[논문리뷰] LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
arXiv 2026. [Paper] [Page] [Github]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Chen Sun, Ming-Hsuan Yang, Forrester Cole, Trevor Darrell, Deqing Sun
Google DeepMind | UC Berkeley
3 Mar 2026
Introduction
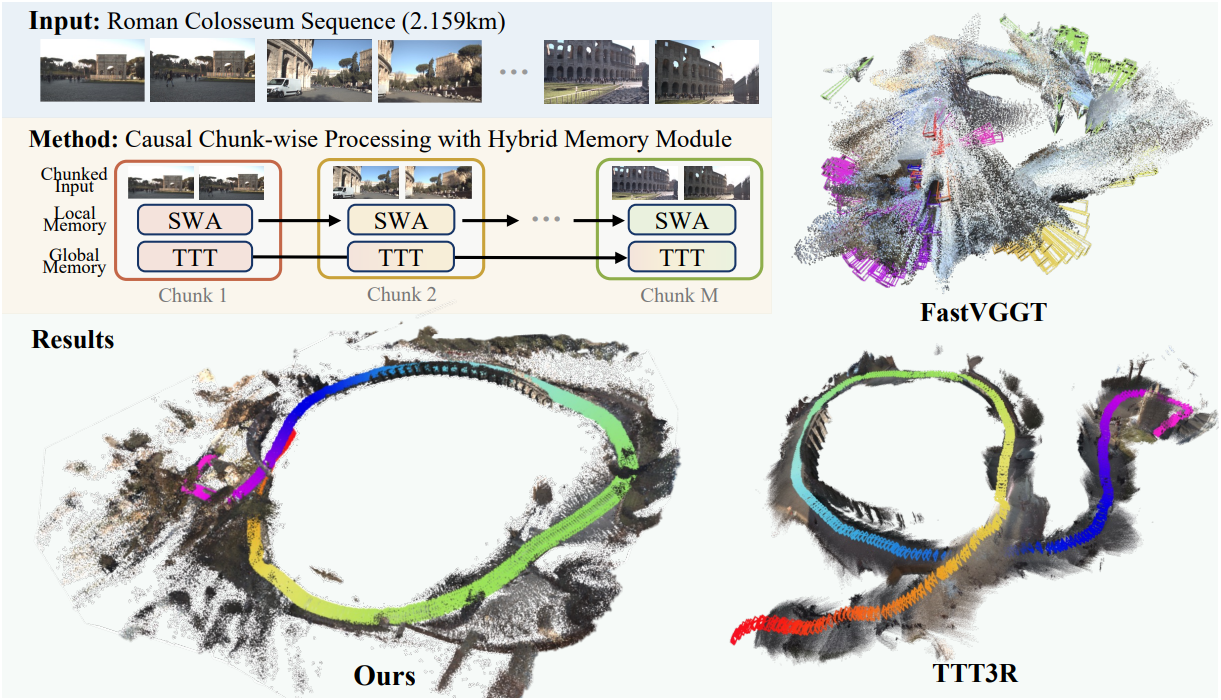
최근 geometric foundation model들이 패러다임 전환을 주도하고 있다. 이러한 모델들은 방대한 데이터셋에서 복잡한 geometric prior를 추출함으로써, 기존 dense 3D reconstruction 방식들이 실패하는 경우에도 강력한 feedforward inference를 가능하게 한다. 그러나 기존 dense 3D reconstruction 파이프라인은 도시 스케일까지 확장 가능한 반면, 현재 feedforward 모델은 제한된 장면에만 적용 가능하다.
이러한 scaling의 주요 장애물은 두 가지이다. 하나는 현재 아키텍처에 내재된 근본적인 “컨텍스트 장벽”이고, 다른 하나는 학습 과정에서 발생하는 심각한 “데이터 장벽”이다. 아키텍처적으로, bidirectional attention은 복잡한 geometric prior를 학습하는 데 필수적이지만, 제곱 복잡도로 인해 짧은 context window에서만 사용이 제한된다. 데이터 관점에서, 현재 모델들은 주로 짧은 컨텍스트들에서 학습되므로, inference 시에 long-range dependency를 통합하는 데 근본적으로 부적합하다.
방대한 양의 장기 데이터셋이 필요한 다양성과 정확도를 갖추도록 큐레이션할 때까지 기다리지 않고 이러한 데이터 장벽을 극복하기 위해, 저자들은 end-to-end 방식의 chunk 단위 처리가 실용적이고 효과적인 전략이라고 주장한다. 시퀀스를 분해하면 로컬 inference가 기존의 단기 컨텍스트 학습 데이터에 대해 in-distribution 상태를 유지할 수 있으며, $\pi^3$와 같은 강력한 bidirectional attention 기반 baseline을 활용할 수 있다. 그러나 이 패러다임은 chunk 경계를 넘나드는 메모리 관리와 일관성 유지라는 중요한 새로운 과제를 제시한다.
긴 시퀀스에 걸쳐 높은 충실도의 dense 3D reconstruction을 달성하려면 세 가지 수준의 일관성 사이의 균형을 맞춰야 한다.
- Window 내 디테일
- 고정밀 로컬 정렬을 위한 압축되지 않은 컨텍스트
- 멀리 떨어져 있는 프레임에 대한 글로벌한 구조적 무결성
기존 모델들은 이러한 상충되는 요구 사항 사이의 균형을 맞추지 못한다. 예를 들어, CUT3R와 같은 recurrent 접근 방식은 모든 시간적 컨텍스트를 하나의 hidden state로 손실 압축하여, 부드러운 인접 정렬에 필요한 고정밀 정보를 희생한다. 반대로, 단순한 deterministic stitching 방식은 로컬 디테일은 보존하지만, scale drift를 방지하는 데 필요한 장기 기억 기능이 부족하다.
이러한 실패는 단일 메모리 전략이 근본적으로 불충분함을 시사한다. 이러한 격차를 해소하기 위해, 본 논문은 고정된 연산 예산 내에서 멀티스케일 기하학적 일관성을 유지하는 학습 기반 하이브리드 메모리 모듈을 제안하였다. 저자들은 이를 이중 메모리 시스템으로 구체화하였다. 하나는 압축되지 않은 로컬 feature와 가장 최근 chunk에 대한 고화질 디테일을 보존하는 sliding-window attention (SWA) 메커니즘이고, 다른 하나는 글로벌 컨텍스트를 압축하는 Test-Time Training (TTT) 메모리이다. TTT 메모리는 글로벌 좌표계를 고정하여 scale drift를 방지하며, SWA 메모리는 매끄럽고 높은 정밀도의 전환을 보장한다.
Method
1. Long-Context 3D Reconstruction Architecture
Motivation
분 단위의 동영상에 대한 feedforward 방식의 dense 3D reconstruction을 scaling하려면 global attention의 제곱 복잡도와 장기 학습 데이터 부족 문제를 극복해야 한다. End-to-end 방식의 chunk 단위 처리가 자연스러운 해결책으로 떠오르는데, 이는 계산 비용을 엄격하게 제한하고 로컬 inference가 기존의 짧은 컨텍스트 학습 데이터 분포 내에 유지되도록 보장한다. 그러나 chunk를 독립적으로 처리하는 방식은 본질적으로 글로벌 일관성을 깨뜨린다. 따라서 다음과 같은 세 가지 기능을 동시에 제공하는 feedforward 아키텍처가 필요하다.
- Dense한 geometry 충실도를 유지하기 위해 짧은 chunk 내에서 강력한 로컬 양방향 추론을 제공해야 한다.
- 인접한 chunk 경계를 넘어 고정밀 geometry 정렬을 유지하기 위해 손실 없는 단거리 정보 통로를 제공해야 한다.
- 수천 개의 프레임에 걸쳐 장거리 글로벌 전파를 위한 선형 시간, 고정 크기 메모리 메커니즘을 갖추도록 해야 한다.
Overview
입력 동영상 스트림을 chunk 단위로 순차적으로 처리한다. 동영상 \(\mathcal{X} = \{I_t\}_{t=1}^T\)이 주어지면, 이를 최소한의 중첩으로 $M$개의 chunk \(\{\mathcal{C}^m\}_{m=1}^M\)로 분할한다. 각 chunk $\mathcal{C}^m$은 가변적인 수의 프레임 \(\mathcal{C}_j^m\)로 구성되며, $j$는 chunk 내의 프레임 인덱스이다. 각 chunk 내에서는 고품질의 dense한 예측을 얻기 위해 bidirectional geometry backbone (ex. VGGT, $\pi^3$)을 사용한다. Chunk 간 정보 전파를 위해 두 가지 상호 보완적인 메커니즘을 사용한다.
(1) Chunk-wise TTT를 통한 장기적인 손실 압축 방식. 다수의 chunk에 걸쳐 fast weight $W$를 유지하는 TTT layer를 삽입한다. Chunk 단위 처리에 맞춰 표준 TTT보다 효율적인 것으로 입증된 LaCT를 활용한다. Inference 시, 각 chunk에 대해 fast weight는 update 연산과 apply 연산을 거친다. Apply 연산에서 TTT layer는 fast weight에 저장된 과거 정보를 사용하여 현재 chunk에 대한 네트워크 처리를 조절한다. Update 연산에서는 현재 chunk의 정보를 저장하도록 fast weight를 수정하여 중요하지만 중복되는 기하학적 정보를 개념적으로 압축한다. Fast weight는 이론적으로 무한한 receptive field를 제공하지만, 실제 용량은 학습 컨텍스트 길이에 의해 제한된다. 매우 긴 학습 기간 동안의 drift를 방지하기 위해 inference 중에 주기적인 state 재설정을 선택적으로 적용한다.
(2) Sliding-window attention (SWA)을 통한 단기 무손실 전송. TTT 방식의 state 전달에만 의존하는 것은 본질적으로 손실이 발생하며, 이는 인접 프레임 간의 기하학적 일관성이 중요한 dense 3D reconstruction에서 문제가 된다. 이를 완화하기 위해, 이전 chunk \(\mathcal{C}^{m-1}\)와 현재 chunk \(\mathcal{C}^m\) 모두에 대하여 frame attention layer의 출력 토큰에 attention하는 SWA layer를 드물게 삽입한다. 이를 통해 이전 chunk의 고충실도 feature를 직접 전달하는 무손실 정보 통로가 구축된다. 중요한 것은, SWA가 인접한 chunk 간에만 적용되고 단 4개의 layer에만 삽입되므로 제한된 연산량과 메모리 사용량으로도 효율적인 연산이 가능하다는 점이다.
이 두 가지 chunk 간 경로는 상호 보완적이다. TTT는 scalable한 장거리 메모리를 제공하는 반면, SWA는 인접한 chunk 간에 세밀한 기하학적 일관성을 보장한다.
Block structure
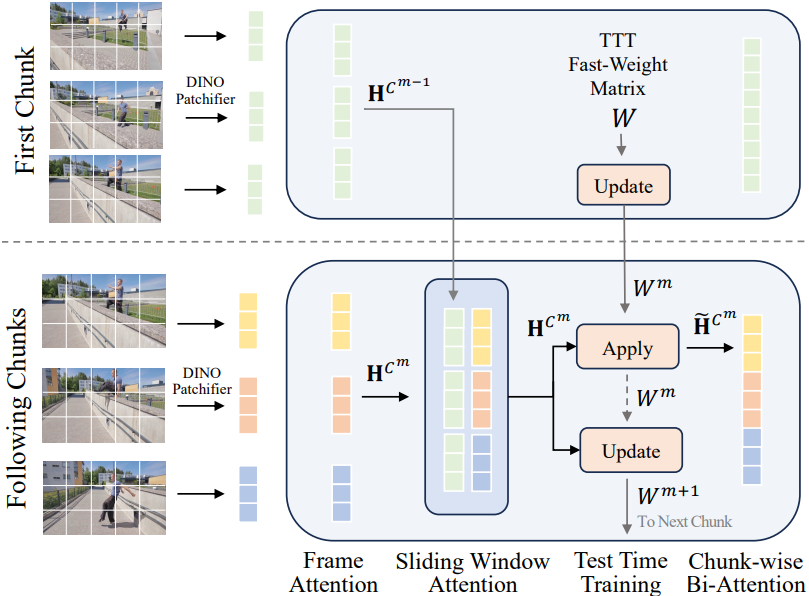
Geometry backbone은 먼저 이미지를 토큰으로 patchify하고 이를 residual network block 스택에 입력한다. 각 block에는 하이브리드 메모리 시스템을 도입한다. Inference 시 고정되는 slow weight를 $\theta$로 나타내고, \(\textbf{H}^{\mathcal{C}^m}\) chunk $m$에 대해 block으로 입력되는 전체 토큰 시퀀스라 하자. 한 block의 디테일한 구조는 다음과 같다.
(1) Per-frame attention. 공간적 feature를 추출하기 위해 각 프레임의 토큰에 독립적으로 self-attention을 적용한다.
\[\begin{equation} \textbf{H}^{\mathcal{C}^m} \leftarrow \textbf{H}^{\mathcal{C}^m} + \left[\textrm{Attn}_\textrm{frame} \left( \textrm{LN} (\textbf{H}^{\mathcal{C}^m}); \theta \right) \vert i \in \{1, \ldots, n\} \right] \end{equation}\]($\textrm{LN}(\cdot)$은 LayerNorm, $[\cdot]$는 concat 연산자)
(2) Sparse sliding-window attention (SWA). 인접한 chunk를 정렬하기 위해, 특정 layer에만 SWA layer를 삽입한다.
\[\begin{equation} \textbf{H}^{\mathcal{C}^m} \leftarrow \textbf{H}^{\mathcal{C}^m} + \textrm{Attn}_\textrm{swa} \left( [\textrm{LN} (\textbf{H}^{\mathcal{C}^{m-1}}), \textrm{LN} (\textbf{H}^{\mathcal{C}^m})]; \theta \right) \end{equation}\](3) Chunk-wise TTT layer. 글로벌 컨텍스트를 통합하기 위해, chunk $m$까지의 정보를 요약하는 fast weight 집합 $W^m$을 유지한다. TTT layer는 chunk 수준에서 apply 연산 후 update 연산을 수행한다. 장기 스트리밍을 안정화하기 위해 TTT 내부에서 pre-norm을 사용한다.
\[\begin{aligned} \textrm{Apply}: \quad & \tilde{\textbf{H}}^{\mathcal{C}^m} = \textbf{H}^{\mathcal{C}^m} + f_{W^m} \left( \textrm{LN} (\textbf{H}^{\mathcal{C}^m}) \right) \\ \textrm{Update}: \quad & W^{m+1} = \mathcal{U} (W^m; \textbf{H}^{\mathcal{C}^m}) \end{aligned}\]($f_{W^m} (\cdot)$은 $W^m$만으로 parameterize된 fast weight 모듈 (SwiGLU MLP), $\mathcal{U}(\cdot)$은 online update rule)
직관적으로, apply 단계는 현재 메모리를 토큰 표현에 주입하고, update 단계는 chunk의 요약을 다음 chunk를 위해 $W$에 기록한다.
(4) Chunk-wise bidirectional attention. 마지막으로, 각 chunk 내에서 제한된 context window 하에서 강력한 기하학적 추론을 위해 bidirectional attention 모듈을 사용한다. 업데이트된 표현 \(\textbf{H}^{\mathcal{C}^m}\)은 이후 block의 입력으로 사용된다.
\[\begin{equation} \textbf{H}^{\mathcal{C}^m} \leftarrow \tilde{\textbf{H}}^{\mathcal{C}^m} + \textrm{BiAttn}_\textrm{chunk} \left( \textrm{LN} (\tilde{\textbf{H}}^{\mathcal{C}^m}); \theta \right) \end{equation}\]Prediction heads. 최종 block 이후에는 가벼운 pointmap 디코더와 카메라 포즈 디코더를 연결하여 최종 pointmap 예측과 프레임별 카메라 포즈를 생성한다.
2. Learning Objectives
Objective
본 논문에서는 $\pi^3$를 따라, scale-invariant local pointmap loss와 affine-invariant relative pose loss를 사용하여 LoGeR를 학습시킨다. 이때 loss는 레퍼런스 뷰를 필요로 하지 않는다.
예측된 로컬 pointmap은 MoGe에서와 같이 시퀀스별 하나의 scale $s^\ast$로 정렬하고, 모든 픽셀에 대해 깊이 값으로 정규화된 reconstruction loss를 계산한다. 긴 시퀀스 학습을 더욱 엄격하게 제약하기 위해, 예측된 카메라 포즈를 사용하여 로컬 pointmap을 변환하여 얻은 월드 좌표 pointmap에 global pointmap loss를 추가로 적용한다.
\[\begin{aligned} \mathcal{L}_\textrm{local} &= \frac{1}{N \vert \Omega \vert} \sum_{i=1}^N \sum_{p \in \Omega} \frac{1}{z_{i,p}} \| s^\ast \hat{\textbf{x}_{i,p} - \textbf{x}_{i,p}} \|_1 \\ \mathcal{L}_\textrm{pose} &= \sum_{(i,j) \in \mathcal{P}} \left( \lambda_r \mathcal{L}_\textrm{rot} (\hat{\textbf{R}}_{ij}, \textbf{R}_{ij}) + \lambda_t \| s^\ast \hat{\textbf{t}}_{ij} - \textbf{t}_{ij} \|_\textrm{Huber} \right) \\ \mathcal{L}_\textrm{global} &= \frac{1}{N \vert \Omega \vert} \sum_{i=1}^N \sum_{p \in \Omega} \| s^\ast \Pi (\hat{\textbf{T}}_i, \hat{\textbf{x}}_{i,p}) - \Pi (\textbf{T}_i, \textbf{x}_{i,p}) \|_1 \\ \mathcal{L} &= \mathcal{L}_\textrm{local} + \mathcal{L}_\textrm{pose} + \lambda_\textrm{global} \mathcal{L}_\textrm{global} \end{aligned}\]($N$은 프레임 수, $\Omega$는 픽셀 집합, \(\hat{\textbf{x}}_{i,p} \in \mathbb{R}^3\)는 예측된 로컬 포인트 좌표, \(\textbf{x}_{i,p} \in \mathbb{R}^3\)는 GT 로컬 포인트 좌표, \(z_{i,p}\)는 정규화를 위한 깊이, $\hat{\textbf{T}}_i = [\hat{\textbf{R}}_i \vert \hat{\textbf{t}}_i]$는 예측된 카메라 포즈, $\textbf{T}$는 GT 카메라 포즈, $\mathcal{P}$는 프레임 쌍 집합, $\Pi$는 포인트 좌표 변환 연산)
LoGeR* feedforward alignment
TTT와 SWA가 있음에도 불구하고 매우 긴 스트림에서는 여전히 예측 오차가 누적될 수 있다. 저자들은 이를 완화하기 위해, 예측값을 일관된 전역 좌표계로 정렬하기 위한 순수 feedforward 정렬 단계를 통합한 버전인 LoGeR*를 도입하였다.
현재 chunk \(\mathcal{C}^m\) 내에서 겹치는 프레임 $k$의 예측 포즈를 \(\hat{\textbf{T}}_k^{(m)}\)라 하고, chunk \(\mathcal{C}^{m-1}\)의 정렬된 포즈를 \(\tilde{\textbf{T}}^{(m-1)}\)라 하자. \(\tilde{\textbf{T}}^{(1)} = \hat{\textbf{T}}^{(1)}\)로 초기화된다. \(\mathcal{C}^m\)을 \(\mathcal{C}^{m-1}\)의 정렬된 좌표계로 겹침을 이용하여 매핑하는 SE(3) 정렬 \(\textbf{A}_m\)을 다음과 같이 계산한다.
\[\begin{equation} \textbf{A}_m = \tilde{\textbf{T}}_k^{(m-1)} (\hat{\textbf{T}}_k^(m))^{-1} \end{equation}\]이 변환은 \(\mathcal{C}^m\)의 모든 프레임에 적용된다.
\[\begin{equation} \tilde{\textbf{T}}_t^{(m)} = \textbf{A}_m \hat{\textbf{T}}_t^{(m)}, \quad \forall t \in \mathcal{C}^m \end{equation}\]학습과 inference 모두에서 LoGeR*의 최종 카메라 포즈 예측값으로 \(\tilde{\textbf{T}}_t^{(m)}\)를 사용한다.
3. Data and Curriculum
Data Wall

아키텍처 개선만으로는 무한 컨텍스트 reconstruction에 충분하지 않다. VGGT의 inference 효율성을 개선한 FastVGGT도 짧은 컨텍스트 또는 소규모 장면 규모의 데이터만으로 학습했을 경우 대규모 장면에 대한 일반화 성능이 저하된다. 이를 극복하기 위해, 본 논문에서는 대규모 장면 데이터셋(ex. TartanAirV2)에 높은 가중치를 부여한 학습 혼합 모델을 구축했다. 이 모델은 효과적인 geometry 압축 학습에 필요한 장기적인 신호를 제공한다.
Curriculum Training
순환적인 TTT layer의 최적화를 안정화하기 위해 점진적 커리큘럼 전략을 사용한다. 쉬운 시퀀스부터 시작하여 점진적으로 복잡성을 증가시킴으로써, 모델이 로컬 SWA에서 글로벌 TTT hidden state에 대한 의존도로 전환하도록 한다. 본 논문의 학습 스케줄은 세 단계로 진행된다.
- 48개의 프레임을 4개의 chunk로 나누어 시작한다.
- 시퀀스 길이는 고정한 채, chunk 밀도를 점진적으로 늘려 12개의 chunk까지 확장한다.
- H200 GPU를 활용하여 컨텍스트 길이를 128 프레임까지 확장하고, 동시에 chunk 수를 점진적으로 20개까지 증가시킨다.
LoGeR*의 경우, 1단계 모델에서 초기화하고, feedforward 정렬을 통합한 후, 나머지 커리큘럼을 통해 fine-tuning한다. 이 전략은 학습 효율성을 향상시킬 뿐만 아니라, 최종 성능도 향상시킨다.
Experiments
- 데이터셋: ARKitScenes, DL3DV, HyperSim, MegaDepth, ScanNet, ScanNet++, Spring, TartanAir, TartanAirV2, UnReal4K, Virtual KITTI 2, Waymo, OmniWorld-Game
- 구현 디테일
- optimizer: AdamW
- steps: 4만
- batch size: 32
- GPU: H100 32개로 2일 + H200 32개로 추가 2일
- $\pi^3$의 patchifier, frame attention, chunk-wise bidirectional attention 모듈로 가중치 초기화
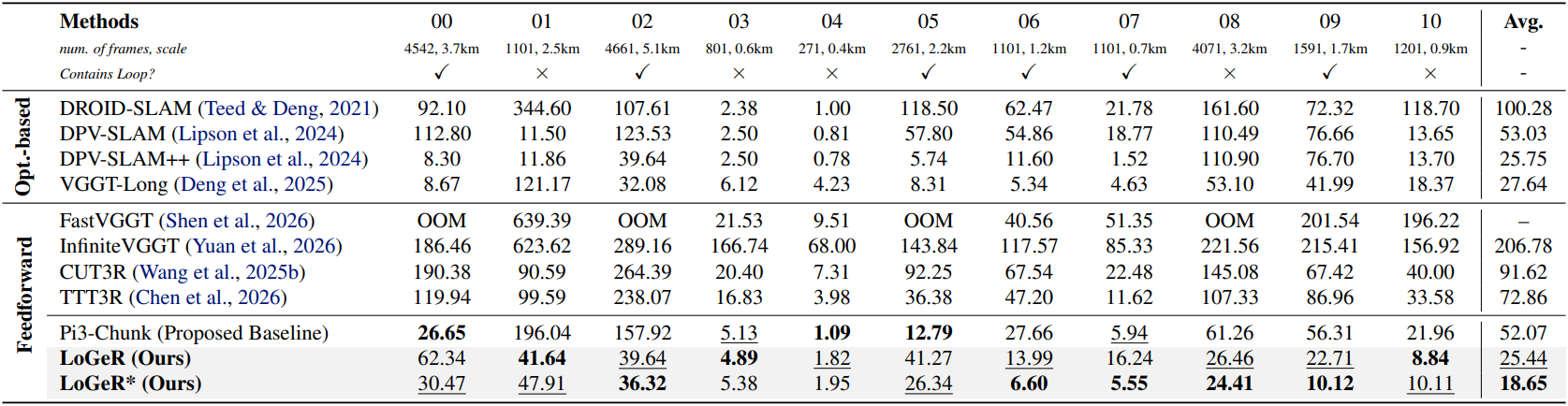
1. Evaluation on Long Sequences
다음은 KITTI에서 Absolute Trajectory Error (ATE, m)를 비교한 결과이다.
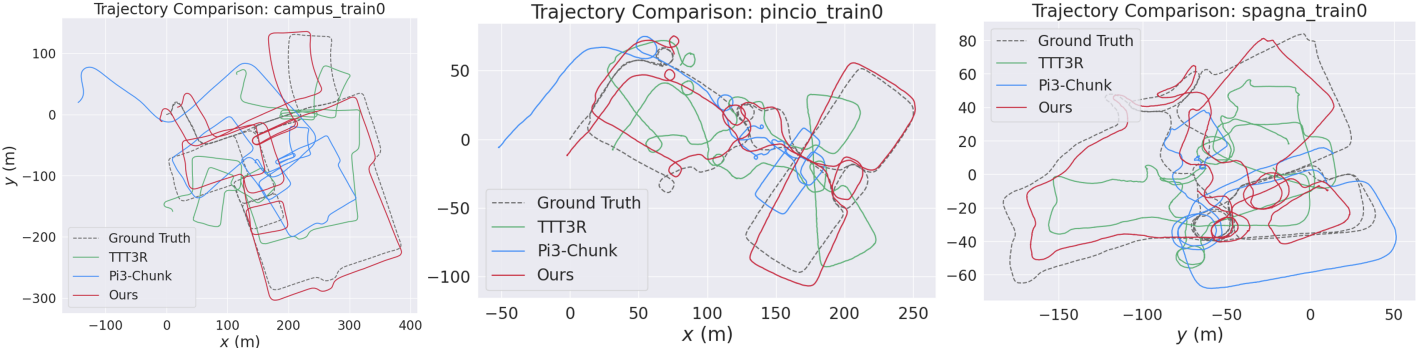
다음은 VBR 데이터셋에 대한 비교 결과이다.
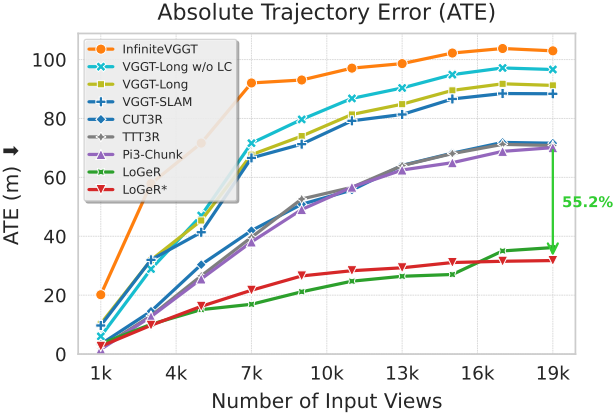
2. Evaluation on Short Sequences
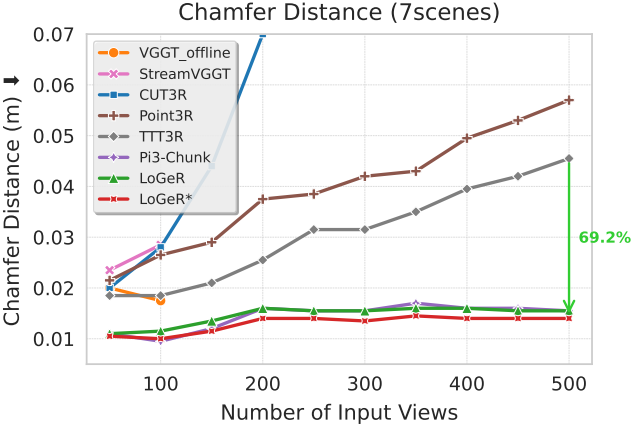
다음은 7scenes 데이터셋에 대한 비교 결과이다.

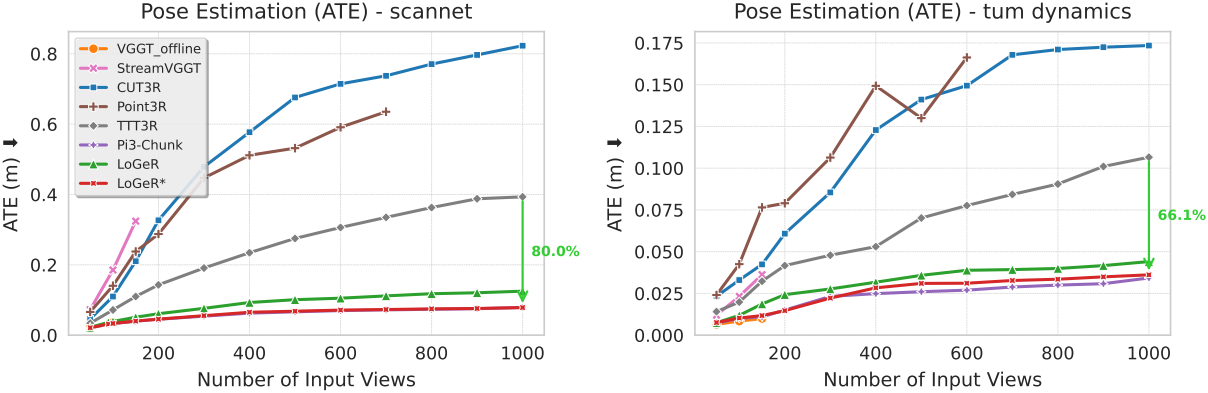
다음은 ScanNet과 TUM-Dynamics에 대한 비교 결과이다.

3. Ablation Study
다음은 ablation study 결과이다.
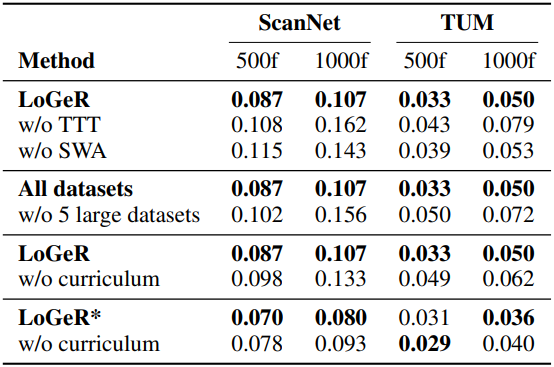
다음은 SWA와 TTT에 대한 ablation 결과이다.
