[논문리뷰] Test-Time Training Done Right
ICLR 2026. [Paper] [Page] [Github]
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T. Freeman, Hao Tan
MIT | Adobe Research
29 May 2025
Introduction
Test-Time Training (TTT)은 주로 TTT layer의 하드웨어 활용률이 극히 낮기 때문에 긴 컨텍스트에 효과적으로 확장하는 데 어려움을 겪고 있다. 이러한 비효율성은 작은 mini-batch 크기, 즉 in-context learning에 더 효과적이라고 일반적으로 여겨지는 매 토큰 또는 16~64개의 토큰마다 fast weight를 업데이트하는 방식에서 비롯된다. 이러한 작은 mini-batch는 병렬성을 저해하고 계산 강도를 낮추며, 특히 크고 비선형적인 fast weight를 사용할 때 하드웨어 효율적인 구현에 상당한 어려움을 초래하여 10% 이상의 FLOPs 활용률을 달성하기 어렵게 만든다.
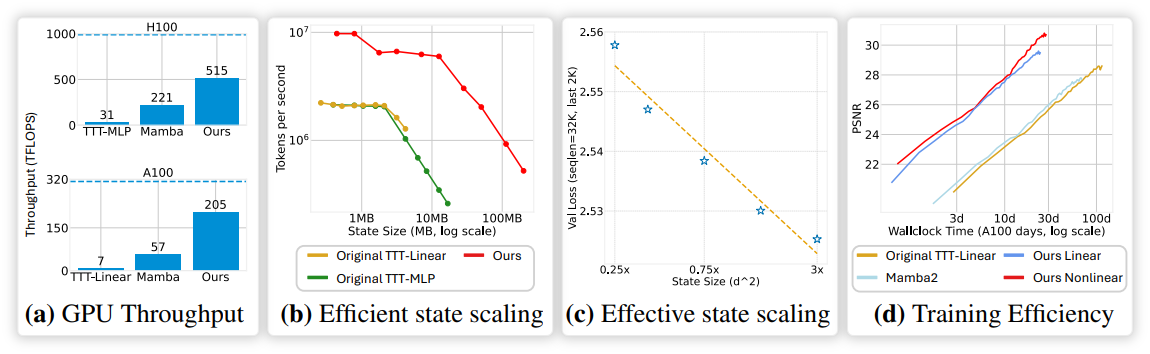
본 논문에서는 정반대의 전략을 채택하여 Large Chunk Test-Time Training (LaCT)을 도입하였다. LaCT는 매우 큰 chunk (2048~100만 토큰)를 기본 단위로 사용하여 fast weight를 업데이트한다. 각 chunk 내의 토큰들은 순서가 없는 집합으로 처리되므로, chunk 내의 local dependency를 포착하기 위해 window attention 을 LaCT에 통합했다. LaCT는 병렬 처리를 크게 향상시켜, 순수 PyTorch 코드 수십 줄만으로도 GPU 활용률을 상당히 높인다 (NVIDIA A100에서 최대 70% 달성). 이러한 효율성 덕분에 비선형적인 fast weight의 확장이 가능해져 메모리 용량을 향상시킬 수 있다. 또한, 간단한 구현으로 Muon과 같은 더욱 효율적인 test-time optimizer를 쉽게 통합할 수 있다.
또한, LaCT의 large-chunk 설계는 chunk 크기를 데이터의 내부 구조와 일치시킬 수 있기 때문에 다양한 $N$차원 데이터를 모델링하는 데에도 적합하다. (ex. 이미지 내의 토큰이나 연속적인 동영상 프레임을 하나의 chunk로 그룹화)
본 논문에서는 다양한 모달리티와 데이터 구조를 아우르는 세 가지 task에서 LaCT를 광범위하게 검증했다.
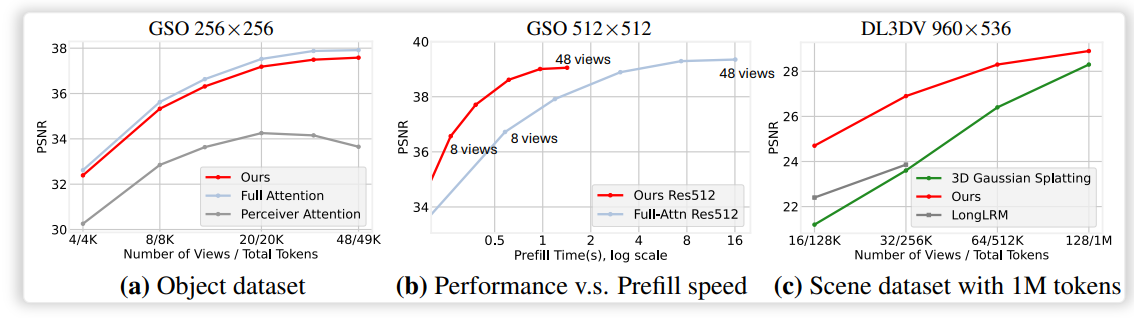
- Novel View Synthesis: 960$\times$536 해상도의 입력 이미지 최대 128개를 처리하여 최대 100만 개의 토큰을 생성할 수 있으며, 이러한 입력 규모에서 렌더링 품질 측면에서 3DGS보다 우수한 성능을 보였다.
- 언어 모델링: 언어 데이터에 chunk 구조가 명시적으로 존재하지 않음에도 불구하고, DeltaNet과 같은 SOTA 방법과 비교하여 경쟁력 있는 성능을 달성하였다.
- Autoregressive Video Diffusion: 저자들은 14B 파라미터의 양방향 video diffusion transformer에 sliding window attention을 적용한 LaCT를 통합하여 autoregressive model로 변환했다. 이 모델은 최대 56,000개의 토큰까지 일관된 동영상을 생성한다.
Preliminary
1. Test-Time Training
$N$개의 토큰으로 이루어진 1D 시퀀스 $\textbf{x} = [x_1, \ldots, x_N]$를 고려해 보자. 여기서 각 토큰 $x_i \in \mathbb{R}^d$이다. Attention 메커니즘에 따라, 각 입력 토큰 $x_i$는 query $q_i$, key $k_i$, value $v_i$로 projection된다. $q_i$, $k_i$, $v_i$ 모두 $d$차원 벡터라고 가정하자.
Test-Time Training (TTT)는 학습과 inference 모두에서 컨텍스트 정보를 동적으로 저장하기 위해 빠르게 적응하는 가중치, 즉 fast weight를 가진 신경망을 도입하였다. 이는 inference 시에 고정되는 slow weight, 즉 모델 파라미터와 대조된다. TTT는 fast weight를 신경망 형태인 $f_W(\cdot) : \mathbb{R}^d \rightarrow \mathbb{R}^d$로 정의하며, 이는 fast weight $W$로 parameterize되고 두 가지 주요 연산을 포함한다.
\[\begin{equation} \textrm{Update operation}: \qquad W \leftarrow W - \eta \nabla_W \mathcal{L} (f_W (k), v) \\ \textrm{Apply operation}: \qquad o = f_W (q) \end{equation}\]($\mathcal{L}(\cdot, \cdot)$은 loss function (일반적으로 MSE), $\eta$는 learning rate)
Loss function은 네트워크가 key와 대응되는 value를 연결하도록 유도하기 위해 설계되었다. 즉, KV 캐시를 가능한 한 정확하게 고정된 state 크기를 가진 뉴럴 메모리에 인코딩되도록 하는 것이 목표이다. Per-token TTT layer는 각 토큰 $x_i$에 대해 순차적으로 update 연산과 apply 연산을 반복적으로 수행한다.
2. Challenges in Efficient Implementation
메모리 대역폭 제한으로 인해 fast weight를 빈번하게 온라인으로 업데이트하는 것은 비효율적이다. 따라서 기존 방법들은 메모리 부하를 줄이기 위해 업데이트 시 fast weight을 SRAM에 저장하는 맞춤형 커널을 사용하는 경우가 많았다. 그러나 이 전략은 일반적으로 통신량을 줄이기 위해 fast weight가 Streaming Multiprocessor (SM) 내에서 대부분 독립적으로 진화해야 한다는 전제를 깔고 있는데, 이는 큰 비선형 state에는 적합하지 않다. 더욱이 이러한 커널 코드를 개발하는 것은 번거롭고, PyTorch 코드보다 개발 주기가 훨씬 길어 신속한 연구 탐색을 저해한다.
반면에 PyTorch 기반 구현은 더 간단하지만 일반적으로 메모리 속도에 제약을 받는다. 예를 들어, 간단한 MLP fast weight의 PyTorch 구현을 생각해 보자. 이 구현의 핵심은 $h \times h$ 행렬의 fast weight와 $b \times h$ mini-batch 입력 ($b$는 chunk 크기) 간의 행렬 곱셈이다. 이상적인 연산량 대 메모리 비율은 다음과 같다.
\[\begin{equation} r = \frac{2 h^2 b}{2h^2 + 4hb} = \frac{b}{1 + 2b/h} \le \min (h/2, b) \end{equation}\]작은 fast weight 크기 또는 작은 chunk 크기는 비율 $r$을 이론적인 최대치(ex. H100에서 290)보다 훨씬 낮게 제한하여 연산이 메모리 제약을 받게 되고 컴퓨팅 사용량이 제한된다.
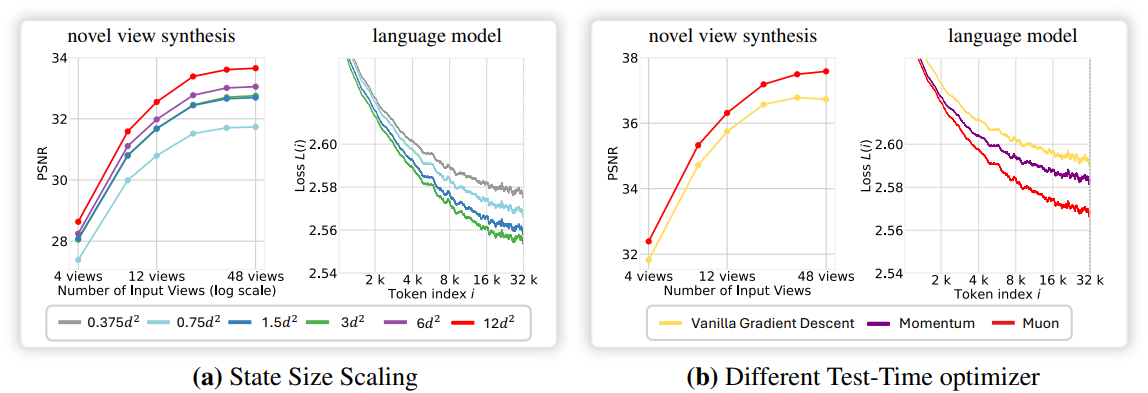
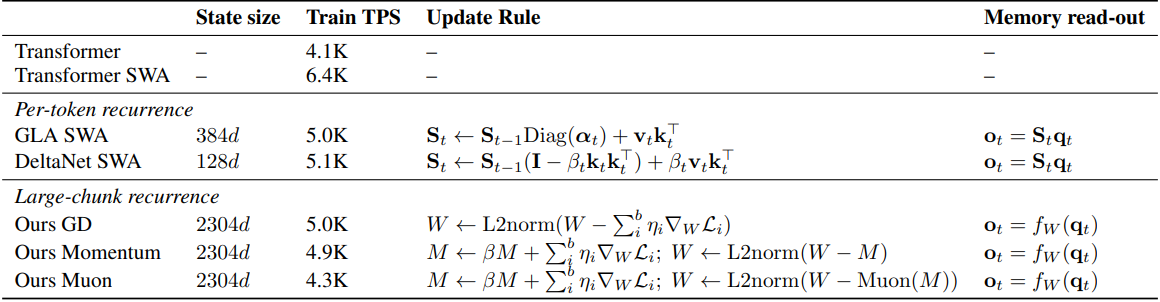
이러한 점을 고려하여, 본 논문은 큰 chunk 크기(2048~1M)를 사용할 것을 권장한다. 이를 통해 더 높은 처리량을 달성하고, 결과적으로 더 짧은 학습 시간 내에 더 나은 성능을 얻을 수 있다. 또한, 이러한 설계는 state 크기를 효율적으로 scaling할 수 있도록 하여, scaling을 통해 상당한 성능 향상을 가져온다. 본 논문의 아키텍처는 파라미터 크기 대비 state 크기 비율이 40% 이상으로, 기존 방법들의 0.1%~5% 비율보다 훨씬 높다.
LaCT Model Architecture
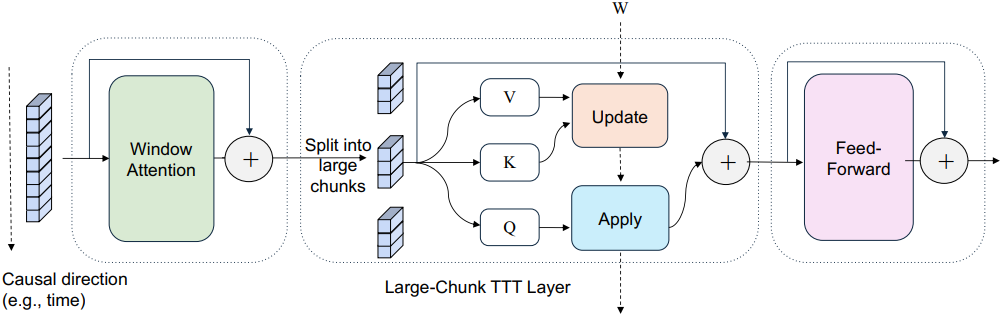
1. Large-Chunk TTT Layer
기존 TTT의 per-token update와 달리, chunk-wise update는 chunk 내의 모든 key \(\{k_i\}\)와 value \(\{v_i\}\)에 대한 loss 합계의 gradient를 계산한다. Chunk 크기가 크기 때문에 가중치 업데이트는 자주 수행되지 않는다. 이는 보다 정교한 가중치 update rule 설계를 가능하게 하고 업데이트 비용을 분산시킨다. Fast weight에 대한 update 연산은 다음과 같다.
\[\begin{equation} g = \nabla_W \sum_{i=1}^b \eta_i \mathcal{L} (f_W (k_i), v_i) \end{equation}\]($b$는 chunk 크기, $g$는 fast weight loss function의 gradient, \(\eta_i\)는 각 토큰의 learning rate (일반적으로 입력 토큰에서 예측됨))
Apply 연산 $o_i = f_W (q_i)$는 기존과 동일하며 chunk 내의 모든 query 벡터 \(\{q_i\}\)는 동일하게 업데이트된 fast weight $W$를 공유한다.
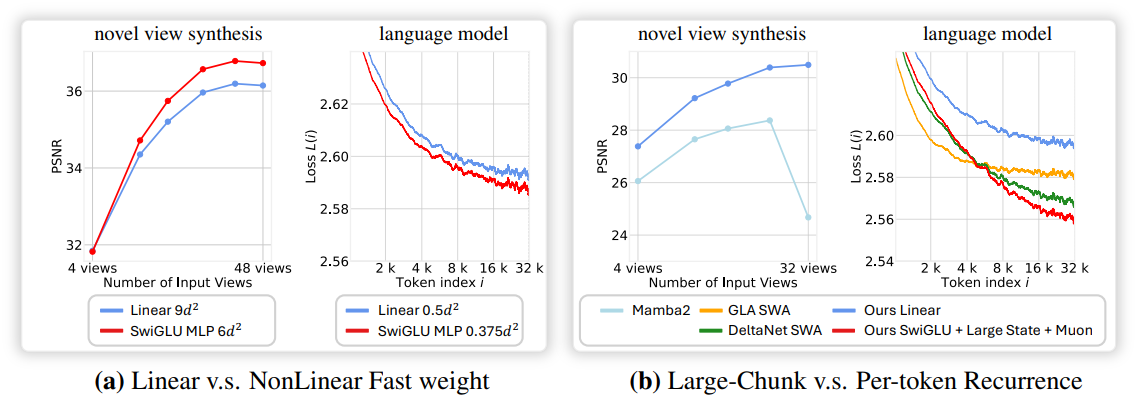
저자들은 Llama 2에서 영감을 받아, bias 항이 없는 SwiGLU-MLP를 fast weight 네트워크로 채택했다. 본 논문의 fast weight는 3개의 가중치 행렬 \(W = \{W_1, W_2, W_3\}\)로 구성되며, 네트워크는 다음과 같다.
\[\begin{equation} f_W (x) = W_2 [\textrm{SiLU} (W_1 x) \circ (W_3 x)] \end{equation}\]($\circ$는 elementwise multiplication)
Loss function으로 간단한 내적 loss를 적용한다.
\[\begin{equation} \mathcal{L} (f_W (k_i), v_i) = -f_W (k_i)^\top v_i \end{equation}\]Apply 연산과 Update 연산의 실행 순서
TTT의 update 연산과 apply 연산은 분리되어 있으며, chunk 크기를 적응적으로 설정하고 연산을 다양한 순서로 적용할 수 있다. 이를 통해 self-attention의 다양한 attention mask와 유사하게 다양한 종류의 데이터 dependency들을 모델링할 수 있다.
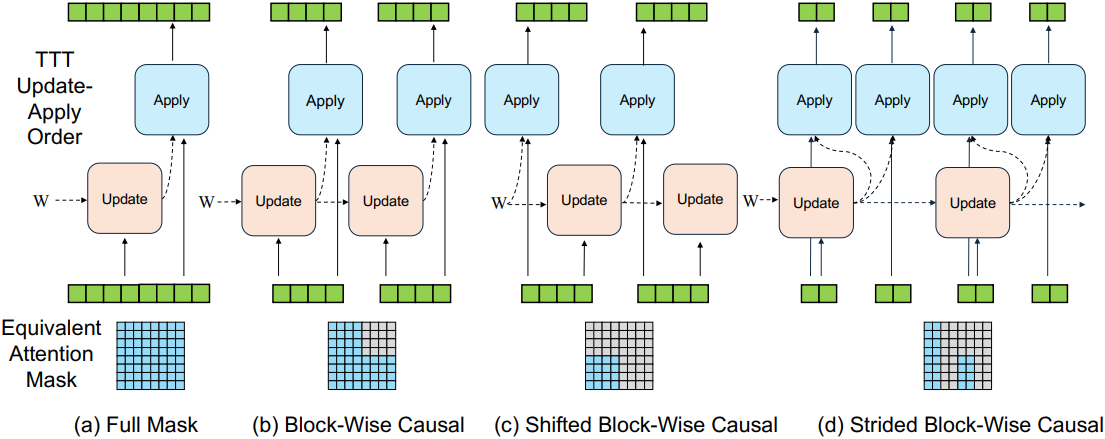
위 그림은 이 개념을 보여준다. Chunk 크기가 전체 시퀀스 길이와 같을 때, apply 연산 후 update 연산을 수행하는 것은 개념적으로 full attention과 유사하다. Update 연산과 apply 연산을 번갈아 사용하면 block-wise causal mask가 생성된다. 여기서 block 크기는 chunk 크기에 해당한다. 두 연산의 순서를 바꾸면 마스크가 shift된다. 이렇게 shift된 마스크는 chunk 내에서 미래 정보를 유출하지 않으며, 언어 모델링에서 causal mask를 구축할 때 중요하다. 또한, chunk의 일부에만 update 연산을 하고 전체에 apply 연산을 하는 것은 strided block-wise causal mask와 유사하다.
2. Non-Linear Update of Fast-Weight
TTT에서 fast weight 업데이트는 gradient를 반복적으로 누적하므로 magnitude explosion이나 decayed memory 문제가 발생한다. LaCT는 비선형 업데이트를 통해 효율성을 유지하면서 안정성과 효과를 향상시킨다.
Fast-weight 정규화
본 논문에서는 입력 차원을 따라 업데이트된 fast weight에 L2 가중치 정규화를 적용하였다.
\[\begin{equation} \textrm{weight-update}(W, g) = \textrm{L2-Normalize}(W - g) \end{equation}\]명시적인 weight decay 항은 사용하지 않는다. 네트워크를 개념적으로 90도 회전시켜 시퀀스 차원을 가상 모델의 깊이로 간주할 때, TTT 업데이트는 시간에 따른 residual 역할을 한다. 이러한 관점에서, fast weight 정규화는 Transformer 아키텍처에서 activation scale을 residual 경로 내에 제한하는 post-layer norm과 유사하다.
Muon update rule
또한 저자들은 가중치 정규화를 적용한 보다 robust한 비선형 Muon update rule을 살펴보았다.
\[\begin{equation} \textrm{weight-update}(W, g) = \textrm{L2-Normalize}(W - \textrm{Muon}(g)) \end{equation}\]기본적으로 Muon은 Newton-Schulz iteration을 사용하여 행렬 gradient의 spectral norm을 정규화한다. 간단히 말해, gradient $g$의 SVD를 $g = USV^\top$라고 하면, Muon 연산자는 gradient를 다음과 같이 근사적으로 변환한다.
\[\begin{equation} \textrm{Muon}(g) \simeq UV^\top \end{equation}\]또한 Muon은 수치적 안정성을 향상시킨다. 예를 들어, Muon은 절대적인 스케일을 정규화하기 때문에 learning rate \(\eta_i\)는 이제 chunk 내 토큰의 상대적 중요도만을 반영한다.
3. Window Attention
LaCT layer는 fast weight 업데이트 덕분에 각 chunk 내의 토큰 순서와 공간적 locality를 본질적으로 무시하므로 데이터를 집합의 시퀀스로 처리한다. 그러나 동영상, 이미지 컬렉션, 텍스트와 같은 많은 데이터 유형은 이러한 집합 기반 관점과 완전히 일치하지 않는다. 이러한 유형의 경우 chunk 내 구조와 locality는 전체 데이터 구조를 파악하는 데 매우 중요하다.
따라서 본 논문에서는 chunk 내 데이터 구조를 처리하기 위해 TTT layer와 함께 local window attention을 통합하였다. 또한 window attention은 데이터의 locality를 효율적으로 처리하여 TTT layer가 고정 크기의 fast weight capacity를 global dependency 모델링에 집중할 수 있도록 한다. 요약하자면, LaCT는 로컬 구조를 위한 attention과 글로벌 컨텍스트를 위한 TTT를 결합한 하이브리드 아키텍처이다.
4. Context Parallelism
Context Parallelism (CP)는 컨텍스트 길이 차원을 따라 시퀀스를 분할하고 병렬 컴퓨팅을 위해 여러 장치에 shard를 분산한다. Feed-forward layer와 window attention은 로컬 연산자이므로 기본적으로 CP를 지원한다. TTT layer의 경우, 작은 chunk는 CP를 지원하기 어렵기 때문에 텐서 병렬 처리가 선호된다.
본 논문에서 제안하는 LaCT layer는 chunk 내 토큰을 sharding함으로써 CP를 가능하게 한다. 각 shard에 $s$개의 토큰이 포함되어 있다고 가정할 때, chunk의 fast weight gradient는 gradient의 선형성을 고려하여 모든 shard의 gradient를 합산한 값이다.
\[\begin{equation} g = \nabla_W \sum_{j=1}^{\textrm{shards}} \sum_{i=1}^s \eta_i \mathcal{L}_i = \sum_{j=1}^{\textrm{shards}} \nabla_W \sum_{i=1}^s \eta_i \mathcal{L}_i \end{equation}\]이는 분산형 all-reduce-sum 방식을 통해 구현할 수 있으며, 파라미터가 fast weight이고 입력 데이터가 chunk의 토큰이라는 점을 제외하면 논리적으로 Distributed Data Parallelism (DDP)와 동일하다. LaCT 아키텍처는 다른 병렬 처리 전략과도 호환된다.
LaCT for N-Dimensional Data
1. Novel View Synthesis - Image Set
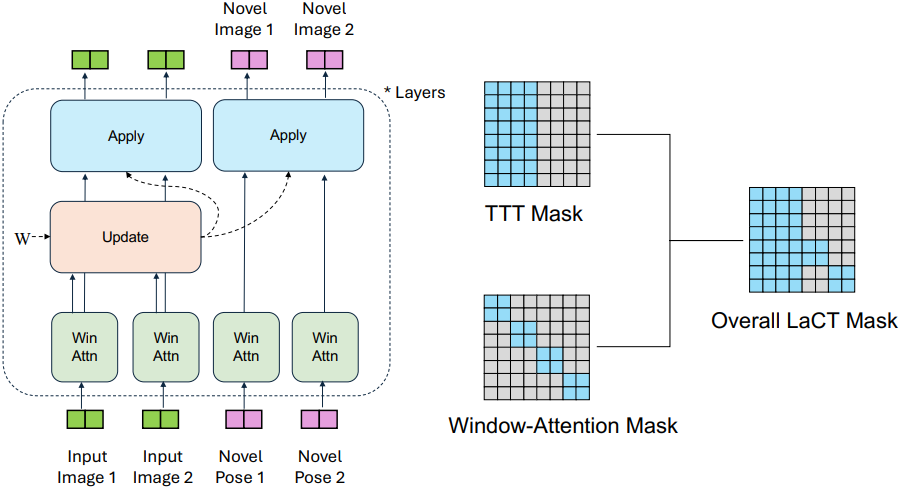
본 논문의 NVS 모델은 기본 LaCT를 따른다. 카메라 포즈를 아는 입력 이미지들과 타겟 novel view의 포즈는 LVSM에 따라 patchify layer와 linear layer를 통해 tokenize된다. Window attention은 한 이미지의 토큰을 정확하게 커버한다. LaCT layer는 strided block-wise causal mask를 한 번 적용하여 모든 입력 이미지 토큰을 사용하여 fast weight를 업데이트하고, 이를 입력 및 타겟 토큰 모두에 적용한다. Update 연산은 prefill 단계와 유사하며, apply 연산은 병렬 디코딩과 유사하다. Novel view 렌더링 시, 각 TTT layer는 정적 가중치 레이어 역할을 하여 전체 모델을 정적 ViT로 만든다.
2. Language Modeling - Text Sequence
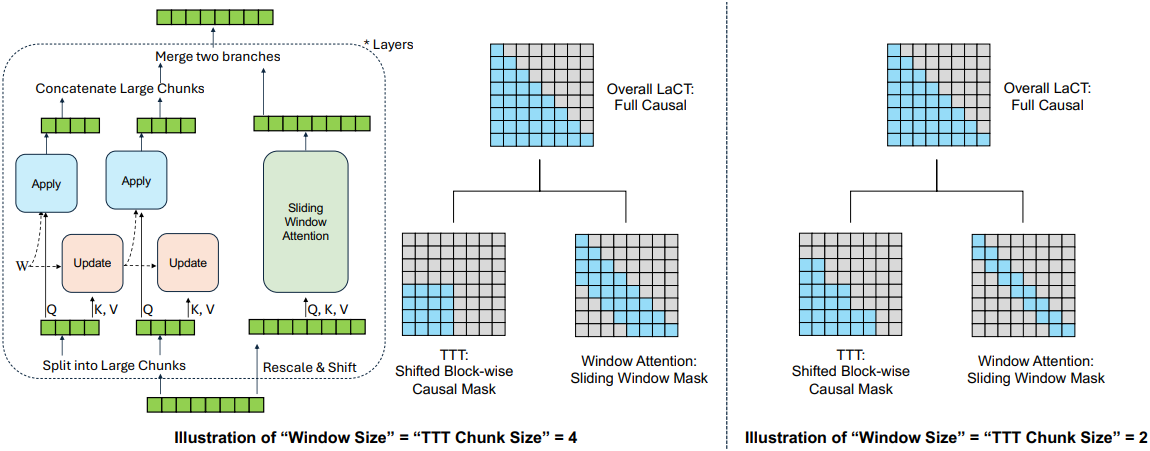
Autoregressive language model은 이전 토큰들이 주어졌을 때 다음 토큰의 확률 분포를 예측한다. 텍스트 시퀀스는 본질적인 chunk 구조를 가지고 있지 않으므로, LaCT에서는 chunk 크기를 hyperparameter (ex. 2048 또는 4096 토큰)로 정의한다. Chunk 내에서 미래 토큰을 보지 않도록 shifted block-wise causal mask를 사용한다. LaCT는 각 chunk 내에서 토큰별 인과 관계를 나타내지 않으므로, chunk 크기와 동일한 window 크기를 갖는 sliding window attention을 사용하여 토큰별 인과 관계를 효율적으로 모델링한다. Sliding window는 GAU와 유사하게 공유 QKV를 사용하여 동일한 TTT layer에 통합된다.
3. Autoregressive Video Diffusion - Image Sequences
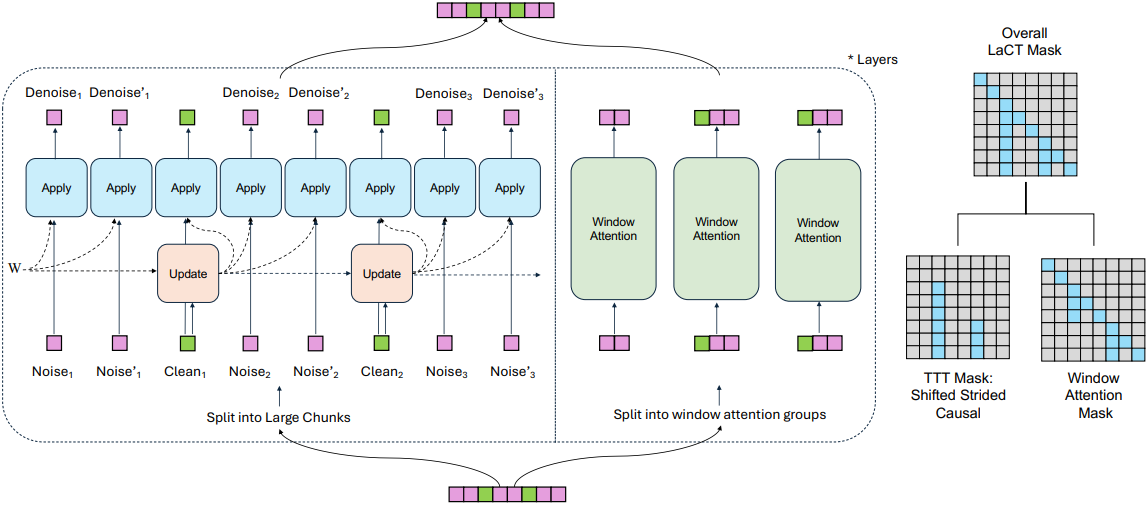
Chunk 단위의 autoregressive video diffusion은 이전에 생성된 깨끗한 프레임을 조건으로 하여 여러 개의 후속 동영상 프레임을 반복적으로 denoising한다. 각 chunk는 수천 개의 비주얼 토큰을 포함할 수 있다. 저자들은 noisy한 frame chunk와 깨끗한 frame chunk를 번갈아 제시하는 teacher-forcing 방식을 사용하였다. 구체적으로, $N$개의 frame chunk로 구성된 동영상은 다음과 같은 구조를 가진다.
각 noisy chunk \(X_i^\textrm{noise}\)는 $i$번째 깨끗한 chunk에 Gaussian noise $\epsilon$을 더하여 생성된다.
\[\begin{equation} X_i^\textrm{noise} = X_i (1 - t_i) + \epsilon t_i \end{equation}\]($t_i \in [0, 1]$는 chunk에 독립적인 noise의 강도)
이러한 데이터 구조를 처리하기 위해, LaCT에 대해 strided block-wise causal mask를 사용한다. 구체적으로, 각 chunk에 순차적으로 apply 연산을 하는 동시에 깨끗한 chunk에 대해서만 update 연산을 한다. 이 간단한 전략을 통해 각 denoising이 이전의 깨끗한 프레임에만 접근하게 된다. Window attention은 연속된 두 chunk를 갖는 겹치지 않는 window $[X_i, X_{i+1}^\textrm{noise}]$를 사용하여 시간적 및 공간적 locality를 구축한다. 각 window 내에서 $X_i$에서 $X_{i+1}^\textrm{noise}$로의 attention은 제외된다. 모든 attention과 TTT 마스킹 패턴을 이동시켜 첫 번째 noisy chunk를 통합한다.
이 방식은 전체 시퀀스 토큰의 약 50%만 사용하여 denoising loss를 계산한다. 토큰 활용도를 개선하기 위해, 학습 시퀀스에서 각 chunk를 두 가지 noise level로 반복할 수 있다.
\[\begin{equation} S = [X_1^\textrm{noise}, X_1^{\textrm{noise}_\ast}, X_1, X_2^\textrm{noise}, X_2^{\textrm{noise}_\ast}, X_2, \ldots, X_N^\textrm{noise}, X_N^{\textrm{noise}_\ast}] \end{equation}\]이러면 토큰 활용도를 50%에서 약 67%로 올릴 수 있다. Window attention은 \([X_i, X_{i+1}^\textrm{noise}, X_{i+1}^{\textrm{noise}_\ast}]\)에 대해 수행된다.
Experiments

1. Novel View Synthesis

2. Language Modeling
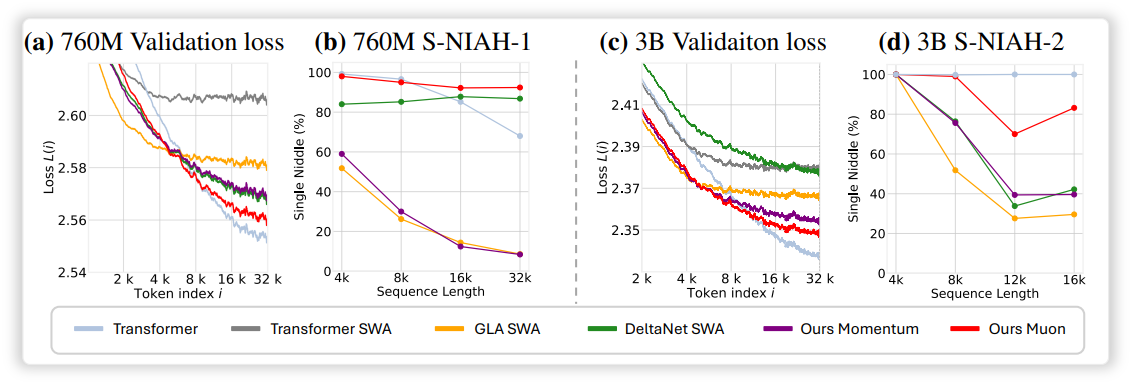
3. Autoregressive Video Diffusion
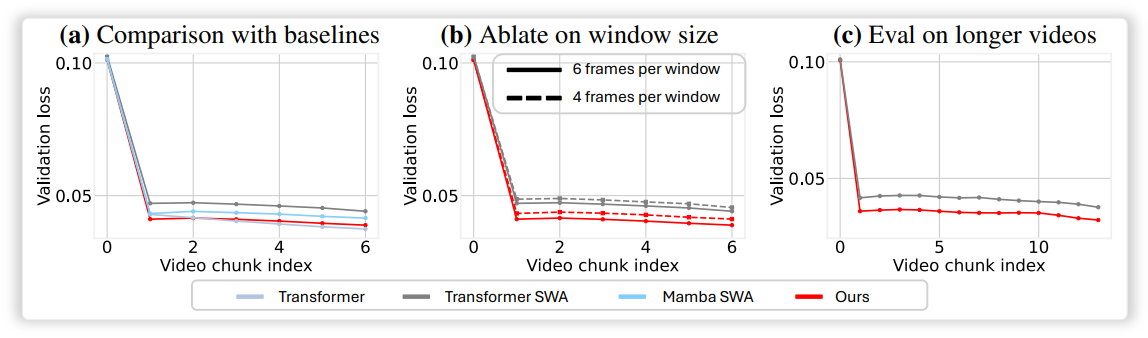
4. Analysis on Design Choices