[논문리뷰] Dual-objective Language Models: Training Efficiency Without Overfitting
ICLR 2026. [Paper]
David Samuel, Lucas Georges Gabriel Charpentier
University of Oslo | National Library of Norway
16 Dec 2025
Introduction
최근 언어 모델 학습의 주요 패러다임은 autoregressive next-token prediction 방식이다. 이 방식은 학습 효율성이 매우 뛰어나 모델이 방대한 양의 텍스트를 빠르게 학습할 수 있다. 그러나 학습 데이터가 반복될 경우 overfitting되는 경향이 있다는 중대한 단점이 있다. 특히, 기존의 scaling law에 따라 점점 더 큰 모델을 학습하는 데 필요한 데이터가 고갈되는 ‘data wall’에 도달함에 따라 이 문제는 더욱 심각해지고 있다.
대안으로 masked diffusion language modeling 방식이 overfitting 문제를 해결하는 효과적인 솔루션을 제시하였다. 하지만 이 방식은 autoregressive 모델에 비해 샘플 효율성이 훨씬 떨어지는 것으로 알려져 있다. 이 두 방식의 상호 보완적인 강점을 고려할 때, 두 방식을 결합하는 것이 각각의 단점을 극복하는 자연스러운 해결책이 될 수 있다.
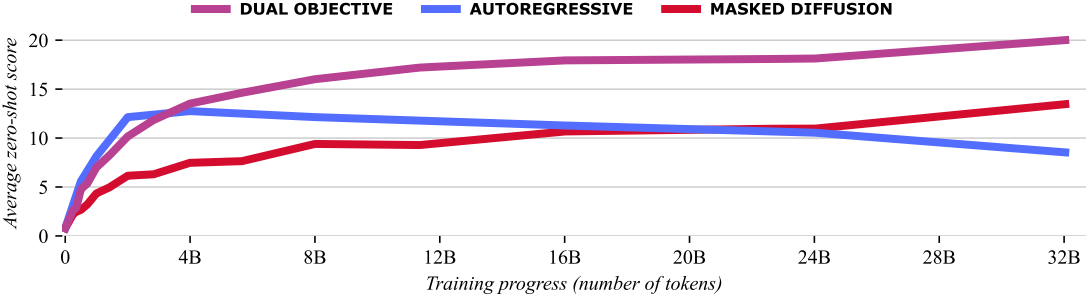
본 논문에서는 autoregressive objective와 masked diffusion objective를 동시에 사용하여 하나의 언어 모델을 학습함으로써 두 가지 장점을 모두 얻을 수 있음을 보여준다. 핵심 아이디어는 autoregressive objective의 학습 효율성을 활용하여 빠른 초기 학습을 수행하는 동시에 masked diffusion objective를 사용하여 모델을 정규화하고 overfitting을 방지하는 것이다. 결과적으로, 이러한 모델은 inference 오버헤드 없이 표준 autoregressive 모델처럼 배포할 수 있다.
이러한 관찰을 바탕으로, 본 논문에서는 다양한 데이터 제약 조건 하에서 이 두 가지 objective 사이의 최적의 균형을 찾기 위해 대규모의 체계적인 연구를 수행하였다. 저자들은 일반적인 학습 환경과 데이터 제약 환경 모두에서 최적의 objective 비율을 설정하기 위한 두 가지 실용적인 권장 사항을 도출하여, 향후 LLM 학습을 위한 구체적인 가이드라인을 제공하였다.
Method
Autoregressive objective와 masked objective를 결합하는 방법들은 초기 GPT-BERT 접근 방식을 기반으로 한다. 그들은 BabyLM Challenge의 제한 조건 내에서 학습된 매우 작은 언어 모델에 대해 유망한 결과를 보여주었다. 본 논문은 GPT-BERT의 접근 방식을 masked diffusion language model로 확장하고 훨씬 더 큰 계산 규모로 확장하였다.
Dual-objective language model은 다음과 같은 결합된 loss function을 최소화하여 학습된다.
\[\begin{equation} \underset{\theta}{\arg \min} \mathbb{E}_{x \sim \mathcal{D}} \left[ \alpha \mathcal{L}_\textrm{AR} (x; \theta) + (1 - \alpha) \mathcal{L}_\textrm{MD} (x; \theta) \right] \end{equation}\]Loss weighting
Autoregressive objective \(\mathcal{L}_\textrm{AR}\)과 masked diffusion objective \(\mathcal{L}_\textrm{MD}\) 사이의 균형은 hyperparameter $\alpha$에 의해 제어된다. 이는 학습 효율성과 overfitting robustness 사이의 절충점을 찾는 데 매우 중요한다.
실제로, 두 objective를 하나의 batch 내에서 단순히 혼합하면 처리량이 감소할 수 있다. 이러한 이유로, 저자들은 각 GPU에 하나의 objective를 할당하여 계산 그래프를 단순하고 정적으로 유지하고 효율적으로 컴파일할 수 있도록 하였다. 구체적으로, 각 모델의 학습을 256개의 장치에 분산시켜 256 + 1개의 $\alpha$ 값 중에서 선택할 수 있도록 하였다.
\[\begin{equation} \alpha \in \{i/256 \vert i = 0, 1, \ldots, 256\} \end{equation}\]Diffusion as next-token prediction
본 논문의 목표는 \(\mathcal{L}_\textrm{AR}\)과 \(\mathcal{L}_\textrm{MD}\)를 하나의 transformer 모델로 parameterize할 수 있도록 정렬하는 것이다. 이를 위해 masked next-token prediction (MNTP)이라는 masked language modeling의 약간 수정된 버전을 사용한다. 이 접근 방식에서 모델은 항상 $i$번째 위치의 hidden state를 사용하여 $i+1$번째 위치의 다음 토큰을 예측한다. 이러한 방식으로 두 가지 작동 모드는 모두 next-token prediction을 수행하므로 원할하게 통합된다.
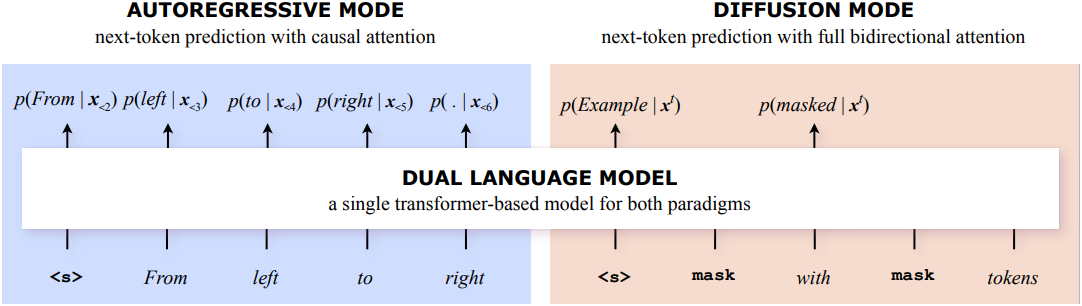
Standard transformer architecture
MNTP를 사용하는 주요 이점은 표준 autoregressive 모델과 동일한 transformer 아키텍처를 사용할 수 있고, 두 가지 objective를 동시에 고려하여 파라미터를 최적화할 수 있다는 것이다. 두 작동 모드의 유일한 차이점은 입력이다.
- 원래의 입력 + causal attention mask (단방향)
- 부분적으로 마스킹된 입력 + 비어 있는 attention mask (완전 양방향)
Experiments
- Task: ARC-Easy, ARC-Challenge, BLiMP, Commonsense QA, HellaSwag, MMLU, OpenBook QA, Physical Interaction QA, Social IQa
- 전체 학습 토큰 수: 320억 개
- repetition factor $R$: 전체 학습 토큰에서 $1/R$을 샘플링한 뒤, $R$번 반복 학습
- 모델: 470M 파라미터
- layer 수: 24
- hidden dimension: 1,024
- head 수: 16
- feed-forward dimension: 3,554
- vocabulary: 51,200
- 학습 디테일
- optimizer: Muon
- learning rate: 0.007 (warmup-stable-decay schedule)
- step 수: 8,192
- global batch size: 400만 토큰
- 시퀀스 길이: 2,048 토큰
- weight decay: 0.1
- 보조 z-loss: $10^{-4}$
1. Results
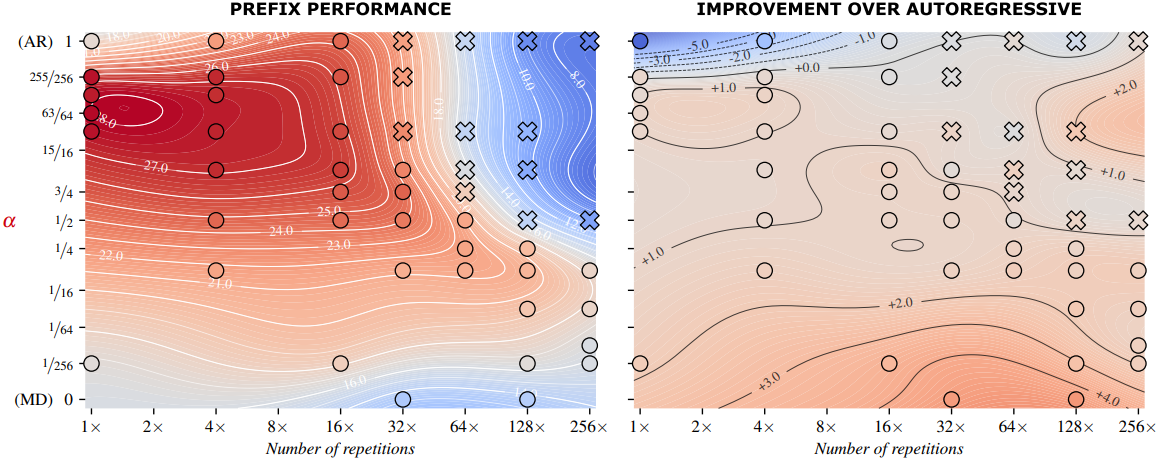
다음은 반복 횟수와 $\alpha$에 따른 결과이다. 위는 Gaussian process regression (GPR)으로 결과를 interpolation한 것이고, 아래는 $\alpha$가 해당 반복 횟수에서 최적일 확률을 추정한 것이다.
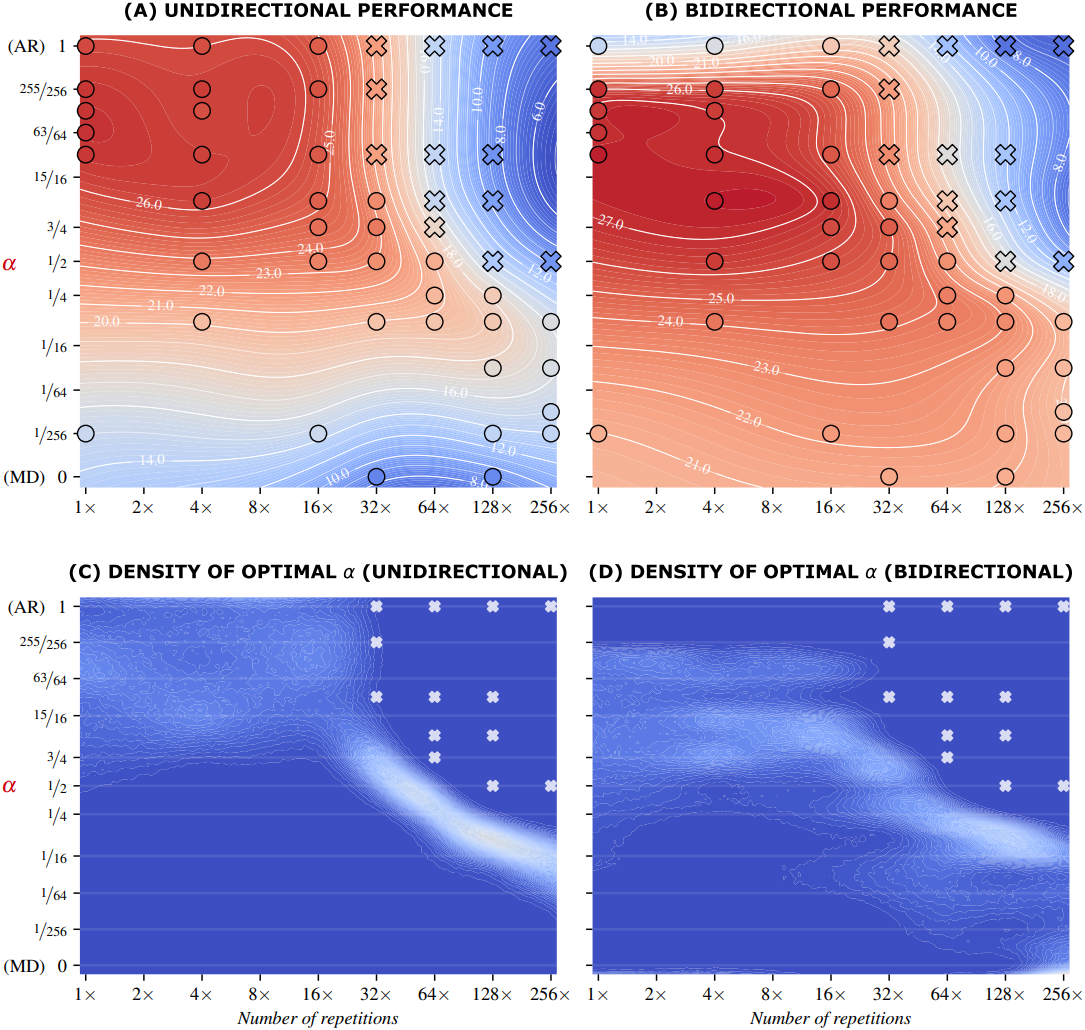
일반적인 학습 환경($R \le 16$)에서는 높은 $\alpha$에서의 성능이 더 좋지만, 데이터 제약이 있는 환경($R \ge 32$)에서는 학습 데이터의 약 16회 반복에 autoregressive objective가 노출되도록 $\alpha$를 선택하는 것이 좋다.
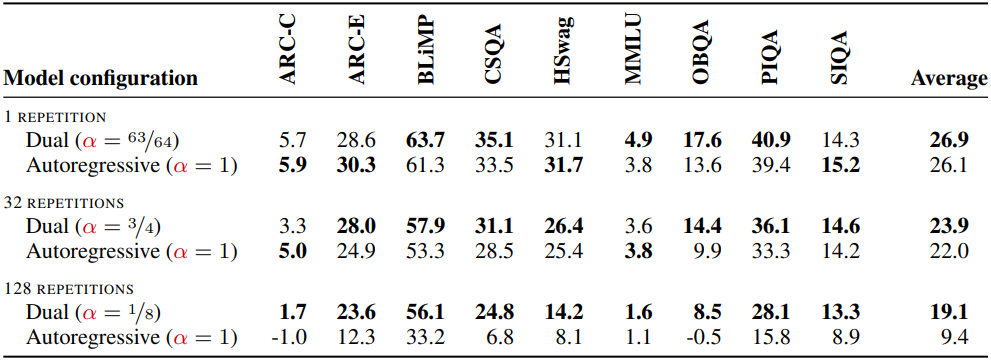
다음은 각 반복 횟수에서 가장 성능이 좋았던 $\alpha$에 대해 autoregressive ($\alpha = 1$) 모델과 비교한 결과이다.
2. Generalization to prefix language modeling
Prefix language modeling은 텍스트의 컨디셔닝 부분에는 양방향 attention을 적용하고 나머지 부분은 autoregressive하게 완성하는 방법이다. 본 논문의 모델은 단방향 attention과 양방향 attention을 모두 사용하여 학습되었기 때문에, 추가 학습 없이 prefix language modeling을 적용할 수 있다. 결과는 다음과 같다.