[논문리뷰] FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
ICLR 2026. [Paper] [Page] [Github]
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, Liujuan Cao
Xiamen University | Shanghai Jiao Tong University
2 Sep 2025
Introduction
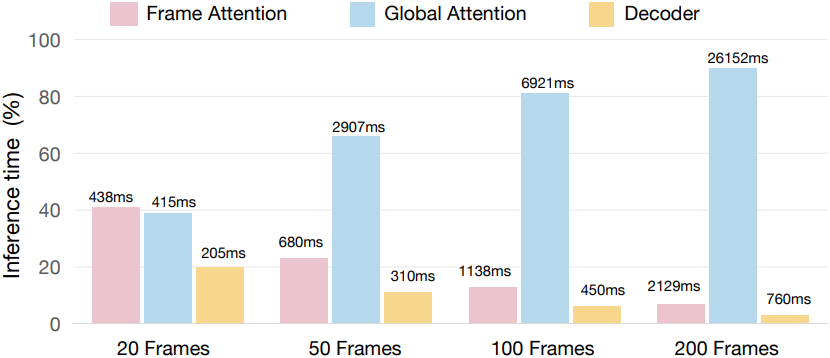
저자들은 VGGT의 주요 inference 병목 현상을 파악하기 위해, 먼저 구성 요소별 성능 분석을 수행했다. 분석 결과, 짧은 시퀀스에서는 frame attention (프레임 내 상호작용)과 global attention (프레임 간 상호작용)의 계산 비용이 유사하지만, 시퀀스 길이가 길어질수록 global attention의 비용이 급격히 증가하여 결국 전체 실행 시간을 지배하는 것으로 나타났다.
VGGT의 성능을 저하시키지 않고 global attention의 계산 비효율성을 완화할 수 있을까? 저자들은 이 가능성을 조사하기 위해 attention map을 시각화했다. 그 결과, 토큰 간 attention 패턴이 매우 유사하다는 중요한 사실을 발견했는데, 이는 global attention 계산에서 상당한 중복이 발생함을 시사한다.
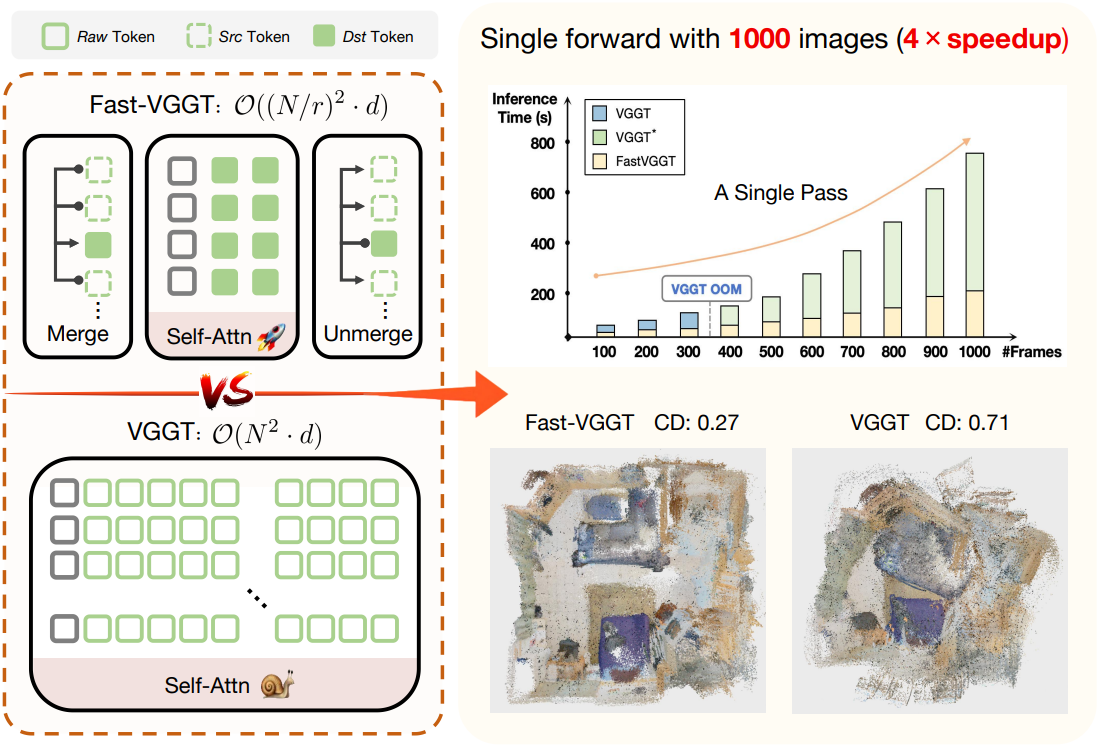
Attention 중복 현상에 대한 관찰에서 착안하여, 본 논문에서는 VGGT의 inference 효율을 향상시키기 위해 학습이 필요 없는 token merging 기법을 적용하였다. Token merging은 토큰을 source (src)와 destination (dst) 세트로 분할하고 각 src 토큰을 가장 유사한 dst 토큰과 병합함으로써 중복 표현을 통합한다. 2D 비전 task에서는 효과적이지만, 3D geometry 이해를 위한 구조로의 확장은 아직 충분히 연구되지 않았다. 하나의 이미지를 처리하는 2D 환경과 달리, VGGT는 이미지 간 correspondence에 의존하기 때문에 token merging을 직접 적용하는 것은 매우 어렵다.
이러한 문제를 해결하기 위해, 본 논문에서는 token merging을 전략적으로 적용하는 학습이 필요 없는 새로운 프레임워크인 FastVGGT를 제안하였다. 본 접근 방식은 기본 좌표계를 보존하는 것에서 시작한다. 구체적으로, 전체 장면의 글로벌 레퍼런스 역할을 하는 초기 프레임의 토큰은 우선순위가 높은 dst 토큰으로 지정되어 재구성 안정성을 보장하기 위해 병합 대상에서 제외된다. 또한, 글로벌 일관성을 유지하고 디테일한 정보를 보존하기 위해 모든 프레임에서 salient 토큰을 식별하고 유지하여 병합 과정을 완전히 건너뛰고 attention 연산에 직접 참여하도록 한다. 마지막으로, 저자들은 ToMeSD에서 영감을 받아 각 프레임 내에서 영역 기반 랜덤 샘플링을 구현하였다. 이를 통해 src 토큰과 dst 토큰의 공간적으로 균형 잡힌 선택을 보장하고, 통합 과정에서 특정 영역에서 중요한 정보 손실을 방지한다.
Method
1. Visualization Findings
아래 그림은 ScanNet 데이터셋에서 VGGT의 global attention map을 시각화한 것이다. 각 이미지는 1,041개의 토큰(카메라 토큰 1개, 레지스터 토큰 4개, 28$\times$37 그리드의 패치 토큰 1,036개)으로 표현된다. Self-attention 메커니즘은 모든 토큰에 대한 attention map을 생성하며, 토큰과 block에 걸쳐 시각화한 결과 이러한 맵들이 매우 유사하다는 것을 알 수 있다.
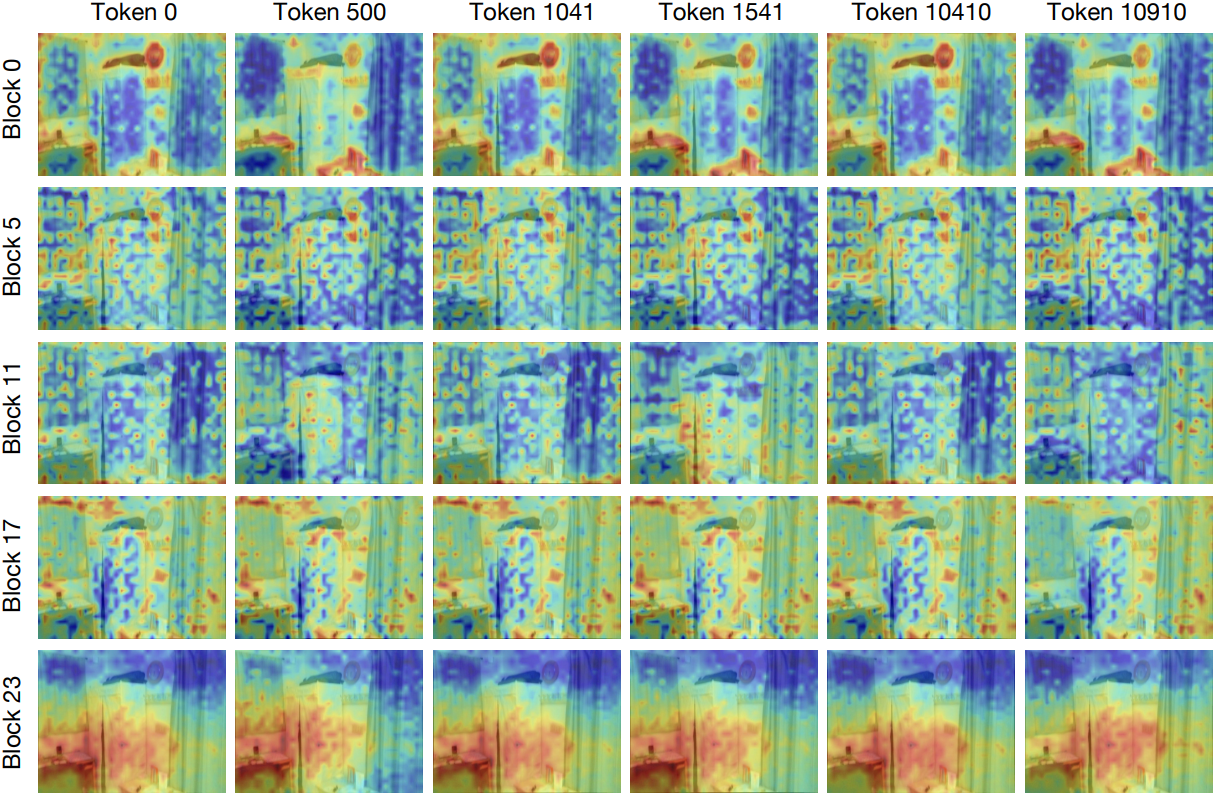
VGGT의 global self-attention layer는 가중 평균을 통해 모든 토큰의 정보를 집계하는데, 명시적인 정규화나 task별 제약 조건이 없으면 표현 공간이 반복적으로 압축된다. 이러한 압축으로 인해 토큰들이 지배적인 방향으로 수렴하여 고유성이 약화된다. 근본적으로 토큰 다양성을 보존하는 명시적인 메커니즘이 부족하여 로컬 다양성이 점진적으로 손실된다.
VGGT는 global attention과 frame attention이라는 두 단계 설계를 따른다. Global attention은 전체적인 시공간적 관계를 포착하여 글로벌 일관성을 강화한다. 여기서 토큰들이 지배적인 부분 공간으로 수렴하는 것처럼 보이는 것은 결함이 아니라 글로벌 semantic을 의도적으로 추출한 것으로 해석될 수 있다. Frame attention은 로컬 가변성을 다시 도입하여 글로벌 추상화와 로컬 차별화 사이의 균형을 맞춘다. 또한, global attention에서 관찰되는 강력한 feature 유사성은 성능 저하 없이 계산 비용을 줄이는 데 활용될 수 있는 중복성을 드러내며, 이는 VGGT의 속도 병목 현상을 해결하는 자연스러운 경로를 제공한다.
본 논문은 global attention map에서 관찰되는 강한 유사성에 착안하여, token merging을 통해 inference 속도를 향상시키는 FastVGGT를 제안하였다. 기존의 token merging 방법들은 일반적으로 랜덤 또는 고정 stride 샘플링을 통해 토큰을 destination (dst) 세트와 source (src) 세트로 분할한다. 그러나 3D reconstruction의 구조적 및 task별 요구 사항으로 인해 이러한 전략을 VGGT에 직접 적용하는 것은 쉽지 않다. 실제로 이러한 전략을 사용하면 inference 속도는 단축되지만 reconstruction 정확도가 저하되며 우수한 성능을 유지하지 못한다.
2. Token Partitioning
주로 2D 비전 task를 위해 개발된 token merging 방법은 일반적으로 개별 이미지에 대해 작동하는 반면, feed-forward 3D reconstruction 모델은 시점 간 중첩 정도가 다양한 멀티뷰 시퀀스를 처리한다. 이러한 중첩은 정확한 3D reconstruction에 매우 중요하며, 일관된 geometry를 복원하는 데 필요한 시점 간 correspondence를 제공한다. 따라서 reconstruction 정확도를 유지하려면 시퀀스의 모든 프레임에 걸쳐 작동하는 효과적인 token merging 전략을 설계하는 것이 필수적이다.
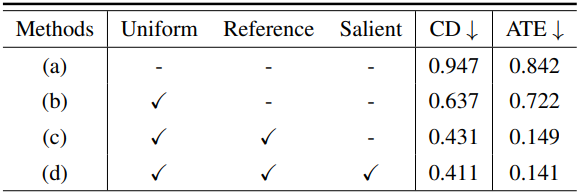
토큰 분할 전략은 세 가지 원칙에 따라 설계되었다.
- 전체 장면의 구조적 일관성을 보장하기 위해 프레임 간 correspondence를 유지한다.
- 과도한 압축과 중복을 방지하기 위해 각 프레임 내에서 균일한 병합을 보장한다.
- 가속 효율을 극대화하기 위해 중복성이 높은 토큰을 가장 대표적인 토큰으로 병합한다.
따라서 토큰을 세 가지 카테고리, 즉 각 프레임의 가장 특징적인 정보를 담고 있는 salient 토큰, 대표적인 기준점 역할을 하는 destination (dst) 토큰, 그리고 병합될 중복 정보를 담고 있는 source (src) 토큰으로 분류한다. 저자들은 이러한 원칙을 바탕으로 다음과 같이 세 가지 토큰 분할 전략을 설계했다.
레퍼런스 토큰 선택
VGGT는 첫 번째 프레임을 월드 좌표계로 정의하고, 모든 토큰은 이 기준 좌표계를 기준으로 등록된다. 이러한 설계 덕분에 첫 번째 프레임은 시퀀스 전체에 걸쳐 공간적 일관성을 유지하는 핵심 기준점이 된다. Attention map 시각화 결과를 보면, 토큰들은 다른 어떤 프레임보다 첫 번째 프레임에 대해 일관되게 더 강한 activation을 보이며, 이는 장면 수준 표현을 가이드하는 데 있어 첫 번째 프레임의 중심적인 역할을 강조한다. 따라서, 첫 번째 프레임의 모든 토큰을 dst 토큰으로 지정한다.
Salient 토큰 선택
VGGT는 프레임 간 토큰 상호작용을 통해 장면을 재구성하므로, 핵심 토큰들은 여러 시점 간에 신뢰할 수 있는 correspondence를 설정하는 데 매우 중요하다. 저자들은 이러한 핵심 토큰을 보존하기 위해, 토큰을 salient, dst, src 그룹으로 나누는 세 번째 카테고리를 도입하여 기존 token merging 방식을 확장했다. Salient 토큰은 병합 연산에서 제외되고, 대신 attention에 직접 참여한다.
Salient 토큰을 선택하기 위해, 먼저 토큰 norm을 기반으로 특징성을 측정하는 top-k 선택 전략을 적용한다. 그러나 이 전략은 시퀀스 길이가 길어질수록 계산 오버헤드가 증가한다. 효율성을 위해, 프레임당 약 10%의 토큰을 salient 토큰으로 유지하는 고정 stride 샘플링 방식을 채택했다. 이 토큰들은 특징성을 유지하는 기준점 역할을 한다.
고정 stride 샘플링 방식은 top-k 선택 방식과 유사한 정확도를 달성하면서 계산 비용을 크게 절감한다. 따라서 효율성과 효과성의 균형을 맞추기 위해 고정 stride 샘플링을 기본 전략으로 사용한다.
균일 토큰 샘플링
3D reconstruction의 dense한 예측 특성을 고려하여, 과도한 압축이나 중복을 방지하기 위해 프레임 내 균일 샘플링을 보장한다. 이를 위해 diffusion model에서 ToMeSD의 성공 사례를 참고하여, 영역 기반 랜덤 샘플링 전략을 활용해 각 프레임 내에서 dst 토큰과 src 토큰을 할당한다.
구체적으로, 먼저 입력 토큰을 프레임별로 분할하고 2D 이미지 패치 그리드에 배치한다. 각 그리드 셀 내에서, 미리 정의된 병합 비율과 stride $K$에 따라 dst 토큰을 샘플링하고, 나머지 토큰은 src 토큰으로 지정한다. 이러한 영역 기반 전략은 공간적으로 균형 잡힌 병합을 보장하고 넓은 영역이 사라지는 등의 아티팩트를 방지한다. 결과적으로 병합 과정이 더욱 일관성 있게 이루어지고, 재구성된 장면은 전반적인 구조적 안정성을 더 잘 유지한다.
3. Token Merging Procedure
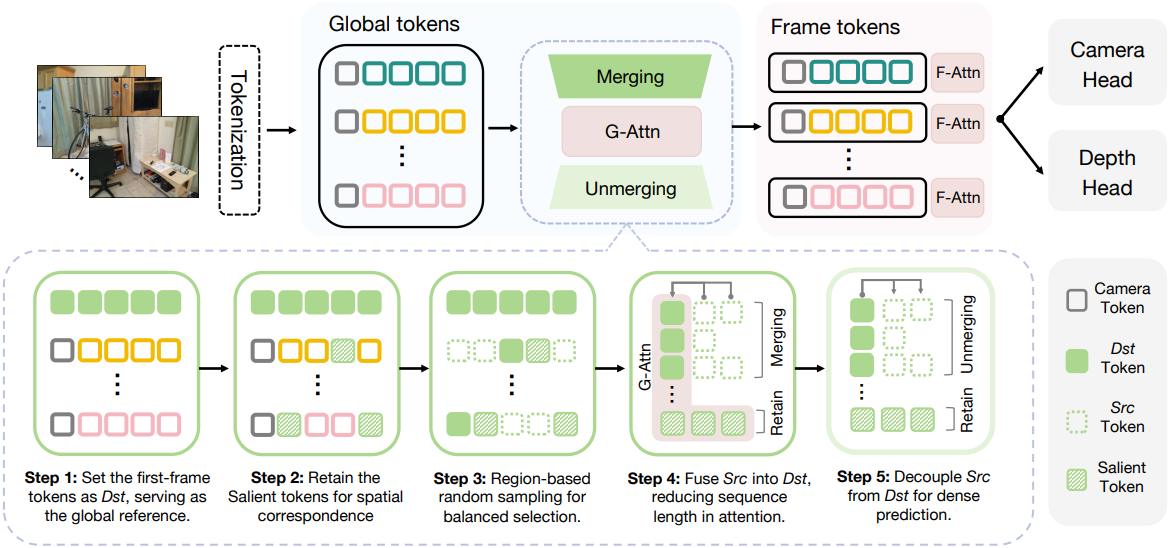
토큰 분할 후, src 토큰은 dst에서 가장 유사한 토큰과 병합되어 attention 계산을 위한 시퀀스 길이를 효과적으로 줄인다. Feature 차원이 $c$인 토큰 표현 $x \in \mathbb{R}^c$가 주어졌을 때, 각 $x_s \in \textrm{src}$와 모든 $x_d \in \textrm{dst}$ 간의 코사인 유사도를 계산한다.
각 src 토큰 $x_s$는 가장 유사한 dst 토큰 $x_d$에 할당되고, 평균값을 사용하여 업데이트된다.
\[\begin{equation} x_d^\prime = \frac{x_d + x_s}{2} \end{equation}\]업데이트된 $x_d^\prime$는 유지되는 반면 $x_s$는 일시적으로 폐기되므로 attention 계산에서 처리되는 토큰 수가 줄어든다.
4. Token Unmerging Procedure
Dense 3D reconstruction에는 토큰별 출력(ex. 깊이 예측)이 필요하다. 따라서 ToMeSD에서 영감을 받은 unmerging 연산을 채택하여 원래 토큰 해상도를 복원하고 VGGT 아키텍처와의 완벽한 호환성을 유지한다.
구체적으로, 두 토큰 $x_1, x_2 \in \mathbb{R}^c$가 하나의 표현으로 병합되었다고 가정해 보자.
\[\begin{equation} x_{1,2}^\ast = \frac{x_1 + x_2}{2} \end{equation}\]Unmerging 과정에서 원래 시퀀스 길이를 복구하기 위해 이 표현이 복제된다.
\[\begin{equation} x_1^\prime = x_{1,2}^\ast, \quad x_2^\prime = x_{1,2}^\ast \end{equation}\]이러한 복제 방식은 토큰 개수가 입력 해상도와 일치하도록 보장하여 디코더가 모든 패치에 대해 dense한 출력을 생성할 수 있도록 한다. 또한, 병합 과정에서 명시적인 src-dst 매핑을 유지함으로써 unmerging 과정이 deterministic하고 효율적으로 수행된다. 이를 통해 모델은 global attention layer에서 압축된 시퀀스의 계산 효율성을 누리면서도 토큰별 예측을 제공할 수 있다.
5. VRAM-Efficient Implementation
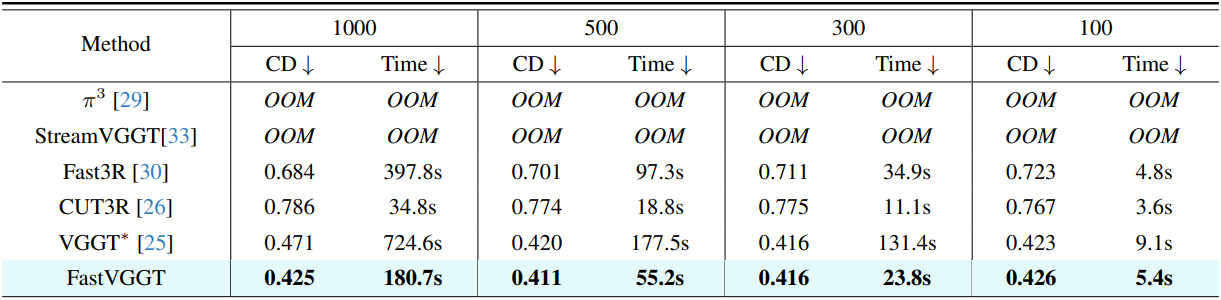
기존 VGGT는 약 300 프레임 정도의 시퀀스를 처리할 때 메모리 부족 오류를 발생시켰다. VGGT는 24개의 인코더 block으로 구성되어 있지만, inference 시에는 4, 11, 17, 23번 layer의 출력만 필요하다. 그럼에도 불구하고 기존 구현 방식은 24개 block 모두의 중간 결과를 저장한다. 더 긴 입력 시퀀스를 지원하기 위해, 본 논문에서는 inference에 사용되지 않는 중간 출력을 버리는 간단한 최적화 버전인 VGGT*를 제안하였다. 이를 통해 메모리 사용량을 줄이고 reconstruction 품질에 영향을 주지 않고 최대 1000프레임까지 처리할 수 있다. (특별히 명시되지 않는 한, VGGT*가 baseline)
Experiments
1. 3D Reconstruction
다음은 ScanNet-50 데이터셋에서의 3D reconstruction 결과이다.
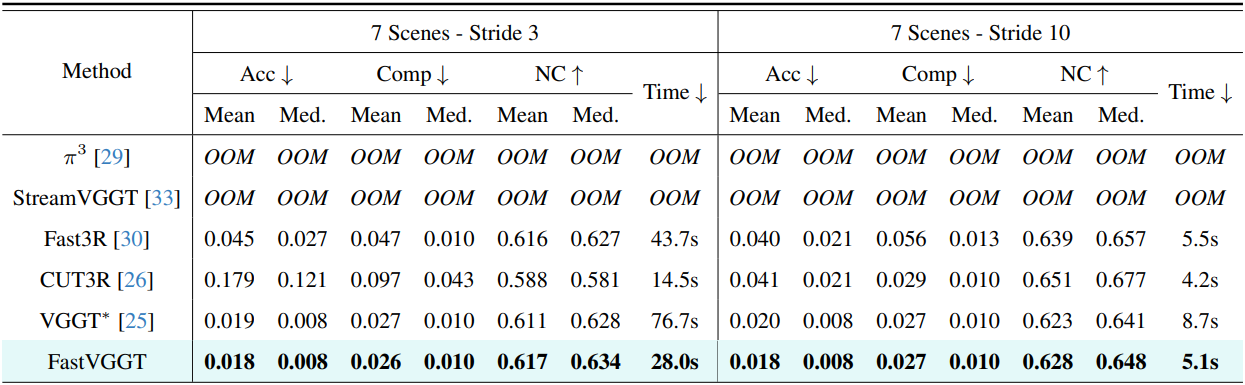
다음은 7 Scenes 데이터셋에서의 3D reconstruction 결과이다.
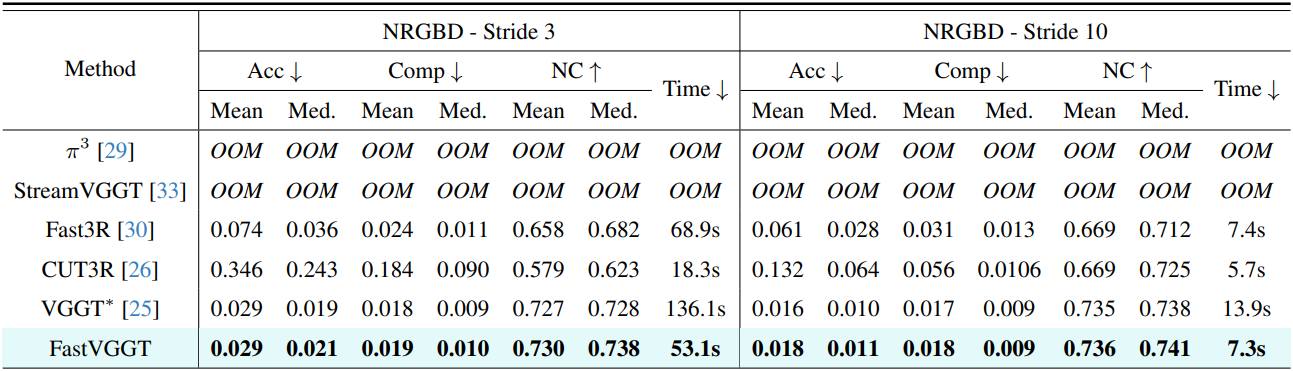
다음은 NRGBD 데이터셋에서의 3D reconstruction 결과이다.
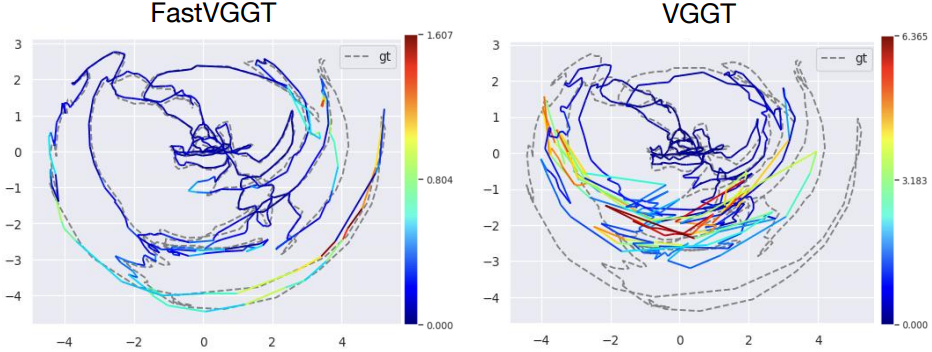
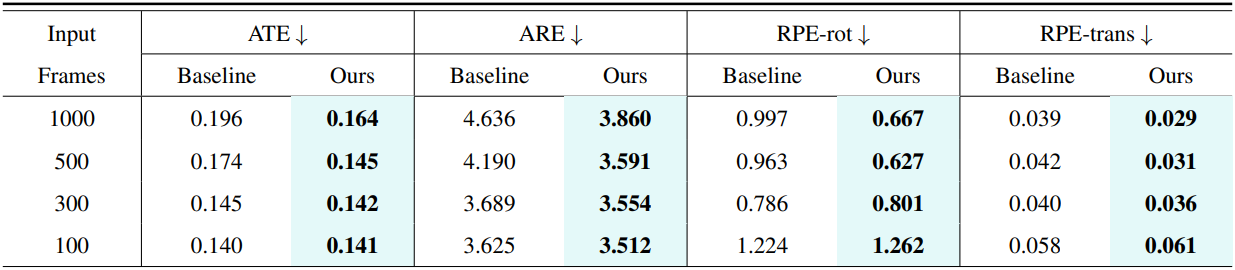
2. Camera Pose Estimation
다음은 ScanNet-50 데이터셋에서의 카메라 포즈 추정 결과이다.
3. Ablation Studies
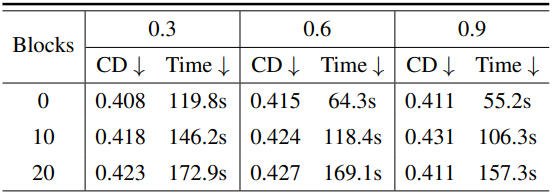
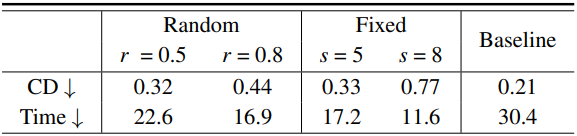
다음은 (왼쪽) 토큰 분할 전략과 (오른쪽) 병합 비율 및 영향을 받는 block에 대한 ablation study 결과이다.