[논문리뷰] Learning to (Learn at Test Time): RNNs with Expressive Hidden States
ICML 2025. [Paper] [Github]
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin
Stanford University | UC San Diego | UC Berkeley | Meta AI
5 Jul 2024

Introduction
가장 인기 있는 RNN 중 하나인 Mamba는 강력한 Transformer와 유사한 scalability를 보인다. 그러나 LSTM에서 지적했던 것과 동일한 문제가 Mamba에서도 나타난다. 시퀀스 후반부의 토큰은 더 많은 정보를 조건으로 하기 때문에 평균적으로 예측하기 쉬워야 하며, Transformer의 경우 각 토큰 인덱스에서의 평균 perplexity가 점차 감소한다. 반면 Mamba는 토큰 인덱스가 16k를 넘어가면 perplexity가 정체된다.
한편으로 Transformer 대비 RNN의 주요 장점은 선형 복잡도이다. 이러한 이점은 실제로 긴 컨텍스트에서만 실현된다. 하지만, 컨텍스트가 충분히 길어지면 Mamba와 같은 기존 RNN은 컨디셔닝된 추가 정보를 실제로 활용하는 데 어려움을 겪는다. 이는 self-attention과 달리 RNN layer는 컨텍스트를 고정된 크기의 hidden state로 압축해야 하기 때문이다. 업데이트 규칙은 수천, 혹은 수백만 개의 토큰 사이의 근본적인 구조와 관계를 파악해야 한다. 이러한 요구 사항은 본질적으로 어려운 과제이다. 본 논문에서는 self-supervised learning이 방대한 학습 데이터셋을 LLM과 같은 모델의 가중치로 압축할 수 있다는 점에 주목하였다. LLM은 학습 데이터 간의 의미적 연결에 대한 깊은 이해를 보여주는 경우가 많으며, 이는 압축에 필요한 바로 그 특성이다.
이러한 관찰에 착안하여, 저자들은 hidden state 자체를 머신러닝 모델로 만들고, 업데이트 규칙을 self-supervised learning의 step으로 구현했다. Hidden state가 테스트 시퀀스를 사용한 학습을 통해서도 업데이트되기 때문에, 이러한 RNN layer를 Test-Time Training (TTT) layer라고 부른다. 본 논문에서는 hidden state가 선형 모델인 TTT-Linear와 2-layer MLP인 TTT-MLP라는 두 가지 간단한 TTT layer를 소개한다. TTT layer는 RNN layer나 self-attention과 유사하게 모든 네트워크 아키텍처에 통합하고 end-to-end 최적화를 수행할 수 있다.
Method
1. TTT as updating a hidden state
파라미터 학습 과정은 방대한 학습 데이터셋을 모델의 가중치로 압축하는 것으로 볼 수 있다. 특히, self-supervised learning으로 학습된 모델은 학습 데이터에 내재된 구조와 관계를 포착할 수 있는데, 이는 압축에 필요한 바로 그 특성이다.
LLM 자체가 좋은 예시이다. Next-token prediction으로 학습된 LLM의 가중치는 인터넷에 존재하는 지식을 압축하여 저장한 형태로 볼 수 있다. LLM에 쿼리를 보내면 가중치에서 지식을 추출할 수 있다. 더 중요한 것은 LLM이 기존 지식 간의 의미적 연결을 깊이 이해하여 새로운 추론을 표현하는 능력을 보여준다는 점이다.
본 논문의 핵심 아이디어는 self-supervised learning을 사용하여 과거 컨텍스트 $x_1, \ldots, x_t$를 hidden state $s_t$로 압축하는 것이다. 여기서 컨텍스트는 레이블이 없는 데이터셋이고, state는 모델이다. 구체적으로, hidden state $s_t$는 이제 모델 $f$의 가중치인 $W_t$와 동일하며, 이 모델 $f$는 어떤 것이든 될 수 있다. 출력 규칙은 간단하다.
\[\begin{equation} z_t = f(x_t; W_t) \end{equation}\]직관적으로, 출력 토큰은 업데이트된 가중치 $W_t$를 사용하여 $f$가 $x_t$에 대해 수행한 예측이다. 업데이트 규칙은 self-supervised loss $\ell$에 대한 gradient descent step이다.
\[\begin{equation} W_t = W_{t-1} - \eta \nabla \ell (W_{t-1}; x_t) \end{equation}\]($\eta$는 learning rate)
압축 관점에서 볼 때, 어떤 입력을 기억하고 어떤 입력을 잊을지 결정해야 한다. $W$는 큰 gradient를 생성하는 입력을 기억한다. 직관적으로, 이는 $W$가 많은 것을 학습하게 만드는 입력이다.
$\ell$의 한 가지 선택은 $x_t$ 자체를 재구성하는 것이다. 학습 문제를 복잡하게 만들기 위해 먼저 $x_t$를 손상된 입력 \(\tilde{x}_t\)로 처리한 다음 최적화한다.
\[\begin{equation} \ell (W; x_t) = \| f (\tilde{x}_t; W) - x_t \|^2 \end{equation}\]$f$는 부분 정보 \(\tilde{x}_t\)로부터 $x_t$를 재구성하기 위해 $x_t$의 차원 간 상관관계를 발견해야 한다. Gradient descent는 $\ell$을 줄일 수는 있지만 0으로 줄일 수는 없다.
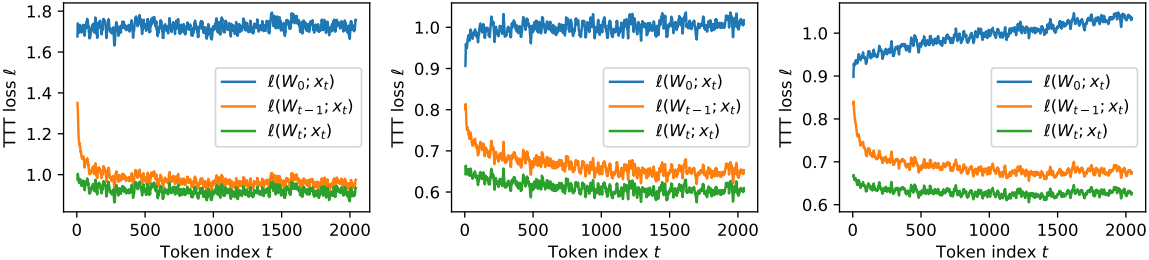
다른 RNN layer나 self-attention과 마찬가지로, 입력 시퀀스 $x_1, \ldots, x_T$를 출력 시퀀스 $z_1, \ldots, z_T$로 매핑하는 본 알고리즘은 위에서 설명한 hidden state, 업데이트 규칙, 출력 규칙을 사용하여 시퀀스 모델링 레이어의 forward pass로 프로그래밍할 수 있다. 테스트 시점에도 이 layer는 모든 입력 시퀀스에 대해 서로 다른 가중치 시퀀스 $W_1, \ldots, W_T$를 학습한다. 따라서 이를 Test-Time Training (TTT) layer라고 부른다.
2. Training a network with TTT layers
TTT layer의 forward pass에는 대응하는 backward pass가 있다. Forward pass는 미분 가능한 연산자 $\nabla \ell$로 표현할 수 있다. 개념적으로 $\nabla \ell$에 대한 backward pass는 gradient의 gradient를 구하는 것과 같다. 이는 meta-learning에서 잘 알려진 테크닉이다.
TTT layer는 RNN layer나 self-attention과 동일한 인터페이스를 가지므로, 일반적으로 이러한 시퀀스 모델링 레이어를 다수 포함하는 더 큰 네트워크 아키텍처에서 대체될 수 있다. TTT layer를 사용한 네트워크 학습은 Transformer와 같은 다른 언어 모델을 학습하는 방식과 동일하다. 동일한 데이터, 레시피, 그리고 next-token prediction과 같은 loss를 사용하여 네트워크의 나머지 부분의 파라미터를 최적화할 수 있다.
더 큰 네트워크 학습을 outer loop, 각 TTT layer 내의 $W$ 학습을 inner loop라고 부른다. 두 중첩 학습 문제 사이의 중요한 차이점은 inner loop의 gradient $\nabla \ell$은 함수 $f$의 파라미터 $W$에 대해 계산되는 반면, outer loop의 gradient는 네트워크의 나머지 부분의 파라미터 \(\theta_\textrm{rest}\)에 대해 계산된다는 점이다.
3. Learning a self-supervised task for TTT
TTT에서 가장 중요한 부분은 self-supervised task라고 할 수 있는데, 이는 $W$가 테스트 시퀀스로부터 어떤 feature를 학습할지를 결정하기 때문이다. TTT의 최종 목표는 $z_t = f(x_t; W_t)$가 언어 모델링에서 좋은 성능을 내도록 하는 것이다. 저자들은 next-token prediction을 위해 self-supervised task를 직접 최적화하는 end-to-end 접근 방식을 취하였다.
구체적으로, outer loop의 일부로 self-supervised task를 수행한다. 이 task를 학습 가능하게 만들기 위해 몇 가지 outer loop 파라미터를 추가한다. 앞의 설명에서 $x_t$에서 \(\tilde{x}_t\)를 생성하는 방법을 구체적으로 명시하지 않았다. 한 가지 방법은 low-rank projection \(\tilde{x}_t = \theta_K x_t\)로 만드는 것이다. 여기서 \(\theta_K\)는 학습 가능한 행렬이며, \(\theta_K x_t\)를 training view라고 부른다.
또한, $x_t$에 있는 모든 정보가 기억할 가치가 있는 것은 아닐 수 있으므로 재구성 레이블은 $x_t$ 대신 다른 low-rank projection $\theta_V x_t$가 될 수 있다. 여기서 \(\theta_V\)도 학습 가능한 행렬이며, \(\theta_V x_t\)를 label view라고 부른다.
요약하면, self-supervised loss는 다음과 같다.
\[\begin{equation} \ell (W; x_t) = \| f(\theta_K x_t; W) - \theta_V x_t \|^2 \end{equation}\]Inner loop에서는 $W$만 최적화되므로 $\theta$들은 이 loss의 hyperparameter이다. Outer loop에서는 \(\theta_K\), \(\theta_V\), \(\theta_Q\)가 \(\theta_\textrm{rest}\)와 함께 최적화되며, $W$는 단순히 hidden state일 뿐 파라미터가 아니다. 아래의 PyTorch 스타일 코드는 이러한 차이점을 보여주는데, \(\theta_K\)와 \(\theta_V\)는 self-attention과 유사하게 TTT layer의 파라미터로 구현되어 있다.

마지막으로, training view \(\theta_K x_t\)는 $x_t$보다 차원 수가 적으므로 기존의 출력 규칙을 더 이상 사용할 수 없다. 가장 간단한 해결책은 test view \(\theta_Q x_t\)를 생성하고 출력 규칙을 다음과 같이 변경하는 것이다.
이 솔루션에는 추가적인 이점이 있다. Training view와 label view는 $x_t$에 포함된 정보를 $W_t$로 압축하여 시간 경과에 따라 전파하는 방식을 지정한다. Test view는 현재 출력 토큰 $z_t$에 매핑되어 네트워크 레이어를 통해 전파되는, 잠재적으로 다른 정보를 지정하므로 self-supervised task에 더 큰 유연성을 제공한다.
4. Parallelization with mini-batch TTT
지금까지의 단순한 TTT layer는 FLOPs 측면에서 이미 효율적이다. 그러나 업데이트 규칙 \(W_t = W_{t-1} - \eta \nabla \ell (W_{t-1}; x_t)\)는 병렬화할 수 없다. $W_t$가 두 곳에서 $W_{t−1}$에 의존하기 때문이다. $\nabla \ell$에 대부분의 계산이 포함되어 있으므로, 저자들은 이 부분을 병렬화하는 데 집중하엿다.
Gradient descent (GD)에는 여러 변형이 있다. GD의 일반적인 업데이트 규칙은 다음과 같이 표현할 수 있다.
\[\begin{equation} W_t = W_{t-1} - \eta G_t = W_0 - \eta \sum_{s=1}^t G_s \end{equation}\]($G_t$는 descent 방향)
$t = 1, \ldots, T$에 대해 $G_t$를 계산한 후에는 누적합을 이용하여 모든 $W_t$를 얻을 수 있다. Online gradient descent로 알려진 단순 업데이트 규칙은 $G_t = \nabla \ell (W_{t−1}; x_t)$를 사용한다.
$t = 1, \ldots, T$에 대한 $G_t$를 병렬화하기 위해, 모든 $t$에 대해 $W_0$에 대한 gradient를 취할 수 있다. 이는 batch gradient descent $G_t = \nabla \ell (W_0; x_t)$이다. 그러나 batch gradient descent에서는 $W_t$가 $W_0$에서 실질적으로 한 step의 gradient만큼 떨어져 있는 반면, online gradient descent에서는 $W_t$가 $W_0$에서 $t$ step만큼 떨어져 있다. 따라서 batch gradient descent는 유효 탐색 공간이 더 작아 언어 모델링 성능 저하로 이어질 수 있다.
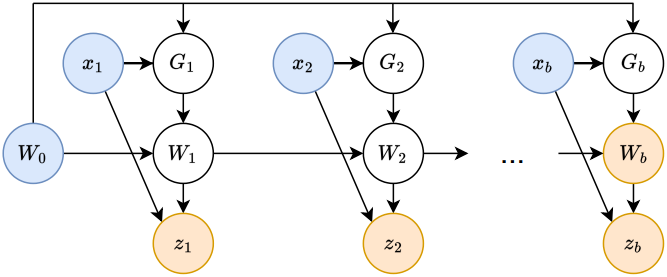
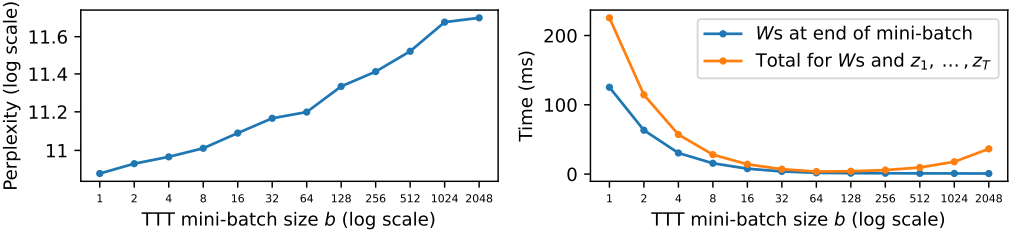
본 논문에서는 mini-batch gradient descent를 제안하였다. TTT batch size를 $b$라 하자. \(G_t = \nabla \ell (W_{t^\prime}; x_t)\)를 사용하는데, 여기서 $t^\prime = t − \textrm{mod}(t,b)$는 이전 mini-batch의 마지막 timestep이다. 이를 통해 $b$개의 gradient 계산을 동시에 병렬화할 수 있다. 경험적으로, $b$는 속도와 품질 사이의 균형을 조절한다. 본 논문에서는 $b = 16$으로 설정했다.
요약하자면, $s < t$인 경우 $W_s$에서 $W_t$로 정보를 전달하는 두 가지 잠재적인 채널이 있다. 바로 누적합(cumsum)과 gradient 연산자이다. 누적합은 항상 활성화되어 있지만, 기울기 채널은 $W_s$가 이전 mini-batch에서 가져온 값일 때만 활성화된다. Gradient descent의 다양한 변형은 gradient 채널, 즉 descent 방향 $G_t$에만 영향을 미치며, 구체적으로 어떤 $W$에서 gradient를 취하는지에 따라 달라진다. 그러나 업데이트 규칙의 autoregressive한 특성 때문에 descent step $W_t = W_{t−1} - \eta G_t$는 항상 $W_{t−1}$에서 시작하며, 이는 $G_t$ 선택과는 무관하다.
5. Dual form
최신 가속기는 행렬 곱셈(matmul)에 특화되어 있다. 이러한 matmul 연산이 충분하지 않으면 TensorCore는 유휴 상태가 되어 가속기의 잠재력 대부분이 발휘되지 못한다.
불행히도, mini-batch를 사용하더라도 지금까지의 TTT layer는 여전히 처리량이 매우 적다. 가장 간단한 경우인 $\ell$, 즉 \(\theta_K = \theta_V = \theta_Q = I\)인 경우를 생각해 보자. 또한, $f$를 선형 모델로 가정하자. 시간 $t$에서의 loss는 다음과 같다.
\[\begin{equation} \ell (W_0; x_t) = \| f(x_t; W_0) - x_t \|^2 = \| W_0 x_t - x_t \|^2 \end{equation}\]다음과 같은 계산을 병렬화할 수 있다.
\[\begin{equation} G_t = \nabla \ell (W_0; x_t) = 2 (W_0 x_t - x_t) x_t^\top, \quad \textrm{where} \; t = 1, \ldots, b \end{equation}\]하지만 단일 행렬 곱셈으로 모든 $b$개의 $G_t$를 계산할 수는 없다. 대신, 하나씩 계산하기 위해 $b$개의 외적 연산이 필요하다. 또한, 각 $x_t \in \mathbb{R}^d$에 대해 $G_t$는 $d \times d$ 행렬이므로, 큰 $d$에 대해 $x_t$보다 훨씬 더 많은 메모리 사용량과 I/O 비용을 발생시킨다.
$W_b$를 계산하고 출력 토큰 $z_1, \ldots, z_b$를 생성할 수 있다면 $G_1, \ldots, G_b$를 실제로 구현할 필요는 없다. 단순화된 TTT-Linear 사례를 생각해보자. $X = [x_1, \ldots, x_b]$라고 하면 다음과 같이 $W_b$를 계산할 수 있다.
\[\begin{equation} W_b = W_0 - \eta \sum_{t=1}^b G_t = W_0 - 2 \eta \sum_{t=1}^b (W_0 x_t - x_t) x_t^\top = W_0 - 2 \eta (W_0 X - X) X^\top \end{equation}\]따라서 $W_b$는 matmul을 사용하여 편리하게 계산할 수 있다. $Z = [z_1, \ldots, z_b]$를 계산하기 위해 $z_t$를 계산하면 다음과 같다.
\[\begin{equation} z_t = f (x_t; W_t) = W_t x_t = \left( W_0 - \eta \sum_{s=1}^t G_t \right) x_t = W_0 x_t - 2 \eta \sum_{s=1}^t (W_0 x_s - x_s) x_s^\top x_t \end{equation}\]\(\delta_t = \sum_{s=1}^t (W_0 x_s - x_s) x_s^\top\)와 \(\Delta = [\delta_1, \ldots, \delta_b]\)로 나타내면, 다음과 같이 유도할 수 있다.
\[\begin{equation} \Delta = (W_0 X - X) \textrm{mask} (X^\top X) \end{equation}\]($\textrm{mask}$는 0으로 채워진 상삼각 마스크)
$W_0 X−X$ 항은 $W_b$ 계산에서 재사용할 수 있다. 이제 $\Delta$ 또한 matmul을 사용하여 편리하게 계산할 수 있다. $\Delta$를 $z_t$ 식에 대입하면 다음과 같이 정리된다.
\[\begin{equation} Z = W_0 X − 2 \eta \Delta \end{equation}\]이 절차를 $W$들과 $G$들이 명시적으로 구체화된 primal form과 대조하여 dual form이라고 부른다. $f$가 non-linear layer를 가진 신경망인 경우에도 dual form이 여전히 유효하다.
TTT mini-batch 내에서 primal form의 시간 복잡도는 $O(b \times d^2)$이다. Dual form의 시간 복잡도는 $W_b$ 계산에만 $O(b \times d^2)$이고, $z_1, \ldots, z_b$ 계산에 추가로 $O(b^2 \times d)$가 소요된다. Dual form은 primal form에 비해 하드웨어 활용도를 높이기 위해 이론적 복잡도를 희생한다. 실제로 $d$는 보통 수백 정도이고 $b$는 16으로 설정된다. 결과적으로 $z_1, \ldots, z_b$ 계산에 소요되는 실제 시간은 상대적으로 짧다. JAX 구현에서 dual form을 사용한 학습은 primal form을 사용한 학습보다 5배 이상 빠르다.
6. Implementation details
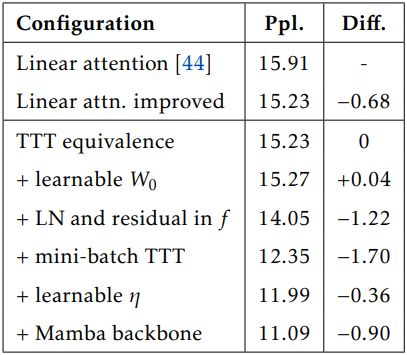
$f$의 선택
본 논문에서는 TTT layer의 두 가지 버전인 TTT-Linear와 TTT-MLP를 제안하였다. 이 두 버전은 $f$만 차이가 있다. TTT-Linear의 경우, square matrix $W$를 사용하여 $f = Wx$로 구현한다. TTT-MLP의 경우, $f$는 Transformer의 MLP와 유사한 2-layer MLP로 구성된다. 구체적으로, hidden dimension은 입력 차원의 4배이며, 그 뒤에 GELU activation이 이어진다. TTT 과정에서 안정성을 높이기 위해, $f$는 항상 Layer Normalization (LN)과 residual connection을 포함한다.
학습 가능한 $W_0$
$W_0$는 모든 시퀀스에서 공유되지만, 이후 가중치 $W_1, \ldots, W_T$는 각 입력 시퀀스마다 다르다. $W_0$를 0으로 설정하는 대신, outer loop의 일부로 학습시킬 수 있다 (\(\theta_\textrm{init} = W_0\)). 실제로 \(\theta_\textrm{init}\)는 입력과 출력 모두 저차원이므로 재구성 뷰 \(\theta_K\), \(\theta_Q\), \(\theta_V\)에 비해 무시할 수 있을 정도로 적은 양의 파라미터를 추가한다. 실험적으로 $W_0$를 학습시키면 학습 안정성이 크게 향상된다.
학습 가능한 $\eta$
Learning rate는 일반적으로 gradient descent에서 가장 중요한 hyperparameter이므로, inner loop의 learning rate $\eta$를 outer loop의 일부로 학습시킨다. 추가적인 유연성을 확보하기 위해 $\eta$를 입력 토큰의 함수로 설정했다.
\[\begin{equation} \eta (x) = \eta_\textrm{base} \sigma (\theta_\textrm{lr} \cdot x) \end{equation}\](\(\theta_\textrm{lr}\)은 outer loop 파라미터, $\sigma$는 sigmoid 함수, \(\eta_\textrm{base}\)는 기본 learning rate)
\(\eta_\textrm{base}\)는 TTT-Linear의 경우 1, TTT-MLP의 경우 0.1로 설정했다. 또는, $\eta (x)$는 $\nabla \ell$에 대한 gate로도 해석할 수 있다.
Backbone 아키텍처
RNN layer를 더 큰 아키텍처에 통합하는 가장 깔끔한 방법은 Transformer에서 self-attention을 바로 대체하는 것이다. 그러나 Mamba와 Griffin과 같은 기존 RNN은 모두 Transformer와는 다른 backbone을 사용한다. 특히, 이들의 backbone에는 RNN layer 앞에 temporal convolution이 포함되어 있어 시간에 따른 로컬 정보를 수집하는 데 도움이 될 수 있다.
Experiments
1. Short context: the Pile
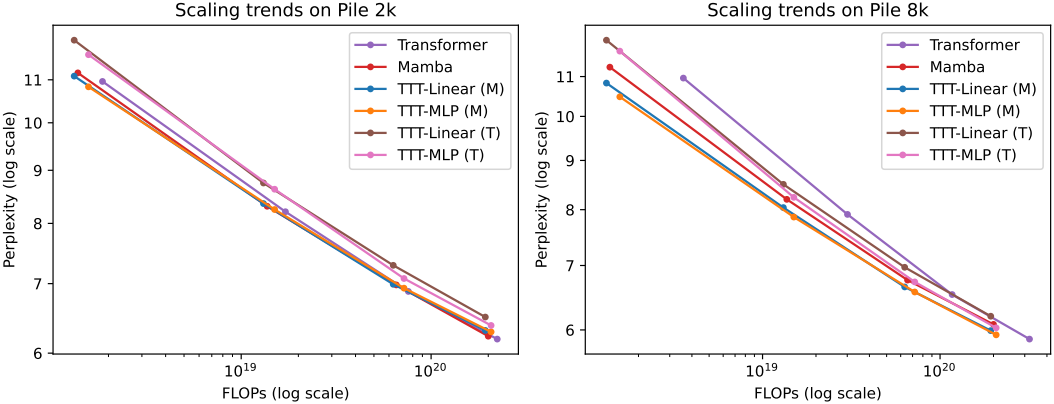
2. Long context: Books
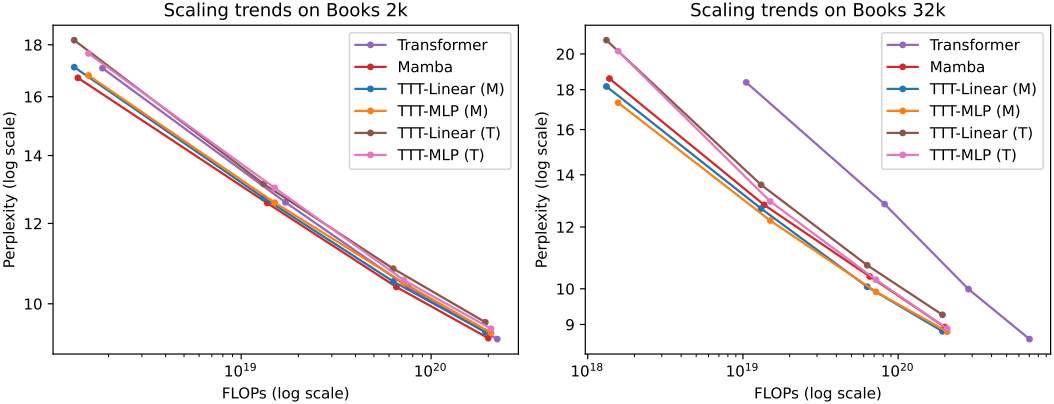
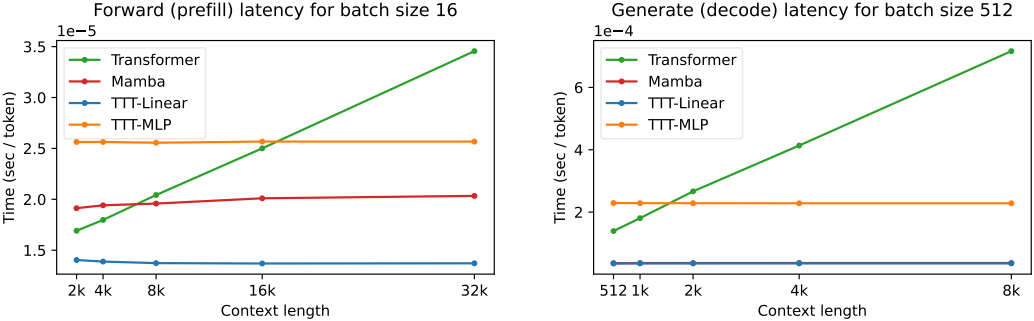
3. Wall-clock time