[논문리뷰] S3OD: Towards Generalizable Salient Object Detection with Synthetic Data
ICLR 2026. [Paper]
Orest Kupyn, Hirokatsu Kataoka, Christian Rupprecht
University of Oxford, VGG | AIST
24 Oct 2025

Introduction
최근 Salient Object Detection (SOD)에는 두 가지 특수 subtask가 등장했는데, 하나는 높은 정확도의 경계에 초점을 맞춘 Dichotomous Image Segmentation (DIS)이고, 다른 하나는 2K~8K 해상도 이미지를 위한 고해상도 SOD (HR-SOD)이다. 이 두 task 모두 새로운 일반화 문제를 제시한다.
SOD는 레이블링된 데이터의 가용성에 의해 근본적으로 제한되는 task의 대표적인 예이다. 다양하고 대표적인 데이터셋을 구축하는 것은 실제 시나리오와 object 유형을 광범위하게 포괄해야 하므로 매우 어렵다. 레이블링 과정은 픽셀 단위의 정밀한 수동 annotation을 필요로 하며, 샘플당 최대 10시간이 소요될 수 있다. 더욱이, 사람마다 장면에서 주요한 object가 뭔지를 다르게 해석하기 때문에, 종종 데이터셋 간에 내재적인 모호성과 불일치를 나타내며, 이는 결정론적 접근 방식에 근본적인 어려움을 야기한다. 이러한 제약 조건으로 인해 실제 시스템의 복잡성을 제대로 반영하지 못하는 상대적으로 작은 규모의 데이터셋이 생성된다. SA-1B와 같은 대규모 데이터셋조차도 고해상도의 픽셀 단위로 완벽한 데이터를 처리하는 데 어려움을 겪는다.
기존 접근 방식은 데이터셋 규모가 작고 도메인 간 격차가 존재하기 때문에 DIS와 HR-SOD에 대해 각각 별도의 모델을 학습시키는데, 이는 특정 task에 대한 overfitting으로 이어진다. 최근의 아키텍처 혁신은 점진적인 개선을 가져왔지만, 도메인 간 일반화 문제는 해결하지 못했다. 근본적인 문제는 모델 복잡성이 아니라 데이터 부족에 있으며, 모델은 일반적으로 결정론적 예측을 강요하여 모호성을 무시한다.
합성 데이터는 매력적인 해결책이지만, 기존 접근 방식에는 치명적인 한계가 있다. 전통적인 pseudo-labeling 방식은 teacher 데이터의 성능에 제약을 받고 종종 동일한 비전 인코더에 의존하기 때문에 성능에 제약이 따른다. Diffusion model을 확장하여 마스크를 직접 예측하는 방법은 일관성 문제가 발생한다. 반면, 마스크 조건부 생성은 대규모 마스크 라이브러리 확보와 복잡한 장면 생성이라는 과제 때문에 다양성 확보에 어려움을 겪는다.
본 논문에서는 기존 연구의 두 가지 주요 한계를 해결함으로써 DIS와 HR-SOD를 통합하는 것을 목표로 하였다. 통합된 task를 high-fidelity salient segmentation이라고 명명하였다. 이를 위해 다음과 같은 요소들을 도입하였다.
- Diffusion model의 생성 능력을 활용하여 teacher 모델 병목 현상을 제거하는 멀티모달 데이터 생성 파이프라인
- 다양한 해석을 처리하는 모호성 인식 아키텍처
- 모델의 약점에 적응하는 반복적 생성 프레임워크
Model
1. Model Architecture
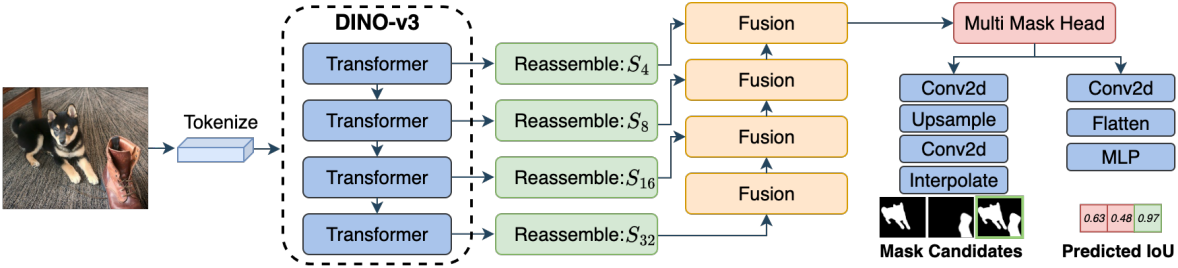
본 논문에서는 입력 이미지를 transformer layer들을 거쳐 처리한 후 멀티스케일 feature 재조립을 수행하는 Dense Prediction Transformer (DPT) 아키텍처를 기반으로 모델을 구축했다. DPT는 입력을 패치 토큰 시퀀스로 변환하고, transformer layer를 통해 처리한 후, 멀티스케일 이미지와 유사한 표현으로 reshape한다. 이러한 feature들은 점진적으로 융합되고 residual convolutional block을 통해 업샘플링되어 최종 예측값을 생성한다. 저자들은 일반화 성능 향상을 위해 DPT 인코더를 DINO-v3 가중치로 초기화했다.
본 논문의 목표는 이미지 $\mathcal{I} \subset \mathbb{R}^{H \times W \times 3}$에서 binary mask \(\mathcal{M} = \{0, 1\}^{H \times W}\)로 매핑하는 함수 $f : \mathcal{I} \rightarrow \mathcal{M}$을 찾는 것이다. 많은 학습 annotation은 모호하다. 여러 object가 존재할 수 있으며, 중요도 해석이 불분명할 수 있다. 단일 출력 모델은 종종 가능한 모든 예측을 평균화하여 신뢰도가 낮은 영역을 생성한다.
이를 해결하기 위해 최종 마스크 예측 head는 여러 개의 마스크 $(m_1, \ldots, m_N)$을 출력하도록 설계되었다. 예측된 마스크는 픽셀 단위의 신뢰도를 모델링하기 위해 soft mask $m_i \in (0, 1)^{H \times W}$이다. 각 학습 이미지 $I \in \mathcal{I}$에 대해, 하나의 GT annotation $y \in \mathcal{M}$만 사용 가능하다. 학습 중 주요 loss는 예측된 마스크와 GT 마스크 간의 IoU 점수를 통해 선택된 최적의 예측 $i^\ast$에 적용된다.
\[\begin{equation} i^\ast = \underset{i}{\arg \max} \; \textrm{IoU} (m_i , y) \end{equation}\]사용되지 않는 branch의 성능 저하를 방지하기 위해, 모든 branch에 걸쳐 가중치가 점차 감소하는 방식으로 loss를 계산하는 relaxed assignment 방식을 사용한다. 테스트 시점의 마스크 선택을 위해, 모델은 모든 예측에 대해 IoU 점수 $(s_1, \ldots, s_N)$을 추정한다. 이는 학습 중 예측과 GT 간의 IoU 점수를 기반으로 하며, 이 추정치를 사용하여 테스트 시 IoU 점수가 가장 높은 마스크를 선택한다.
2. Objective Function
표준적인 semantic segmentation 방식을 따라, 픽셀별 supervision과 영역별 supervision을 결합한 loss를 사용한다. 전체 loss $\mathcal{L}$은 클래스 불균형을 위한 focal loss와 영역 수준 정확도를 위한 IoU loss의 두 가지 구성 요소로 이루어져 있다.
Focal Loss
전경-배경 불균형 문제를 해결하기 위해, dense prediction에서 널리 사용되는 focal loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{focal} (m_i) = - \sum_{p=1}^{H \times W} (1 - m_i (p))^\tau y(p) \log (m_i (p)) \end{equation}\]($m_i (p)$는 예측된 마스크, $y(p)$는 GT 마스크, $\tau = 2$)
IoU Loss
영역 수준의 정확도를 측정하기 위해, 예측된 마스크와 GT 마스크 간의 중첩도를 측정하는 IoU loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{IoU} (m_i) = 1 - \frac{\sum_{p=1}^{H \times W} m_i (p) y(p)}{\sum_{p=1}^{H \times W} (m_i (p) + y(p) - m_i (p) y(p))} \end{equation}\]전체 mask loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{mask} (m_i) = \lambda_\textrm{mask} \mathcal{L}_\textrm{focal} (m_i, y) + \mathcal{L}_\textrm{IoU} (m_i, y) \end{equation}\](\(\lambda_\textrm{mask} = 10\))
IoU Score Loss
Inference 시 최적의 마스크 선택을 가능하게 하기 위해, 예측된 IoU $s_i$와 실제 IoU 값 사이의 MSE를 loss로 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{score} (s_i) = (s_i - \textrm{IoU} (m_i, y))^2 \end{equation}\]전체 학습 loss는 최적 예측에 대한 mask loss, 모든 예측에 대한 score loss, 모든 예측 마스크에 걸쳐 감소하는 정규화 항으로 구성된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{mask} (m_{i^\ast}) + \sum_{i=1}^N \lambda_\textrm{score} \mathcal{L}_\textrm{score} (s_i) + \lambda_\textrm{reg} e^{-\gamma t} \mathcal{L}_\textrm{mask} (m_i) \end{equation}\](\(\lambda_\textrm{score} = 0.05\), \(\lambda_\textrm{reg} = 0.1\), $\gamma = 0.2$, $t$는 현재 epoch, $N$은 전체 예측 branch 개수)
Dataset
다른 dense prediction task와 달리, SOD 데이터셋의 확장은 LAION과 같은 기존 컬렉션을 단순히 활용하는 것만으로는 해결할 수 없는 고유한 과제를 안고 있다. SOD는 전경 객체가 명확하게 구분되는 샘플을 필요로 하며, 특히 경계 조건이 정확한 고해상도 이미지의 경우 annotation에 상당한 전문 지식과 세심한 주의가 요구된다. 이러한 제약 조건으로 인해 기존의 수동 데이터셋 관리 방식은 비현실적이고 비용 효율적이지 않다. 본 논문의 목표는 실제 분포를 정확하게 반영하는 대규모 합성 데이터를 생성하는 것이다.
1. Multi-Modal Dataset Diffusion
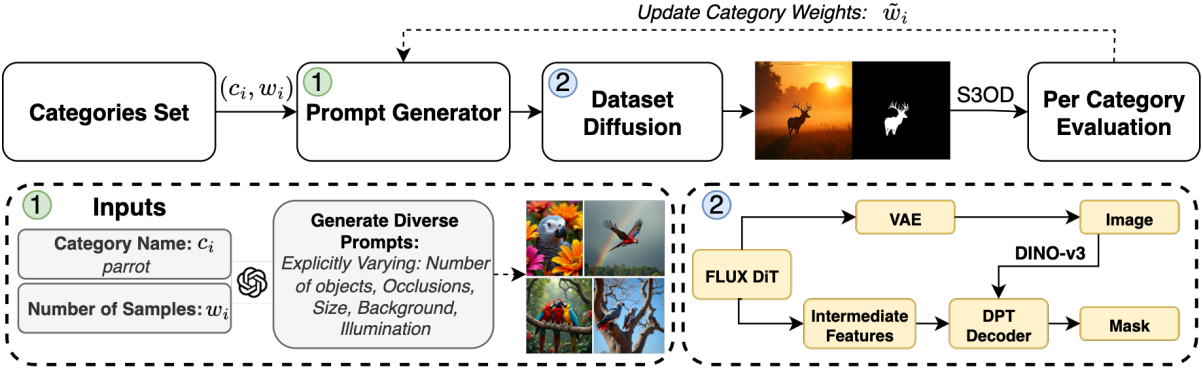
대규모 DiT인 FLUX는 생성 과정에서 풍부한 semantic 및 공간적 표현을 인코딩한다. 이러한 latent 표현을 무시하고 생성된 이미지에서 마스크를 직접 예측하는 teacher 모델에 의존하는 대신, 본 논문에서는 여러 보완적인 모달리티를 결합하여 마스크를 출력하도록 diffusion model을 확장하였다. 공간적 이해를 인코딩하는 latent feature map, 해석 가능한 semantic localization을 제공하는 concept-attention map, 그리고 디코딩된 이미지에서 세밀한 semantic을 포착하는 DINO-v3 feature를 추출한다. 이러한 멀티모달 supervision은 데이터 부족 문제를 완화하고 생성된 이미지와 해당 마스크 간의 정렬을 보장한다.
DiT Feature Maps
FLUX DiT는 텍스트 토큰과 이미지 토큰을 별도로 처리하는 19개의 dual-stream transformer block과 연결된 시퀀스를 처리하는 38개의 single-stream block으로 구성된 하이브리드 아키텍처를 사용한다. 4개의 single-stream transformer block (4, 16, 27, 36)에서 feature map을 추출한다. 각 block은 $B \times (L_T + L_I) \times 3072$ 크기의 feature를 출력하며, 여기서 $L_T = 512$이다. 저자들은 이미지 토큰만 추출하여 $B \times L_I \times 3072$ 크기의 feature를 학습된 projection을 통해 768차원으로 projection시켰다. 이러한 feature는 생성 과정에서 사용되는 모델 내부의 공간 이해를 인코딩한다.
Concept Attention Maps
일반적인 데이터셋 생성 방법은 모든 텍스트 토큰에 걸쳐 평균 attention map을 추출하여 의미적으로 모호한 supervision을 생성한다. 대신, 저자들은 해석 가능하고 일관된 map을 얻기 위해 정적인 개념 집합을 사용하였다. Concept-attention 프레임워크를 따라, 생성된 각 이미지에 대해 이미지 패치와 개념 토큰 간의 attention map을 계산한다. 개념 토큰 $c$와 이미지 패치 $x$에 대해 다음과 같이 계산한다.
\[\begin{equation} A_\textrm{concept} (x, y) = \textrm{softmax}(o_x \cdot o_c^\top) \end{equation}\]($o_x$와 $o_c$는 transformer layer에서 출력되는 attention 벡터)
각 샘플에 대해, 주요 object 카테고리(ex. “dog”)와 “background” 토큰을 사용하여 두 개의 개념 attention map을 추출한다. 이렇게 생성된 해석 가능한 맵 \(\{A_\textrm{object}, A_\textrm{background}\}\)는 object 위치와 배경 영역을 일관되게 인코딩한다.
DINO-v3 Visual Features
DINO-v3 (ViT-L)를 사용하여 생성된 이미지에서 semantic feature를 추출한다. 이를 통해 대규모 실제 데이터에 대한 self-supervised learning으로 학습된 풍부한 object-level 표현을 제공한다.
세 가지 모달리티는 각각 별도의 convolution branch와 batch normalization을 거쳐 공통의 256차원 공간으로 projection하는 전용 모듈을 통해 융합된다. FLUX feature와 concept-attention map은 bilinear interpolation을 사용하여 DINO-v3 해상도에 맞게 업샘플링된다. Projection된 feature는 채널별로 concat되고 2단계 convolutional network (3$\times$3 후 1$\times$1)을 통해 처리된다. 최종 결과는 원래의 DINO-v3 feature와 결합되어 통합된 멀티모달 표현을 생성한다. 이 결합된 표현을 DPT 디코더에 입력하고 DIS-5K, HR-SOD, UHRSOD, DUTS 데이터셋으로 학습시켜 모델이 여러 소스를 세밀한 segmentation mask로 디코딩하는 방법을 학습하도록 한다.
2. Iterative Data Synthesis
저자들은 데이터 생성에 피드백 메커니즘을 통합하기 위해, 모델의 성능에 따라 파라미터들을 조정하는 반복 프로세스를 도입하였다. 합성 데이터 $\mathcal{D}^{(r)}$로 모델을 학습시킨 후, 각 카테고리 $c_i$에 대해 별도의 테스트 세트에서 모델의 성능을 평가한다. 각 이미지 $I_j$에 대해, 다양한 이미지 변환(ex. 뒤집기)에 대한 평균 IoU 점수인 $\kappa (I_j)$를 계산한다. 그런 다음, 카테고리 $c_i$에 속하는 모든 이미지에 대해 이러한 점수를 평균하여 평균 카테고리 점수 \(\bar{\kappa}_i\)를 계산한다. 다음 iteration의 카테고리 가중치 $w_i^{(r+1)}$는 다음과 같은 비선형 scaling function을 통해 계산된다.
\[\begin{equation} w_i^{(r+1)} = \frac{1}{\vert \mathcal{C} \vert} + \frac{4}{\vert \mathcal{C} \vert} e^{- \alpha (\bar{\kappa}_i - \beta)} \end{equation}\]($\alpha = 8$, $\beta = 0.5$)
이 함수는 주어진 threshold 미만의 점수를 가진 카테고리의 가중치를 높이는 동시에 성능이 우수한 카테고리의 최소 가중치를 유지한다. 이러한 적응형 샘플링 전략은 합성 데이터 생성 프로세스가 지속적으로 진화하여 모델 개선을 극대화하는 예제를 생성하도록 보장한다.
3. Multi-Stage Quality Filtering
합성 데이터 생성은 확장성을 제공하지만, 필연적으로 학습 품질을 저하시킬 수 있는 불완전한 샘플을 생성한다. 저자들은 고품질 데이터셋을 보장하기 위해, 합성 데이터 생성에서 발생하는 일반적인 오류들을 해결하는 포괄적인 다단계 필터링 파이프라인을 구현했다.
- 일관성 필터링: FLUX feature 없이 학습된 별도의 대규모 모델을 사용하여 예측 일관성을 평가한다. 각 샘플에 대해 원래 예측과 수평으로 뒤집힌 예측 간의 IoU를 계산하고, $\tau = 0.8$의 일관성 threshold 미만인 샘플을 필터링한다. 낮은 일관성 점수는 강력한 모델조차 일관된 예측을 유지하기 어려운 지나치게 모호한 샘플을 나타내며, 이는 생성된 이미지-마스크 쌍에 근본적인 문제가 있음을 시사한다.
- 마스크 품질 평가: Gemma-3 VLM을 사용하여 파편화, 노이즈, image segmentation에서 흔히 발생하는 아티팩트를 식별하고, 마스크 품질을 평가한다. Main component가 5개 이하인 마스크만 이 단계를 통과하여 모델 학습을 위한 깨끗한 supervision을 보장한다.
- Semantic 검증: Gemma VLM을 사용하여 원본 이미지와 마스크 오버레이를 분석하여 semantic 정확성을 평가한다. 이 단계는 salient object의 존재와 적절한 마스크 커버리지(70% 이상)를 모두 보장하여, 멀티모달 supervision이 의도한 semantic 컨텐츠를 포착하지 못한 샘플을 걸러낸다.
이러한 다단계 접근 방식을 통해 생성된 샘플의 6.8%가 제거되어 데이터셋 품질이 크게 향상되는 동시에 규모적 이점을 유지한다.


Experiments
1. Cross-Dataset Generalization
다음은 다양한 데이터셋에 대한 일반화 성능을 비교한 결과이다. (SOD 데이터셋은 HRSOD-TR + UHRSD-TR + DUTS-TR)
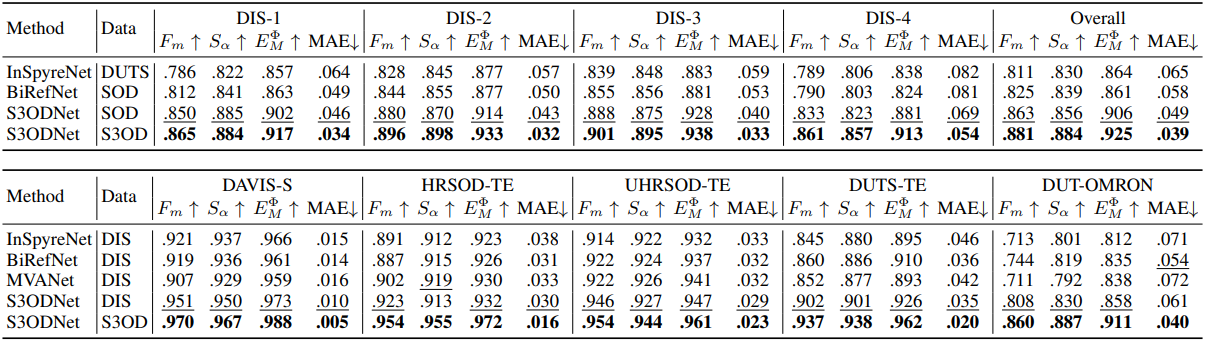
다음은 학습 데이터셋에 따른 SOD 성능을 다양한 방법들에 대해 비교한 결과이다.

2. State-of-the-Art Comparison
다음은 DIS5K와 SOD 벤치마크에 대한 비교 결과이다.
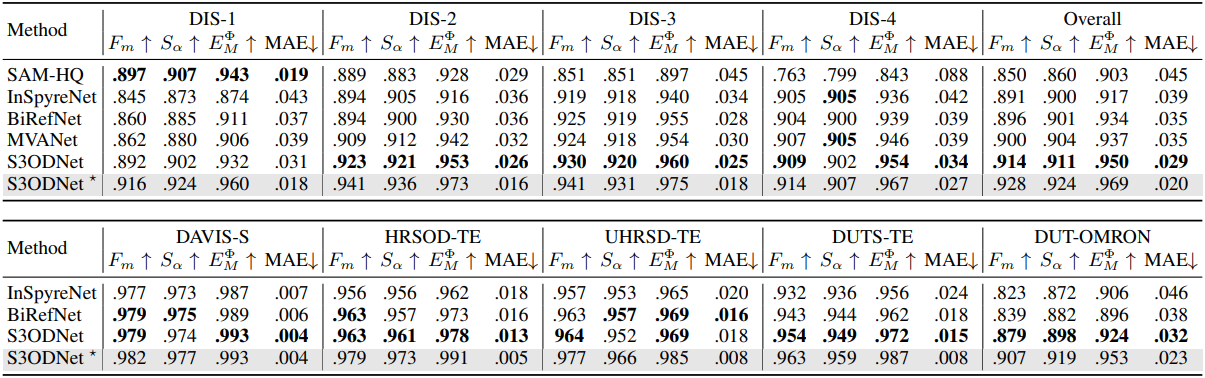
3. Synthetic Data Evaluation
다음은 함께 사용한 합성 데이터에 따른 성능을 비교한 결과이다.

4. Generalization to Camouflaged Object Detection
다음은 Camouflaged Object Detection 벤치마크에 대한 비교 결과이다.

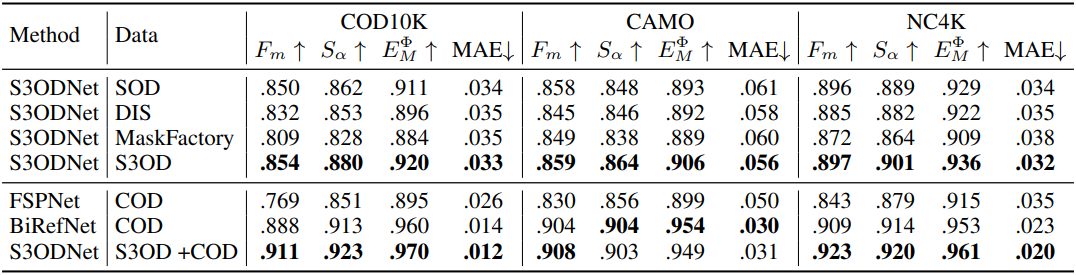
5. Ablation Study
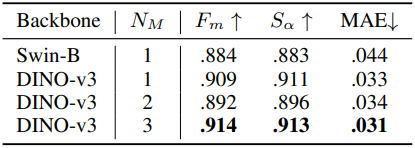
다음은 반복적인 데이터 생성에 대한 ablation 결과이다.

다음은 데이터 diffusion model에 대한 ablation 결과이다.

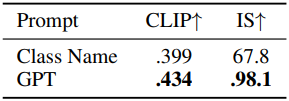
다음은 (왼쪽) 아키텍처와 (오른쪽) 프롬프트에 대한 ablation 결과이다.