[논문리뷰] Weak-to-Strong Diffusion with Reflection
ICLR 2026. [Paper] [Github]
Lichen Bai, Masashi Sugiyama, Zeke Xie
HKUST | RIKEN AIP | The University of Tokyo
1 Feb 2025

Introduction
Diffusion model에서 학습된 데이터 분포와 실제 데이터 분포 간의 정렬을 향상시키기 위해, 다양한 전략을 통해 추정된 밀도와 실제 밀도 간의 기울기 정렬을 개선하는 데 광범위한 연구가 집중되어 왔다. 그러나 현실적인 제약으로 인해 기존 diffusion model은 필연적으로 기울기 추정 오차가 존재하며, 이는 학습된 데이터 분포와 실제 데이터 분포 간의 차이를 초래한다. 이러한 차이의 크기에 따라 “강한” diffusion model과 “약한” diffusion model로 분류할 수 있다. 특히, 실제 데이터 분포에 직접 접근할 수 없기 때문에 이러한 차이를 측정하고 효과적으로 줄이는 직접적인 방법론을 확립하기는 어렵다.
본 논문에서는 강한 모델과 약한 모델 사이의 차이를 이용하여 이상적인 모델과 강한 모델 사이의 차이를 경험적으로 해소할 수 있음을 보여준다. 그리고 약한 차이와 강한 차이를 이용하여 강한 차이와 이상적인 차이를 연결하는 새로운 프레임워크인 Weak-to-Strong Diffusion (W2SD)을 제안하였다. 약한 차이와 강한 차이를 기반으로 denoising과 inversion 연산을 번갈아 수행하는 reflective 연산을 통합함으로써, W2SD가 latent를 샘플링 궤적을 따라 가이드하여 실제 데이터 분포 영역으로 효과적으로 이끌 수 있다.
Preliminaries
랜덤 Gaussian noise $z_t$가 주어졌을 때, diffusion model의 forward process를
\[\begin{equation} x_t = x_{t - \Delta t} + \sigma^t \sqrt{\Delta t} z_t, \quad t \in [0, 1] \end{equation}\]로 나타낸다. 실제 데이터 분포의 GT 밀도를 \(p_0^\textrm{gt}\)로 나타내고, 시간 $t$에서 noise가 추가된 후의 밀도는 \(p_t^\textrm{gt}\)로 표현된다.
DDIM에 따르면, 상미분 방정식 (ODE) 과정을 통해 noise가 추가된 데이터 $x_t$로부터 denoising된 결과 \(x_{t - \Delta t}\)를 얻을 수 있다.
\[\begin{aligned} x_t &= \mathcal{M} (x_t, t) \\ &= x_t + \sigma^{2t} s_\theta (x_t, t) \Delta t \end{aligned}\](\(s_\theta\)는 score network)
마찬가지로, 위 식을 역으로 하면 \(x_{t - \Delta t}\)를 새로운 \(\tilde{x}_t\)로 다시 변환할 수 있다.
\[\begin{aligned} \tilde{x}_t &= \mathcal{M}_\textrm{inv} (x_{t - \Delta t}, t) \\ &= x_{t - \Delta t} - \sigma^{2t} s_\theta (x_t, t) \Delta t \\ &\approx x_{t - \Delta t} - \sigma^{2t} s_\theta (x_t, t) \Delta t \end{aligned}\]실제로 inversion process를 따라 시간 $t$에서 예측된 score 값을 시간 $t − \Delta t$로 근사화하는 경우가 많다.
\[\begin{equation} s_\theta (x_t, t) \approx s_\theta (x_{t - \Delta t}, t) \end{equation}\]근사 오차가 무시할 수 있고 동일한 score network \(s_\theta\)를 고려하면 $\mathcal{M}$과 \(\mathcal{M}_\textrm{inv}\)는 서로 역 매핑으로 취급할 수 있으므로
\[\begin{equation} \mathcal{M}_\textrm{inv} (\mathcal{M} (x_t, t), t) = x_t \end{equation}\]를 만족한다.
Method
1. Weak-to-Strong Diffusion
Diffusion model에서 목표는 추정 결과와 실제 값 사이의 log probability density의 기울기 차이를 최소화하는 것이다. 그러나 실제 데이터 분포에 접근할 수 없기 때문에 이 차이를 직접적으로 정량화할 수 없다. 이러한 문제를 해결하기 위해, 본 논문에서는 강력한 모델 \(\mathcal{M}^s\) (추정 밀도를 $p^s$)과 약한 모델 \(\mathcal{M}^w\) (추정 밀도 $p^w$)을 고려한다.
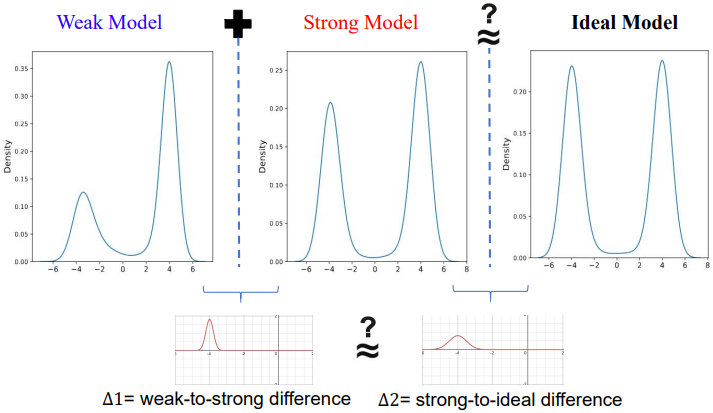
약한 모델과 강한 모델의 분포 차이를 \(\Delta_1 = \nabla \log p^s - \nabla \log p^w\)로, 강한 모델의 분포와 이상적인 분포의 차이를 \(\Delta_2 = \nabla \log p^\textrm{gt} - \nabla \log p^s\)로 정의하자. 추정 가능한 \(\Delta_1\)을 이용하여 \(\Delta_2\)를 근사함으로써 기존 diffusion model과 이상적인 모델 간의 격차를 간접적으로 줄여 학습된 분포를 실제 데이터 분포에 더 가깝게 만든다.

Algorithm 1에 설명된 바와 같이 reflection 연산자 \(\mathcal{M}_\textrm{inv}^w (\mathcal{M}^s (\cdot))\)를 사용하여 샘플링 궤적을 최적화할 수 있다. 강력한 모델의 denoising과 약한 모델의 inversion을 반복적으로 통합함으로써 샘플링 과정에서 step별 reflective process를 수행하고, latent $x_t$를 개선된 \(\hat{x}_t\)로 정제한다.
Auto-guidance는 latent를 정제하기 위해 저하된 모델 버전을 사용하는 단순한 interpolation 접근 방식을 활용한다. 이는 W2SD와 유사한 상위 개념을 공유하지만, W2SD는 근본적으로 다른 메커니즘을 도입하여 훨씬 강력한 성능과 더 넓은 적용 범위를 제공한다.
2. Visualization in Various Settings
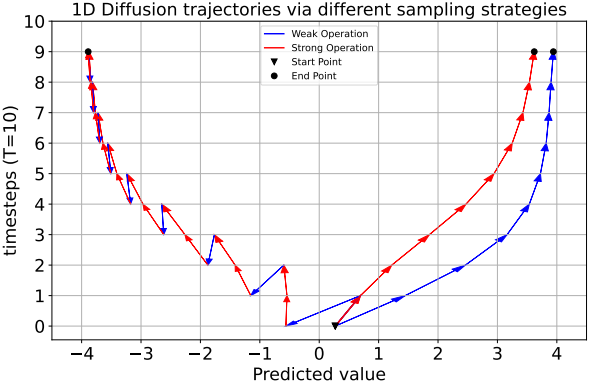
다음은 피크가 -4와 4인 1D Gaussian mixture 합성 데이터에 대한 실험 결과이다.
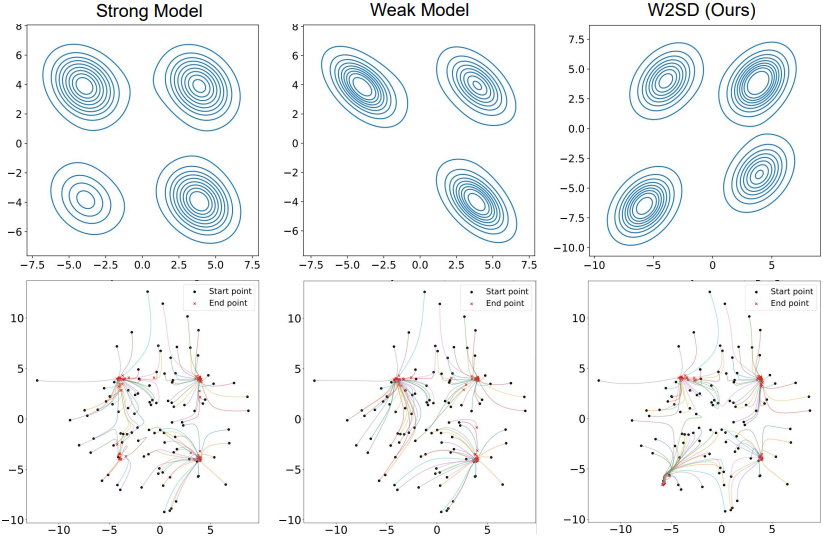
다음은 2D Gaussian mixture 합성 데이터에 대한 실험 결과이다.
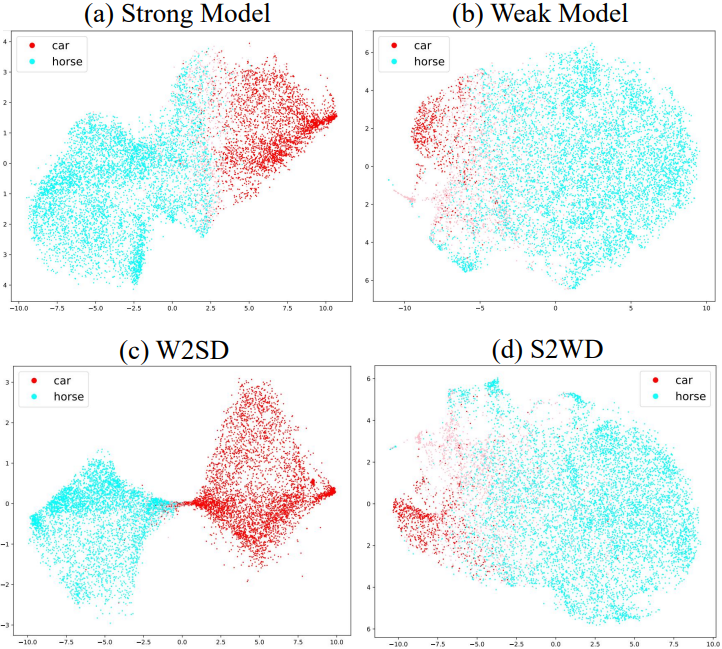
다음은 CIFAR-10의 실제 이미지에 실험 결과이다. \(\mathcal{M}^s\)는 말 5,000장, 차 2,500장으로 학습되었으며, \(\mathcal{M}^s\)는 말 5,000장, 차 500장으로 학습되었다. 위는 t-SNE로 CLIP feature의 차원을 줄여 나타낸 것이고, 아래는 샘플링 예시들이다.

Empirical Analysis
1. Weight Difference
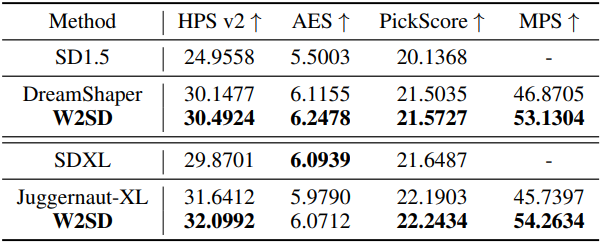
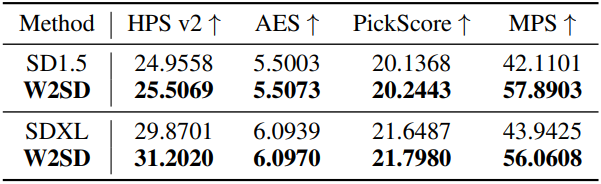
다음은 전체 파라미터 fine-tuning에 대한 결과이다. 인간 선호도에 맞게 전체 파라미터가 fine-tuning된 모델을 강한 모델로, 원래 모델을 약한 모델로 하였다.
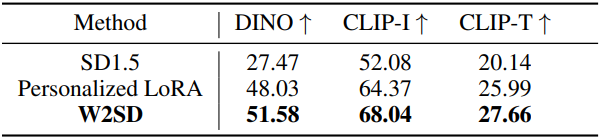
다음은 LoRA fine-tuning에 대한 결과이다. SD1.5를 약한 모델로, SD1.5를 LoRA fine-tuning한 모델을 강한 모델로 하였다. (왼쪽부터 약한 모델, 강한 모델, W2SD)

다음은 MoE에 대한 결과이다. DiT-MoE-S를 강한 모델로 사용하고, 각 denoising step에서 가장 성능이 낮은 두 expert를 약한 모델로 사용하였다. (위가 DiT-MoE-S, 아래가 W2SD)


2. Condition Difference
다음은 classifier-free guidance에 대한 결과이다. Guidance scale이 높은 모델을 강한 모델로, 낮은 모델을 약한 모델로 사용하였다. (모델: SDXL, 데이터셋: Pick-a-Pic)
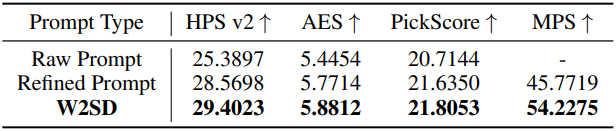
다음은 프롬프트에 대한 결과이다. GenEval의 텍스트 프롬프트 (5~6 단어)를 약한 모델에 사용하고, LLM으로 정제한 프롬프트를 강한 모델에 사용하였다. (모델: SDXL, 데이터셋: GenEval)
3. Sampling Pipeline Difference
다음은 ControlNet을 강한 모델로, 일반 모델을 약한 모델로 사용하였을 때의 결과이다.

4. Cumulative Effects of Different Model Differences
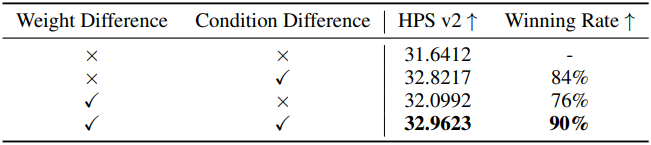
다음은 모델 차이를 함께 사용한 결과이다. 높은 guidance scale의 Juggernaut-XL을 강한 모델로, guidance scale이 0인 SDXL을 약한 모델로 사용하였다.
5. More Detailed Analysis
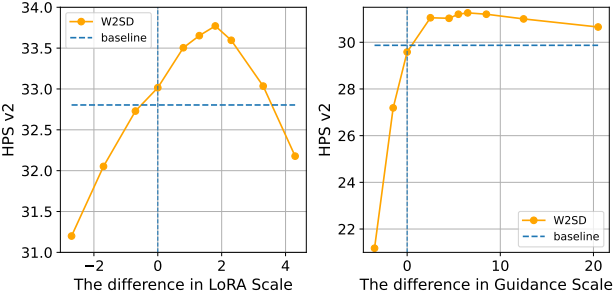
다음은 LoRA scale과 guidance scale에 따른 W2SD의 성능을 비교한 결과이다.

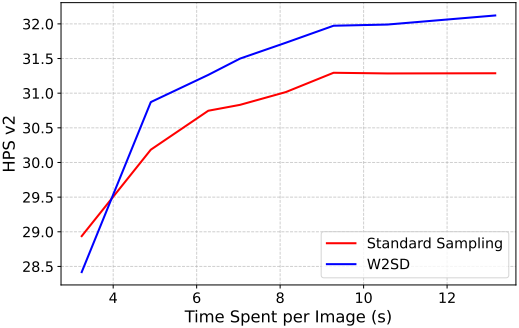
다음은 이미지 생성 속도를 비교한 결과이다.