[논문리뷰] RLP: Reinforcement as a Pretraining Objective
ICLR 2026. [Paper] [Github]
Ali Hatamizadeh, Syeda Nahida Akter, Shrimai Prabhumoye, Jan Kautz, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Yejin Choi
NVIDIA | Carnegie Mellon University | Boston University | Stanford University
26 Sep 2025
Introduction
인간의 이해는 토큰 단위로 이루어지는 선형적인 과정이 아니라 입력과 사전 지식을 병렬적으로 통합하는 과정이다. 현재의 LLM 사전 학습 방식은 이러한 메커니즘을 결여하고 있어, 모델이 학습 과정에서 언어를 세계 지식에 기반하여 추론하고 활용하는 능력을 제한한다.
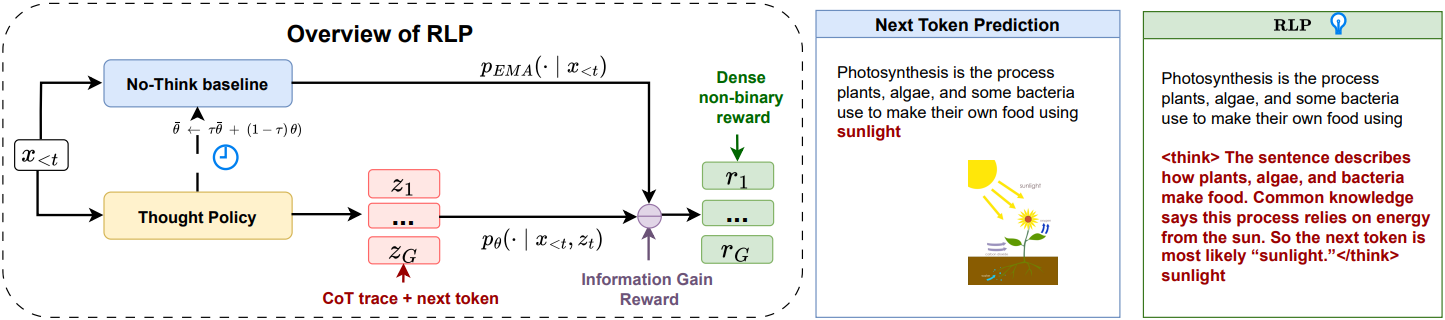
이러한 격차를 해소하기 위해, 본 논문에서는 각 토큰을 예측하기 전에 명시적으로 수행되는 행동으로 Chain-of-Thought (CoT) 생성을 처리하는 Reinforcement Learning Pre-training (RLP)을 제안하였다. 모델은 먼저 내부 생각을 샘플링한 다음, 해당 생각이 추가된 동일한 컨텍스트에서 관찰된 토큰을 예측한다. 학습 신호는 생각할 때 관찰된 토큰의 log likelihood 증가량을 생각하지 않는 baseline과 비교한 값이다. 이를 통해 검증자 개입이 필요 없는 dense reward를 얻을 수 있으며, 생각이 예측을 향상시키는 모든 위치에 대해 크레딧을 부여한다. 신호는 teacher forcing을 적용한 일반 텍스트에 대해 정의되므로, RLP는 추론을 위한 강화 학습을 maximum likelihood에 사용되는 동일한 스트림에 대한 reinforcement pretraining으로 재구성한다.
검증 가능한 reward를 사용하는 post-training 방식과 달리, RLP는 검증 도구가 필요 없다. 신호는 모델과 baseline 하에서의 log-evidence로부터 직접 계산되므로 도메인에 구애받지 않는 웹스케일 텍스트에 균일하게 적용할 수 있다. RLP는 모든 위치에서 continuous한 개선 신호를 제공하고 전체 문서를 사용하여 학습한다. 따라서 엔트로피가 높은 토큰을 미리 선택하거나 별도의 소규모 모델과 학습을 연결할 필요가 없다. RLP는 next token prediction에 실질적으로 도움이 되는 생각에만 reward를 제공함으로써 기본 모델의 사고방식을 개선하도록 설계되었다.
Method
본 논문에서는 추론을 명시적으로 유도하는 사전 학습 절차인 RLP를 소개한다. RLP는 다음 토큰 예측 전에 짧은 Chain-of-Thought (CoT)을 삽입하고, 해당 CoT가 관찰된 토큰의 log-probability를 CoT가 없는 baseline에 비해 얼마나 향상시키는지 측정한다. 이 향상 정도는 log likelihood 비율로 표현되며, 검증자가 필요 없는 dense reward로 일반 텍스트 코퍼스의 모든 위치에서 활용 가능하다. RLP는 예측 이점에 비례하여 가치를 부여함으로써, 표준 next token prediction에 사용되는 동일한 데이터를 기반으로 사고하는 법을 학습하는 과정으로 전환한다.
Parameterization and roles
Thought policy \(\pi_\theta (c_t \; \vert \; x_{<t})\)와 predictor \(p_\theta (x_t \; \vert \; x_{<t}, c_t)\)는 정확히 동일한 네트워크와 파라미터 $\theta$를 공유한다. 네트워크는 먼저 CoT $c_t$를 샘플링한 다음, concat된 prefix \((x_{<t}, c_t)\)를 조건으로 다음 토큰 $x_t$에 점수를 매긴다. No-think baseline \(\bar{p}_\phi (x_t \; \vert \; x_{<t})\)는 CoT 채널 없이 동일한 토큰에 점수를 매기는 데 사용되는 현재 네트워크의 EMA teacher이다.
따라서 생각을 생성하고 그 생각이 주어졌을 때 다음 토큰을 예측하는 하나의 모델이 존재한다. EMA teacher는 생각하지 않는 반사실적 상황을 제공한다.
Classical next-token objective
텍스트 시퀀스 $\textbf{x} = (x_0, \ldots, x_T)$와 위치 $t$가 주어졌을 때, predictor \(q_\eta\)에 대한 next-token prediction (NTP) objective는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{NTP} (\eta) = \mathbb{E}_{(x_{<t}, x_t) \sim \mathcal{D}} [\log q_\eta (x_t \; \vert \; x_{<t})] \end{equation}\]다음 토큰의 분포 $p$와 $q$에 대해 cross-entropy (CE)를 다음과 같이 정의한다.
\[\begin{equation} \textrm{CE}(p, q) = \mathbb{E}_{x \sim p} [- \log q(x)] \end{equation}\]$x_t$에 대한 데이터 분포를 \(p^\ast (\cdot \; \vert \; x_{<t})\)로 나타낼 때, \(\mathcal{L}_\textrm{NTP}\)을 최대화하는 것은
\[\begin{equation} \mathbb{E}_{x_{<t} \sim \mathcal{D}} [\textrm{CE} (p^\ast, q_\eta (\cdot \; \vert \; x_{<t}))] \end{equation}\]을 최소화하는 것과 같다. 표준 NTP loss 항을 학습에 포함하지 않기 때문에, \(\mathcal{L}_\textrm{NTP}\)은 컨텍스트 설명을 위해서만 포함한다. 대신, RLP는 추후 설명할 information-gain objective를 최적화하고 샘플링된 생각의 토큰을 통해서만 파라미터를 업데이트한다.
1. Reasoning as an Action
RLP는 샘플링된 생각을 활용하여 다음 토큰 예측을 강화한다. 각 위치 $t$에서 policy는 latent CoT 확률 변수를 추출한다.
\[\begin{equation} z_t \sim \pi_\theta (\cdot \; \vert \; x_{<t}) \end{equation}\]$z_t$를 현실화한 것을 $c_t$라고 하자. 그러면 네트워크는 \(p_\theta (\cdot \; \vert \; x_{<t}, c_t)\)를 사용하여 $x_t$를 예측한다. CoT를 제공하지 않고 동일한 컨텍스트에서 쿼리된 EMA teacher \(\bar{p}_\phi (\cdot \; \vert \; x_{<t})\)를 생각하지 않은 반사실적 추론으로 사용한다.
EMA teacher instantiation and schedule
첫 번째 batch에서 현재 모델과 일치하도록 EMA teacher를 생성하고 ($\phi \leftarrow \theta$), 그 후 각 최적화 step 후에 EMA teacher를 다음과 같이 업데이트한다.
\[\begin{equation} \phi \leftarrow \tau \phi + (1 - \tau) \theta, \quad \tau = 0.999 \end{equation}\]이러한 선택을 통해 \(\bar{p}_\phi\)는 유익한 비교를 제공할 만큼 충분히 최신 상태이면서 reward 조작을 완화하기 위해 의도적으로 시차를 둔 반사실적 사고다. Baseline을 고정하면 반사실적 사고가 진화하는 모델에서 너무 멀리 벗어나게 되고, 시차 없이 모델을 그대로 따라가면 log likelihood 비율이 0에 가까워진다. 업데이트 후 평균화를 통해 한 단계 시차를 둔 smoothed teacher를 생성하여 학습을 안정화한다.
2. Information-gain Reward
다음 토큰에 대한 teacher forcing에 대하여, 추론된 log-evidence와 baseline log-evidence는 다음과 같다.
\[\begin{aligned} S_\textrm{pred} (c_t) = \log p_\theta (x_t \; \vert \; x_{<t}, c_t) \\ S_\textrm{EMA} = \log \bar{p}_\phi (x_t \; \vert \; x_{<t}) \\ \end{aligned}\]Information-gain reward는 다음과 같은 log-likelihood 비율이다.
\[\begin{equation} r(c_t) = S_\textrm{pred} (c_t) - S_\textrm{EMA} \end{equation}\]이는 관찰된 다음 토큰에 대해 추론된 점수와 사고 과정이 없는 baseline의 점수를 비교한다. Reward는 각 $t$에 대해 teacher forcing 하에서 계산된다. Policy를 업데이트할 때, $r(c_t)$는 $\theta$에 대해 상수로 취급한다 (\(p_\theta\) 또는 \(\bar{p}_\phi\)를 통한 backpropagation 없음).
3. Expected Improvement Identity
고정된 컨텍스트 \(x_{<t}\)와 현실화된 사고 $c_t$에 대해, reward는 다음과 같이 쓸 수 있다.
\[\begin{equation} r(c_t) = \log p_\theta (x_t \; \vert \; x_{<t}, c_t) - \log \bar{p}_\phi (x_t \; \vert \; x_{<t}) \end{equation}\]기대값에 선형성을 사용해서 \(x_t \sim p_t^\ast = p^\ast (\cdot \; \vert \; x_{<t})\)에 대해 기대값을 구하면 다음과 같다.
\[\begin{equation} \mathbb{E}_{x_t \sim p_t^\ast} \left[ r (c_t) \right] = \mathbb{E}_{x_t \sim p_t^\ast} \left[ \log p_\theta (x_t \; \vert \; x_{<t}, c_t) \right] - \mathbb{E}_{x_t \sim p_t^\ast} \left[ \log \bar{p}_\phi (x_t \; \vert \; x_{<t}) \right] \end{equation}\]Cross-entropy의 정의에 따라, 다음과 같이 cross-entropy로 표현할 수 있다.
\[\begin{aligned} \mathbb{E}_{x_t \sim p_t^\ast} \left[ r (c_t) \right] &= - \mathbb{E}_{x_t \sim p_t^\ast} \left[ \log \bar{p}_\phi (x_t \; \vert \; x_{<t}) \right] + \mathbb{E}_{x_t \sim p_t^\ast} \left[ \log p_\theta (x_t \; \vert \; x_{<t}, c_t) \right] \\ &= \textrm{CE} \left(p^\ast, \bar{p}_\phi (\cdot \; \vert \; x_{<t}) \right) - \textrm{CE} \left(p^\ast, p_\theta (\cdot \; \vert \; x_{<t}, c_t) \right) \end{aligned}\]즉, reward의 기대값을 최대화하면 다음 토큰을 위한 사고의 유용성이 최대화된다.
4. RLP Objective and Optimization
RLP는 정답을 더 잘 맞히게 만들어주는 생각을 생성하도록 thought policy를 최적화한다. 학습 과정에는 NTP loss가 포함되지 않는 대신, information-gain objective만 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{IG} (\theta) = - \mathbb{E}_{x_{<t} \sim \mathcal{D}} \mathbb{E}_{c_t \sim \pi_\theta (\cdot \; \vert \; x_{<t})} \left[ r (c_t) \right] \end{equation}\]Gradient는 사고 토큰에만 적용되며, $r(c_t)$는 상수로 처리된다.
Group-relative baseline (inclusive mean with correction)
분산을 줄이기 위해 각 컨텍스트에 대해 $G \le 2$개의 생각 \(\{c_t^{(i)}\}_{i=1}^G\)을 샘플링하고 수정된 baseline을 사용한다.
\[\begin{equation} \bar{r} = \frac{1}{G} \sum_{j=1}^G r (c_t^{(j)}) \end{equation}\]각 생각에 대한 advantage는 다음과 같이 정의된다.
\[\begin{equation} A^{(i)} = \frac{G}{G-1} \left( r (c_t^{(i)}) - \bar{r} \right), \quad \textrm{with no gradient propagated through} \; \bar{r} \end{equation}\]Per-token importance ratios and clipped surrogate
Clipped surrogate를 사용하여 사고 토큰의 log-probability를 업데이트한다. \(\ell_u^{(i)}\)를 \(c_t^{(i)}\)의 $u$번째 토큰이라고 하고, \(\textrm{prefix}_u^{(i)} = (x_{<t}, \ell_{1:u-1}^{(i)})\)라고 하자. 사고를 샘플링하는 데 사용되는 behavior 파라미터 \(\theta_\textrm{old}\)를 이용하여 토큰별 중요도 비율을 정의한다.
\[\begin{equation} \rho_u^{(i)} = \exp \left( \log \pi_\theta (\ell_u^{(i)} \; \vert \; \textrm{prefix}_u^{(i)}) - \log \pi_{\theta_\textrm{old}} (\ell_u^{(i)} \; \vert \; \textrm{prefix}_u^{(i)}) \right) \end{equation}\]Surrogate loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{clip} (\theta) = - \mathbb{E} \left[ \frac{1}{\vert c_t^{(i)} \vert} \sum_u \min \left( \rho_u^{(i)} \textrm{sg}(A^{(i)}), \textrm{clip} (\rho_u^{(i)}; 1 - \epsilon_\ell, 1 + \epsilon_\ell) \textrm{sg}(A^{(i)}) \right) \right] \end{equation}\](\(\textrm{clip}(\rho; 1 - \epsilon_\ell, 1 + \epsilon_h)\)는 element-wise clipping, $\textrm{sg}(\cdot)$는 stop-gradient)
전체 알고리즘은 다음과 같다.

Experiments
1. Results
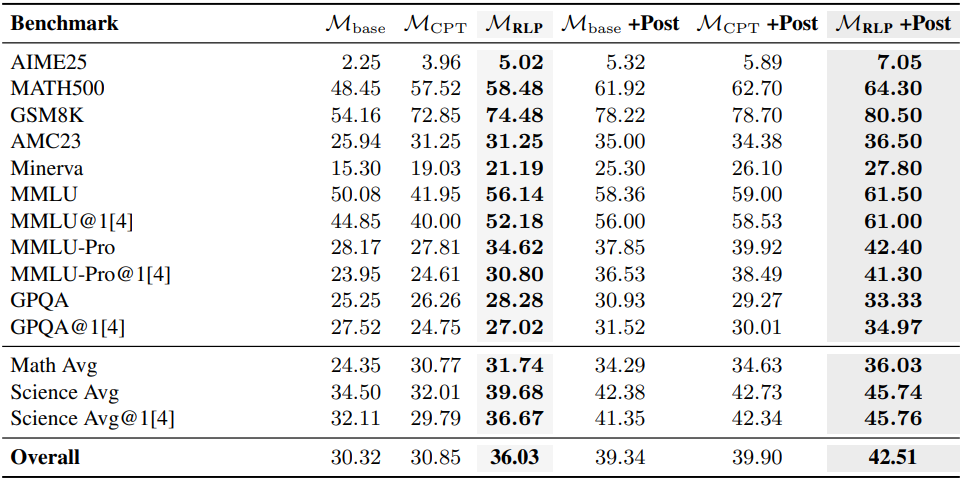
다음은 Qwen3-1.7B-Base를 base model로 하였을 때의 비교 결과이다. (CPT는 continuous pretraining)
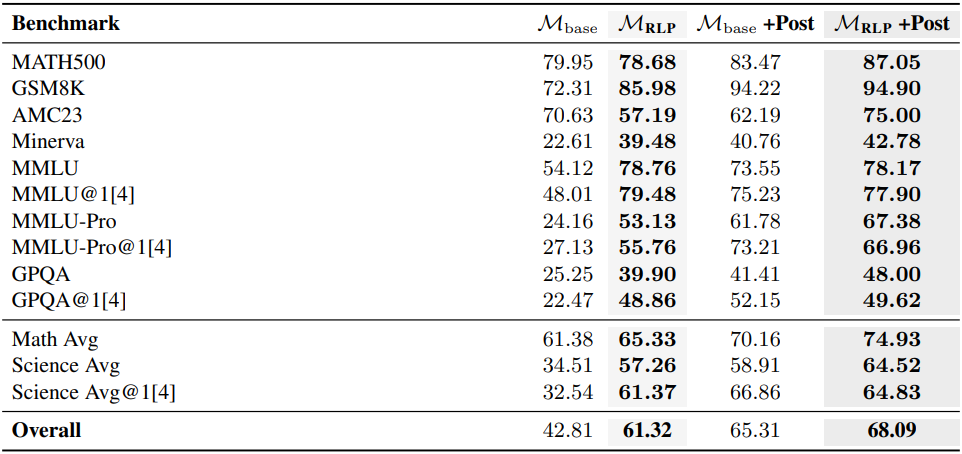
다음은 NEMOTRON-NANO-12B-V를 base model로 하였을 때의 비교 결과이다.
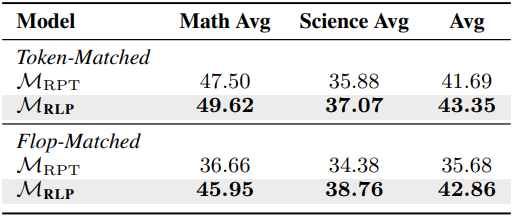
다음은 RPT와의 비교 결과이다.
2. Ablations
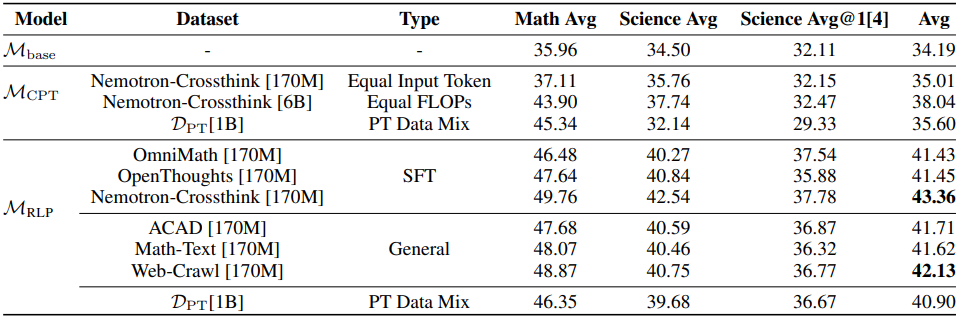
다음은 다양한 데이터셋에 유형에 대한 비교 결과이다.
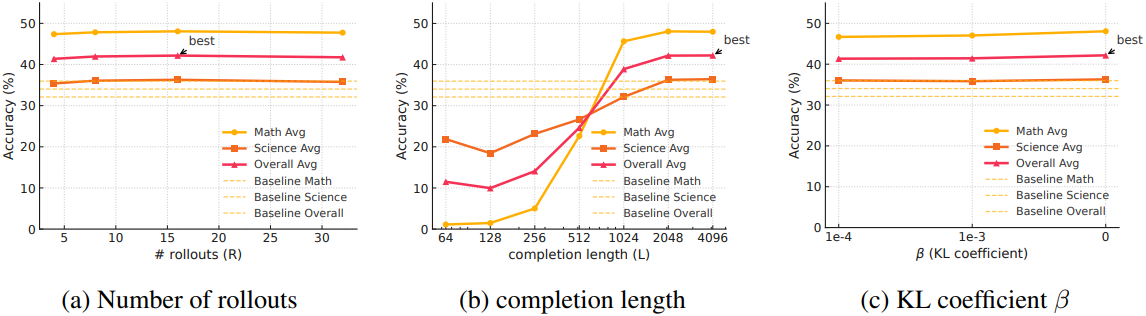
다음은 Qwen3-1.7B를 base model로 하였을 때의 ablation 결과이다.