[논문리뷰] From Blobs to Spokes: High-Fidelity Surface Reconstruction via Oriented Gaussians
arXiv 2026. [Paper] [Page] [Github]
Diego Gomez, Antoine Guédon, Nissim Maruani, Bingchen Gong, Maks Ovsjanikov
LIX | Inria
8 Apr 2026

Introduction
3DGS에서 표면을 추출하는 데 있어 핵심적인 한계는 primitive 자체의 해석 방식에 있다. 표준적인 접근 방식은 Gaussian들을 질량 또는 밀도를 가진 대칭적인 blob들로 취급한다. 이러한 가정은 비어 있는 공간과 채워진 공간을 구분하는 표면의 본질과 상충된다. 표면의 점들을 대칭적인 primitive로 모델링함으로써 기존 방법들은 재구성에 편향을 초래하고 표면 추출을 훨씬 더 어렵게 만든다.
본 연구에서는 Gaussian Wrapping이라는 새로운 프레임워크를 도입하여 이러한 한계를 해결하였다. 이 프레임워크는 Objects as Volumes (OaV)에서 영감을 받아 Gaussian primitive의 역할을 재해석하였다. Gaussian을 대칭적인 구름으로 취급하는 대신, 방향성을 가진 확률적 표면 요소로 간주하여 방향성을 가진 half-space 내에서만 primitive를 표현한다. 이러한 관점에서 Gaussian은 경계의 바깥쪽 면에서 밀도 감소를 모델링하고, 안쪽 면은 완전히 채워진 것으로 간주한다.
이를 통해 robust한 wrapping 전략을 도출할 수 있다. 즉, 방향성 표면 가정이 위반되는 기하학적 간극을 식별하여 방향성을 가진 primitive로 이루어진 watertight한 껍질을 얻는다. 본 프레임워크는 occupancy, vacancy, normal field와 같은 기하학적 양을 closed-form으로 도출할 수 있도록 하여, 아티팩트나 누락된 geometry 없이 얇은 구조를 재구성할 수 있게 한다.
Background and Motivation
Objects as Volumes
명확하게 정의된 표면을 재구성하려면 occupancy function $\mathcal{O} : \mathbb{R}^3 \rightarrow [0, 1]$과 같은 적절하게 정의된 geometric field가 필요하지만, NeRF와 3DGS의 핵심인 볼륨 렌더링은 날카로운 경계가 아닌 연속적이고 반투명한 볼륨에서 작동한다. Objects as Volumes (OaV)는 장면을 확률적 표면으로 해석함으로써 이러한 간극을 메웠다.
구체적으로, exponential light transport를 가정할 때, 이 프레임워크는 Nerual SDF의 이론적 정당성을 뒷받침하고, vacancy \(v(\textbf{x}) = 1 − \mathcal{O}(\textbf{x})\)를 volumetric ray-marching의 attenuation (또는 density) $\sigma$와 연결한다.
\[\begin{equation} \forall (\textbf{x}, \textbf{w}) \in \mathbb{R}^3 \times \mathcal{S}^2, \quad \sigma (\textbf{x}, \textbf{w}) = \vert \textbf{w} \cdot \nabla \log v (\textbf{x}) \vert \end{equation}\]이 방정식은 geometric field인 vacancy를 볼륨 렌더링을 구동하는 attenuation과 직접 연결한다.
어떤 두 점 \(\textbf{x}_1\)과 \(\textbf{x}_2\)에 대해, \(\textbf{x}_1\)에서 \(\textbf{x}_2\)로 가는 경우의 투과율 감소와 \(\textbf{x}_2\)에서 \(\textbf{x}_1\)으로 가는 경우의 투과율 감소는 같아야 한다. 따라서 attenuation은 다음과 같이 reciprocal해야 한다.
\[\begin{equation} \sigma (\textbf{x}, \textbf{w}) = \sigma (\textbf{x}, -\textbf{w}) \end{equation}\]3DGS와 동등한 attenuation 모델 찾기
통계적 독립성과 겹치지 않는 Gaussian primitive를 가정할 때, 알파 블렌딩에 기반한 3DGS 모델은 다음과 같은 attenuation을 갖는 ray-marching 볼륨 렌더링 모델과 동등하다.
\[\begin{equation} \sigma (\textbf{x}, \textbf{w}) = \sum_{i=1}^N \max (0, -\textbf{w} \cdot \nabla \log (1 - G_i (\textbf{x}))) \end{equation}\]그러나 이 표현식은 일반적으로 reciprocal하지 않다. Reciprocity는 OaV 결과를 적용하기 위한 필수 조건이므로, 이 표현식을 사용하면 closed-form vacancy 표현식을 도출할 수 없다.
Oriented Gaussian
Reciprocity를 복원하기 위해, 저자들은 Gaussian에 방향을 부여하는 방식을 제안하였다. 즉, 각 primitive에 학습 가능한 normal 벡터를 부여하는 것이다. 구체적으로, 각 Gaussian에 normal 파라미터 \(n_i \in \mathcal{S}^2\)를 할당하고, attenuation을 다음과 같이 정의한다.
\[\begin{equation} \bar{\sigma}_i (\textbf{x}, \textbf{w}) = \unicode{x1D7D9}_{n_i^\top (\textbf{x} - \mu_i) \ge 0} \vert \textbf{w} \cdot \nabla \log (1 - G_i (\textbf{x})) \vert \end{equation}\]이는 OaV의 요구 사항을 충족하는 명시적인 attenuation 기반 3DGS 공식을 도출하여, 보다 정확한 깊이 렌더링과 표면 추출을 위한 명시적인 geometric field를 제공한다. 또한, 이 attenuation 기반 공식은 가우시안 분포가 장면을 적절하게 감싼다는 추가적인 가정 하에, 3DGS 모델과 동일한 볼륨 렌더링 모델을 유도한다.
Method

1. Gaussian Wrapping
저자들의 핵심 직관은 간단하다. 정확한 표면 재구성을 위해서는 Gaussian들이 object 주변에 빈틈없는 경계를 형성해야 한다는 것이다. 이를 위해 각 Gaussian에 학습 가능한 normal 벡터 $n_i$를 부여하고, 표면 근처의 보이는 Gaussian은 카메라 방향을 향하도록 한다. 이러한 wrapping을 통해 자전거 바퀴살처럼 매우 얇은 구조물 주변에도 primitive로 이루어진 연속적인 껍질을 생성할 수 있다. 기존의 방법으로는 이러한 구조물의 외형만 몇 개의 primitive로 복원할 수 있을 뿐, geometry는 복원할 수 없었다.
저자들은 두 가지 상호 보완적인 메커니즘을 통해 장면 속에서의 wrapping을 촉진시켰다.
Normal alignment loss
Splatting rasterizer를 사용하여 depth와 normal $n_i$를 렌더링하면 각각 표면 깊이 추정치와 표면 근처 Gaussian의 예상 방향을 얻을 수 있다. 따라서 학습 과정에서 normal $n_i$와 표면 사이를 다음과 같이 정렬한다.
\[\begin{equation} \mathcal{L}_\textrm{N} = \sum_p 1 - N(p) \cdot \nabla D(p) \end{equation}\]($N(p)$는 픽셀 $p$에서의 렌더링된 normal, $\nabla D (p)$는 렌더링된 depth의 image-space gradient)
저자들은 본 프레임워크에 맞게 미분 가능한 CUDA rasterizer를 수정하고, 깊이를 geometric field의 정확한 0.5-isosurface로 렌더링하였다.
Densification
Gaussian들이 표면의 모든 면을 덮지 못하는 부분에는 \(\mathcal{L}_\textrm{N} (p)\)가 로컬하게 증가한다. 이는 자연스러운 densification 기준을 제공한다. $K$ iteration마다 모든 학습 뷰에 걸쳐 \(\mathcal{L}_\textrm{N} (p)\)를 계산하고, 이를 블렌딩 가중치를 통해 개별 Gaussian에 전파한다. 이 값이 큰 Gaussian은 normal을 반전시켜 복제함으로써 틈을 메운다.
Loss 디테일
최적화 과정에서, \(\mathcal{L}_\textrm{N}\)과 함께 3DGS의 photometric loss \(\mathcal{L}_\textrm{RGB}\), 2DGS의 depth-normal consistency \(\mathcal{L}_\textrm{DN}\), PGSR의 multi-view loss를 사용한다. 전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{RGB} + \lambda_\textrm{DN} \mathcal{L}_\textrm{DN} + \lambda_\textrm{N} \mathcal{L}_\textrm{N} + \mathcal{L}_\textrm{MV} \\ \textrm{where} \quad \mathcal{L}_\textrm{MV} = \lambda_\textrm{pc} \mathcal{L}_\textrm{pc} + \lambda_\textrm{gc} \mathcal{L}_\textrm{gc} \end{equation}\](\(\lambda_\textrm{DN} = 0.05\), \(\lambda_\textrm{N} = 0.05\), \(\lambda_\textrm{pc} = 0.6\), \(\lambda_\textrm{gc} = 0.02\))
2. Gaussian Vector and Normal Fields
$N$개의 oriented Gaussian들로 이루어진 Gaussian vector field \(V : \mathbb{R}^3 \rightarrow \mathbb{R}^3\)와 $V$의 normalization \(N : \mathbb{R}^3 \rightarrow \mathcal{S}^2\)를 다음과 같이 정의한다.
\[\begin{aligned} V(x) &:= \nabla \log v(x) = \sum_{i=1}^N \mathbb{1}_{n_i^\top (x-\mu_i) \ge 0} \nabla \log (1 - G_i (x)) \\ N(x) &:= \frac{V(x)}{\| V (x) \|} \end{aligned}\]이러한 closed-form 표현식은 Gaussian 파라미터를 표면 geometry에 직접 연결하며 메쉬 추출 파이프라인의 기초를 형성한다. 점 $x$ 주변의 Gaussian을 쿼리함으로써 이러한 값들을 명시적으로 쿼리할 수 있다.
3. Mesh Extraction
메쉬 추출을 위한 implicit function으로 vacancy $v$를 활용한다. 임의의 카메라 광선을 따라 $V$를 직접 적분하는 것도 가능하지만, 렌더링에 기여하지 않는 Gaussian은 최적화 후에도 geometry 내부에 숨겨져 있을 수 있으며, 이는 wrapping 가정을 위반하고 광선을 따라 교차할 경우 아티팩트를 생성한다. 따라서, 모든 학습 카메라 광선 집합 \(\mathcal{T}_c\)를 순회하면서 vacancy를 계산한다.
\[\begin{equation} v (\textbf{x}) = \max_{(\textbf{o}, \textbf{w}) \in \mathcal{T}_c} \left\{ \prod_{i=1}^N \left(1 - \bar{G}_{\textbf{o}, \textbf{w}}^{(i)} (t) \right) \, : \, \textbf{x} = \textbf{o} + t \textbf{w}, \, t > 0 \right\} \\ \textrm{where} \quad \bar{G}_{\textbf{o}, \textbf{w}}^{(i)} (t) = G_i (\textbf{o} + \min (t, t_{\textbf{o}, \textbf{w}}^{G_i}) \textbf{w}), \quad t_{\textbf{o}, \textbf{w}}^{G_i} = \underset{t \ge 0}{\arg \max} G_i (\textbf{o} + t \textbf{w}) \end{equation}\]직관적으로, 이 계산은 점 $x$에 도달하는 가장 방해받지 않는 광선을 찾는 것과 같다. 엄밀히 말하면, 이 표현식은 실제 vacancy에 대한 하한값이며 본질적으로 robust하다. 곱셈 결과는 광선을 따라서 감소만할 수 있으므로, geometry 내부에 숨겨진 Gaussian이 vacancy 추정치를 부풀릴 수 없다.
Pivot-Based Marching Tetrahedra
표면은 각 Gaussian의 중심과 저밀도 영역 사이에서 교차하며 oriented plane에 평행하다. 따라서 각 Gaussian에 대해 중심 \(\mu_i\)와 \(\mu_i + 2 s_i n_i\), 두 개의 Delaunay pivot을 생성한다. 여기서 \(s_i = \vert \vert S_i R_i^\top n_i \vert \vert_2\)이다. 그런 다음 Delaunay tetrahedralization 결과에 Marching Tetrahedra를 적용하고 binary search를 통해 vertex들을 0.5-isosurface로 다듬는다.
이 접근 방식은 Gaussian당 2개의 pivot을 사용하기 때문에, 이전 방법들에서 요구했던 Gaussian당 9개의 pivot과는 대조적으로 표면 충실도를 희생하지 않고 훨씬 가볍고 완벽한 메쉬를 생성한다.
Primal Adaptive Meshing
단순하고 효율적이긴 하지만, pivot 기반 방식은 장면 geometry가 아닌 Gaussian primitive에서 직접 vertex를 생성한다. 글로벌한 vacancy field $v$를 활용하고 메쉬 생성을 더욱 개선하기 위해, 저자들은 Delaunay 기반 재구성 방법에서 영감을 받은 적응형 메쉬 생성 프레임워크를 도입하였다. 이 파이프라인은 다음과 같이 진행된다.
- Vertex 초기화: Marching Tetrahedra 메쉬의 면들을 샘플링하여 vertex를 초기화하는데, 이때 각 면에는 가장 가까운 학습 카메라와의 거리에 반비례하는 가중치를 부여한다.
- Isosurface 정제: Vertex들은 반복적인 Newton update를 통해 0.5-isosurface로 projection된다.
- 필터링: $\vert 0.5 − v(x) \vert > \epsilon$인 vertex $x$는 outlier로 간주되어 제거된다. 더 이상 제거되는 점이 없을 때까지 1~3단계를 반복한다.
- Delaunay: 남은 vertex들에 대해 Delaunay tetrahedralization을 계산하고, 랜덤 샘플링된 내부 점의 vacancy 값을 기준으로 각 사면체를 내부 또는 외부로 분류한다.
- 메쉬 추출: 최종 표면 메쉬는 내부 사면체와 외부 사면체를 분리하는 삼각형 면을 추출하여 얻는다.
이 접근 방식은 메쉬 해상도를 Gaussian 분포와 효과적으로 분리하여 장면의 제한된 영역에 대해 매우 세밀한 메쉬 생성을 가능하게 한다. 결과적으로 생성된 메쉬는 smoothness가 크게 향상되고 discretization 아티팩트가 감소한다.

Experiments
1. Main Results
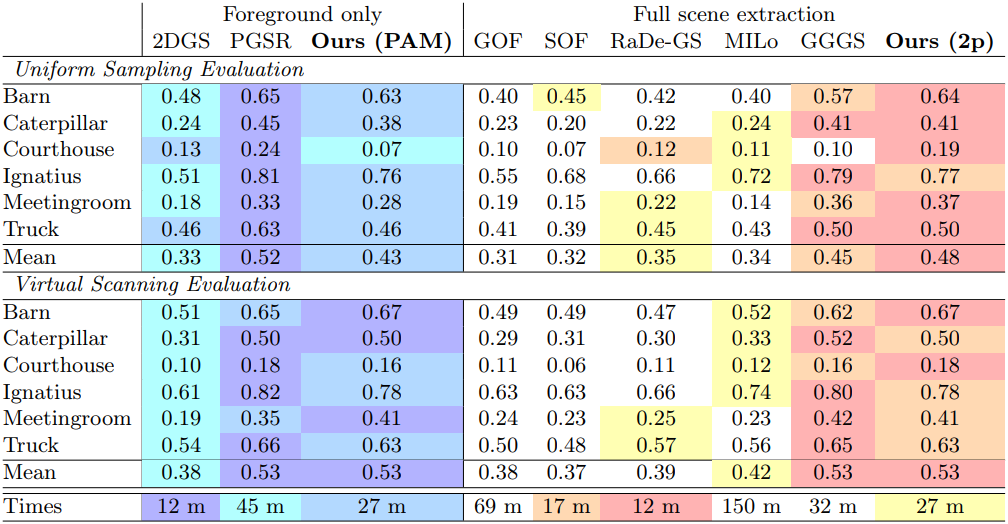
다음은 Tanks & Temples에서의 F1 score를 비교한 결과이다.
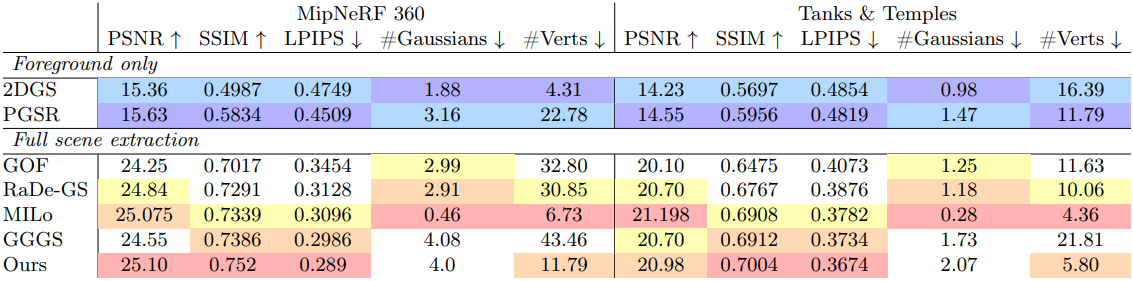
다음은 novel view synthesis 성능을 비교한 결과이다.
다음은 Tanks & Temples와 MipNerf360에서의 결과를 비교한 예시들이다.

2. Ablation Studies
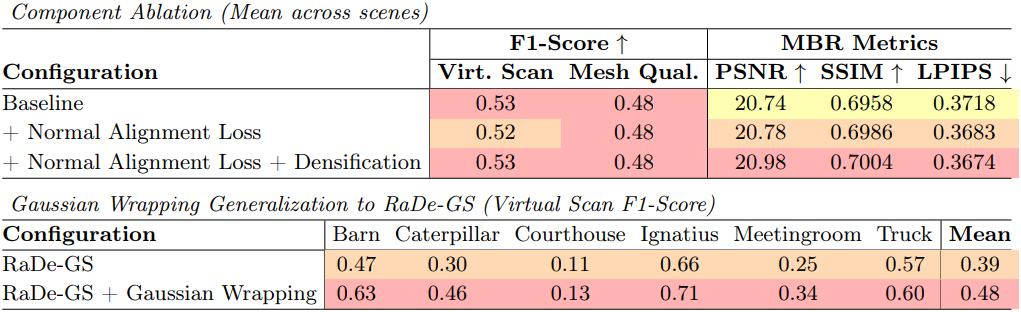
다음은 Tanks & Temples에서의 ablation study 결과이다.