[논문리뷰] End-to-End Test-Time Training for Long Context
arXiv 2025. [Paper] [Github]
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin, Jed McCaleb, Yejin Choi, Yu Sun
MIT | Adobe Research
29 Dec 2025
Introduction
기존의 Test-Time Training (TTT) 방법들은 학습 시 모델의 초기 loss를 최적화하는 데 초점을 맞추었지만, TTT 후의 loss를 최적화하는 데는 초점을 맞추지 않았다. 저자들은 이러한 불일치를 해결하기 위해, 사전 학습 대신 meta-learning을 통해 TTT에 대비한 모델 initialization을 구현했다. 구체적으로, 각 학습 시퀀스를 테스트 시퀀스처럼 처리하여 inner loop에서 TTT를 수행한다. 그런 다음, 여러 독립적인 학습 시퀀스에 걸쳐 TTT 후의 loss를 평균화하고, outer loop에서 gradient의 gradient를 이용하여 이 평균값을 모델 initialization에 대해 최적화한다.
요약하면, 본 논문의 방법은 두 가지 측면에서 end-to-end 방식이다. Inner loop는 네트워크의 끝단에서 next-token prediction loss를 직접 최적화하며, 이는 기존의 long-context TTT와는 대비된다. 또한, outer loop는 TTT 이후의 최종 loss를 직접 최적화한다.
Method
표준적인 next-token prediction task를 생각해 보자. 이 task는 테스트 시 두 단계로 구성된다.
- Prefill: $T+1$개의 토큰 $x_0, x_1, \ldots, x_T$를 컨디셔닝 ($x_0$는 BOS 토큰)
- Decode: 다음 토큰의 가능한 모든 인스턴스에 대한 분포 \(\hat{p}_{T+1}\)을 예측
Test loss는 cross-entropy loss \(\textrm{CE}(\hat{p}_{T+1}, x_{T+1})\)이다. 설명을 쉽게 하기 위해 먼저 $T+1$개의 토큰을 prefill하고 하나의 토큰을 디코딩하는 task에 초점을 맞추자. 이 경우, 전체 컨텍스트에 대한 self-attention (full attention)은 prefill의 경우 $O(T^2)$의 계산 복잡도를, 디코딩의 경우 $O(T)$의 계산 복잡도를 갖는다. Test-Time Training (TTT)은 prefill의 경우 $O(T)$, 디코딩의 경우 $O(1)$의 계산 복잡도를 갖는다.
1. TTT via Next-Token Prediction
주요 방법론을 설명하기 위해, Transformer 모델에서 모든 self-attention layer를 제거하고 MLP layer만 남긴 아키텍처를 기반으로 하는 toy example을 도입하자. 이 toy example은 이전 토큰에 대한 기억이 없기 때문에 사실상 bigram과 같다. 본 논문의 목표는 다른 시퀀스 모델링 구성 요소의 영향을 배제하고 TTT의 효과를 독립적으로 이해하는 것이다.
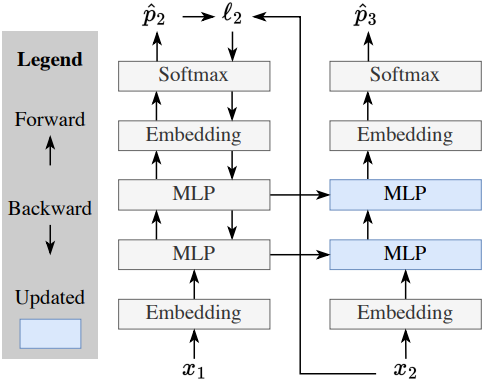
이 아키텍처에 메모리를 부여하는 한 가지 방법은 컨텍스트를 사용하여 학습하는 것이다. 사전 학습과 유사하게, $t = 1, \ldots, T$마다 \(\hat{p}_t\)를 예측하고 이를 $x_t$와 비교하는 연습을 할 수 있다. 구체적으로, 기본 아키텍처를 가중치 $W$를 갖는 $f$로 나타내면, 시간 $t$에서의 next-token prediction loss는 다음과 같이 쓸 수 있다.
모든 $t = 1, \ldots, T$에 대해 gradient descent를 사용하여 순차적으로 테스트 시점에 $W$를 업데이트한다. (update rule)
\[\begin{equation} W_t = W_{t-1} - \eta \nabla \ell_t (W_{t-1}) \end{equation}\]($\eta$는 learning rate, $W_0$는 초기 가중치)
최종적으로 단순히 \(\hat{p}_{T+1} = f(x_T; W_T)\)를 출력한다.
2. Learning to (Learn at Test Time)
이제 동일한 toy example을 통해, 학습 완료 후 TTT 이전의 초기 가중치인 $W_0$가 어떻게 얻어지는지 살펴보자. TTT loss \(\ell_t (W_{t−1})\)는 $x_0, \ldots, x_{t-1}$을 조건으로 $x_t$를 예측하려는 next-token prediction에 대한 test loss이기도 하다. 따라서 시퀀스 $X = (x_1, \ldots, x_T)$에 대한 test loss는 다음과 같다.
\[\begin{equation} \mathcal{L} (W_0; X) = \frac{1}{T} \sum_{t=1}^T \ell_t (W_{t-1}) = \frac{1}{T} \sum_{t=1}^T \textrm{CE} (f(x_{t-1}; W_{t-1}), x_t) \end{equation}\]테스트 시점에 낮은 \(\mathcal{L} (W_0; X)\) 값을 생성하는 $W_0$를 얻기 위한 가장 직접적인 접근 방식은 대규모 학습 시퀀스 세트를 사용하여 학습 시점에 동일한 loss를 평균적으로 최적화하는 것이다. 이러한 접근 방식은 train loss와 test loss가 일치하는 end-to-end 학습의 한 예시이다. TTT가 이러한 방식으로 학습된 $W_0$를 사용할 때, 이를 TTT-E2E라고 부른다.
대조적인 예로, 테스트 시점에 $W_0$이 업데이트된다는 점을 고려하지 않고, 정적인 모델의 train loss를 단순히 모방하는 또 다른 접근 방식을 생각해 보자.
\[\begin{equation} \mathcal{L}_\textrm{naive} (W_0; X) = \frac{1}{T} \sum_{t=1}^T \ell_t (W_0) \end{equation}\]이 접근 방식은 모델의 학습 시점과 테스트 시점의 동작이 일치하지 않기 때문에 end-to-end가 아니다. 결과적으로, \(\mathcal{L}_\textrm{naive}\)를 최소화하는 해가 test loss $\mathcal{L}$ 또한 낮게 유지할 것이라는 보장은 거의 없다. 이러한 접근 방식을 TTT-naive라고 부른다.
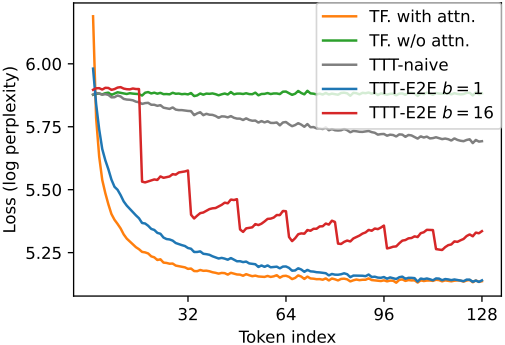
위 그림은 $t = 1, \ldots, 128$에 대해 여러 테스트 시퀀스에 걸쳐 평균화된 token-level test loss \(\ell_t\)를 비교한 것이다. TTT-naive는 toy baseline보다 약간 나은 성능을 보이는 반면, TTT-E2E는 full attention과 거의 비슷한 성능을 보인다. 특히, TTT-E2E는 더 많은 컨텍스트를 효과적으로 활용하여 다음 토큰을 더 잘 예측할 수 있으며, 이는 시간이 지남에 따라 test loss가 감소하는 것으로 나타난다.
Gradient 기반 최적화에서 E2E $\mathcal{L}$에 대한 \(\nabla \mathcal{L}(W_0)\)를 계산하는 것은 gradient의 gradient를 계산하는 것을 의미한다. 다행히 최신 자동 미분 프레임워크는 최소한의 오버헤드로 gradient의 gradient를 효율적으로 계산할 수 있다. $\mathcal{L}$에 대한 gradient step을 outer loop, $\ell$에 대한 gradient step을 inner loop라고 부른다.
현재 TTT-E2E 버전은 긴 컨텍스트를 사용하는 대규모 모델에서 여전히 두 가지 문제를 가지고 있다.
- 효율성 문제: Inner loop에 병렬화할 수 없는 step이 많다.
- 안정성 문제: Inner loop의 각 gradient step이 단 하나의 토큰에만 의존하기 때문에, 우연히 gradient 폭발이 발생하기 쉽다.
3. Mini-Batch TTT and Sliding Window
위의 두 문제는 공통된 원인을 가지고 있다. 바로 update rule이 mini-batch gradient descent 대신 online gradient descent로 실행된다는 점이다. 크기가 $T$인 학습 데이터셋이 주어졌을 때, 일반적으로는 이를 $T/b$개의 batch로 나누고, 각 batch의 크기를 $b$로 설정한 후, 각 batch마다 한 번씩 gradient descent를 적용한다. $b=1$인 online gradient descent와 비교했을 때, $b$ 값을 크게 하면 병렬 처리와 안정성이 모두 향상되는 것으로 알려져 있다. 이러한 mini-batch 방식을 TTT에도 적용하면 동일한 이점을 얻을 수 있다.
$x_1, \ldots, x_T$를 포함하는 TTT 데이터셋이 주어졌을 때, update rule은 다음과 같이 일반화된다.
\[\begin{equation} W_i = W_{i-1} - \eta \frac{1}{b} \sum_{t=(i-1)b+1}^{ib} \nabla \ell_t (W_{i-1}), \quad \textrm{for} \; i = 1, \ldots, T/b \end{equation}\]그런 다음, \(\hat{p}_{T+1} = f(x_T; W_{T/b})\)를 출력한다. 또한, 학습이 TTT의 변화를 반영하도록 하기 위해 $\mathcal{L}$을 다음과 같이 일반화한다.
\[\begin{equation} \mathcal{L}(W_0; X) = \frac{1}{T} \sum_{i=1}^{T/b} \sum_{t=(i-1)b+1}^{ib} \ell_t (W_{i-1}) \end{equation}\]하지만 mini-batch TTT를 사용한 모델은 각 batch 내에서 다시 bigram을 형성한다. 예를 들어, $x_1, \ldots, x_b$를 포함하는 첫 번째 mini-batch를 생각해 보자. 모든 예측 \(\hat{p}_t = f(x_{t-1}; W_0)\)는 $W_{t−1}$ 대신 $W_0$를 사용하여 수행되므로, \(\hat{p}_t\)가 더 많은 컨텍스트(즉, $t−1$까지의 모든 토큰)를 놓치게 되면서 \(\ell_t (W_0)\)가 $t$에 따라 증가한다. 이러한 현상은 모든 mini-batch에서 동일하게 나타나며, 컨텍스트를 놓치지 않는 예측은 mini-batch 내의 첫 번째와 두 번째 예측뿐이다. 이러한 loss 증가는 TTT에 대한 gradient step을 악화시키고, 궁극적으로 성능 저하를 초래한다.
이 문제를 해결하기 위해, 저자들은 sliding window attention layer를 추가하여 아키텍처를 확장했다. 즉, 기존의 self-attention layer 대신 고정된 window 크기 $k$의 sliding window attention을 사용한다. $T = 128K$인 경우, 저자들은 window 크기 $k$를 8K, TTT mini-batch 크기 $b$를 1K로 설정했다. $k \ge b$로 설정하는 것이 중요한데, 이는 모델이 TTT가 가중치를 업데이트하기 전에 각 mini-batch 내의 컨텍스트를 기억할 수 있도록 하기 위함이다.
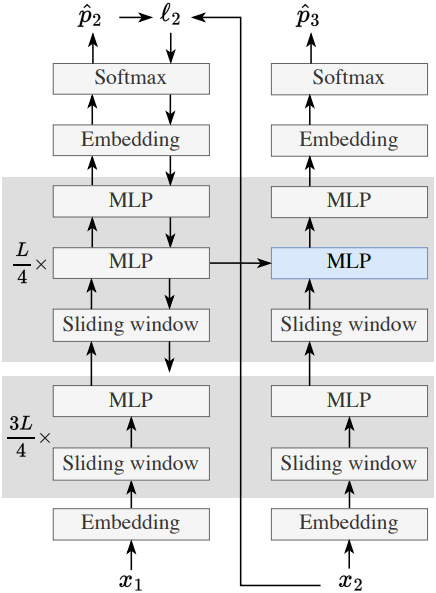
3.1 Implementation Details
TTT only the MLP layers
Transformer 모델은 반복적인 block으로 구성되며, 각 block은 full attention layer (sliding window attention으로 대체됨), MLP layer, 그리고 몇 개의 normalization layer로 이루어져 있다. Inner loop에서 embedding layer, normalization layer, attention layer를 업데이트하면 outer loop에 불안정성을 초래하기 때문에 TTT 동안에는 이 layer들을 고정한다. 따라서 TTT 동안에는 MLP layer만 업데이트된다.
TTT only 1/4 of the blocks
일반적으로 업데이트된 MLP layer가 클수록 압축 과정에서 손실되는 컨텍스트가 줄어든다. 하지만 더 많은 layer를 업데이트한다는 것은 gradient를 backpropagation하는 데 필요한 계산량이 증가한다는 것을 의미한다. 따라서 계산 비용과 컨텍스트 길이에 따른 scalability 사이에는 직관적인 trade-off가 존재한다. 본 논문에서는 실험 결과를 바탕으로 마지막 1/4 block만 TTT 처리하기로 결정했지만, 컨텍스트 길이가 훨씬 더 긴 경우에는 다른 선택이 필요할 수 있다.
Two MLP layers per block
TTT의 문제점 중 하나는 사전 학습 과정에서 얻은 지식을 잊어버리는 것이다. 본 논문에서는 이러한 문제를 해결하기 위해 가장 간단한 방법을 채택했다. TTT 과정에서 업데이트되는 block에 사전 학습된 지식을 안전하게 저장할 수 있는 정적인 MLP layer를 하나 더 추가했다. 저자들은 baseline 모델과의 공정한 비교를 위해 전체 네트워크의 MLP hidden dimension을 축소하여 전체 파라미터 수는 동일하게 유지했다.
3.2 Decoding Multiple Tokens
지금까지는 $T+1$개의 토큰을 prefill한 다음 하나의 토큰만 디코딩하는 것에 초점을 맞췄다. 이제 여러 토큰을 디코딩하는 경우를 고려해보자. 이 경우에는 디코딩된 토큰들이 TTT mini-batch를 완전히 채웠을 때에만 gradient step을 수행하면 된다.
예를 들어, $T$가 $b$로 나누어떨어진다고 가정하면, prefill된 토큰들은 정확히 $T/b$개의 mini-batch로 TTT 과정에서 모두 소모된다. 이후 다음 $b$개의 토큰을 디코딩할 때에는 특별한 처리를 할 필요가 없다. 그 다음에는 이 디코딩된 토큰들로 이루어진 batch에 대해 TTT를 수행하고, 업데이트된 가중치를 사용하여 디코딩을 계속 진행한다.
Experiments
1. Ablations on Hyper-Parameters
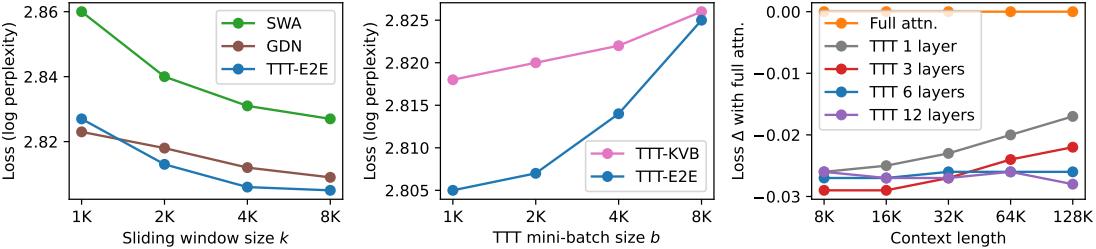
다음은 sliding window 크기 $k$, mini-batch 크기 $b$, 컨텍스트 길이에 대한 ablation 결과이다.
2. Scaling with Training Compute
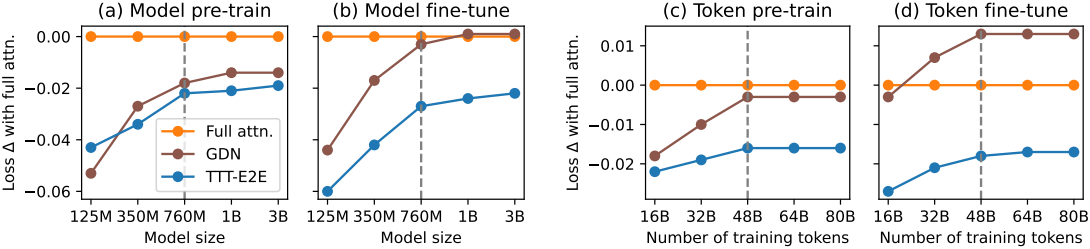
다음은 학습 연산량에 따른 scaling 결과이다.
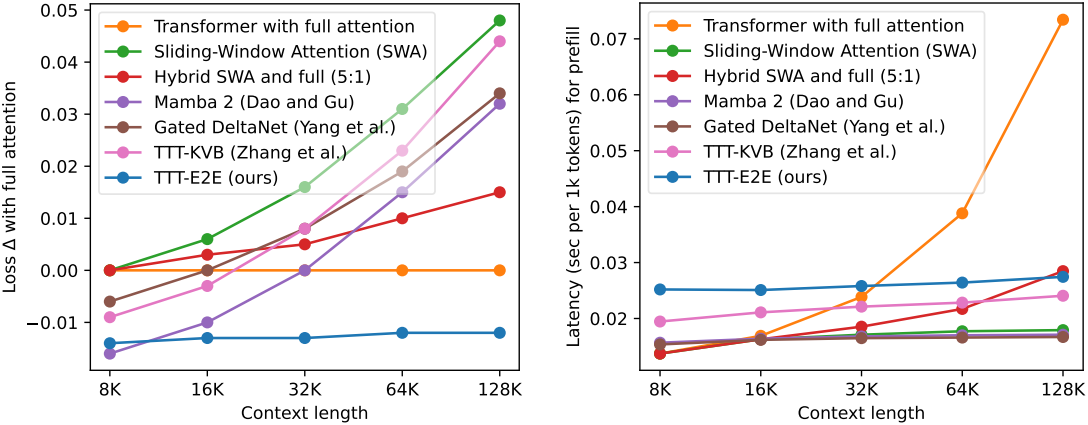
3. Scaling with Context Length
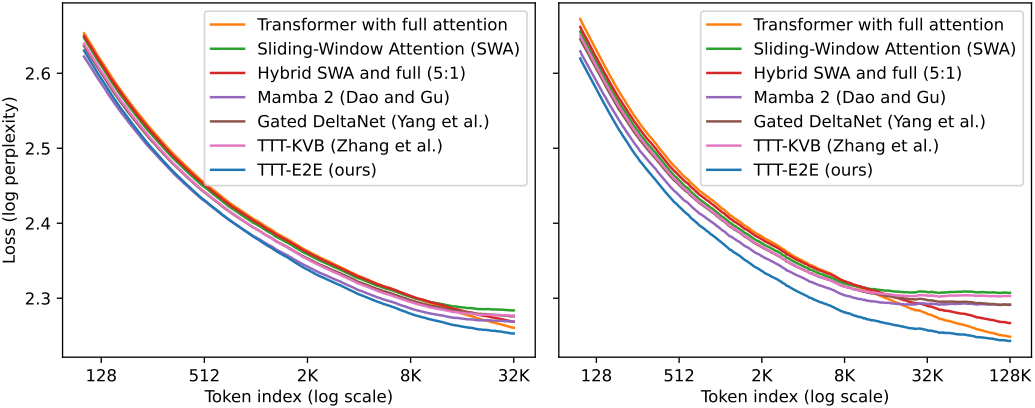
다음은 컨텍스트 길이에 따른 scaling 결과이다.
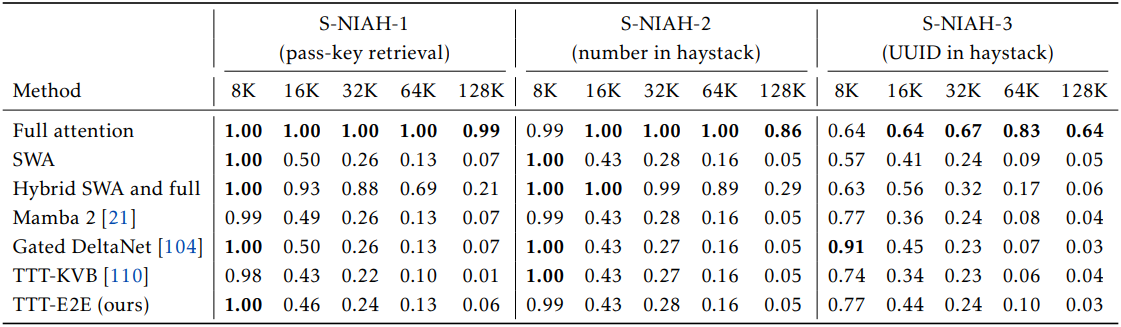
4. Needle in a Haystack
다음은 다양한 컨텍스트 길이에 대한 S-NIAH 성능을 비교한 결과이다.
5. Decoding Long Sequences
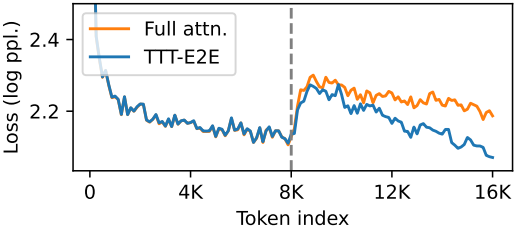
다음은 Books 데이터에서 8K 토큰을 컨텍스트 윈도우에 prefill하고, 그 뒤에 이어지는 8K 토큰을 디코딩한 결과이다.
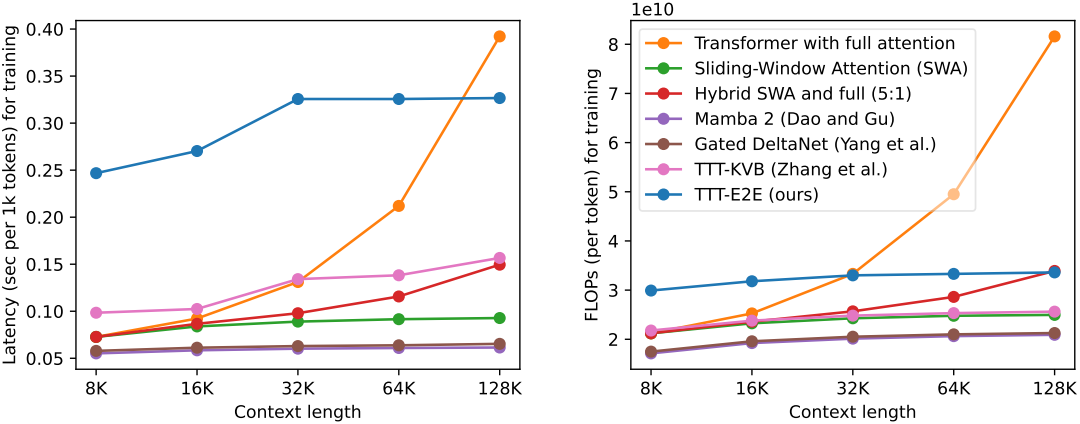
6. Computational Efficiency
다음은 학습 효율성을 비교한 그래프이다. TTT-E2E는 다른 방법들에 비해 학습 효율성이 떨어진다는 한계점이 있다.