[논문리뷰] Mean Flows for One-step Generative Modeling
NeurIPS 2025 (Oral). [Paper]
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, Kaiming He
CMU | MIT
19 May 2025
Introduction
본 연구에서는 MeanFlow라는 원칙적이고 효과적인 one-step 생성 프레임워크를 제안하였다. 핵심 아이디어는 Flow Matching에서 일반적으로 모델링되는 순간 속도와는 대조적으로 평균 속도를 나타내는 새로운 GT field를 도입하는 것이다. 평균 속도는 변위를 시간 간격으로 나눈 값으로 정의되며, 변위는 순간 속도의 시간 적분으로 주어진다. 이러한 정의에서 출발하여 평균 속도와 순간 속도 사이의 명확하고 내재적인 관계를 도출할 수 있으며, 이는 네트워크 학습을 가이드하는 원칙적인 기반이 된다.
이러한 기본 개념을 바탕으로, 평균 velocity field를 직접 모델링하는 신경망을 학습시킨다. 평균 속도와 순간 속도 사이의 내재적 관계를 만족하도록 신경망을 유도하는 loss function을 도입하였다. 별도의 일관성 휴리스틱은 필요하지 않다. GT field의 존재는 최적해가 원칙적으로 특정 신경망에 독립적임을 보장하며, 이는 실제로 더욱 robust하고 안정적인 학습으로 이어질 수 있다. 또한, 본 프레임워크는 classifier-free guidance (CFG)를 GT field에 자연스럽게 통합할 수 있으며, guidance를 사용할 때 샘플링 시간에 추가 비용이 발생하지 않는다.
MeanFlow 모델은 ImageNet 256$\times$256 데이터셋에서, 1-NFE 생성을 통해 3.43의 FID를 달성했다. 이는 동급 SOTA 모델 대비 50%~70%의 상대적 성능 차이를 보이는 결과이다. 또한, 본 방법은 사전 학습, distillation, curriculum learning 없이 완전히 처음부터 학습된 생성 모델이다.
Method
1. Mean Flows
본 접근 방식의 핵심 아이디어는 평균 속도를 나타내는 새로운 field를 도입하는 것이며, Flow Matching에서 모델링된 속도는 순간 속도를 나타낸다.

평균 속도
평균 속도 $u$는 두 timestep $t$와 $r$ 사이의 변위를 시간 간격으로 나눈 값으로 정의한다.
\[\begin{equation} u(z_t, r, t) = \frac{1}{t-r} \int_r^t v(z_\tau, \tau) d \tau \end{equation}\]$u(z_t, r, t)$는 $(r, t)$에 공동으로 의존하는 field이다. 일반적으로 평균 속도 $u$는 순간 속도 $v$의 함수로 표현된다. 이는 어떤 신경망에도 의존하지 않고 $v$에 의해 유도되는 field이다. 개념적으로, 순간 속도 $v$가 Flow Matching에서 GT field 역할을 하는 것처럼, 평균 속도 $u$는 학습을 위한 GT field를 제공한다.
$r \rightarrow t$일 때, \(\textrm{lim}_{r \rightarrow t} u = v\)가 성립한다. 또한, 일종의 “일관성”이 자연스럽게 만족된다. 즉, 임의의 중간 시간 $s$에 대해, $[r, t]$에 대해 큰 step을 취하는 것은 $[r, s]$와 $[s, t]$에 대해 연속적으로 두 step을 취하는 것과 같다.
\[\begin{equation} (t − r)u(z_t, r, t) = (s − r)u(z_s, r, s) + (t − s)u(z_t, s, t) \end{equation}\]따라서 실제 $u$를 정확하게 근사하는 네트워크는 명시적인 제약 조건 없이도 본질적으로 일관성 관계를 만족할 것으로 예상된다.
MeanFlow 모델의 궁극적인 목표는 신경망 \(u_\theta (z_t, r, t)\)를 사용하여 평균 속도를 근사하는 것이다. 이 방법은 평균 속도를 정확하게 근사한다고 가정할 때, \(u_\theta(\epsilon, 0, 1)\)을 한 번만 평가하여 전체 경로를 근사할 수 있다는 장점을 가지고 있다. 다시 말해, 이 접근 방식은 순간 속도를 모델링할 때처럼 inference 시점에 시간 적분을 명시적으로 근사할 필요가 없으므로 one-step 또는 few-step 생성에 훨씬 더 적합하다.
그러나 평균 속도를 네트워크 학습의 GT로 직접 사용하는 것은 학습 중에 적분을 평가해야 하므로 다루기 어렵다. 저자들의 핵심적인 통찰은 순간 속도만 사용할 수 있는 경우에도 학습에 적합한 loss를 구성하기 위해 평균 속도의 정의 방정식을 조작할 수 있다는 것이다.
MeanFlow Identity
학습에 적합한 형태로 만들기 위해 $u$의 정의를 다음과 같이 다시 쓴다.
\[\begin{equation} (t - r) u (z_t, r, t) = \int_r^t v (z_\tau, \tau) d \tau \end{equation}\]이제 $r$을 $t$와 무관한 변수로 간주하고 양변을 $t$에 대해 미분한다.
\[\begin{equation} \frac{d}{dt} (t - r) u (z_t, r, t) = \frac{d}{dt} \int_r^t v (z_\tau, \tau) d \tau \\ u(z_t, r, t) + (t - r) \frac{d}{dt} u (z_t, r, t) = v(z_t, t) \end{equation}\]항들을 재배열하면 다음과 같은 항등식을 얻는다.
\[\begin{equation} \underbrace{u(z_t, r, t)}_{\textrm{average vel.}} = \underbrace{v(z_t, t)}_{\textrm{instant. vel.}} - (t - r) \underbrace{\frac{d}{dt} u (z_t, r, t)}_{\textrm{time derivative}} \end{equation}\]이 방정식을 $v$와 $u$ 사이의 관계를 나타내는 MeanFlow Identity라고 부른다.
위 식의 우변은 $u(z_t, r, t)$에 대한 target 형태를 제공하며, 이를 활용하여 신경망을 학습시키기 위한 loss function을 구성한다. 적절한 loss가 되기 위해서는 time derivative 항을 추가로 분해해야 한다.
Time derivative 계산
$\frac{d}{dt} u$ 항에서 $\frac{d}{dt}$는 전미분을 나타내며, 이는 편미분으로 전개될 수 있다.
\[\begin{equation} \frac{d}{dt} u (z_t, r, t) = \frac{d z_t}{dt} \partial_z u + \frac{dr}{dt} \partial_r u + \frac{dt}{dt} \partial_t u \end{equation}\]\(\frac{dz_t}{dt} = v(z_t, t)\)이고 \(\frac{dr}{dt} = 0\), \(\frac{dt}{dt} = 1\)이므로, $u$와 $v$ 사이에는 다음과 같은 또 다른 관계가 있다.
\[\begin{equation} \frac{d}{dt} u (z_t, r, t) = v (z_t, t) \partial_z u + \partial_t u \end{equation}\]이 방정식은 전미분이 함수 $u$의 Jacobian \([\partial_z u, \partial_r u, \partial_t u]\)와 접선 벡터 $[v, 0, 1]$의 Jacobian-vector product (JVP)으로 주어진다는 것을 보여준다. PyTorch의 torch.func.jvp 또는 JAX의 jax.jvp와 같은 jvp 인터페이스를 통해 이를 효율적으로 계산할 수 있다.
평균 속도로 학습
이제 $u$를 학습하기 위한 모델을 소개한다. 네트워크 \(u_\theta\)를 parameterize하고 MeanFlow Identity를 만족하도록 유도한다. 구체적으로, 이 loss를 최소화한다.
\[\begin{equation} \mathcal{L}(\theta) = \mathbb{E} \| u_\theta (z_t, r, t) - \textrm{sg} (u_\textrm{tgt}) \|_2^2 \\ \textrm{where} \quad u_\textrm{tgt} = v(z_t, t) - (t - r) (v(z_t, t) \partial_z u_\theta + \partial_t u_\theta) \end{equation}\]Target \(u_\textrm{tgt}\)는 $\partial u$를 포함해야 하지만, 여기서는 parameterize된 값 \(\partial u_\theta\)로 대체된다. 일반적인 관행에 따라 target \(u_\textrm{tgt}\)에 stop gradient 연산이 적용된다. 이 경우, JVP를 통한 이중 backpropagation이 필요 없어진다. Loss가 0이 되면 MeanFlow Identity를 만족하고 따라서 원래 $u$의 정의를 만족한다.
$v(z_t, t)$는 Flow Matching에서의 marginal velocity이다. 이를 conditional velocity로 대체한다. 이렇게 하면 target은 다음과 같다.
\[\begin{equation} u_\textrm{tgt} = v_t - (t - r) (v_t \partial_z u_\theta + \partial_t u_\theta) \\ \textrm{where} \quad v_t = a_t^\prime x + b_t^\prime \epsilon = \epsilon - x \; (\textrm{default}) \end{equation}\]Flow Matching과 유사하게 동작하며, 핵심적인 차이점은 평균 속도를 고려했기 때문에 매칭 대상이 \(- (t - r) (v_t \partial_z u_\theta + \partial_t u_\theta)\)만큼 수정된다는 것이다. 특히, $t = r$ 조건으로 제한하면 두 번째 항이 사라지고, 이 방법은 표준 Flow Matching과 정확히 일치하게 된다.

jvp 연산은 매우 효율적이다. 본질적으로 jvp를 통해 $\frac{d}{dt} u$를 계산하는 데에는 일반적인 backpropagation과 유사하게 한 번의 backward pass만 필요하다. $\frac{d}{dt} u$는 target \(u_\textrm{tgt}\)의 일부이므로 stopgrad의 영향을 받기 때문에, 신경망 최적화를 위한 backpropagation은 $\frac{d}{dt} u$를 상수로 취급하여 고차 gradient 계산을 수행하지 않는다. 결과적으로 jvp는 한 번의 추가 backward pass만 발생시키며, 그 비용은 backpropagation과 유사하다. JAX 구현에서 오버헤드는 전체 학습 시간의 20% 미만이다.
샘플링
MeanFlow 모델을 사용한 샘플링은 시간 적분을 평균 속도로 대체하는 것만으로 간단하게 수행된다.
\[\begin{equation} z_r = z_t - (t - r) u(z_t, r, t) \end{equation}\]1-step 샘플링의 경우, \(z_0 = z_1 − u(z_1, 0, 1)\)로 간단히 표현되며, \(z_1 = \epsilon \sim p_\textrm{prior}(\epsilon)\)이다. 본 논문에서는 1-step 샘플링에 주로 초점을 맞추지만, 위 식을 이용하면 few-step 샘플링 또한 간단하게 구현할 수 있다.

2. Mean Flows with Guidance
MeanFlow는 classifier-free guidance (CFG)를 자연스럽게 지원한다. 샘플링 시점에 CFG를 단순히 적용하여 NFE를 두 배로 늘리는 대신, CFG를 GT field의 속성으로 취급한다. 이러한 접근 방식을 통해 샘플링 과정에서 1-NFE 특성을 유지하면서 CFG의 이점을 누릴 수 있다.
GT field
Class-conditional field와 class-unconditional field의 선형 조합인 새로운 GT field \(v^\textrm{cfg}\)를 구성한다.
\[\begin{equation} v^\textrm{cfg} (z_t, t \; \vert \; \textbf{c}) = \omega v (z_t, t \; \vert \; \textbf{c}) + (1 - \omega) v (z_t, t) \\ v (z_t, t \; \vert \; \textbf{c}) = \mathbb{E}_{p_t (v_t \vert z_t, \textbf{c})} [v_t], \quad v (z_t, t) = \mathbb{E}_\textbf{c} [v (z_t, t \; \vert \; \textbf{c})] \end{equation}\]MeanFlow의 정신에 따라, \(v^\textrm{cfg}\)에 대응하는 평균 속도 \(u^\textrm{cfg}\)를 도입한다. MeanFlow Identity에 따라, \(u^\textrm{cfg}\)는 다음을 만족한다.
\[\begin{equation} u^\textrm{cfg} (z_t, r, t \; \vert \; \textbf{c}) = v^\textrm{cfg} (z_t, t \; \vert \; \textbf{c}) - (t - r) \frac{d}{dt} u^\textrm{cfg} (z_t, r, t \; \vert \; \textbf{c}) \end{equation}\]\(v^\textrm{cfg}\)와 \(u^\textrm{cfg}\)는 신경망에 의존하지 않는 GT field이다. 정의에 의해 $v (z_t, t) = v^\textrm{cfg} (z_t, t)$ 임을 보일 수 있다.
\[\begin{aligned} v^\textrm{cfg} (z_t, t) &= \mathbb{E}_\textbf{c} [v^\textrm{cfg} (z_t, t \; \vert \; \textbf{c})] \\ &= \omega \mathbb{E}_\textbf{c} [v (z_t, t \; \vert \; \textbf{c})] + (1 - \omega) v(z_t, t) \\ &= v(z_t, t) \end{aligned}\]\(v^\textrm{cfg} (z_t, t) = u^\textrm{cfg} (z_t, t, t)\) 이므로, \(v^\textrm{cfg}\)는 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} v^\textrm{cfg} (z_t, t \; \vert \; \textbf{c}) = \omega v (z_t, t \; \vert \; \textbf{c}) + (1 - \omega) u^\textrm{cfg} (z_t, t, t) \end{equation}\]Guidance와 함께 학습
$u^\textrm{cfg}$를 함수 \(u_\theta^\textrm{cfg}\)로 직접 parameterize한다. 그러면 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}(\theta) = \mathbb{E} \| u_\theta^\textrm{cfg} (z_t, r, t \; \vert \; \textbf{c}) - \textrm{sg} (u_\textrm{tgt}) \|_2^2 \\ \textrm{where} \quad u_\textrm{tgt} = \tilde{v}_t - (t - r) (\tilde{v}_t \partial_z u_\theta^\textrm{cfg} + \partial_t u_\theta^\textrm{cfg}) \end{equation}\]이 공식은 수정된 \(\tilde{v}_t\)를 가지고 있다는 점을 제외하면 원래 loss와 유사하다.
\[\begin{equation} \tilde{v}_t = \omega v_t + (1 - \omega) u_\theta^\textrm{cfg} (z_t, t, t) \end{equation}\]Marginal velocity인 \(v(z_t, t \; \vert \; \textbf{c})\) 항은 conditional velocity $v_t$로 대체된다. $\omega = 1$인 경우 이 loss는 CFG가 없는 원래 loss가 된다.
네트워크 \(u_\theta^\textrm{cfg}\)를 class-unconditional 입력에 노출시키기 위해, 10% 확률로 클래스 조건을 제거한다. 비슷한 이유로, \(u_\theta^\textrm{cfg} (z_t, t, t)\)도 class-unconditional 입력과 class-conditional 입력 모두에 노출시킬 수 있다.
CFG를 사용한 1-NFE 샘플링
\(u_\theta^\textrm{cfg}\)는 CFG velocity $v^\textrm{cfg}$에 의해 유도된 평균 속도인 $u^\textrm{cfg}$를 직접 모델링한다. 결과적으로 샘플링 중에 선형 결합이 필요하지 않다. 따라서 \(u_\theta^\textrm{cfg}\)를 직접 사용하여 1-step 샘플링이 가능하다.
Experiments
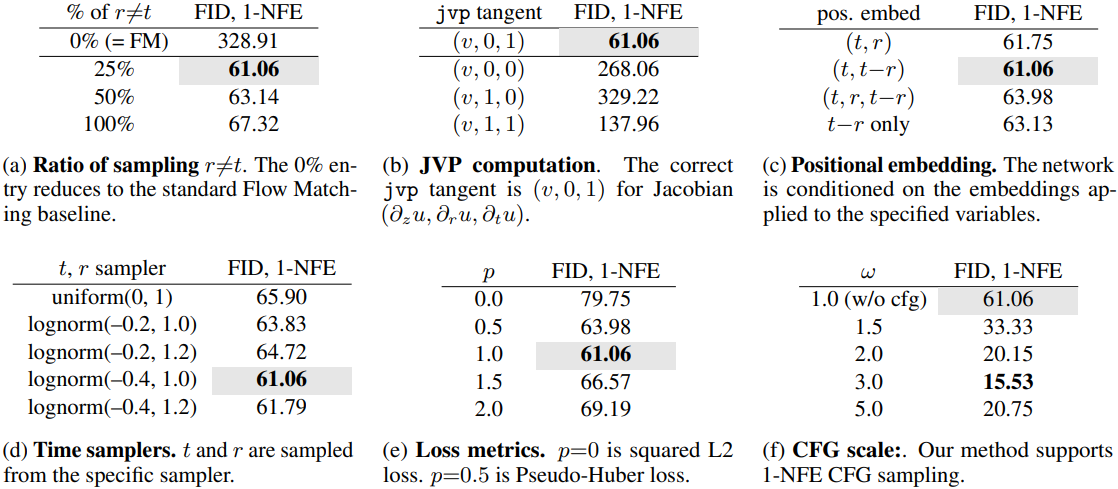
1. Ablation Study
다음은 ablation study 결과이다. (1-NFE ImageNet 256$\times$256)
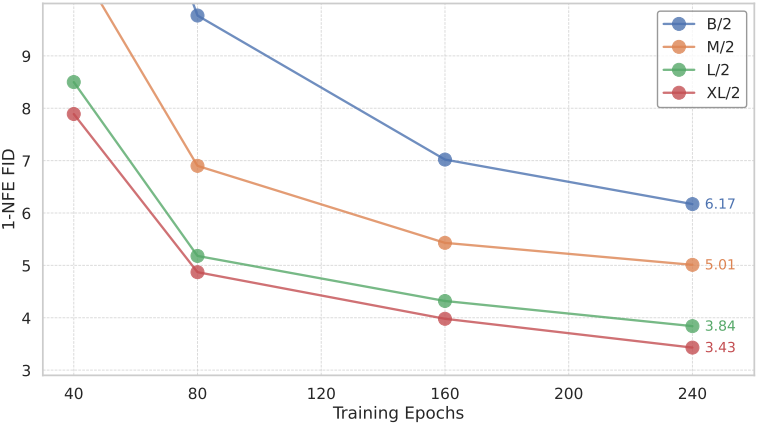
다음은 scalability를 나타낸 그래프이다. (1-NFE ImageNet 256$\times$256)
2. Comparisons with Prior Work
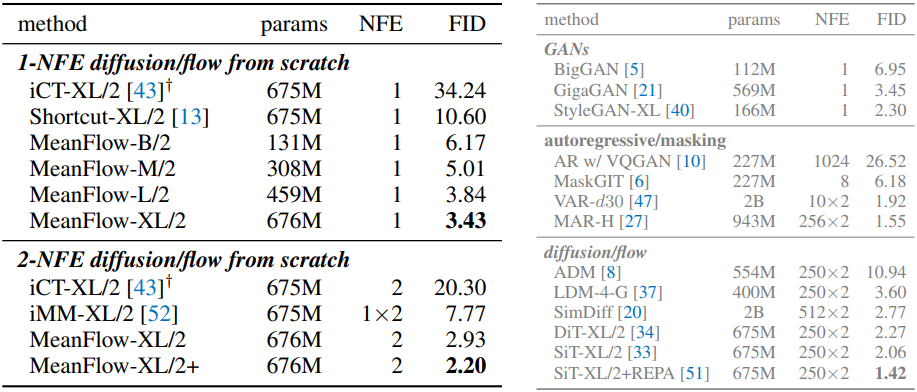
다음은 ImageNet 256$\times$256에 대한 class-conditional 생성 결과이다.
다음은 unconditional CIFAR-10에 대한 생성 결과이다.