[논문리뷰] STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
ICLR 2026. [Paper] [Github]
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, Xingang Pan
Nanyang Technological University | Shanghai Artificial Intelligence Laboratory | Peking University | The University of Hong Kong
14 Aug 2025
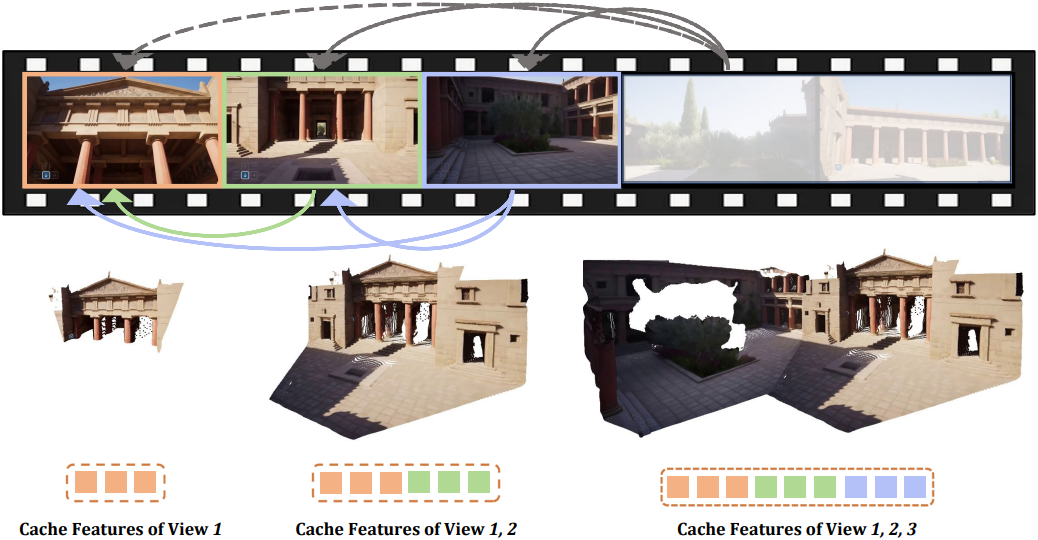
Introduction
본 논문에서는 calibration 되지 않은 스트리밍 이미지를 입력으로 받아 3D 속성들을 출력하는 transformer인 STream3R를 소개한다. 입력은 이미지 컬렉션 또는 동영상일 수 있다. 기존 접근 방식들은 전체 입력 시퀀스에 걸쳐 비용이 많이 드는 양방향 attention을 적용하거나 고정 크기 메모리 버퍼를 사용하는 방식으로 이 문제를 해결했다. STream3R는 이전 프레임의 feature들을 컨텍스트로 캐싱하고, 누적된 관측치에 대해 causal attention을 수행하여 들어오는 프레임을 순차적으로 처리한다. 이러한 설계는 더 빠른 학습과 수렴을 가능하게 할 뿐만 아니라, 최신 LLM의 아키텍처 원칙과도 부합하여 해당 분야의 발전을 활용할 수 있게 한다.
Method
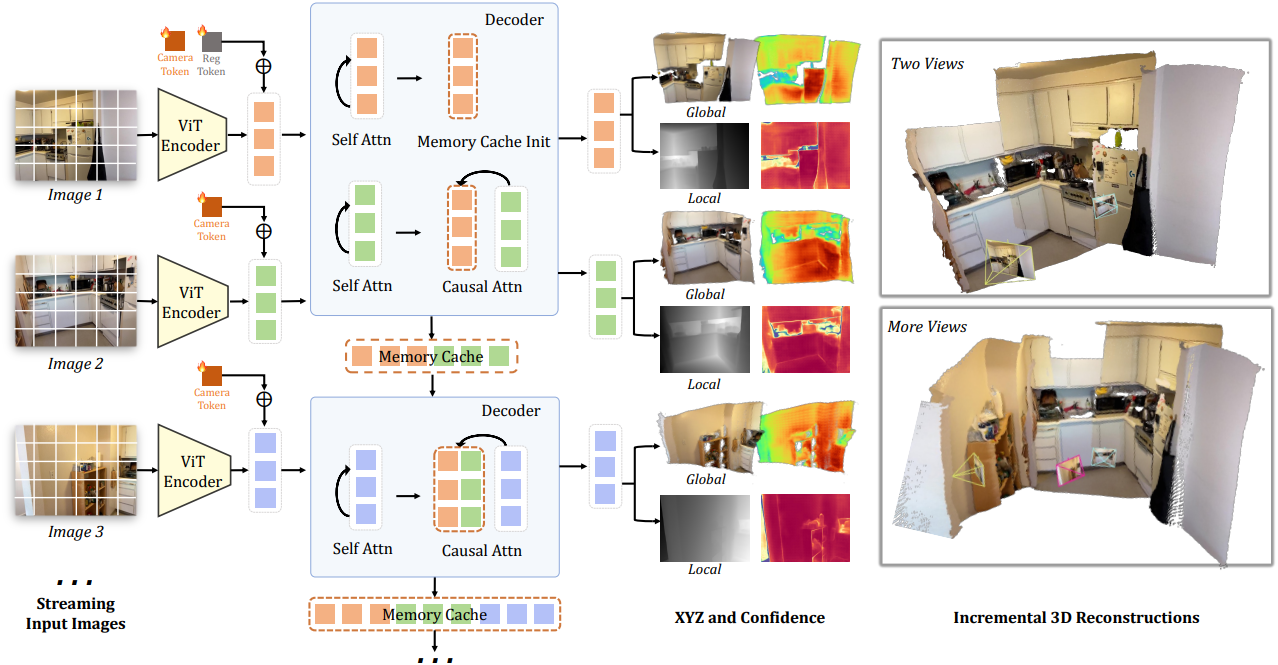
1. Problem Definition and Notation
STream3R는 $N$개의 RGB 이미지 \((\textbf{I})_t^N\)의 스트리밍을 순차적으로 입력받는 regression model이다. 여기서 각 이미지 $\textbf{I} \in \mathbb{R}^{3 \times H \times W}$는 동일한 3D 장면에 속한다. 스트리밍 입력은 각 프레임에 해당하는 3D annotation 세트로 순차적으로 변환된다.
\[\begin{equation} f_\theta ((\textbf{I})_t^N) = (\hat{\textbf{X}}_t^\textrm{local}, \hat{\textbf{X}}_t^\textrm{global}, \hat{\textbf{P}}_t)_t^N \end{equation}\]STream3R는 각 이미지 \(\textbf{I}_t\)를 로컬 좌표계의 pointmap \(\hat{\textbf{X}}_t^\textrm{local} \in \mathbb{R}^{3 \times H \times W}\)와 글로벌 좌표계의 pointmap \(\hat{\textbf{X}}_t^\textrm{global} \in \mathbb{R}^{3 \times H \times W}\)로 매핑하는 causal transformer로 구현된다. Pointmap들은 첫 번째 입력 프레임 \(\textbf{I}_0\)으로 표시되며, intrinsic 및 extrinsic을 모두 포함하는 상대적인 카메라 포즈 \(\hat{\textbf{P}}_t \in \mathbb{R}^9\)도 포함한다.
2. Causal Transformer for 3D Regression
긴 컨텍스트 3D 추론을 위한 Causal Attention
스트리밍 입력이 주어졌을 때, 각 현재 이미지 \(\textbf{I}_t\)에 대해, 먼저 이를 feature \(\textbf{F}_t = \textrm{Encoder}(\textbf{I}_t)\)로 tokenize한다. 주요 차이점은 디코더 부분에 있다. RNN처럼 전체 시퀀스에 걸쳐 양방향 attention을 수행하거나 학습 가능한 state와 상호 작용하는 대신, LLM과 비슷하게 이전 관측값을 활용하여 효율적인 causal attention을 수행한다.
구체적으로, 각 디코더 block에서 프레임별 self-attention을 수행한 후, 현재 feature \(G_t^{i-1}\)는 동일한 layer에 해당하는 이전에 관측된 프레임의 feature에 대해 cross-attention을 수행한다.
\[\begin{equation} G_t^i = \textrm{DecoderBlock}^i (G_t^{i-1}, G_0^{i-1} \oplus G_1^{i-1} \oplus \cdots \oplus G_{t-1}^{i-1}) \end{equation}\]이러한 상호 작용을 통해 긴 컨텍스트 의존성을 처리하기 위한 효율적인 정보 전달이 보장된다. 이 연산은 구현이 간편하고 inference 시에 KV 캐시를 사용하여 효율적인 계산을 위해 잘 최적화되어 있다.
단순화된 디코더 디자인
이를 위해 몇 가지 네트워크 아키텍처 수정이 필요하다. DUSt3R에서 디코더는 대칭 설계를 따르는데, 즉 두 개의 입력 뷰를 처리하기 위해 두 개의 별도 디코더가 사용된다. 임의의 입력 수로 확장하기 위해 대칭 설계를 제거하고 모든 입력 프레임을 처리하는 하나의 디코더만 유지한다.
구체적으로, 디코더의 각 block은 프레임별 attention을 위한 self-attention block과 이전 모든 관측치의 feature에 인과적으로 attention하는 cross-attention block을 포함한다. 과거 컨텍스트가 부족하기 때문에 처음 두 프레임은 DUSt3R와 같이 처리한다. 이후 들어오는 모든 프레임은 인과적인 연산을 수행한다. Canonical world space를 나타내기 위해, 첫 번째 프레임에 대한 학습 가능한 레지스터 토큰 $[\textrm{reg}]$을 추가한다.
\[\begin{equation} \textbf{F}_1 = \textbf{F}_1 + [\textrm{reg}] \end{equation}\]이러한 방식으로 모델은 $N$개의 별도 디코더를 도입하지 않고도 글로벌 좌표를 출력하도록 학습한다. Fast3R와 달리, 단순화를 위해 다른 프레임에 대해서는 위치 임베딩을 적용하지 않는다.
Prediction Head
디코딩 연산 후, 각 프레임에 해당하는 3D 속성을 예측할 수 있다. 두 세트의 pointmap \(\hat{\textbf{X}}_t^\textrm{local}\), \(\hat{\textbf{X}}_t^\textrm{global}\)와 이에 대응하는 신뢰도 맵 \(\hat{\textbf{C}}_t^\textrm{local}\), \(\hat{\textbf{C}}_t^\textrm{global}\)를 예측한다. 구체적으로, 로컬 pointmap \(\hat{\textbf{X}}_t^\textrm{local}\)는 현재 카메라의 좌표계에서 정의되고, 글로벌 pointmap \(\hat{\textbf{X}}_t^\textrm{global}\)는 첫 번째 이미지 \(\textbf{I}_1\)의 좌표계에서 정의된다. Pointmap 예측을 위해 두 개의 DPT head를 사용한다.
\[\begin{aligned} \hat{\textbf{X}}_t^\textrm{local}, \hat{\textbf{C}}_t^\textrm{local} &= \textrm{Head}_\textrm{local} (G_t^0, \ldots, G_t^B) \\ \hat{\textbf{X}}_t^\textrm{global}, \hat{\textbf{C}}_t^\textrm{global} &= \textrm{Head}_\textrm{global} (G_t^0, \ldots, G_t^B) \\ \hat{\textbf{P}}_t &= \textrm{Head}_\textrm{pose} (G_t^0, \ldots, G_t^B) \end{aligned}\]이러한 중복 예측은 학습을 단순화하고 부분적인 annotation이 있는 3D 데이터셋에 대한 학습을 용이하게 한다.
3. Training Objective
STream3R는 DUSt3R에서 도입된 pointmap loss의 일반화된 형태를 사용하여 학습된다. 동영상 또는 이미지 컬렉션에서 가져온 $N$개의 무작위로 샘플링된 이미지 시퀀스가 주어지면, Pointmap 예측 \(\hat{\mathcal{X}} = \{\hat{\mathcal{X}}^\textrm{local}, \hat{\mathcal{X}}^\textrm{global}\}\)을 생성하도록 모델을 학습시킨다.
\[\begin{equation} \hat{\mathcal{X}}^\textrm{local} = \{\hat{\textbf{X}}_t^\textrm{local}\}_{t=1}^N, \quad \hat{\mathcal{X}}^\textrm{global} = \{\hat{\textbf{X}}_t^\textrm{global}\}_{t=1}^N \end{equation}\]DUSt3R를 따라, pointmap에 confidence-aware regression loss를 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{conf} = \sum_{(\hat{\textbf{x}}, \hat{c}) \in (\hat{\mathcal{X}}, \hat{\mathcal{C}})} \left( \hat{c} \cdot \lVert \frac{\hat{\textbf{x}}}{\hat{s}} - \frac{\textbf{x}}{s} \rVert_2 - \alpha \log \hat{c} \right) \end{equation}\]여기서 $\hat{s}$와 $s$는 scale-invariant supervision을 위한 $\hat{\mathcal{X}}$와 $\mathcal{X}$의 scale normalization factor이다. 또한 MASt3R에서와 같이 metric-scale 데이터셋의 경우 $\hat{s} = s$로 설정하여 metric-scale pointmap 예측을 가능하게 한다. 카메라 예측 loss의 경우, 포즈 \(\hat{\textbf{P}}_t\)를 quaternion \(\hat{\textbf{q}}_t\), translation \(\hat{\boldsymbol{\tau}}_t\), focal \(\hat{\textbf{f}}_t\)로 parameterize하고 예측값과 GT 사이의 L2 norm을 최소화한다.
\[\begin{equation} \mathcal{L}_\textrm{pose} = \sum_{t=1}^N \left( \lVert \hat{\textbf{q}}_t - \textbf{q}_t \rVert_2 + \lVert \frac{\hat{\boldsymbol{\tau}}_t}{\hat{s}} - \frac{\boldsymbol{\tau}_t}{s} \rVert_2 + \lVert \hat{\textbf{f}}_t - \textbf{f}_t \rVert_2 \right) \end{equation}\]Experiments
- 데이터셋: Co3Dv2, ScanNet++, ScanNet, HyperSim, Dynamic Replica, DL3DV, BlendedMVS, Aria Synthetic Environments, TartanAir, MapFree, MegaDepth, ARKitScenes
- 구현 디테일
- STream3R$\vphantom{1}^\alpha$
- DUSt3R의 사전 학습된 가중치를 fine-tuning
- 24-layer CroCo ViT 인코더를 계승
- 12-layer 디코더 네트워크에서 첫 번째 디코더만 남겨 reconstruction
- 디코딩된 토큰을 pointmap에 각각 매핑하는 데 DPT-L head 사용
- STream3R$\vphantom{1}^\beta$
- VGGT로 초기화
- VGGT의 global attention에 있는 self-attention을 causal attention으로 대체
- 각 transformer layer에 QK-Norm 삽입
- BFloat16 mixed precision 학습을 위한 FlashAttention 사용
- STream3R$\vphantom{1}^\alpha$
- 학습 디테일
- optimizer: AdamW (learning rate = $10^{-4}$)
- batch size: 64
- iteration: 40만
- 랜덤한 장면에서 4~10 프레임을 랜덤 샘플링하여 batch로 구성
- 해상도: 224$\times$224 ~ 512$\times$384
- NVIDIA A100 GPU 8개로 7일 소요
1. Monocular and Video Depth Estimation
다음은 단일 프레임에 대한 깊이 추정 결과이다.
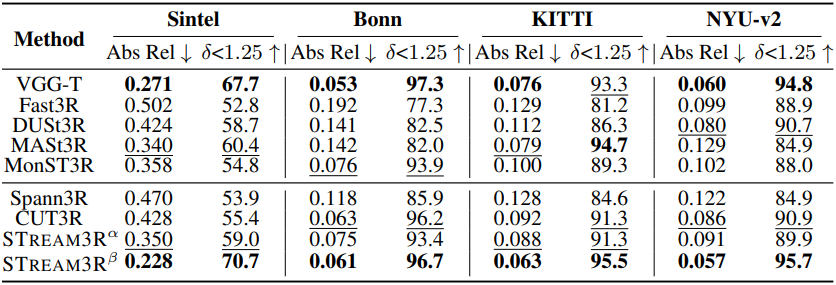
다음은 동영상에 대한 깊이 추정 결과이다.
2. 3D Reconstruction
다음은 7-Scenes에서의 3D reconstruction 결과이다.
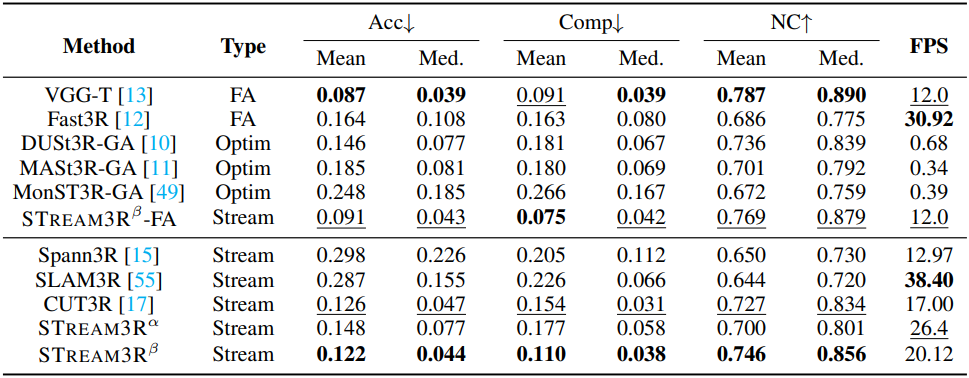
3. Camera Pose Estimation
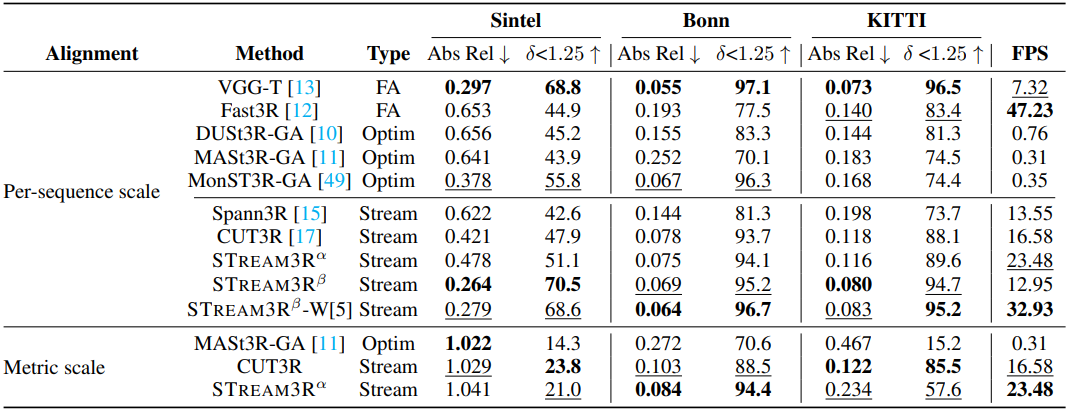
다음은 카메라 포즈 추정에 대한 비교 결과이다.
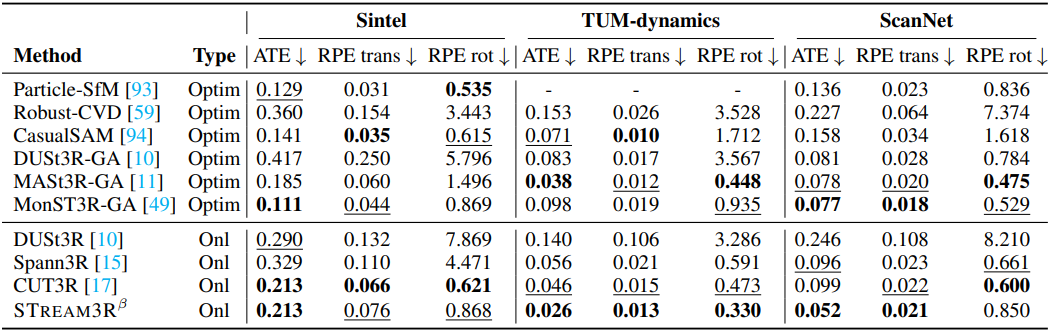
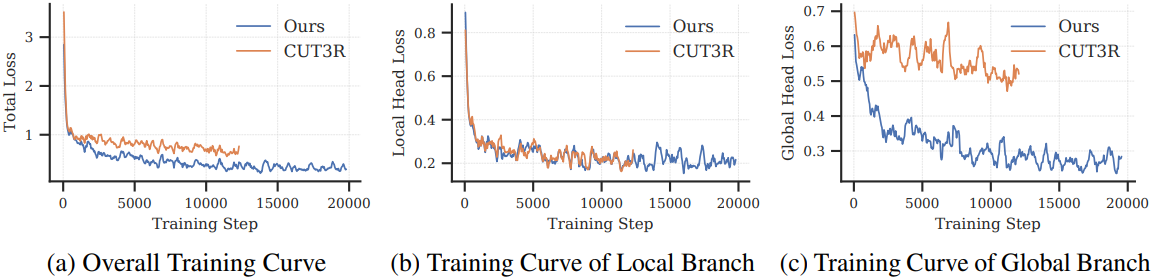
4. Ablation on the Effectiveness of the Proposed Architecture
다음은 RNN 기반의 CUT3R와 비교한 결과이다.
다음은 동영상 깊이 추정에 대해 CUT3R와 비교한 결과이다.

다음은 3D reconstruction에 대해 CUT3R와 비교한 결과이다. (7-Scenes)
