers with Embedding Modules
ICLR 2026. [Paper] [Page] [Github]
Ranajoy Sadhukhan, Sheng Cao, Harry Dong, Changsheng Zhao, Attiano Purpura-Pontoniere, Yuandong Tian, Zechun Liu, Beidi Chen
Carnegie Mellon University | Meta AI
15 Jan 2026
Introduction
Sparse한 연산은 토큰당 연산량을 비례적으로 증가시키지 않고도 파라미터 scaling law에서 예측되는 이점을 실현하는 핵심 메커니즘이다. 특히, Mixture of Experts (MoE) 모델은 토큰당 적은 수의 expert만을 sparse하게 활성화함으로써 활성화된 FLOPs를 거의 일정하게 유지하면서 파라미터 용량을 향상시키기 때문에 여러 LLM에 채택되어 왔다.
하지만 expert가 많은 구조는 최적화와 시스템 모두에서 상당한 어려움을 야기한다.
- 불균일한 라우팅으로 인해 상당수의 expert들이 충분히 학습되지 않은 상태로 남을 수 있으며 학습 불안정성을 초래할 수 있다.
- All-to-all 메시지 수가 많은 반면 각 메시지의 크기는 작아 대역폭 활용도가 저하되고 통신 오버헤드가 증가한다.
- Parameter-access locality가 감소하고, expert 네트워크가 너무 작아 선형 대수 커널이 높은 점유율을 달성하지 못하게 되면 커널 효율성을 저하시킨다
- 각 expert의 역할을 파악하기 어렵기 때문에 해석이 어렵다.
Sparsity의 잠재력을 최대한 활용하기 위해서는 안정적인 최적화, 광범위한 expert 활용, 무시할 수 있을 정도의 expert 검색 시간 및 통신 오버헤드가 필요하다. 또한, 아키텍처가 더 해석하기 쉽고 모든 expert를 보다 투명하게 활용할 수 있도록 설계되어야 한다.
본 논문에서는 static sprsity를 이러한 바람직한 특성을 달성하기 위한 잠재적 해결책으로 제시하였다. Static sparsity는 컴퓨팅 경로를 예측 가능하게 유지하고 (런타임 라우팅 지연 없음), prefetch와 CPU offloading을 가능하게 한다 (노드 간 통신 필요성 제거). 최근 토큰 인덱싱 라우팅을 통한 static sparsity가 강력한 성능 보장을 제공하는 유망한 방향으로 부상하고 있다. 그러나 이러한 토큰 기반 선택 전략은 컨텍스트 적응성이 부족하다. 이를 단순하게 적용할 경우, 더 많은 파라미터를 사용하더라도 모델의 표현력이 저하되고 품질이 떨어질 수 있다.
본 논문에서는 STEM이라는 정적 토큰 인덱싱 기반의 메커니즘을 제안하였다. STEM은 gated FFN에서 up projection만을 layer별 임베딩 테이블에서 가져온 토큰별 벡터로 대체한다. Gating 경로와 down projection 경로는 유지되고 토큰 간에 공유된다. STEM을 적용하면 학습 안정성이 향상되고, 더 큰 지식 용량에서의 성능이 향상되고, 해석 가능한 feature를 얻을 수 있고, 긴 컨텍스트 inference 성능이 향상된다.
Method
1. STEM
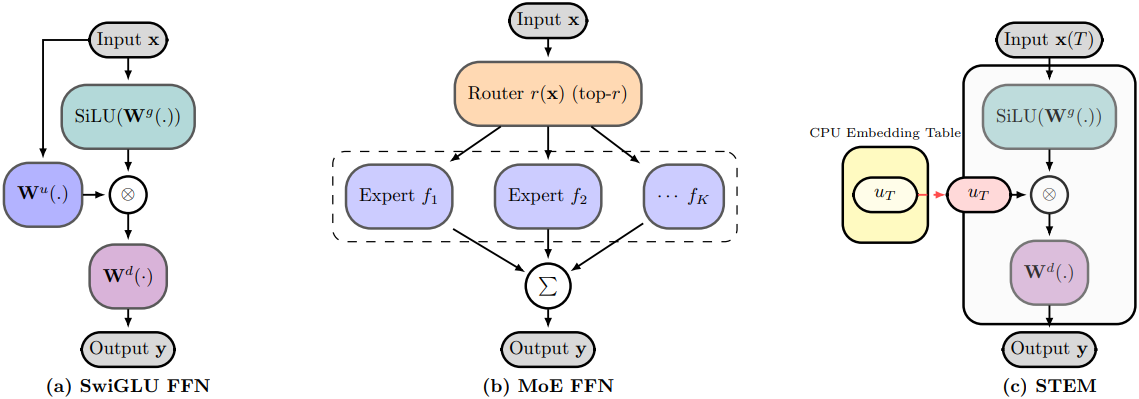
$N$개의 layer, vocabulary 크기 $V$, 모델 차원 $d$, feed-forward 차원 \(d_\textrm{ff}\)를 갖는 decoder-only transformer를 고려해 보자. 주어진 layer $\ell$에 대해 SwiGLU feed-forward block은 gate projection \(\textbf{W}_\ell^g \in \mathbb{R}^{d_\textrm{ff} \times d}\), up projection \(\textbf{W}_\ell^u \in \mathbb{R}^{d_\textrm{ff} \times d}\), down projection \(\textbf{W}_\ell^d \in \mathbb{R}^{d \times d_\textrm{ff}}\)를 사용한다. 현재 토큰의 vocabulary ID를 \(t \in \{1, \ldots, V\}\)라고 하고, $\ell$번째 FFN layer의 입력 hidden state를 \(\textbf{x}_\ell \in \mathbb{R}^d\)라고 하면, FFN layer에서의 변환은 다음과 같다.
\[\begin{equation} \textbf{y}_\ell = \textbf{W}_\ell^d \left( \textrm{SiLU}(\textbf{W}_\ell^g \textbf{x}_\ell) \odot (\textbf{W}_\ell^u \textbf{x}_\ell) \right) \end{equation}\]STEM은 Per Layer Embedding (PLE)의 설계를 기반으로 한다. Layer $\ell$에 대해 layer별 임베딩 테이블을 \(\textbf{U}_\ell [t] \in \mathbb{R}^{d_\textrm{ff}}\)라 하자. STEM layer는 다음을 계산한다.
\[\begin{equation} \textbf{y}_\ell = \textbf{W}_\ell^d \left( \textrm{SiLU}(\textbf{W}_\ell^g \textbf{x}_\ell) \odot \textbf{U}_\ell [t] \right) \end{equation}\](\(\textbf{U}_\ell [t] \in \mathbb{R}^{d_\textrm{ff}}\)는 토큰 $t$에 해당하는 \(\textbf{U}_\ell\)의 행, $\odot$은 element-wise multiplication)
STEM은 PLE와 몇 가지 디자인 측면에서 중요한 차이가 있다.
- PLE는 각 디코더 layer에서 기존 FFN blcok을 완전히 없애는 대신, 기존 FFN block과 함께 추가 구성 요소로 사용된다. 따라서 모델의 오버헤드와 유효 layer 깊이가 증가한다.
- PLE 임베딩 테이블은 일반적으로 일반 FFN layer의 중간 차원에 비해 훨씬 낮은 차원을 가진다. 예를 들어, gemma-3n-E4B-it는 FFN 중간 차원이 16384인 반면, PLE 차원은 256에 불과하다.
2. Insights
FFN의 key-view 메모리 관점
STEM의 동기를 이해하기 위해서는 FFN을 key-value 메모리 관점에서 바라보는 것이 중요하다. 2개의 projection을 가진 FFN은 콘텐츠 기반 검색이 가능한 key-value 메모리로 해석될 수 있다.
\[\begin{equation} \textbf{y} = \textbf{W}^d \phi (\textbf{W}^u \textbf{x}) = \sum_{i=1}^{d_\textrm{ff}} \underbrace{\phi (\langle \textbf{k}_i, \textbf{x} \rangle)}_{\textrm{addressing weight} \alpha_i (\textbf{x})} \end{equation}\](\(\textbf{k}_i\)는 $\textbf{W}^u$의 $i$번째 행, \(\textbf{v}_i\)는 $\textbf{W}^d$의 $i$번째 열)
$\textbf{W}^u$의 행은 key 역할을 하고, $\textbf{W}^d$의 열은 value를 나타낸다. Gated linear unit (GLU)은 콘텐츠 기반 검색을 content 스트림과 gate 스트림으로 분해하여 이 메모리를 더욱 풍부하게 만든다.
\[\begin{equation} \textbf{y} = \textbf{W}^d \left( (\textbf{W}^u \textbf{x}) \odot \sigma (\textbf{W}^g \textbf{x}) \right) = \sum_{i=1}^{d_\textrm{ff}} \{ \underbrace{\langle \textbf{k}_i, \textbf{x} \rangle}_{\textrm{content}} \cdot \underbrace{\sigma (\langle \tilde{\textbf{k}}_i, \textbf{x} \rangle)}_{\textrm{gate}} \} \textbf{v}_i \end{equation}\]\(\textbf{W}^g\)는 각 메모리 슬롯의 참여를 조절하는 두 번째 key \(\tilde{\textbf{k}}_i\)를 제공한다. 이러한 상호 작용은 query에 의존적인 슬롯별 증폭/억제를 구현하여 단일 스트림 FFN보다 더 선명하고 컨텍스트에 적응하는 검색 결과를 제공한다. SwiGLU는 gate nonlinearity를 SiLU로 대체하였다.
STEM 디자인 선택
저자들은 STEM 디자인의 효율성을 실증적으로 검증하기 위해, STEM 임베딩 테이블을 사용하여 up projection과 gate projection을 각각 독립적으로 대체해 보았다. Down projection은 모델의 forward 경로를 손상시키기 때문에 임베딩 모듈로 대체할 수 없다. Gate projection을 대체하면 다운스트림 성능이 저하되는 반면, up projection을 대체하면 성능이 향상된다. 이는 메모리 관점에 따라 FFN block에서 각 행렬이 수행하는 역할로 설명할 수 있다. Up projection은 down projection에서 feature 조회를 위한 주소를 생성하는 반면, gate projection은 보다 효율적인 정보 검색을 위해 컨텍스트에 따라 변조되는 정보를 제공한다. Gate projection을 컨텍스트에 구애받지 않는 임베딩으로 대체하면 오히려 그 기능이 저하될 수 있다. 이러한 이유로 STEM은 up projection을 layer별 임베딩 테이블로 대체하였다.
이러한 디자인 선택은 STEM이 성능과 효율성 측면에서 모두 이점을 누릴 수 있도록 한다. 또한, STEM은 지식 귀속을 개선하여 해석 가능성을 높이는 추가적인 이점을 제공한다.
2.1 Better Information Storage Capacity
FFN의 key-value 메모리 관점에서, up projection 행렬은 각 입력 hidden state를 down projection에서 관련 정보를 검색하는 주소 벡터로 매핑한다. 이러한 주소 벡터는 고차원 공간에 존재하지만, 실제 차원은 훨씬 낮은 경우가 많다. 실제로 FFN layer는 상대적으로 낮은 차원의 주소 공간 내에 많은 개념을 인코딩한다.
이와 대조적으로, STEM은 주소 벡터를 생성하기 위해 up projection 행렬에 의존하지 않는다. 대신, STEM 임베딩 자체가 토큰별 주소 벡터 역할을 하며, 이는 컨텍스트 의존하는 gate projection 출력에 의해 변조된다. 목표는 상호 일관성을 최소화하면서 토큰별 주소 벡터를 학습하는 것이다. 학습 후 STEM 임베딩 공간은 표준 FFN에서 생성된 주소 벡터보다 훨씬 더 큰 각도 분포를 나타낸다. 주소 공간의 이러한 중복성 감소가 더 정확하고 분리된 지식 귀속을 가능하게 하여 모델의 유효 정보 저장 용량을 향상시킨다.
2.2 Knowledge Specificity & Interpretability
STEM 임베딩은 개별 토큰에 할당된다. 메모리 관점에 따르면, 이 임베딩은 해당 토큰과 관련된 필수 정보를 localize해야 한다. 따라서 텍스트 입력을 변경하지 않고 각 layer의 STEM 임베딩을 신중하게 수정함으로써 출력 확률 분포를 조절할 수 있는 조향 벡터 역할을 할 수 있다. 표준 FFN layer에는 이러한 직접적인 지식 귀속 특성이 결여되어 있다. 그러나 STEM에는 이러한 지식 귀속 특성이 내재되어 있으므로, 모델 성능과 해석 가능성 사이의 trade-off를 해결하고자 한다.
2.3 Efficiency
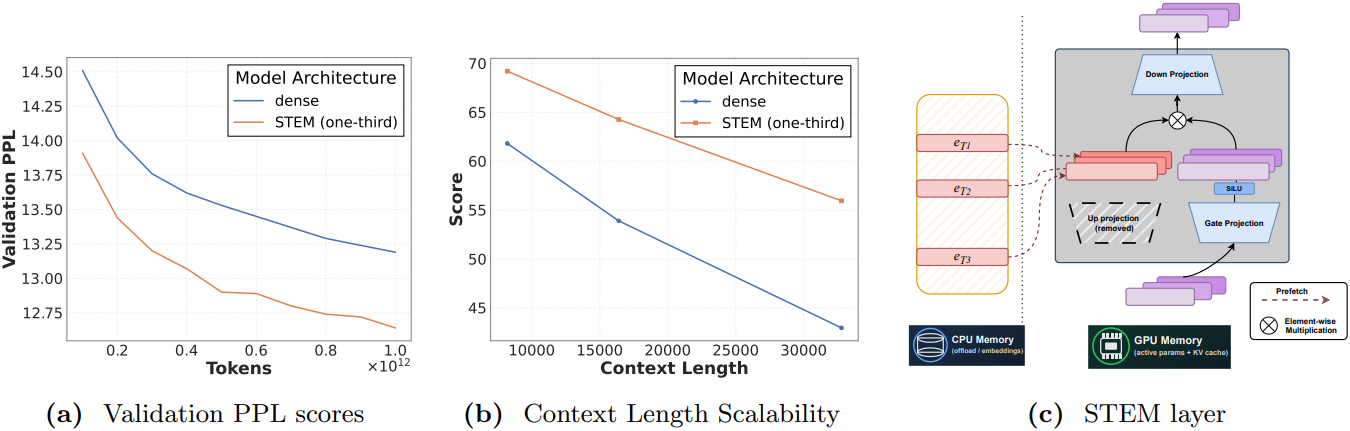
STEM은 연산량과 메모리 접근량을 모두 향상시킨다. 연산 집약적인 학습 단계와 prefill 단계에서 FFN up projection을 토큰 인덱싱 임베딩으로 대체하면 layer별 FLOPs가 감소한다. 메모리 집약적인 디코딩 단계에서는 dense up projection에 비해 파라미터 트래픽이 줄어든다.
학습 효율성
시퀀스 길이 $L$, hidden layer 차원 $d$, FFN 차원 \(d_\textrm{ff}\)를 갖는 $B$개의 시퀀스 batch를 고려해 보자. Element-wise 연산과 bias를 무시하면, 각 layer의 학습 FLOPs (forward + backward)는 다음과 같이 나타낼 수 있다.
\[\begin{aligned} F_\textrm{train}^\textrm{base} &= B (4Ld^2 + 2L^2 d + 3Ld d_\textrm{ff}) \\ F_\textrm{train}^\textrm{stem} &= B (\underbrace{4Ld^2 + 2L^2 d}_{\textrm{Attn}} + \underbrace{2Ld d_\textrm{ff}}_{\textrm{FFN}}) \\ \textrm{saving fraction} &= \frac{F_\textrm{train}^\textrm{base} - F_\textrm{train}^\textrm{stem}}{F_\textrm{train}^\textrm{base}} = \frac{d_\textrm{ff}}{4d + 2L + 3d_\textrm{ff}} \end{aligned}\]각 Qwen2.5 모델에 대한 아키텍처 hyperparameter를 입력하면, Qwen2.5-1.5B의 경우 21.7%, Qwen2.5-3B의 경우 22.8%, Qwen2.5-7B의 경우 23.9%, Qwen2.5-14B의 경우 19.7%, Qwen2.5-32B의 경우 24.8%의 절감 효과를 얻을 수 있다.
Inference 효율성
Prefill 효율성은 학습 효율성과 매우 유사하다. 반면 디코딩은 주로 메모리 집약적이다. 주요 비용은 FLOP 연산보다는 파라미터 로딩과 KV cache에 소요된다. Layer별 메모리 접근 비용은 다음과 같이 나타낼 수 있다.
\[\begin{aligned} M_\textrm{dec}^\textrm{base} &= B (4d^2 + 2Ld + 3d d_\textrm{ff}) \\ M_\textrm{dec}^\textrm{stem} &= B (\underbrace{2Ld}_{\textrm{KV cache}} + \underbrace{4d^2 + 2d d_\textrm{ff}}_{\textrm{projection parmas}}) \\ \textrm{saving fraction} &= \frac{M_\textrm{dec}^\textrm{base} - M_\textrm{dec}^\textrm{stem}}{M_\textrm{dec}^\textrm{base}} = \frac{d_\textrm{ff}}{4d + 2L + 3d_\textrm{ff}} \end{aligned}\]즉, 학습 과정과 prefill 과정에서 FLOPs 절감 효과와 일치한다. Batch size가 커짐에 따라 linear layer는 점점 더 계산 집약적인 연산 능력을 요구하게 되는데, STEM의 layer별 FLOPs 감소는 높은 처리량 환경에서도 이러한 효율성 향상을 보장한다.
MoE와의 주요 차이점은 batch size에 따른 비용 증가 방식이다. STEM에서는 파라미터 트래픽이 주로 고유한 토큰 수에 따라 증가한다. 반면 MoE의 expert 선택은 batch size와 라우팅 다양성에 따라 확장된다. Batch size가 클수록 더 많은 expert가 활성화되어 sprsity 이점이 빠르게 감소한다.
2.4 VRAM and Communication Savings
MoE 모델은 많은 VRAM을 사용한다. Expert들은 GPU에 상주해야 하거나, 반복적으로 가져와야 한다. 또한, expert 병렬 처리는 적은 수의 expert만 활성화된 경우에도 모든 expert 간의 all-to-all 통신이 필요하다.
STEM은 이러한 비용을 절감한다. STEM의 임베딩은 토큰 인덱싱 방식으로 각 layer에 로컬로 저장되므로, 모델은 별도의 라우팅 로직 없이 미리 가져올 수 있다 (prefetching). 이러한 테이블은 행렬 곱셈 가중치와 분리되어 있어 CPU 메모리로 offloading할 수 있다. 이를 통해 FFN 파라미터 메모리의 약 3분의 1을 절약할 수 있다. 또한, 모든 서빙 노드의 CPU 메모리에 임베딩 테이블을 복제할 수 있다. 이를 통해 노드 간 expert 트래픽과 expert parallelism의 동기화 오버헤드를 제거할 수 있다.
Prefetching 비용
Batch로 구성된 토큰의 STEM 임베딩 중복을 제거하면 prefetching 비용을 크게 줄일 수 있다. 또한 up projection 행렬을 제거하여 절약한 추가 메모리를 활용하여 가장 자주 사용되는 STEM 임베딩을 캐싱함으로써 트래픽을 더욱 줄일 수 있다. 모델 임베딩 크기가 커짐에 따라 계산 비용은 제곱에 비례하여 증가하지만, prefetching 비용은 선형적으로만 증가한다. 따라서 CPU로 offloading된 STEM은 모델 크기가 커질수록 더욱 매력적이고 scalability가 뛰어나다.
2.5 Context-length Adaptive Parameter Usage
STEM은 토큰 인덱싱 기반의 sparsity를 사용하기 때문에, forward pass에서 영향을 받는 파라미터의 수는 window 내 고유한 토큰 수에 비례하여 증가한다. Attention의 공유 Q/K/V/O projection과 gated FFN의 gate/down projection을 제외하고, STEM 모듈은 layer별로 토큰 ID당 하나의 벡터를 사용한다. 반복되는 토큰은 동일한 벡터를 재사용하고, 새로운 토큰은 새로운 벡터를 활성화한다. 컨텍스트 길이를 $L$, 시퀀스 내 고유 토큰 ID 수를 \(L_\textrm{uniq}\)라고 할 때, STEM이 layer 집합 $\mathcal{S}$에 적용되고 FFN 차원이 $$ dff인 경우, 하나의 시퀀스에 의해 활성화되는 STEM 관련 파라미터는 다음과 같다.
\[\begin{equation} \textrm{Params}_\textrm{act}^\textrm{STEM} (L) = \vert \mathcal{S} \vert d_\textrm{ff} L_\textrm{uniq} \end{equation}\]자연어 텍스트에서는 일반적으로 \(L_\textrm{uniq}\)는 sublinear하게 증가하므로, 더 긴 컨텍스트를 사용할수록 더 많은 파라미터가 점진적으로 활성화되지만 토큰당 FLOPs는 증가하지 않는다.
이를 통해 예측 가능한 지연 시간으로 test-time capacity scaling이 가능해진다. 활성 파라미터 수는 컨텍스트 길이에 따라 계속 증가하며 MoE처럼 빠르게 포화되지 않는다. Gate projection과 down projection은 컨텍스트 혼합을 유지하는 반면, STEM 경로는 낮은 오버헤드로 추가 용량을 제공하여 토큰당 거의 일정한 컴퓨팅 성능으로 long-context task를 지원한다.
3. Knowledge Editing with STEM
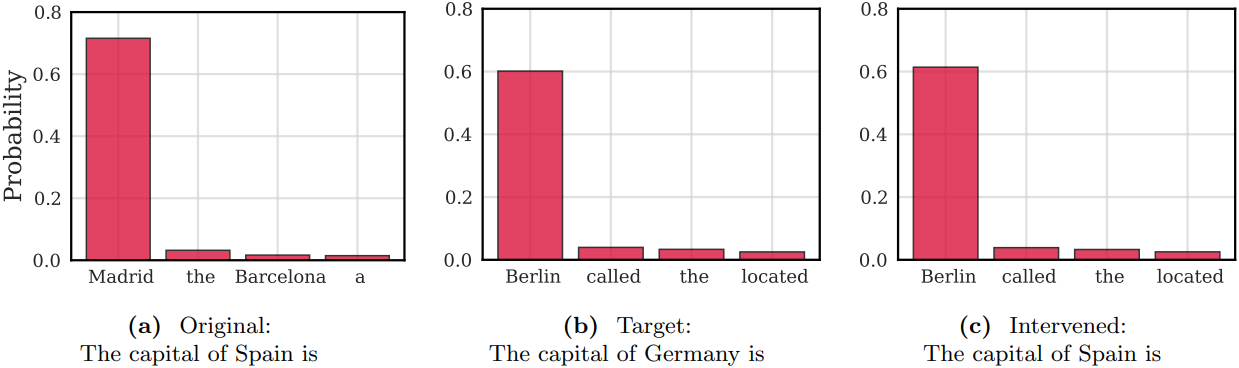
저자들은 STEM 임베딩을 이용하여 입력 텍스트 자체는 변경하지 않고 STEM 벡터만 수정함으로써 사실적 지식을 편집할 수 있는지 살펴보았다. 구체적으로, 프롬프트에 나타나는 소스 엔티티(ex. “스페인”)와 모델이 대신 처리하기를 원하는 타겟 엔티티(ex. “독일”)를 고려해보자. 소스 토큰 위치의 STEM 임베딩을 적절하게 대체함으로써, 모델이 타겟 엔티티와 일치하는 텍스트를 생성하도록 유도할 수 있다. 예를 들어, 스페인의 수도에 대해 쓰라는 요청을 받았을 때 “마드리드” 대신 “베를린”에 대하여 작성하도록 할 수 있다.
소스 엔티티와 타겟 엔티티가 동일한 수의 토큰으로 tokenize될 경우 편집은 간단하다. 각 소스 토큰의 STEM 임베딩을 해당 타겟 토큰의 STEM 임베딩으로 바꾸기만 하면 된다. 이러한 일대일 치환만으로도 출력 분포에 의미 있는 변화를 유도하기에 충분한 경우가 많다.
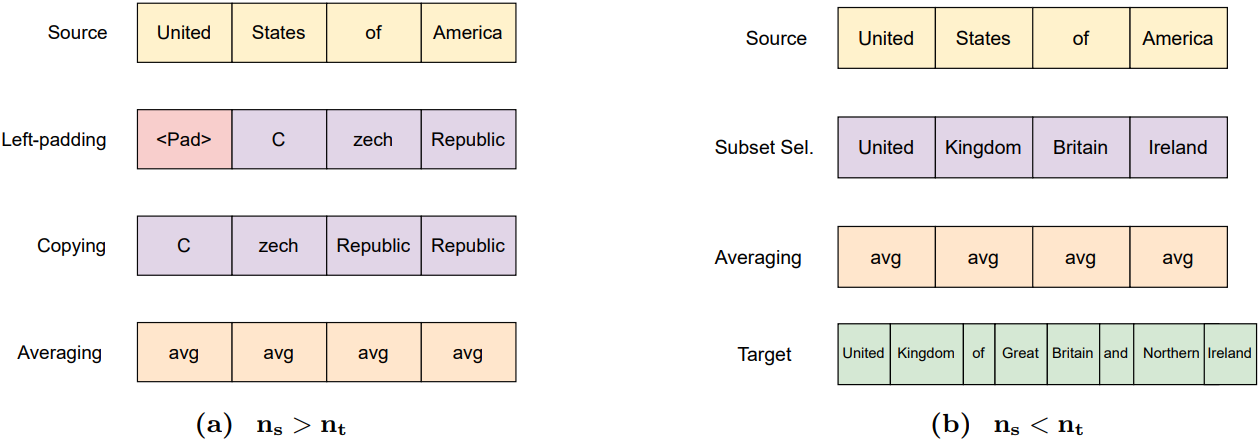
소스 엔티티와 타겟 엔티티의 토큰 개수가 서로 다른 경우가 더 흥미롭다. 소스 토큰 수와 타겟 토큰 수를 각각 $n_s$와 $n_t$라고 하자. $n_s > n_t$인 경우, 두 가지 전략을 사용할 수 있다.
- Padding: 타겟 토큰 시퀀스의 패딩을 소스 토큰의 개수와 일치하도록 조정한다. 이때 왼쪽 또는 오른쪽에 특수 패딩 토큰을 삽입한다. 경험적으로 왼쪽 패딩이 약간 더 나은 결과를 보이는 경향이 있다.
- Copying: 타겟 토큰을 반복하여 소스 토큰의 개수와 일치하도록 조정한다. 각 타겟 토큰은 \(\lfloor n_s/n_t \rfloor\)번 반복되며, 마지막 타겟 토큰은 소스 개수를 정확히 일치시키도록 필요에 따라 추가로 반복된다.
$n_s < n_t$일 때, 모든 타겟 토큰을 일대일로 매핑할 수 없다. 이 경우, 의미적으로 가장 대표적인 임베딩을 가진 타겟 토큰 부분집합을 선택하고, 이 부분집합만을 사용하여 소스 토큰 임베딩을 대체한다. 이러한 부분집합 선택 전략은 여전히 일관성 있는 편집을 유도할 수 있다.
마지막으로, 위에서 언급한 모든 시나리오에서 작동하는 길이 무관 전략을 사용할 수도 있다. 이 전략은 타겟 토큰의 STEM 임베딩의 평균을 계산하고, 이 하나의 평균 벡터를 사용하여 각 소스 토큰 임베딩을 대체하는 것이다. 이 averaging 방식은 단순해 보이지만 놀라울 정도로 우수한 성능을 보이며, 광범위한 예제에서 안정적인 편집 결과를 제공한다.
Experiments
1. Experimental Results
다음은 모델 아키텍처에 따른 학습 안정성을 비교한 결과이다.
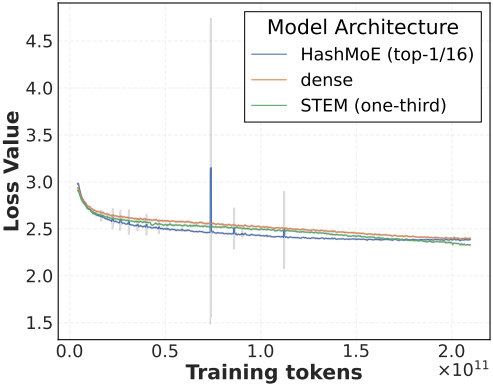
다음은 pre-training 후 모델에 대한 평가 결과이다.
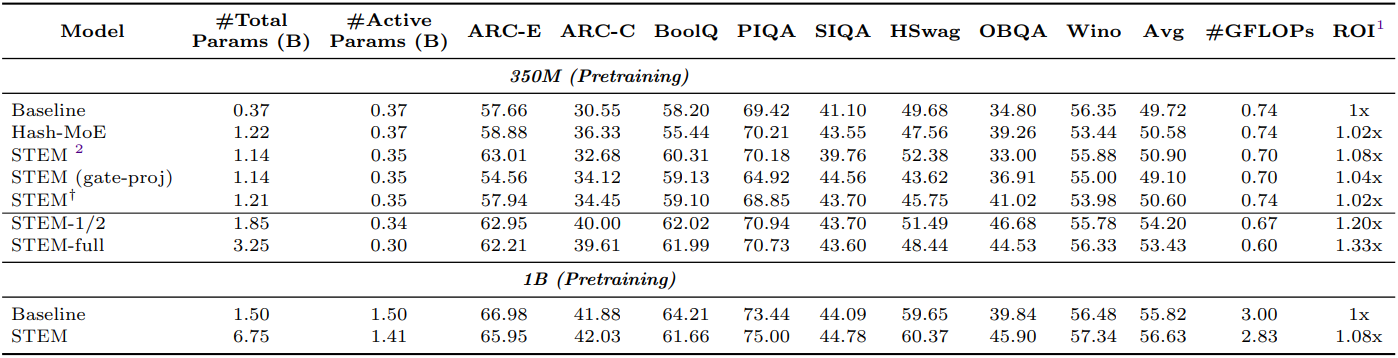
다음은 mid-training 후 모델에 대한 평가 결과이다.

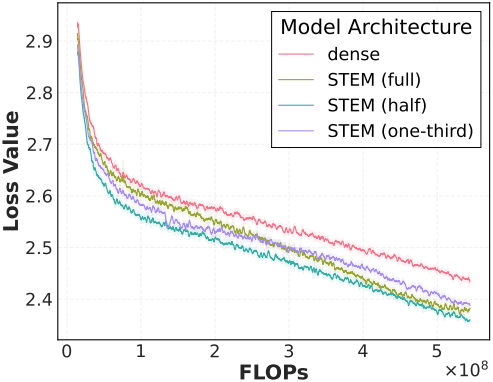
다음은 STEM으로 대체한 layer 비율에 따른 성능을 비교한 결과이다.
3. STEM Characteristics
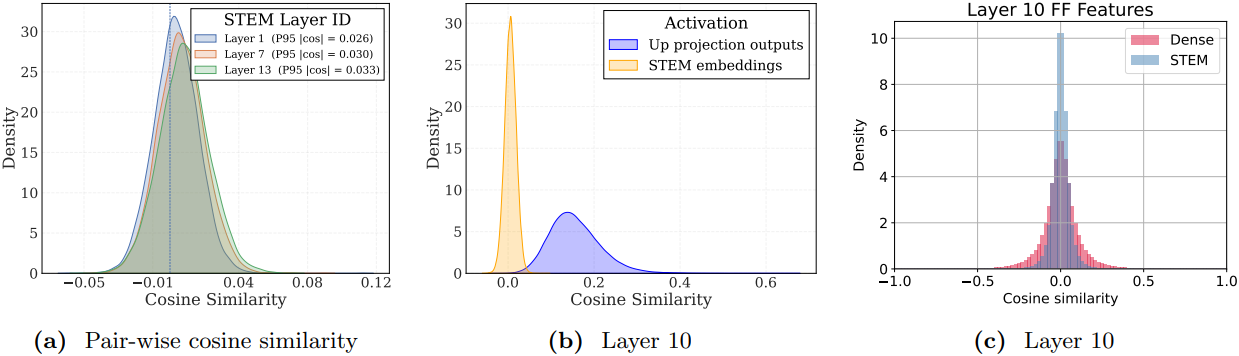
다음은 STEM 임베딩에 대한 쌍별 코사인 유사도 분포를 나타낸 그래프이다. (a)는 각 layer별 비교, (b)는 up projection 출력과의 비교, (c)는 down projection 행렬의 입력 hidden state 간 비교 결과이다. (모두 1B 모델)
다음은 원래 프롬프트는 그대로 두고 모든 STEM layer에서 “Spain”의 STEM 벡터을 “Germany”와 바꿨을 때의 상위 4개 다음 토큰 확률을 나타낸 것이다. 교환을 통해 Madrid에서 Berlin으로 확률 분포가 이동하며, 이는 토큰 기반, layer별, 그리고 가역적인 사실 예측 제어가 가능함을 보여준다.