[논문리뷰] Flow Q-Learning
ICML 2025. [Paper] [Page] [Github]
Seohong Park, Qiyang Li, Sergey Levine
UC Berkeley
4 Feb 2025
Introduction
Offline RL은 비용이 많이 드는 환경 상호작용 없이 미리 수집된 데이터셋으로부터 효과적인 의사결정 policy를 학습할 수 있게 해준다. Offline RL의 핵심은 에이전트가 데이터셋의 state-action 분포 내에서 return을 최대화해야 한다는 것이다. 데이터셋이 점점 더 커지고 다양해짐에 따라 action 분포는 더욱 복잡해지고 multimodal이 되었으며, 이는 종종 이러한 복잡한 분포를 포착하고 보다 정확한 행동 제약을 구현할 수 있는 표현력이 풍부한 policy를 필요로 한다. 본 논문에서는 flow matching을 활용하여 scalable한 offline RL 방법을 개발하고자 한다. 표현력이 풍부한 flow policy를 사용함으로써 데이터셋의 복잡한 action 분포를 효과적으로 모델링하고, 많은 offline RL 알고리즘의 핵심인 정확한 행동 제약을 적용할 수 있다.
하지만 flow model이나 diffusion model을 활용하여 offline RL policy를 parameterize하는 것은 결코 간단한 문제가 아니다. 이러한 생성 모델의 반복적인 특성 때문에 학습된 value function을 최대화하도록 flow policy나 diffusion policy를 학습하는 간단한 방법이 없다. 기존 연구들에서는 다양한 기법을 기반으로 학습된 value function에서 반복적인 생성 policy를 추출하는 여러 가지 방법을 고안해냈지만, 내재적인 단점(ex. 불안정한 backpropagation, 제한된 샘플 사용, 높은 계산 비용)으로 인해 더 복잡한 문제에 적용하는 데 한계가 있거나 scalability가 부족한 경우가 많다.
본 논문에서는 offline RL에서 표현력이 풍부한 flow policy를 활용하는 간단하고 효과적인 flow Q-learning (FQL)을 제안하였다. 핵심 아이디어는 behavioral cloning (BC)만을 사용하여 반복적인 flow policy를 학습하는 것이다. 대신, flow model로부터 정보를 추출하면서 value를 최대화하는 별도의 표현력이 풍부한 one-step policy를 학습시킨다. Flow model에서 value 최대화의 부담을 덜어줌으로써, 반복 과정을 제어하는 데 따르는 문제를 완전히 해결하고 flow model의 표현력을 최대한 활용할 수 있다. 또한, 이 절차는 표현력이 풍부한 one-step policy를 생성하므로 평가 시 비용이 많이 드는 반복적인 flow step을 제거한다.
Method
본 논문의 목표는 두 가지이다.
- 복잡한 action 분포를 처리하기 위해 표현력이 풍부한 flow matching policy를 활용한다.
- 쉽게 구현하고 사용할 수 있도록 방법을 최대한 단순하게 유지한다.
단순한 접근 방식
Offline RL을 위한 flow policy를 학습시키는 가장 간단한 방법은 Gaussian policy를 사용하는 actor-critic 프레임워크
\[\begin{aligned} \mathcal{L}_Q (\phi) &= \mathbb{E}_{s, a, r, s^\prime \sim \mathcal{D}, a^\prime \sim \pi_\theta} [(Q_\phi (s, a) - r - \gamma Q_{\bar{\phi}} (s^\prime, a^\prime))^2] \\ \mathcal{L}_\pi (\theta) &= \mathbb{E}_{s, a \sim \mathcal{D}, a^\pi \sim \pi_\theta} [\underbrace{-Q_\phi (s, a^\pi)}_{\textrm{Q loss}} - \underbrace{\alpha \log \pi (\alpha \; \vert \; s)}_{\textrm{BC loss}}] \end{aligned}\]에서 BC loss를 flow matching loss
\[\begin{equation} \mathcal{L}_\textrm{Flow} (\theta) = \mathbb{E}_{s, a=x^1 \sim \mathcal{D}, x^0 \sim \mathcal{N}(0, I_d), t \sim U([0, 1])} [\| v_\theta (t, s, x^t) - (x^1 - x^0) \|_2^2] \end{equation}\]로 대체하는 것이다. 이 단순한 접근 방식은 다음과 같이 정의된 actor loss \(\mathcal{L}_\pi (\theta)\)를 최소화한다.
\[\begin{equation} \mathcal{L}_\pi (\theta) = \underbrace{\mathbb{E}_{s \sim \mathcal{D}, a^\pi \sim \pi_\theta} [-Q_\phi (s, a^\pi)]}_{\textrm{Q loss}} + \underbrace{\alpha \mathcal{L}_\textrm{Flow} (\theta)}_{\textrm{BC loss}} \end{equation}\]직관적으로, 이 flow policy \(\pi_\theta\)는 BC loss를 최소화하면서 value function을 최대화하도록 조종된다. 그러나 Gaussian policy와 달리, flow policy는 numerical ODE solver의 재귀로 인해 Q loss에서 backpropagation through time (BPTT)을 필요로 한다. 불행히도, 이는 종종 불안정하고 비용이 많이 들며, 성능을 저해할 수 있다.
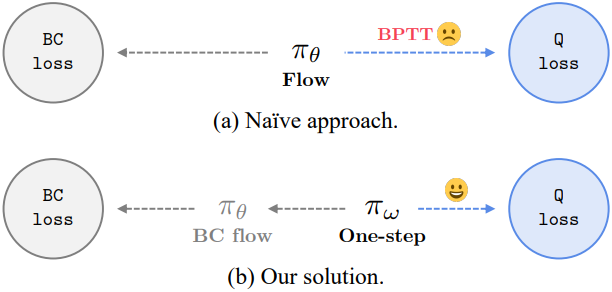
해결책
핵심 아이디어는 원래의 flow policy를 전혀 조종하지 않는 것이다. 대신, BC loss만을 사용하여 flow policy를 학습시키고, 전체 BC flow policy에서 distillation loss로 정규화하면서 value function을 최대화하는 별도의 표현력이 풍부한 one-step policy를 학습시킨다. One-step policy는 반복적인 프로세스를 포함하지 않으므로 Q loss에서 BPTT를 완전히 피할 수 있다.
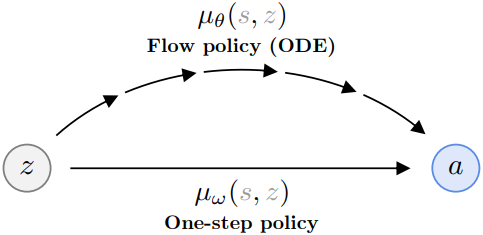
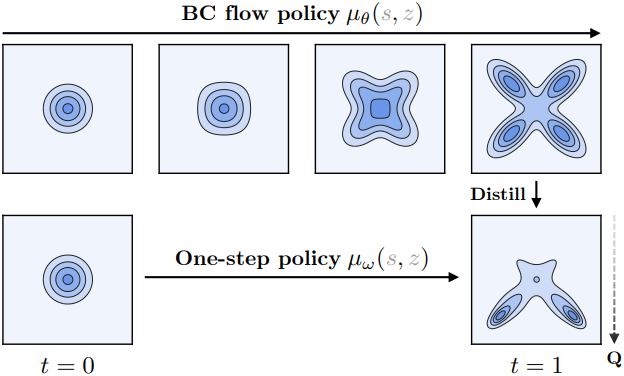
구체적으로, BC flow matching loss만을 사용하여 flow policy \(\mu_\theta (s, z)\)를 학습시킨다. 동시에, 파라미터 $\omega$를 갖는 one-step policy \(\mu_\omega (s, z)\)를 학습시키는데, 이 모델의 주요 역할은 noise $z$에서 전체 ODE flow policy \(a = \mu_\theta (s, z)\)의 출력 action으로의 직접 매핑을 학습하는 동시에 값을 최대화하는 것이다.
Distillation loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{Distill} (\omega) = \mathbb{E}_{s \sim \mathcal{D}, z \sim \mathcal{N}(0, I_d)} [\| \mu_\omega (s, z) - \mu_\theta (s, z) \|_2^2] \end{equation}\]\(\mu_\theta (s, z)\)는 vector field \(v_\theta\)로 정의된 ODE의 출력이다. 중요한 것은 distillation loss를 사용하여 고품질 샘플을 생성하는 표현력이 뛰어난 one-step 모델을 학습하는 것이 가능하다는 점이다.
Flow Q-learning (FQL)
FQL은 critic \(Q_\phi (s, a)\), BC flow policy \(\mu_\theta (s, z)\), 그리고 one-step policy \(\mu_\omega (s, z)\)의 세 가지 구성 요소로 이루어져 있다. 먼저, BC flow policy는 flow matching loss만을 사용하여 학습된다. Critic은 원래의 actor-critic loss를 사용하여 학습되는데, \(\pi_\theta\) one-step policy \(\pi_\omega\)를 사용한다. 마지막으로, one-step policy는 다음과 같은 actor loss를 사용하여 학습된다.
\[\begin{equation} \mathcal{L}_\pi (\omega) = \underbrace{\mathbb{E}_{s \sim \mathcal{D}, a^\pi \sim \pi_\omega} [-Q_\phi (s, a^\pi)]}_{\textrm{Q loss}} + \underbrace{\alpha \mathcal{L}_\textrm{Distill} (\omega)}_{\textrm{BC loss}} \end{equation}\]또한 distillation loss는 이제 BC flow policy를 기반으로 하는 behavioral regularizer로 사용된다. 이 알고리즘의 출력은 one-step policy \(\pi_\omega\)이다. 전체 알고리즘을 아래와 같다.

FQL이 좋은 이유
FQL은 세 가지 장점을 가지고 있다.
- 가장 효과적인 policy 추출 방법 중 하나로 알려져 있는 policy gradient를 활용한다. 동시에 불안정하고 비용이 많이 드는 BPTT를 완전히 회피한다.
- 효율적인 one-step policy를 출력으로 제공하므로 inference 시 반복적인 프로세스를 제거하면서도 전체 flow model의 표현력을 대부분 유지한다.
- 구현과 튜닝이 간편하다. Flow matching이 간단하기 때문에 표준 actor-critic 프레임워크 위에 몇 줄의 코드로 구현할 수 있으며, noise schedule을 튜닝할 필요 없이 hyperparameter $\alpha$ 하나만으로 충분하다.
Experiments
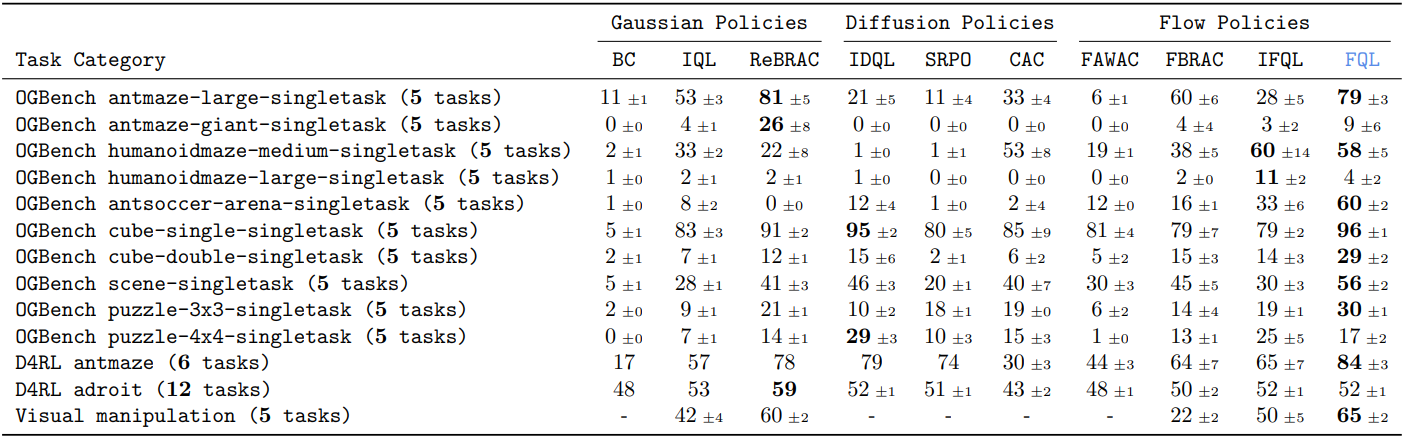
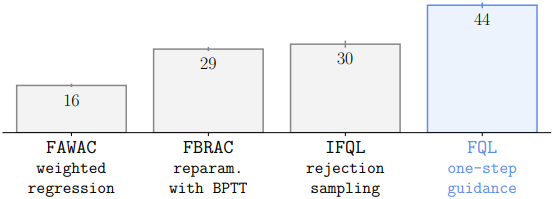
다음은 offline RL 결과이다.
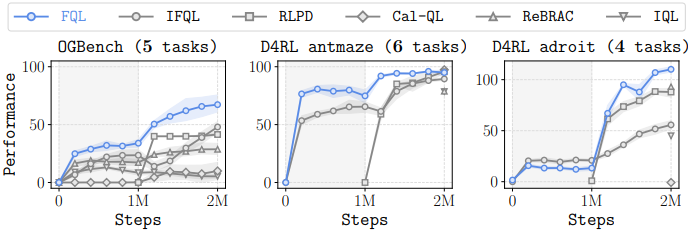
다음은 offline-to-online RL 결과이다. (100만 step에서부터 online fine-tuning)
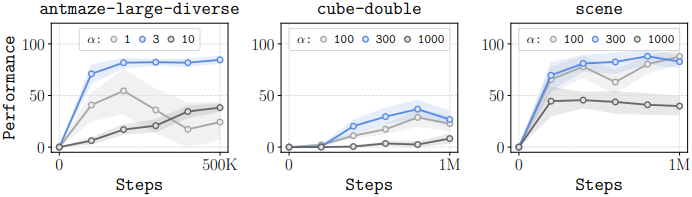
다음은 $\alpha$에 따른 성능을 비교한 그래프이다.
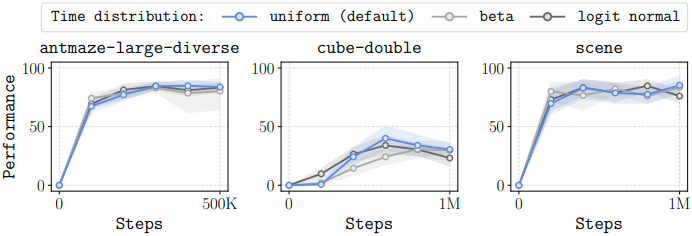
다음은 flow model의 시간 샘플링 분포에 따른 성능을 비교한 그래프이다.
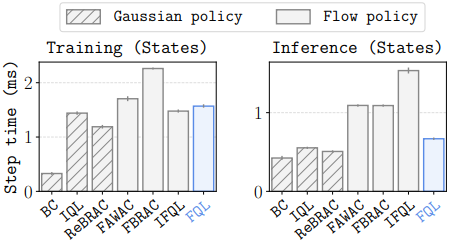
다음은 학습 시간과 inference 시간을 비교한 그래프이다.