[논문리뷰] Learning to Orchestrate Agents in Natural Language with the Conductor
ICLR 2026. [Paper] [Page]
Stefan Nielsen, Edoardo Cetin, Peter Schwendeman, Qi Sun, Jinglue Xu, Yujin Tang
Sakana AI | University of Michigan | Institute of Science Tokyo
4 Dec 2025
Introduction
LLM의 잠재력을 최대한 활용하는 것은 숙련된 사용자에게조차 여전히 어려운 과제이며, 상용 AI 제품에서는 수동으로 설계된 agent workflow가 핵심 구성 요소로 사용되고 있는 반면, 효과적인 프롬프트 및 self-reflection 전략은 현재 연구의 핵심 초점이다. 더욱이, 다양한 모델은 특정 데이터셋과 특정 도메인에 특화되도록 fine-tuning되며, 모든 task에 보편적으로 최적인 하나의 언어 모델은 존재하지 않는다.
이러한 고려 사항을 바탕으로, 본 논문에서는 강화 학습(RL)으로 학습된 새로운 유형의 추론 모델인 RL Conductor를 소개한다. RL Conductor는 어려운 문제를 동적으로 분할하고, 목표에 맞는 subtask를 위임하며, LLM worker agent 집합을 위한 통신 토폴로지를 설계한다. 본 모델 자체는 workflow step의 순서를 출력하는 LLM이며, 각 단계는 전체 task의 특정 측면에 초점을 맞춘 자연어 명령, 해당 명령을 수신하는 할당된 agent, 그리고 각 agent가 자신의 역할을 수행하는 동안 다른 agent에게 보이는 visibility로 정의된다. 이러한 구성을 통해 RL Conductor는 프롬프트 엔지니어링, 정제, 심지어 메타 프롬프트 최적화와 같은 공통 전략을 통해 각 입력 문제에 맞게 완전히 유연한 agent workflow를 구성할 수 있으며, 이러한 전략은 end-to-end reward 최대화에서 자연스럽게 도출된다.
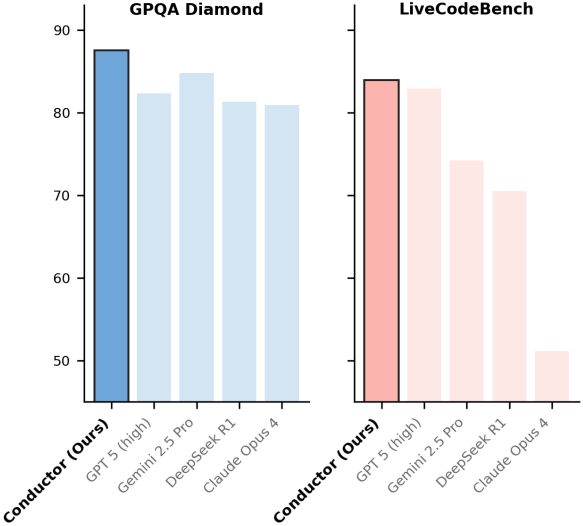
7B Conductor는 강력한 worker agent들의 상호 보완적인 능력을 효과적으로 활용하여 LiveCodeBench 및 GPQA Diamond와 같은 까다로운 추론 벤치마크에서 SOTA 결과를 달성하였다. Conductor의 성능은 기존의 worker agent의 self-reflection 은 물론, 훨씬 더 많은 agent 호출을 사용하는 비용이 많이 드는 기존의 multi-agent collaboration 모델보다 훨씬 뛰어나다.
Method
본 논문에서는 훨씬 더 크고 강력한 LLM agent 집합을 프롬프트 엔지니어링하고 조정할 수 있도록 Conductor 언어 모델을 학습시키기 위한 새로운 RL 프레임워크를 설계하였다. Conductor는 입력 task를 분할하고, 자연어로 subtask를 할당하며, agent의 상호 보완적인 기능을 최대한 활용하기 위한 통신 전략을 정의하는 완전한 agent workflow를 출력한다.
1. Framing agent coordination in natural language
The Conductor task
Conductor의 목표는 입력 질문 $q_i$에 특화된 다양한 agent workflow를 설계함으로써 task를 간접적으로 해결하는 것이다.
각 agent workflow는 workflow step들의 시퀀스로 정의되며, 최종 출력은 실제 Conductor 응답 $o_i$로 반환된다. 각 step은 자연어 subtask를 나타내는 문자열, 해당 subtask를 수행하는 할당된 worker agent에 해당하는 정수 ID, 그리고 이전 step의 subtask를 worker의 컨텍스트에 포함할지 여부를 나타내는 access list 인덱스를 지정한다.
각 agent workflow에 대한 정보는 Conductor가 chain-of-thought을 거쳐 제공한 응답에서 동일한 개수의 항목을 가진 3개의 간단한 Python 리스트로 파싱된다. 아래는 이러한 출력 구조의 예시이다.

Conductor는 먼저 agent 2에게 알고리즘을 설계하도록 요청한 다음, agent 0에게 agent 2의 이전 응답을 컨텍스트로 사용하여 파이썬으로 구현하도록 요청하는 방식으로 agent workflow를 설계한다. 학습 속도를 높이고 프레임워크를 임의의 모델과 호환되도록 하기 위해, 시스템 프롬프트에 Conductor에게 예상 출력 형식을 포함한 예시와 함께 자세한 instruction을 제공한다.
이러한 설계를 통해 Conductor는 subtask와 worker 간의 통신 전략을 자유롭게 구성할 수 있으며, 순차적인 체인형 토폴로지부터 병렬 처리가 가능한 임의의 트리 구조 방식까지 다양한 agent workflow를 지정할 수 있어, 고도로 전문화된 agent들의 개별적인 강점과 시너지를 활용할 수 있다.
Workflow execution and learning dynamics
Conductor에서 출력되는 각 agent workflow는 지정된 worker agent에게 할당된 자연어 subtask를 제시함으로써 순차적으로 실행된다. 각 workflow step에서 worker의 컨텍스트에는 access list에 정의된 이전 subtask 및 해당 응답 순서가 포함되며, 이는 대화 템플릿의 이전 메시지 형태로 제공된다. 기존 RL 프레임워크와 유사하게, Conductor 모델의 각 응답에 대한 reward $r_i$는 두 가지 점진적 조건에 따라 결정된다.
- 형식 조건: Subtask, worker ID, access list의 Python 리스트를 파싱할 수 없는 응답의 경우 $r_i = 0$으로 설정한다.
- 정확성 조건: 형식이 잘 갖춰진 agent workflow $o_i$를 실행한 최종 출력이 솔루션 $s_i$와 일치하면 $r_i = 1$로 설정하고, 그렇지 않으면 $r_i = 0.5$로 설정한다.
Conductor reward를 활용한 end-to-end 학습은 본질적으로 모든 RL 알고리즘과 호환되지만, 구체적으로 GRPO를 사용한다. 저자들은 이 간단한 방식으로 Conductor를 학습시키면서, 각 worker의 강점에 맞춰 문제 분할 및 프롬프트 기반 subtask가 생성되는 것을 관찰했다. 또한, 독립적인 시도와 최종 토론을 결합한 통신 전략도 개발되었다. 이러한 Conductor의 행동은 모델이 훨씬 더 큰 규모의 worker들을 빠르게 능가하게 하여, 수동으로 설계된 multi-agent 파이프라인을 훨씬 뛰어넘는 SOTA 성능을 달성하게 한다.
2. Extending the RL Conductor
Adaptive worker selection
사용 가능한 worker 풀의 변화에 강인하게 대응하기 위해, 본 프레임워크는 커스터마이징 가능한 모델들의 부분집합에서 작동하도록 확장되었다. 이를 위해 사전 학습된 Conductor를 fine-tuning하여, 각 질문에 대해 전체 $n$개 worker 풀에서 랜덤 샘플링된 $k$개 모델 부분집합으로 제한하고 입력 instruction을 그에 따라 수정한다. 학습 후, 이러한 설계는 Conductor가 $k \le n$개의 특정 모델 부분집합에서 일반화하고 강력한 성능을 발휘하도록 하여, 특정 제약 조건 및 비용 선호도에 맞춰 작동할 수 있도록 한다. Conductor는 임의의 agent 집합의 다양한 시너지 효과에 따라 문제 해결 방식을 재구성하는 방법을 학습한다.
Recursive topologies and test-time scaling
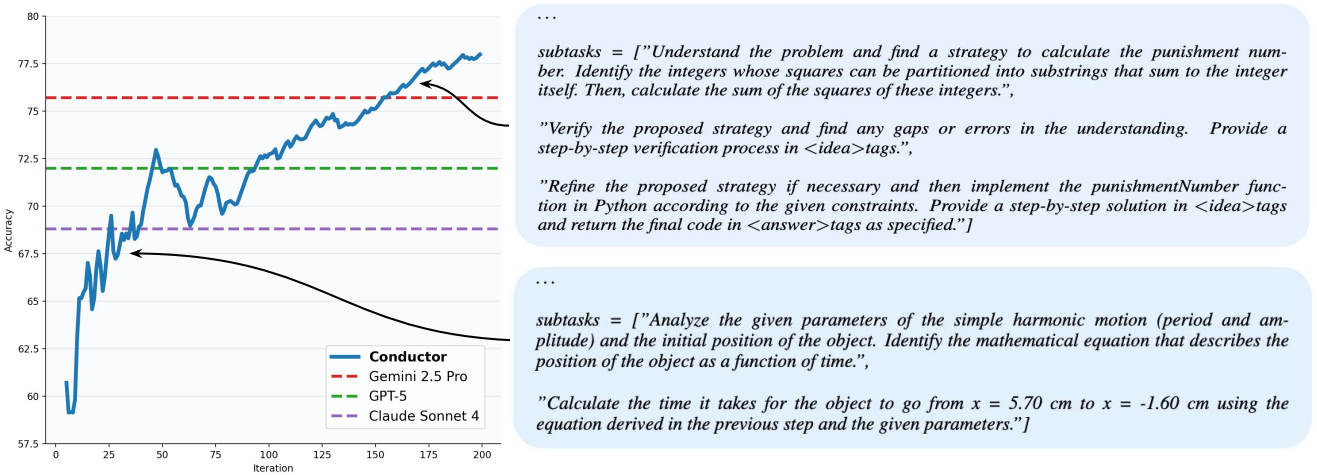
저자들은 recursive agent workflow를 도입하여 Conductor가 자신의 능력을 활용해 다른 worker agent를 보완할 수 있도록 확장하였다. 각 내부 재귀 호출 시, Conductor는 호출이 시작된 부모 agent의 출력과 이전 agent의 응답을 추가 입력으로 제공받는다. 이러한 컨텍스트를 바탕으로 Conductor는 새로운 agent workflow를 시작하거나 최종 subtask 솔루션을 사용자에게 직접 반환하여 루프를 종료할 수 있다. 초기 root Conductor 호출 이후 재귀 호출은 지정된 최대 횟수까지만 허용하여 무한 루프를 방지한다.
사전 학습된 Conductor 모델에서 재귀 기능을 활성화하려면, 각 batch에서 절반의 샘플에 대해 한 번의 재귀 호출을 수동으로 실행하면서 동일한 RL 알고리즘으로 fine-tuning하면 된다. 학습 후, inference 중에 재귀 호출의 최대 횟수를 적응적으로 증가시켜 새로운 형태의 test-time scaling을 효과적으로 도입할 수 있으며, 무한한 chain-of-thought을 넘어 재귀를 조정 가능한 컴퓨팅 축으로 활용한다.
Experiments
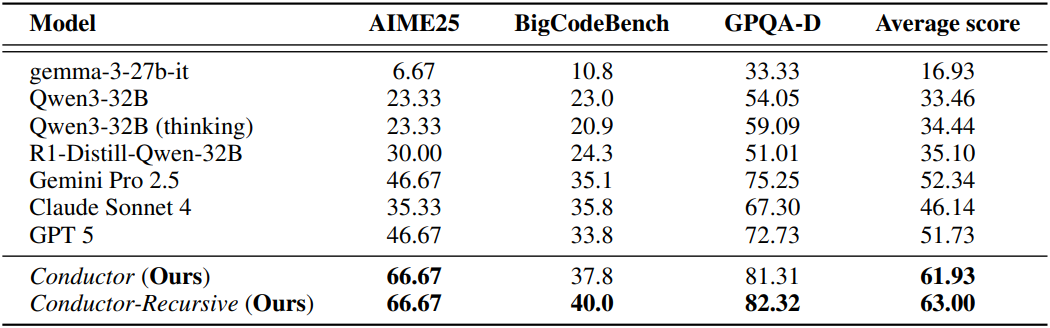
1. Elevating llms to a new frontier with the Conductor
다음은 다양한 추론 벤치마크에서 제약 없이 비교한 결과이다.

2. Controlled large-scale evaluation
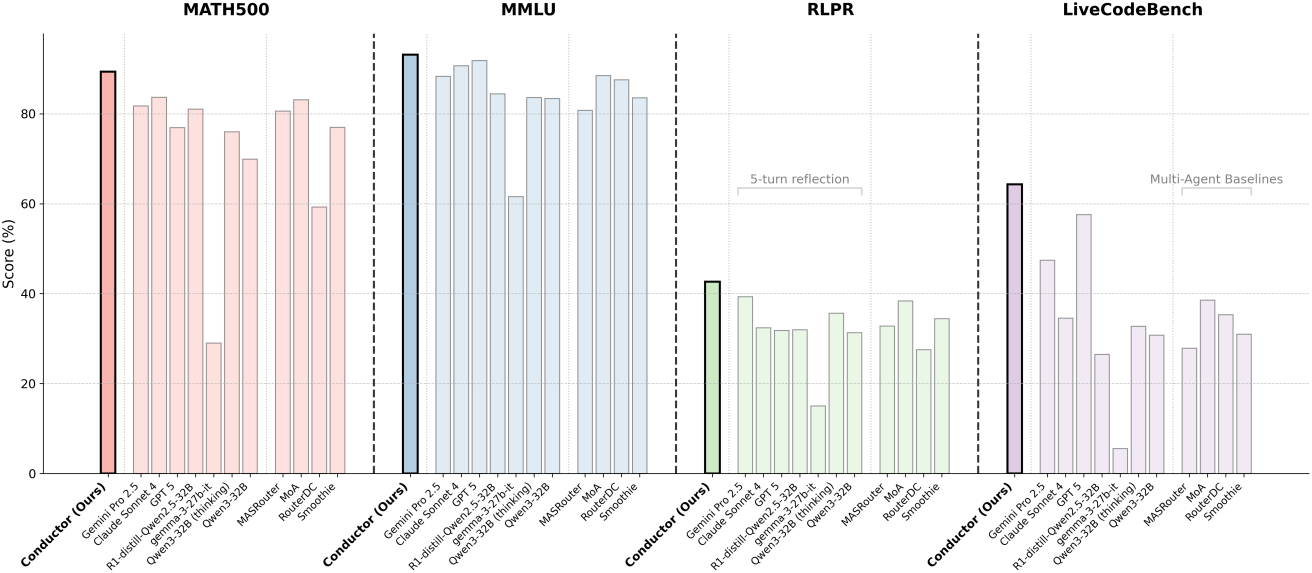
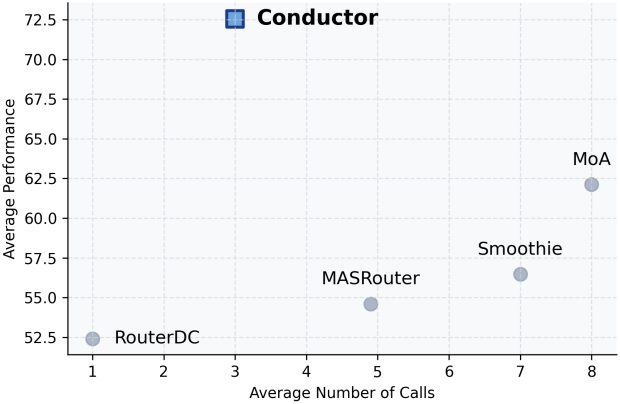
다음은 multi-agent 방법들 및 5-turn reflection agent들과 비교한 결과이다.
3. User-customization and test-time recursive scaling
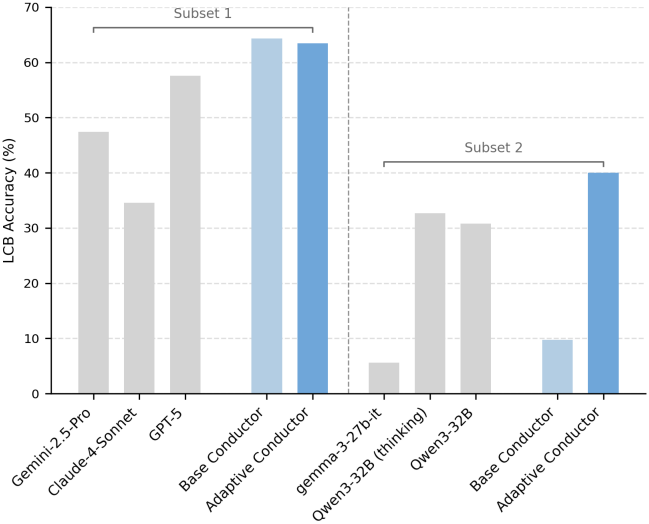
다음은 랜덤한 worker 풀에 대해 fine-tuning한 결과이다.
다음은 recursive agent workflow에 대한 결과이다.
4. Analyzing and ablating the properties of an effective Conductor
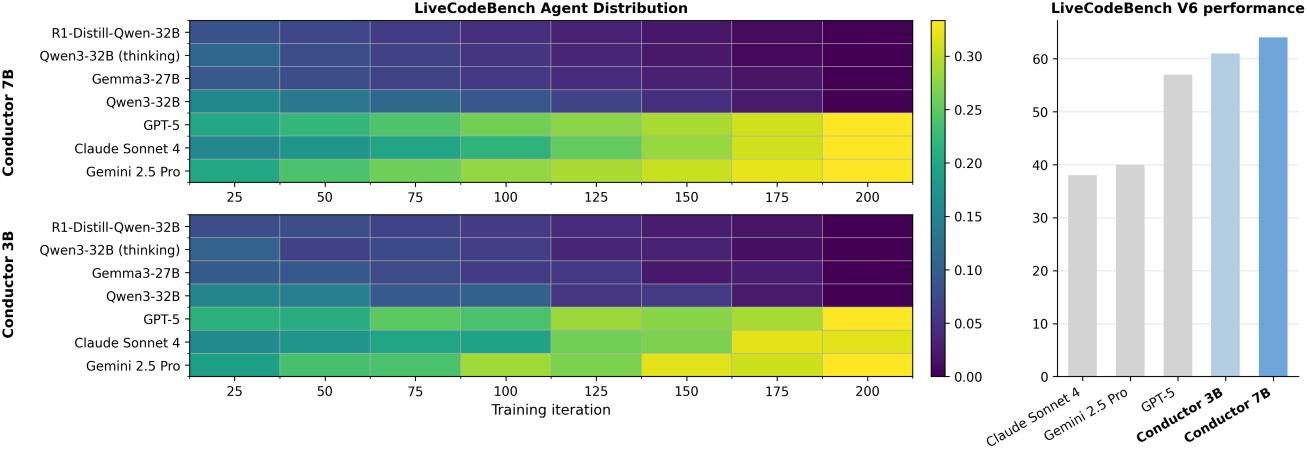
다음은 7B Conductor와 3B Conductor를 비교한 결과이다.
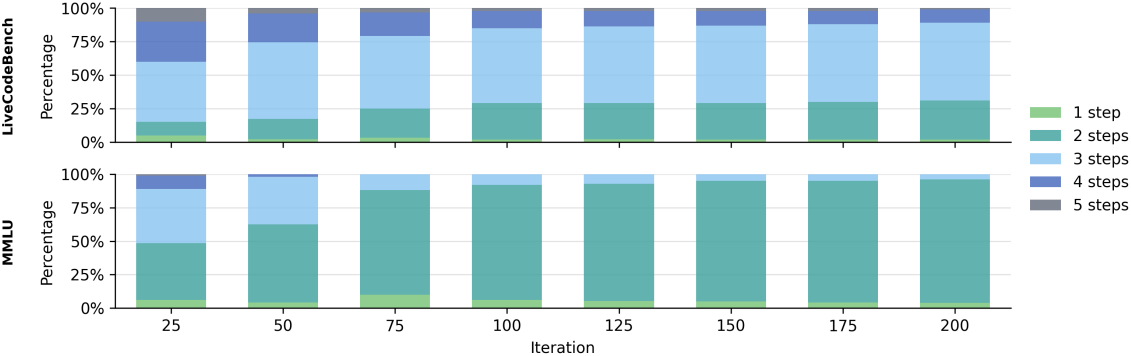
다음은 Conductor의 task 적응력을 나타낸 그래프이다. MMLU와 같이 쉬운 task에서는 2개의 agent를 사용하지만, LiveCodeBench와 같은 복잡한 task에서는 3~4개의 agent를 사용한다.