[논문리뷰] TSLM: Tree-Structured Language Modeling for Divergent Thinking
ICLR 2026. [Paper]
Doyoung Kim, Jaehyeok Doo, Minjoon Seo
NYU | KAIST AI
30 Jan 2026
Introduction
최근의 추론 모델인 o1과 DeepSeek-R1은 확장된 추론 과정을 통해 인상적인 성능을 보여주었지만, 근본적으로는 여전히 순차적으로 작동한다. 이러한 모델들은 내부적으로 여러 옵션을 고려할 수 있지만, 생성 과정 내에서 병렬 branch를 명시적으로 분리할 수는 없다. Tree-of-Thoughts와 같은 외부 탐색 방법은 사후 탐색을 통해 이 문제를 해결하지만, 여러 번의 독립적인 모델 호출과 외부 오케스트레이션이 필요하다.
핵심 과제는 모델이 다양한 탐색 branch를 일관성 있게 구성할 수 없다는 점이다. 순차적 모델은 모든 추론을 하나의 경로로 축소한다. 외부 탐색 방법은 여러 궤적을 독립적으로 샘플링하지만, 이는 탐색 샘플이 조정 없이 추출되어 일부 영역에서는 중복이 발생하고 다른 영역에서는 중요한 branch를 놓치는 등 파편화된 분포를 초래한다. 모델에는 전체 탐색 공간을 체계적으로 재구성하는 메커니즘이 없다.
TSLM은 일관된 트리 생성 방식을 통해 이 문제를 해결한다. 여러 개의 독립적인 궤적을 샘플링하는 대신, 특수 토큰 [SEP], [FAIL], [GOAL]을 사용하여 실행 가능한 경로, 막다른 길, 목표 지점을 표시하고, 하나의 forward pass에서 완전한 branch 구조를 생성한다. 학습 과정에서 모델은 각 node에 대해 다양한 branch를 체계적으로 구성하는 방법을 학습한다. Inference 시에 모델은 이러한 일관된 트리 구조를 생성한 다음, 각 branch를 선택적으로 독립적인 컨텍스트에 연결하여 확장함으로써, 병렬 샘플링으로 전체 탐색 토폴로지를 커버할 수 있기를 기대하는 대신 완전한 탐색 토폴로지를 유지한다.
이 접근 방식은 성공적인 경로와 실패한 시도를 모두 포함하여 전체 추론 과정을 학습할 수 있도록 함으로써 모델이 더욱 robust한 문제 해결 능력을 갖추도록 한다. 실험 결과는 이러한 내재화된 탐색 전략이 순차적 모델보다 우수한 성능을 보일 뿐만 아니라, 최종 답만이 아닌 전체 탐색 패턴을 학습함으로써 자연스럽게 발생하는 파라미터 효율성과 새로운 기능들을 보여준다는 것을 입증하였다.
Method
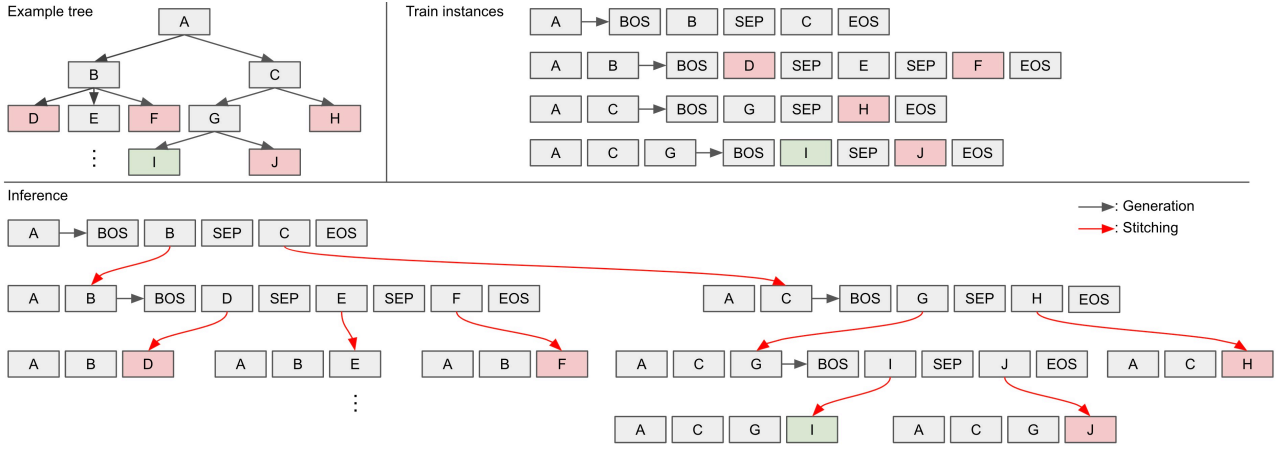
1. Modeling Multiple Next Actions
$s$를 현재 state 또는 부분적인 solution이라고 하자. 순차적 언어 모델에서는 $s$로부터 하나의 다음 action $a$를 예측하고 $s^\prime = T(s, a)$로 transition한다. 이와 대조적으로, TSLM에서는 가능한 여러 후속 action을 표현한다.
\[\begin{equation} \pi_\theta (s) = \{ T(s, a_1), \cdots, T(s, a_k) \} \end{equation}\]여기서 각 $a_i$는 서로 다른 branch를 나타내고 $k$는 branching factor이다. TSLM은 한 번의 forward pass에서 $s$를 이러한 $k$개의 후속 branch로 확장하는 방법을 학습하며, branch들을 독립적으로 생성하는 대신 branch들 간의 관계를 유지한다. 이러한 branch 표현 방식은 $k$개의 독립적인 궤적을 샘플링하는 것과는 근본적으로 다르다. 각 $a_i$는 동일한 node에서 이전 action들 \(a_1, \cdots, a_{i-1}\)를 조건으로 생성되므로, 중복 샘플링하는 대신 action space를 체계적으로 커버할 수 있다.
2. Encoding and Decoding with Tree Structure
저자들은 표준 transformer 아키텍처가 트리 구조 추론을 학습할 수 있도록, 완전한 탐색 트리를 선형 시퀀스로 인코딩하는 serialization 방식을 개발했다. 이 접근 방식을 통해 branch 구조를 유지하면서 트리 데이터로 언어 모델을 학습할 수 있다.
토큰 기반 Tree Serialization
본 논문에서는 TSLM이 트리 구조를 인코딩하기 위해 특수 토큰을 도입하였다.
- [SEP]: 추가 확장이 가능한 실행 가능한 action을 나타냄
- [FAIL]: 실행 불가능한 action을 나타냄
- [GOAL]: 원하는 goal state를 표시
- [BOS], [EOS]: 각 node에 대한 자식 확장의 시퀀스 경계를 표시
이러한 serialization은 성공적인 경로와 실패한 탐색 모두를 포착하여 모델이 최종 답변뿐만 아니라 전체 탐색 과정을 학습하도록 한다.
학습 절차
학습 시에는 serialize된 전체 시퀀스에 표준 언어 모델링 loss를 적용한다.
\[\begin{equation} \mathcal{L} = -\sum_{t=1}^T \log p (y_t \vert y_{<t}, x) \end{equation}\]여기서 $y_t$는 추론 내용과 구조적 토큰을 모두 포함한다. 이 cross entropy loss는 표준적이지 않은 학습 신호를 사용한다. 각 토큰이 prefix에만 의존하는 순차적 모델링과 달리, TSLM 토큰은 트리 구조에 의존한다. 예를 들어, action $a_i$는 $T(s, a_i)$가 확장 가능한지, 그리고 $a_1, \cdots, a_{i-1}$과 다른지에 따라 컨디셔닝된다. 이러한 구조적 컨디셔닝은 모델에게 다음과 같은 것을 학습시킨다.
- 각 의사결정 지점에서 여러 가지 action을 생성
- 적절한 마커(ex. [SEP], [FAIL], [GOAL])를 지정
- 탐색 과정을 체계적으로 구성
Inference 절차
Inference 시에 TSLM은 트리 구조를 다음과 같이 재구성한다.
- 여러 후보 action을 포함하는 다음 추론 step을 생성
- 구조적 토큰들을 파싱하여 실행 가능한 branch를 식별
- 병렬적 확장을 위해 서로 다른 branch를 독립적인 시퀀스로 분기
- Solution을 찾을 때까지 또는 모든 옵션을 소진할 때까지 각 실행 가능한 state를 재귀적으로 확장
3. Formal Training Objective
Node $\mathcal{N}$을 갖는 탐색 트리 $\mathcal{T}$에 대해 $\pi (s_i)$는 root에서 node $s_i$까지의 경로를 나타낸다. 각 node $s_i$는 토큰 시퀀스 $y_{s_i} = [a_i, m_i]$를 생성하며, 여기서 $a_i$는 action 설명이고 \(m_i \in \{\)[SEP], [FAIL], [GOAL]\(\}\)는 마커이다.
Node $s_i$의 컨텍스트는 다음과 같다.
\[\begin{equation} \textrm{ctx} (s_i) = \bigcup_{s_j \in \pi (s_i)} y_{s_j} \cup \bigcup_{s_k \in \textrm{siblings} (s_i), k < i} y_{s_k} \end{equation}\](\(\textrm{siblings} (s_i)\)는 동일한 부모를 공유하는 형제 node이며, $k < i$는 $s_i$ 이전에 생성된 형제들)
학습 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = - \frac{1}{\vert \mathcal{N} \vert} \sum_{s_i \in \mathcal{N}} \sum_{t=1}^{\vert y_{s_i} \vert} \log p(y_{s_i, t} \; \vert \; y_{s_i, <t}, \textrm{ctx}(s_i)) \end{equation}\]즉, 각 node는 조상 경로 및 이전에 생성된 형제 노드로 컨디셔닝되지만 관련 없는 하위 트리에는 컨디셔닝되지 않는다. 이러한 선택적 컨디셔닝이 컨텍스트 분리를 가능하게 한다.
실제로는 깊이 우선 탐색을 사용하여 트리를 serialize하고, transformer가 처리할 수 있는 선형 시퀀스로 변환한다. 중요한 것은 입력은 선형이지만 조건부 의존성은 트리 토폴로지에 따라 결정된다는 점이다. Node $s_i$는 serialize된 시퀀스에서 자신보다 앞에 있는 모든 토큰이 아니라 $\textrm{ctx}(s_i)$에만 의존한다. 이러한 구조화된 컨디셔닝은 TSLM을 모든 탐색 경로를 단순히 순차적으로 연결하는 방식과 구별하는 특징이다.
4. Search Tree Supervision
Structured tasks
미리 정의된 탐색 트리를 갖는 구조화된 task의 경우, TSLM을 직접 학습시켜 트리 구조를 학습하고 재현할 수 있다. State-action 쌍을 새로운 state로 매핑하는 transition function을 $T(s, a)$라고 하며, state $s$에서 유효한 action을 정의하는 유한한 action space를 $A(s)$라고 하자. 이러한 구성 요소들이 명시적으로 정의되어 있으므로, 완전한 탐색 트리를 생성하고 TSLM을 사용하여 탐색 트리의 각 state에서 분기 구조 $(T(s, a) \; \vert \; a \in A(s))$를 예측할 수 있다. 미리 정의된 트리 확장을 직접 모방함으로써, TSLM은 모델이 구조화된 탐색 패턴을 충실하게 재현하도록 유도한다.
Open-ended reasoning tasks
구조화된 task에는 TSLM이 직접 학습할 수 있는 미리 정의된 탐색 트리가 있지만, 대부분의 실제 task에는 명시적인 트리 구조가 부족하여 정답 또는 정답 경로만 제공된다. 본 논문에서는 모델이 생성한 탐색과 알려진 solution을 결합하여 합성 학습 트리를 구축하는 간단한 부트스트래핑 방법을 채택하였다.
각 학습 인스턴스에 대해 supervision 언어 모델에서 Tree-of-Thoughts 샘플링을 사용하여 탐색 트리를 생성한다. 이 과정은 다음과 같다.
- Beam search를 이용하여 각 state에서 후보 action 집합을 샘플링한다.
- 이러한 action들을 전파하여 트리 구조를 구축한다.
- 알려진 정답 경로들을 우선순위가 높은 branch들로 통합한다.
- Reward function $R(s, a)$를 사용하여 나머지 branch들의 순서를 정한다.
- 트리 구조를 유지하면서 중복 경로를 제거한다.
Algorithm 1은 이 절차를 자세히 설명한다. 다양한 대안을 탐색하는 동안 각 학습 트리에 적어도 하나의 유효한 solution이 포함되도록 보장한다. Reward 기반 순서 지정은 유망한 action에 우선순위를 부여하는 데 도움이 되며, 중복 제거는 불필요한 검색을 방지한다. 저자들은 RAP reward function을 채택했다.

Experiments
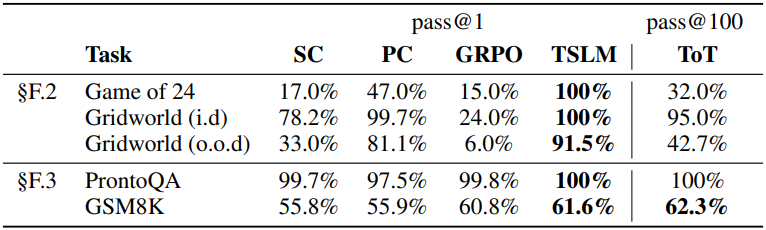
다음은 다양한 task에 대한 성공률을 비교한 결과이다.
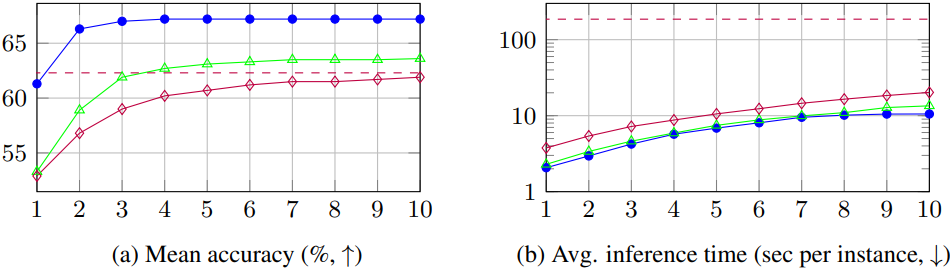
다음은 (a) 평균 정확도와 (b) 평균 inference 시간을 비교한 결과이다. (SC가 빨간색, PC가 초록색, TSLM이 파란색)
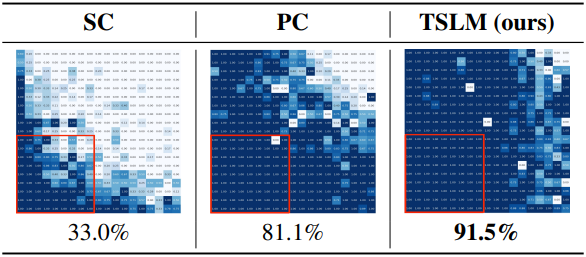
다음은 다양한 크기의 Gridworlds에서 모델의 extrapolation 능력을 비교한 결과이다.