[논문리뷰] Sapiens2
ICLR 2026. [Paper] [Github]
Rawal Khirodkar, He Wen, Julieta Martinez, Yuan Dong, Su Zhaoen, Shunsuke Saito
Meta Reality Labs
23 Apr 2026

Introduction
Sapiens는 인간 중심 비전을 위한 foundation model을 제시했다. 궁극적인 목표는 최고의 출력 정확도를 유지하면서 모든 인간 중심 task와 모든 인간 이미지에 적용 가능한 모델을 구축하는 것이다. 본 논문에서는 task, 이미지, 정확도라는 세 가지 축 모두에서 이 목표를 더욱 발전시킨 Sapiens2를 소개한다.
Sapiens는 masked image modeling (MIM)에 크게 의존한다. MIM은 reconstruction을 최적화함으로써 공간적 신호와 디테일을 보존하며, semantic을 안정적으로 표현하기 위해 중간에서 높은 수준의 supervision이 필요한 경우가 많다. 반면 contrastive learning (CL)은 세밀한 공간적 디테일과 정확도가 중요한 dense prediction에서 성능이 저하되는 경향이 있다. Sapiens2는 reconstruction objective와 contrastive objective를 결합하여 픽셀 공간에 feature를 고정하고 semantic하게 구성함으로써 이러한 한계를 해결하였다.
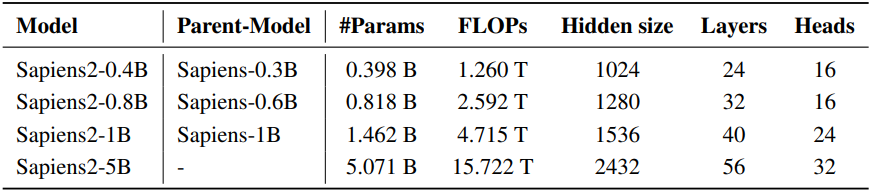
Sapiens와 비교하여, Sapiens2는 task별 supervision 데이터를 10배 확장하여 일반적으로 task당 약 100만 개의 레이블을 사용하고, 더욱 세밀한 geometry와 사실적인 표현을 통해 합성 에셋을 개선했다. 모델 스케일 측면에서, 가장 큰 모델은 5B이며, 광범위한 활용을 위해 0.4B, 0.8B, 1B 모델도 개발했다. 1K의 기본 해상도에서, 5B 모델은 ViT 중 최고 수준의 FLOPs 성능을 달성했다. 본 모델은 체인이나 귀걸이와 같은 작은 액세서리까지 분할하고, 치아와 잇몸을 픽셀 단위로 정확하게 분리한다. 또한, 예측된 normal 벡터는 얼굴 주름과 머리카락의 디테일을 더욱 정확하게 포착한다.
Sapiens의 1K backbone을 넘어, 본 논문에서는 4K backbone을 도입하고, 모든 task에서 2K 해상도로 디코딩하는 task head를 사용하였다. 또한 4K 해상도를 효율적으로 처리하기 위해 계층적 디자인을 채택했다. 먼저 window 기반의 self-attention layer 스택을 사용하여 각 window에서 텍스처와 미세한 경계를 포착하고, 각 window에서 [CLS]-guided pooling을 한 후, 1K 모델과 유사하게 global self-attention을 적용하여 long-range 컨텍스트를 통합한다. 이러한 구조는 MAE 방식의 사전 학습과 자연스럽게 호환된다. 로컬 단계 후 마스킹된 토큰을 제거하여 마스킹된 영역을 넘어 정보가 유출되지 않도록 함으로써 정보 누출을 방지한다. 또한, 효율성과 안정성 향상을 위해 LayerNorm 대신 RMSNorm을 사용하고, 처리량 향상을 위해 grouped-query attention을 적용했으며, robust한 고해상도 학습을 위해 QK-Norm을 사용하고, sub-pixel 추론을 위해 pixel-shuffle 디코더를 적용했다. 이러한 선택들을 통해 고해상도 설정을 최대한 활용하면서도 메모리 사용량을 적절하게 유지할 수 있다.
Pretraining
1. Humans-1B Dataset
데이터 분포가 다양하고 균형 잡혀 있으며 고품질일 때만 규모의 이점이 발휘된다. 저자들은 약 40억 개의 이미지로 구성된 웹 스케일의 데이터 풀에서, bounding box detection, 머리 포즈 추정, 미적 점수 및 사실성, CLIP feature 추출, 텍스트 오버레이 감지 등 다단계 필터를 통해 사람 중심 콘텐츠를 추출하였다. 남은 이미지 중에서 짧은 변의 길이가 384픽셀 이상인 이미지를 선별하였다. 이미지에는 여러 사람이 포함될 수 있다. Perceptual hashing과 deep-feature nearest-neighbor pruning을 통해 중복을 제거하고, 비전 임베딩을 클러스터링한 후 선택적 샘플링을 통해 포즈, 시점, occlusion, 의상, 장면 유형, 조명에 걸쳐 콘텐츠 균형을 맞추었다. 그 결과, 사전 학습에 사용할 수 있는 약 10억 개의 고품질 사람 이미지로 구성된 선별되고 균형 잡힌 데이터셋을 얻었다.
2. Self-Supervised Learning
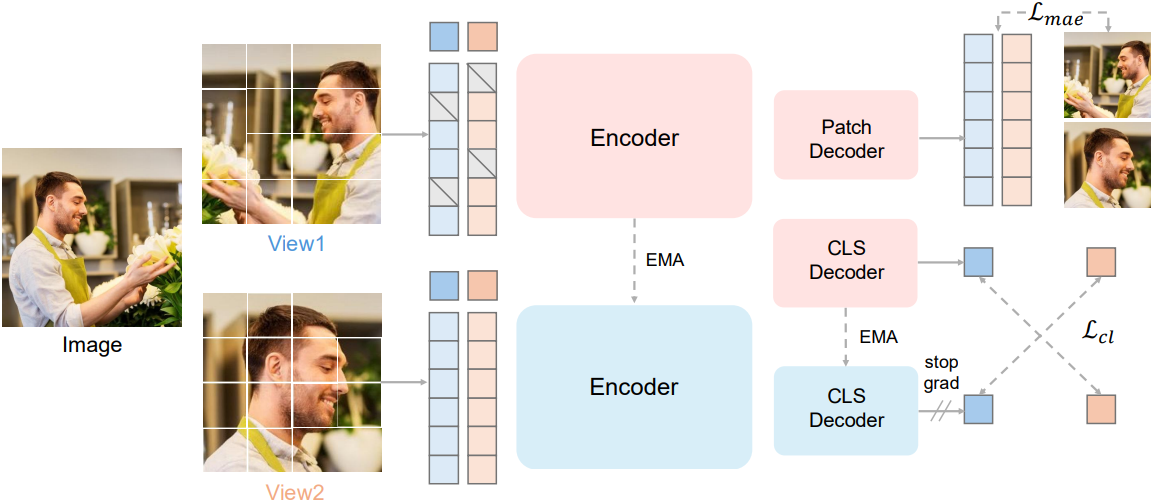
학습 데이터셋을 $\mathcal{I}$라고 하자. 이미지 $\textbf{x} \sim \mathcal{I}$를 샘플링하고 $V$개의 무작위 augmentation된 이미지를 생성하여 뷰 \(\{\textbf{x}_i\}_{i=1}^V\)을 얻는다. 각 뷰는 \(\mathcal{P} = \{1, \ldots, N\}\)으로 인덱싱되는 $N$개의 토큰 \(\textbf{x}_i = \{\textbf{x}_i^p\}_{p \in \mathcal{P}}\)으로 patchify된다. \(\{\textbf{e}_\textrm{pos}^p\}_{p \in \mathcal{P}}\)를 위치 임베딩이라고 하고, \(\Phi_\textrm{enc}\), \(\Phi_\textrm{dec}\), \(\Phi_\textrm{cls}\)를 각각 transformer 인코더, 패치 디코더, contrastive 디코더라고 하자. 구체적으로, \(\Phi_\textrm{cls}\)는 인코더 [CLS] 토큰을 $K$개의 logit으로 매핑한다.
Masked Image Modeling
각 뷰 \(i \in \{1, \ldots, V\}\)에 대해 마스킹 비율 $r$로 binary mask \(\textbf{m}_i \in \{0, 1\}^N\)을 샘플링한다. 마스킹된 인덱스 집합과 마스킹되지 않은 인덱스 집합을 \(\mathcal{M}_i = \{p \in \mathcal{P} : m_i^p = 1\}\)와 \(\mathcal{V}_i = \mathcal{P} \setminus \mathcal{M}_i\)로 정의한다. 인코더 \(\Phi_\textrm{enc}\)는 마스킹 되지 않은 토큰만 처리한다.
\[\begin{equation} \textbf{z}_i^\textrm{vis} = \Phi_\textrm{enc} (\{ \textbf{x}_i^p + \textbf{e}_\textrm{pos}^p \}_{p \in \mathcal{V}_i}) \end{equation}\]그런 다음 \(\textbf{z}_i^\textrm{vis}\)를 \(\mathcal{V}_i\)로 다시 분산시키고 학습된 마스킹 토큰을 \(\mathcal{M}_i\)에 삽입하여 전체 시퀀스를 구성한다.
\[\begin{equation} \textbf{z}_i = \textrm{scatter} (\textbf{z}_i^\textrm{vis}; \mathcal{V}_i) \, \cup \, \left\{ \textbf{e}_{[\textrm{MASK}]} + \textbf{e}_\textrm{pos}^p \right\}_{p \in \mathcal{M}_i} \end{equation}\]디코더 \(\Phi_\textrm{dec}\)는 모든 패치를 복원한다.
\[\begin{equation} \hat{\textbf{x}}_i = \{ \hat{\textbf{x}}_i^p \}_{p \in \mathcal{P}} = \Phi_\textrm{dec} (\textbf{z}_i) \end{equation}\]Target은 \(\tilde{\textbf{x}}_i^p\)로 정규화되고 loss는 마스킹된 토큰과 뷰에 대한 MSE의 평균이다.
\[\begin{equation} \mathcal{L}_\textrm{MAE} = \frac{1}{V} \sum_{v=1}^V \frac{1}{\vert \mathcal{M}_i \vert} \sum_{p \in \mathcal{M}_i} \| \tilde{\textbf{x}}_i^p - \hat{\textbf{x}}_i^p \|_2 \end{equation}\]Contrastive Learning
본 논문에서는 DINOv3 기반의 student-teacher 방식을 채택하였다. Teacher는 student와 동일한 아키텍처(\(\Phi_\textrm{enc}\), \(\Phi_\textrm{cls}\))를 가지며, 학습 불가능하고, 파라미터는 student의 EMA이다. 각 뷰 $i$에 대해 학생과 교사의 [CLS] 임베딩과 logit은 다음과 같다.
\[\begin{equation} \textbf{c}_i^s = [\textrm{CLS}] (\Phi_\textrm{enc}(\textbf{x}_i)), \quad \textbf{c}_i^t = [\textrm{CLS}] (\Phi_\textrm{enc}^\textrm{ema}(\textbf{x}_i)) \\ \textbf{s}_i = \Phi_\textrm{cls} (\textbf{c}_i^s), \quad \textbf{t}_i = \Phi_\textrm{cls}^\textrm{ema} (\textbf{c}_i^t) \\ \textbf{p}_i = \textrm{softmax}(\textbf{s}_i), \quad \textbf{q}_i = \textrm{softmax}(\textbf{t}_i) \end{equation}\]$V$-뷰 (global + local)의 경우, 모든 cross-view global↔global 쌍과 global↔local 쌍으로 구성된 positive 쌍 집합 $\mathcal{S}$를 생성한다. Global crop에 대한 동일 뷰 매칭은 제외하며, local↔local 쌍은 건너뛴다. Contrastive objective는 positive 쌍들에 대한 teacher-to-student cross-entropy의 평균이다.
\[\begin{equation} \mathcal{L}_\textrm{CL} = \frac{1}{\vert \mathcal{S} \vert} \sum_{(i,j) \in \mathcal{S}} H (\textbf{q}_j, \textbf{p}_i), \quad H(\textbf{q}, \textbf{p}) = - \sum_{k=1}^K q_k \log p_k \end{equation}\]전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{MAE} + \lambda \mathcal{L}_\textrm{CL} \end{equation}\]Model Architecture
본 연구에서는 5B 파라미터까지 안정적으로 scaling 가능하도록 backbone을 수정하고, 입력 해상도를 1K에서 4K로 높이며, masked pretraining과의 호환성을 유지한다. 중간 block에는 grouped-query attention (GQA)을 사용하고, 초기 및 나중 block에는 표준 multi-head self-attention을 사용하였다. Feed-forward layer는 gated SwiGLU-FFN으로 대체하였다. 고해상도 학습의 안정성을 위해 attention 전에 query와 key를 정규화하는 QK-Norm을 적용하고, LayerNorm 대신 파라미터 효율이 높은 RMSNorm을 사용하였다.
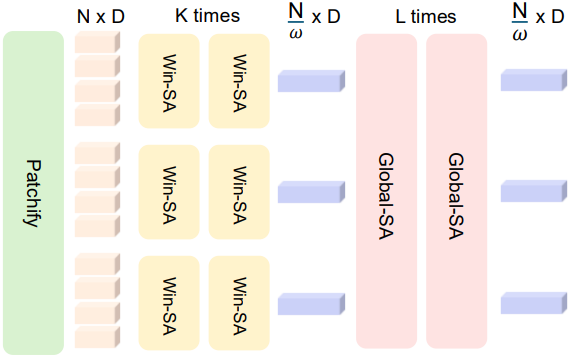
저자들은 4K 입력에 대응하기 위해 계층적 attention 디자인을 채택했다. $H \times W$ 이미지에서 생성된 $N = (H/p)(W/p)$개의 토큰에 대해 (패치 크기 $p$), 처음 $K$개 layer는 windowed self-attention을 적용하여 로컬 구조를 포착한다. 그런 다음, stride $\sqrt{w}$를 사용하여 2D 토큰 그리드를 다운샘플링하고, [CLS]-guided pooling을 통해 $N/ω$개의 토큰을 얻는다. 다음으로 $L$개의 layer에서 global attention을 적용한다.
사전 학습 동안, 로컬 단계 이후에 토큰 마스킹을 적용하고, dense prediction에서 sub-pixel 정밀도를 향상시키면서 semantic 손실을 방지하기 위해 2K 해상도에서 짧은 마스킹 복원 단계를 추가한다. 마지막으로, 기본 backbone의 경우 디코더 출력을 기존 0.5K에서 1K로, 4K backbone의 경우 2K로 증가시킨다.
Post-Traning
저자들은 사전 학습된 backbone을 변경하지 않고 경량화된 task별 head를 사용하여 포즈 추정, body-part segmentation, 깊이, 표면 normal, albedo라는 5가지 인간 중심 task에 대해 fine-tuning하였다.
Pose estimation
저자들은 입력 이미지로부터 키포인트 히트맵을 추정하기 위해 하향식 패러다임을 사용하였다. 키포인트 토폴로지는 얼굴(243개), 손(40개), 몸통, 하체를 커버하는 308개의 키포인트로 구성된 전신 스켈레톤이다. 캡처 스튜디오 주석에 더불어, 저자들은 10만 개의 고해상도 이미지를 새롭게 annotation하여 in-the-wild supervision을 추가하였다. Loss는 GT 히트맵에 대한 MSE이다.
\[\begin{equation} \mathcal{L}_\textrm{pose} = \sum_{u \in \Omega} \| \hat{\textbf{H}}(u) - \textbf{H}(u) \|_2 \end{equation}\]Body-part segmentation
본 논문에서 사용한 segmentation vocabulary는 29개의 클래스로 구성되어 있다. 이 vocabulary는 신체 부위별 supervision과 정확한 위치 파악을 목표로 한다. 저자들은 segmentation 레이블이 있는 2만 개의 실제 이미지로 supervision을 확대했다. Loss는 픽셀별 weighted cross-entropy와 Dice loss를 결합한 것이다.
Pointmap (depth) estimation
상대적인 깊이 대신, 카메라 프레임 내에서 픽셀별 3D pointmap \(\hat{\textbf{P}}(u) \in \mathbb{R}^3\)를 예측한다. Intrinsic을 모르면 metric scale이 모호하기 때문에, focal-normalized pointmap \(\bar{P} (u)\)와 스칼라 $s$를 예측하여 \(\hat{\textbf{P}}(u) = s \bar{\textbf{P}}(u)\)를 구성한다. 학습은 전적으로 고해상도 합성 에셋을 사용하며, loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{pointmap} = \sum_{u \in \Omega} \| \hat{\textbf{P}}(u) - \textbf{P}(u) \|_2 + \| \nabla \hat{\textbf{P}} (u) - \nabla \textbf{P} (u) \|_2 \end{equation}\]Normal estimation
동일한 고품질 합성 에셋을 사용하여 사람 픽셀에 대한 픽셀별 normal 벡터 \(\hat{\textbf{N}}(u) \in \mathbb{R}^3\)을 예측한다. 디코더는 아티팩트 없는 업샘플링을 위해 여러 PixelShuffle layer를 사용한다. Loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{normal} = \sum_{u \in \Omega} (1 - \hat{\textbf{N}}(u) \cdot \textbf{N}(u)) + \| \hat{\textbf{N}}(u) - \textbf{N}(u) \|_2 + \| \nabla \hat{\textbf{N}}(u) - \nabla \textbf{N} (u) \|_2 \end{equation}\]Albedo estimation
픽셀별 diffuse albedo \(\hat{\textbf{A}}(u) \in [0, 1]^3\)을 예측한다. 학습에는 높은 정확도의 합성 쌍 $\textbf{A}(u)$가 사용되며, 피부색과 옷의 조명 불변한 복원을 유도한다. Loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{albedo} = \sum_{u \in \Omega} \| \hat{\textbf{A}} (u) - \textbf{A} (u) \|_2 + \| \nabla \hat{\textbf{A}} (u) - \nabla \textbf{A} (u) \|_2 + \| \mu (\hat{\textbf{A}}) - \mu (\textbf{A}) \|_2 \end{equation}\]($\mu(\cdot)$는 RGB 평균)
Experiments
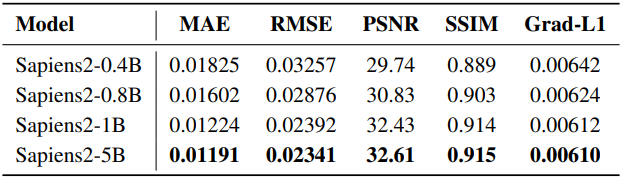
1. Pretraining Generalization: Dense Probing
다음은 dense probing 결과이다.
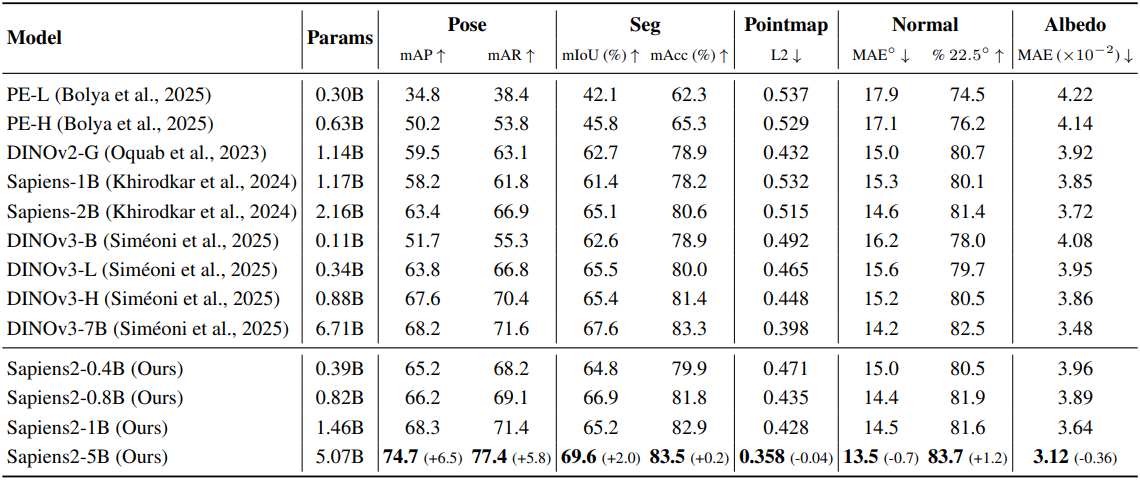
2. Comparison with State-of-the-Art Methods
다음은 포즈 추정에 대한 결과이다.
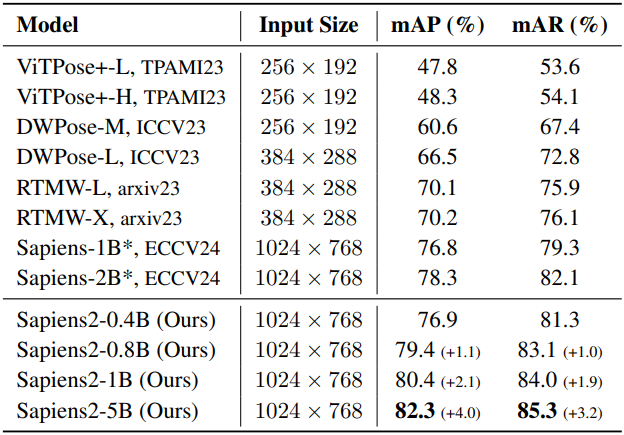
다음은 segmentation에 대한 결과이다.

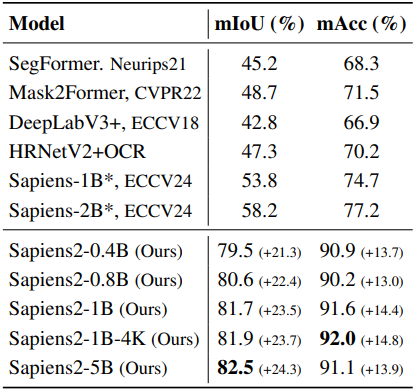
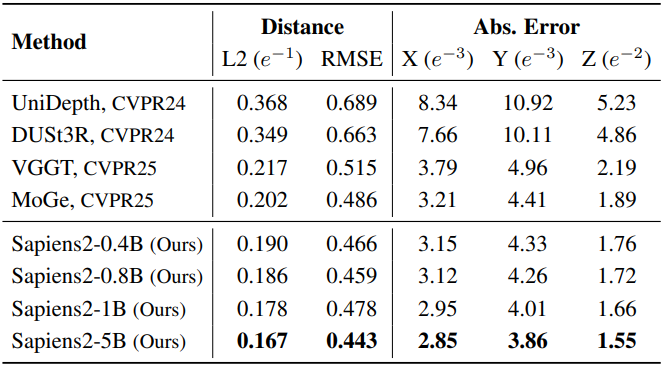
다음은 pointmap 평가 결과이다.
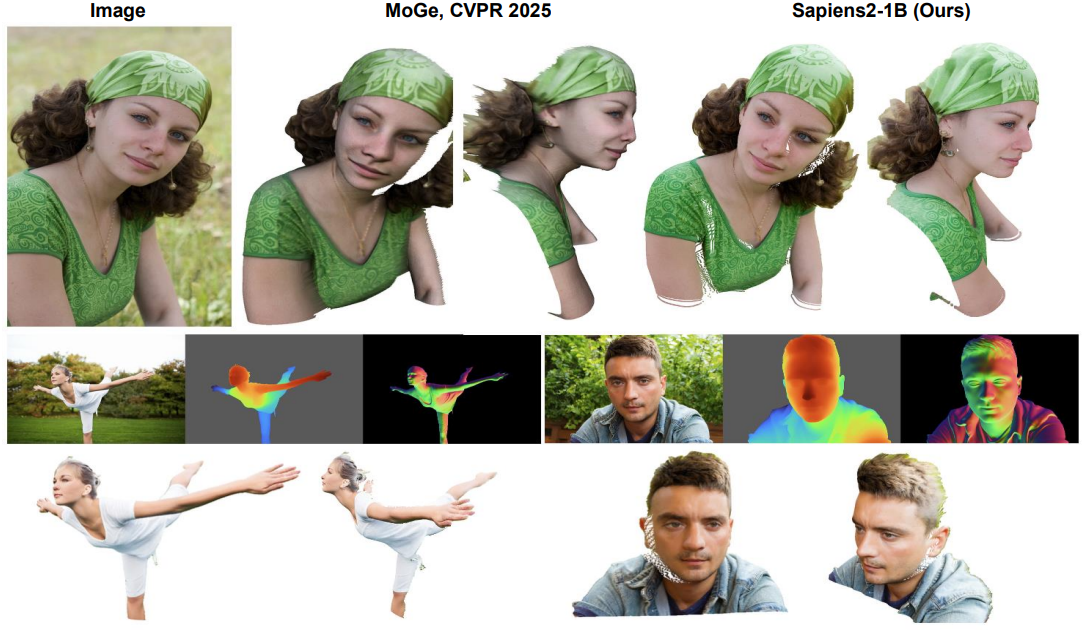
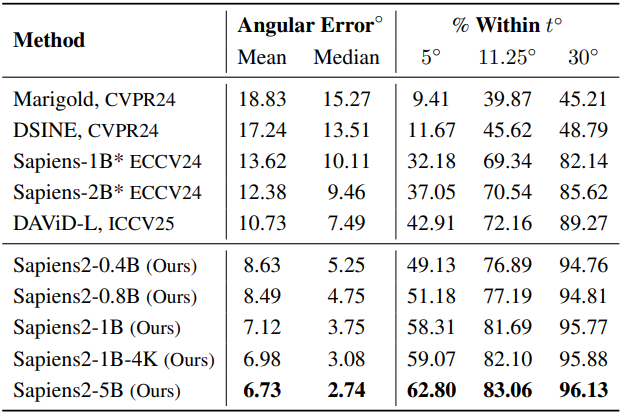
다음은 normal 추정에 대한 결과이다.

다음은 albedo 추정에 대한 결과이다.