[논문리뷰] PI-Light: Physics-Inspired Diffusion for Full-Image Relighting
ICLR 2026. [Paper]
Zhexin Liang, Zhaoxi Chen, Yongwei Chen, Tianyi Wei, Tengfei Wang, Xingang Pan
Nanyang Technological University | Tencent
29 Jan 2026

Introduction
기존 이미지 relighting 방법들은 세 가지 주요 한계점이 있다.
- 다양하고 복잡한 장면 조명을 포함하는 데이터셋을 확보하는 것이 가장 큰 어려움이다. 전체 장면에서 다양하고 제어된 조명 조건 하에 고품질 이미지를 얻는 것은 자원 소모가 심하고 기술적으로도 매우 어렵다. 특히, 동일한 장면을 여러 조명 조건에서 촬영한 실제 데이터셋을 확보하는 것은 현실적으로 불가능하다.
- 물리적 타당성을 확보하는 것이 여전히 어렵다. 순수 데이터 기반 접근 방식은 종종 기본적인 light transport 원리를 위반하는 결과를 생성하기 때문이다.
- 제한적인 데이터 기반 prior는 일반화 가능성을 저해하여, 더 많은 미지의 material, 조명 조건 또는 현실적인 장면 구성을 접할 때 robustness가 떨어진다.
이러한 어려움을 해결하기 위해, 본 논문에서는 전체 이미지 relighting 문제를 다루도록 설계된 새로운 diffusion 기반 신경망 relighting 파이프라인인 $\pi$-Light를 제안하였다. 기존의 PBR 접근 방식과 유사하게, 본 접근 방식 역시 inverse neural rendering과 forward neural rendering의 2단계 프레임워크를 채택하지만, 다음과 같은 주요 측면에서 기존 연구와 차별화된다.
- Inverse neural rendering과 forward neural rendering 단계 모두에서 표준 self-attention layer가 global-aware하도록 확장하여 batch 간 통신을 가능하게 한다. 이러한 설계는 효율성과 예측된 intrinsic들 간의 일관성을 모두 향상시킨다.
- 물리 기반 loss를 효율적인 학습 메커니즘으로 활용하는 physics-inspired neural forward rendering 모듈을 설계했다. 본 논문에서 제안하는 물리 기반 loss는 학습 과정을 물리적으로 타당한 환경으로 정규화하여 수렴을 용이하게 하고, 더 적은 데이터와 계산량으로 더 정확한 light transport를 학습할 수 있도록 한다.
- Environment map의 전면 반구만을 사용하는 간단하면서도 효과적인 조명 표현 방식을 제안하였다. 이 설계는 자체 발광 물체와 내장된 장면 조명의 간섭을 피하고, 배경의 일관성을 유지하면서 빛의 방향과 강도를 효과적으로 제어할 수 있도록 한다.
결과적으로, 본 논문에서 제안하는 방법은 기존 연구보다 적은 학습 샘플과 완전한 현실적 데이터셋 없이도 경쟁력 있는 성능을 달성하고 실제 장면에도 잘 일반화된다.
저자들은 데이터 부족 문제를 해결하기 위해, 제어된 조명 조건에서 촬영된 다양한 object와 장면을 특징으로 하는 새로운 데이터셋을 구축했다. 이 데이터셋은 supervised learning을 지원할 뿐만 아니라 포괄적인 후속 벤치마킹도 가능하게 한다. 사전 학습을 통해 얻은 이미지 정보를 활용하여 이 데이터셋으로 학습한 $\pi$-Light는 다양한 object와 장면에서 뛰어난 일반화 성능을 보여주었다.
Method
1. Dataset Construction
Object Data
Object 중심 데이터의 경우, 필터링된 Objaverse에서 BRDF material을 포함하는 10,000개 이상의 object를 무작위로 선택하고 다양한 시점과 조명 조건에서 렌더링한다. 각 object는 10개의 시점과 10개의 조명 조건으로 렌더링되어 object당 총 100개의 이미지를 생성한다. 조명은 위쪽 반구에서 샘플링되며, point light와 Poly Haven에서 제공하는 700개 이상의 environment map 중에서 무작위로 선택된 HDRI map을 모두 포함한다.
BlenderProc은 Blender의 composition layer를 활용하여 고유 속성을 생성한다. 그러나 특정 albedo 값이 광원에 따라 변동하고, 투명 또는 반투명 material의 경우 composition layer가 종종 완전히 흰색 또는 검은색 값을 출력하여 부정확한 결과를 나타낸다. 이러한 문제를 해결하기 위해 Blender의 Principled BRDF 노드에서 모든 고유 속성을 직접 추출하고, Principled 영역이 아닌 부분을 제외하는 마스크를 생성한다.
기존의 방법들은 글로벌 HDRI 조명 정보를 사용하거나 배경에서 조명을 추론하여 전경을 재조명하는 방식을 사용했다. 본 논문에서는 이미지에 직접 접해 있는 광원, 즉 HDRI에서 렌더링된 회색 구의 앞쪽 반구만을 이용하여 조명 조건을 구성한다. 이러한 표현 방식은 원본 장면에 존재하는 자체 발광 물체 및 내장 광원(ex. 창문에서 들어오는 빛)의 영향을 최소화한다.
Scene Data
저자들은 온라인 저장소 BlenderKit에서 엄선한 고품질 실내외 장면 300개를 수동으로 필터링하여 안개나 비와 같은 과도한 특수 효과가 포함된 장면은 제거했다. 카메라 시점은 유효한 시점을 유지하기 위해 제약 조건이 있는 랜덤 perturbation을 통해 샘플링했다. 조명은 카메라 뒤에 point light를 추가하여 다양한 그림자와 하이라이트 패턴을 구현했다. 일반 렌더링의 일관성을 유지하기 위해 장면별로 Blender 버전을 고정했다.
2. Stage 1: Inverse Neural Rendering
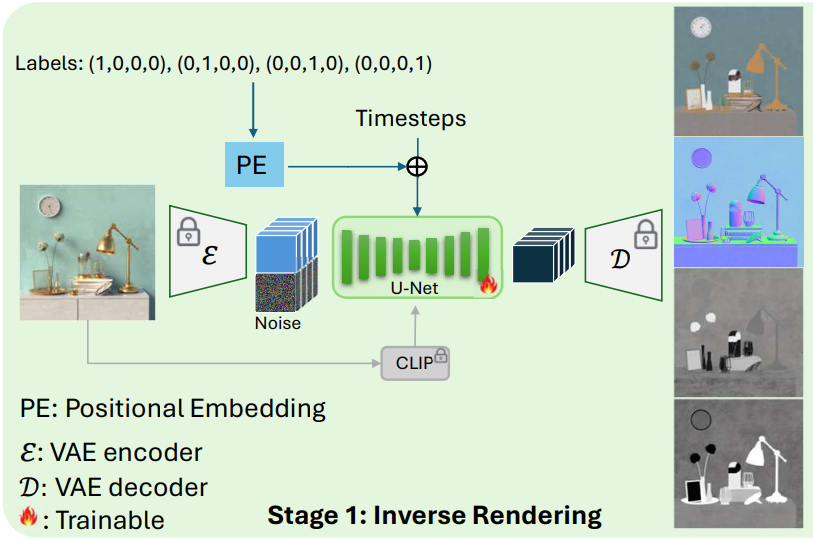
Pipeline
Wonder3D와 GeoWizard에서 영감을 받아, 첫 번째 단계에서는 4개의 batchwise로 concat된 입력 이미지 \(I_\textrm{in} \in \mathbb{R}^{C \times H \times W}\)를 조건으로 하고, albedo $A \in \mathbb{R}^{C \times H \times W}$, normal $N \in \mathbb{R}^{C \times H \times W}$, roughness $R \in \mathbb{R}^{C \times H \times W}$, metallic $M \in \mathbb{R}^{C \times H \times W}$를 동시에 예측한다. 입력 조건들의 CLIP 이미지 임베딩은 cross-attention layer에도 입력된다. 표준 self-attention layer는 global-aware하도록 확장되어 batch 간 통신이 가능하다.
네 개의 batch에 걸친 attention link는 예측된 intrinsic 간의 구조적 일관성을 보장하는 동시에 글로벌 정보 공유를 가능하게 하여 예측 정확도를 향상시킨다. 모델은 네 개의 one-hot 레이블 \(L \in \mathbb{N}_{+}^{1 \times 4}\)을 사용하여 각 batch가 어떤 intrinsic을 출력할지 제어한다.
Training Objective
반투명/투명 object의 albedo, 하늘의 normal, 그리고 Principled BRDF 모델 없이 렌더링된 object의 intrinsic 등 일부 intrinsic은 데이터 수집 과정에서 정확도가 떨어지거나 얻기 어렵다. 이러한 문제를 해결하기 위해 각 데이터셋 샘플과 함께 해당 마스크 $m$을 생성하여 이러한 신뢰할 수 없는 영역을 표시한다.
구체적으로, 임의의 intrinsic의 latent v-prediction 출력 \(v_\textrm{pred} \in \mathbb{R}^{4 \times \frac{H}{8} \times \frac{W}{8}}\)이 주어졌을 때, 마스킹된 latent loss가 v-prediction 공간에 직접 적용된다. 마스크 $m$은 8배로 다운샘플링되어 \(m_z \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8}}\)을 생성하고, 이는 예측된 latent와 GT latent 모두에 element-wise로 곱해진다. Loss는 다음과 같이 정의된다.
\[\begin{equation} L_\textrm{stage1} = \textrm{MSE} (v_\textrm{pred} \cdot m_z, v_\textrm{target} \cdot m_z) \end{equation}\](\(v_\textrm{target}\)은 GT intrinsic latent에 GT noise를 추가하여 얻은 latent code의 v-prediction)
3. Stage 2: Neural Forward Rendering
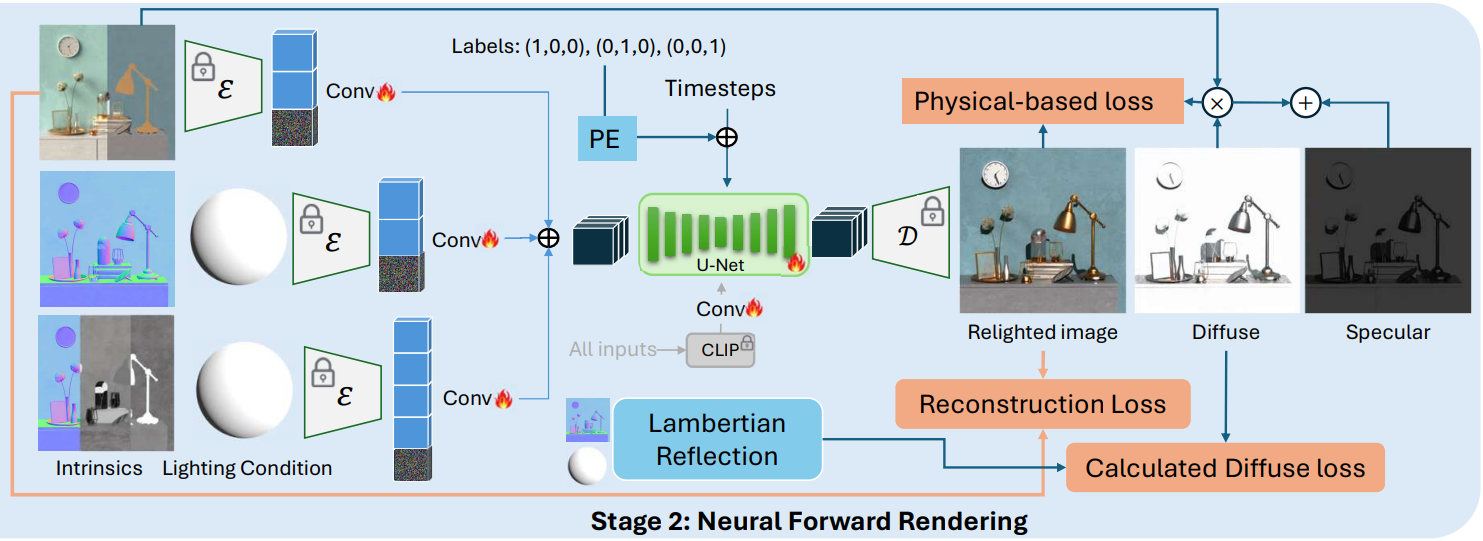
Physics-inspired pipeline
Relighting 파이프라인은 PBR 프레임워크 내에서 다음과 같은 방정식으로 표현되는 표면 반사 모델을 기반으로 설계되었다.
\[\begin{equation} I_\textrm{rendered} = A \odot D + S \end{equation}\](\(I_\textrm{rendered}\)는 렌더링된 이미지, $A$는 albedo map, $D$는 diffuse map, $S$는 specular map)
본 모델은 Principled BRDF를 따른다. Diffuse 성분은 조명 조건과 표면 normal에만 의존하는 Lambertian 반사를 사용하여 모델링된다. 반면, specular 성분은 조명 조건, 표면 normal선, roughness, metallic 속성의 조합에 영향을 받는 Cook-Torrance microfacet model을 따른다.
이러한 의존성을 고려하기 위해, relighting 모델은 다음과 같이 세 가지 batchwise로 concat된 입력 조건을 사용한다.
\[\begin{equation} I_\textrm{in}^\textrm{stage2} = [I_\textrm{in1}, I_\textrm{in2}, I_\textrm{in3}] \\ I_\textrm{in1} = (I_\textrm{in}, A), \quad I_\textrm{in2} = (N, L, m), \quad I_\textrm{in3} = (N, L, M, R, m) \end{equation}\]이러한 각 입력 조건은 각각의 noise map과 concat되어 입력된다. 각 noise map에 대한 출력은 다음과 같다.
\[\begin{equation} I_\textrm{out}^\textrm{stage2} = [I_\textrm{relit}, D_\textrm{pred}, S_\textrm{pred}] \end{equation}\]따라서 각 batch에 대한 입력과 출력은 다음과 같다.
\[\begin{aligned} I_\textrm{in1} &= (I_\textrm{in}, A) \rightarrow I_\textrm{relit} \\ I_\textrm{in2} &= (N, L, m) \rightarrow D_\textrm{pred} \\ I_\textrm{in3} &= (N, L, M, R, m) \rightarrow S_\textrm{pred} \end{aligned}\]이를 통해 모델의 두 번째 batch와 세 번째 batch가 조명과 그림자의 강도 및 구조에 집중하고, 첫 번째 batch는 최종 렌더링 색상에 더 집중하도록 하여 두 번째 batch와 세 번째 batch의 출력이 해당 batch에서 제공된 속성을 더 정확하게 따르도록 한다.
Training Objectives
물리 법칙은 latent space에서 계산될 때 의미를 잃기 때문에, relighting 모델에 사용되는 물리 기반 loss는 전적으로 RGB space에서 적용된다. 즉, VAE 디코더가 출력을 재구성한 후에 계산된다.
Diffuse Shading Loss
경우에 따라 GT diffuse reflectance를 얻기가 어렵고 일부 장면 조명 조건이 부정확할 수 있으므로, normal map과 environment map을 기반으로 수동으로 계산한 loss를 적용한다. 이 loss는 모델이 normal과 조명 조건 간의 관계를 더 잘 포착하도록 도와준다.
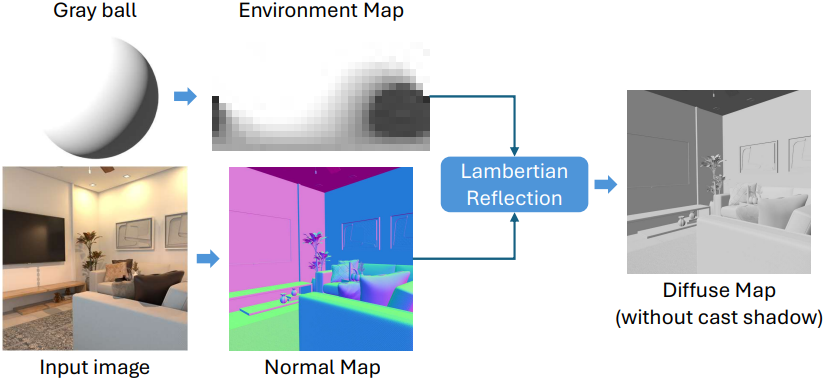
광원을 나타내는 회색 구 $G$를 environment map $E \in \mathbb{R}^{32 \times 16 \times 3}$으로 변환한다. 그런 다음 normal map $N$을 $[-1, 1]$로 정규화한다. 장면에서 렌더링된 회색 구는 이미 조명 표현의 diffuse 버전에 해당하므로, 이를 직접 펼치면 diffuse environment map \(E_\textrm{diff}\)를 얻을 수 있다.
Normal map을 이용한 조회 기반 샘플링을 통해 그림자가 포함되지 않은 diffuse map을 얻는다.
\[\begin{equation} N = [\textbf{n}_x, \textbf{n}_y, \textbf{n}_z]^\top, \quad N \in \mathbb{R}^{3 \times H \times W} \\ D_\textrm{calculated} = \textrm{grid_sample} (E_\textrm{diff}, [\frac{1}{\pi} \textrm{tan}^{-1} (\frac{\textbf{n}_x}{\textbf{n}_y}), \frac{2}{\pi} \textrm{cos}^{-1} (\textbf{n}_y) - 1]) \end{equation}\]마지막으로, 계산된 diffuse map \(D_\textrm{calculated}\)와 latent 예측에서 디코딩된 예측된 diffuse map \(D_\textrm{pred}\) 사이의 diffuse loss를 계산한다.
\[\begin{equation} L_\textrm{DS} = \textrm{MSE} (D_\textrm{calculated}, D_\textrm{pred}) \end{equation}\]Physical-based Shading Loss
주어진 조명 조건에 따라 렌더링된 결과가 shading되고 물리적 원리를 준수하도록 하기 위해, 물리 기반 loss를 다음과 같이 정의한다.
\[\begin{equation} L_\textrm{PS} = \textrm{MSE} (I_\textrm{relit}, A \odot D_\textrm{pred} + S_\textrm{pred}) \end{equation}\]Reconstruction Loss
조명을 변경하기 전후 이미지의 전체적인 내용이 변하지 않도록 하기 위해 reconstruction loss를 도입한다. 이 loss는 DINO feature extractor $\phi$를 사용하여 두 이미지에서 feature를 추출하고 그 차이를 측정함으로써 얻어지는 perceptual loss이다.
\[\begin{equation} L_\textrm{rec} = \| \phi (I_\textrm{relit}) - \phi (I_\textrm{input}) \|_2^2 \end{equation}\]Final loss
학습을 위한 전체 loss는 다음과 같다.
\[\begin{equation} L_\textrm{stage2} = L_\textrm{V-pred} + \frac{1}{t} (\lambda_1 L_\textrm{DS} + \lambda_2 L_\textrm{PS} + \lambda_3 L_\textrm{rec}) \end{equation}\]($t$는 diffusion timestep)
예측된 $z_t$로부터 $z_0$을 직접 추론함으로써 발생하는 오차를 완화하기 위해 $1/t$를 사용한다.
Experiments
- 구현 디테일
- GPU: 40GB A100 8개
- iteration: 8만 / 9만
- batch size: 8
- optimizer: Adam (learning rate = $10^{-5}$)
- U-Net의 가중치는 GeoWizard의 가중치로 초기화
1. Comparisons for Inverse Neural Rendering
다음은 inverse neural rendering에 대한 비교 결과이다.


2. Evaluations of Neural Forward Rendering
다음은 object relighting에 대한 비교 결과이다.


다음은 scene relighting에 대한 비교 결과이다.

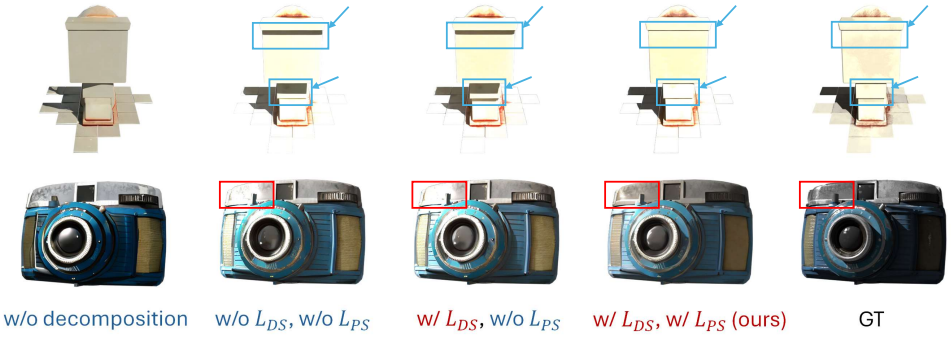
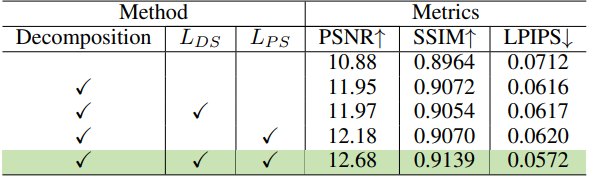
3. Ablation Studies
다음은 ablation study 결과이다.