[논문리뷰] ReconViaGen: Towards Accurate Multi-view 3D Object Reconstruction via Generation
ICLR 2026. [Paper] [Page] [Github]
Jiahao Chang, Chongjie Ye, Yushuang Wu, Yuantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, Xiaoguang Han
The Chinese University of Hong Kong
27 Oct 2025

Introduction
멀티뷰 이미지로부터 3D diffusion 기반으로 생성하는 TRELLIS는 여전히 글로벌 구조의 부정확성과 로컬 디테일의 불일치 문제를 안고 있다. 이러한 실패의 근본적인 원인은 다음과 같다.
- 멀티뷰 이미지 feature 추출 시 시점 간 상관관계 구축의 불충분성으로 인해 글로벌 및 로컬 수준에서 object geometry 및 텍스처 추정의 정확도가 떨어진다.
- Inference 시에 denoising process의 제어 가능성과 안정성이 부족하여 특히 디테일한 geometry 및 텍스처 추정에서 입력 시점과의 불일치가 쉽게 발생한다.
이러한 문제를 해결하기 위해 본 논문에서는 멀티뷰 prior를 diffusion 기반 object reconstruction 생성 프레임워크에 통합한 ReconViaGen을 제안하였다. 본 방법은 세 단계로 구성된다.
- 사전 학습된 VGGT는 object의 geometry와 텍스처에 대한 멀티뷰 이해를 구축하기 위해 개발되었으며, 이를 하나의 글로벌 토큰 리스트와 여러 개의 로컬 토큰 리스트로 집계하여 각각 글로벌한 geometry와 디테일한 시점별 외형을 나타낸다.
- TRELLIS의 coarse-to-fine 3D generator는 먼저 coarse한 구조를 추정한 다음, 첫 번째 단계에서 얻은 글로벌 및 로컬 토큰을 조건으로 세밀한 텍스처의 메쉬를 생성한다.
- 두 번째 단계에서 생성된 결과를 사용하여 VGGT에서 추정된 포즈를 개선하고, rendering-aware velocity compensation (RVC) 메커니즘을 사용하여 입력 뷰와의 픽셀 단위 정렬을 유도한다. 여기서 입력 이미지와 추정된 카메라 포즈를 결합하여 로컬 latent 표현의 denoising 궤적을 명시적으로 가이드한다.
Method
1. Preliminary
Calibration되지 않은 object의 멀티뷰 이미지 $N$개 \(I = \{I_i\}_{i=1}^N\)가 주어졌을 때, 완전한 3D object $O$를 얻는 것을 목표로 한다. 본 프레임워크는 완전하고 정확한 재구성 결과를 얻기 위해 두 가지 강력한 prior를 활용한다. 하나는 VGGT의 reconstruction prior이고, 다른 하나는 TRELLIS의 generation prior이다.
VGGT의 reconstruction prior
VGGT는 하나 또는 여러 이미지로부터 효율적이고 통합된 3D 장면 재구성을 위해 설계된 feed-forward transformer 아키텍처를 채택하였다. 멀티뷰 이미지 $I$는 먼저 DINO 기반 ViT에 동시에 입력되어 tokenization 및 feature 추출을 통해 \(\phi_\textrm{dino}\)로 변환된다. 그런 다음, 24개의 self-attention layer가 frame-wise self-attention과 global self-attention을 번갈아 사용하는 전략을 통해 \(\phi_\textrm{dino}\)를 3D-aware feature \(\{\phi_i\}_{i=1}^{24}\)로 추가 변환하여 로컬 정보와 글로벌 정보의 균형을 맞추고 멀티뷰 일관성을 향상시킨다. 마지막으로, 4개의 prediction head가 4번째, 11번째, 17번째, 23번째 layer의 출력 \(\phi_\textrm{vgg} (I) = \{\phi_4, \phi_{11}, \phi_{17}, \phi_{24}\}\)을 디코딩하여 카메라 파라미터, depth map, point map, tracking feature 예측값을 생성한다.
저자들은 object reconstruction에 적응하기 위해 object reconstruction을 사용하여 VGGT를 fine-tuning하였다. 사전 학습된 3D prior를 보존하기 위해, 다음과 같은 multi-task objective를 사용하여 VGGT aggregator에 LoRA fine-tuning을 적용하였다.
\[\begin{equation} \mathcal{L}_\textrm{VGGT} (\theta) = \mathcal{L}_\textrm{camera} + \mathcal{L}_\textrm{depth} + \mathcal{L}_\textrm{nmap} \end{equation}\](카메라 포즈 loss + depth loss + point map loss)
TRELLIS의 generation prior
TRELLIS는 sparse한 3D 그리드와 vision foundation model에서 추출한 dense visual feature를 결합한 Structured LATent (SLAT)라는 새로운 표현 방식을 제안하였다. 이 방식은 geometry 정보와 텍스처 정보를 모두 포착하고 다양한 3D 표현으로 디코딩할 수 있도록 한다.
이 방법은 두 단계로 이루어진 coarse-to-fine 파이프라인을 사용한다. 첫 번째 단계에서는 sparse structure (SS), 즉 sparse voxel \(\{p_i\}_i^L\)를 SS Flow를 통해 생성하고, 두 번째 단계에서는 활성 SS voxel에 대한 SLAT \(X = \{(p_i, x_i)\}_i^V\)를 SLAT Flow를 통해 예측한다. 여기서 $p_i$는 voxel 위치, $x_i$는 latent 벡터이다. 두 단계 모두에서 DINO로 인코딩된 이미지 feature를 조건으로 하는 rectified flow transformer를 사용한다. SLAT Flow의 결과는 radiance field, 3DGS 또는 메쉬로 표현되는 3D 출력으로 디코딩된다.
Backward process를 velocity field \(v(x, t) = \nabla_t (x)\)로 모델링하고, transformer \(v_\theta\)는 conditional flow matching (CFM) objective를 최소화하여 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{CFM} (\theta) = \mathbb{E}_{t, x_0, \epsilon} \| v_\theta (x, t) - (\epsilon - x_0) \|_2^2 \end{equation}\]Overview
ReconViaGen 프레임워크는 재구성과 생성을 동시에 수행하며, 두 가지 prior를 상호 보완적으로 활용한다. TRELLIS를 기반으로 구축된 이 프레임워크는 강력한 generation prior를 활용하여 완전한 3D 출력을 생성하고, reconstruction의 한계를 보완하기 위해 보이지 않는 부분까지 그럴듯하게 표현한다.
ReconViaGen은 coarse-to-fine reconstruction 파이프라인을 채택하였다. 첫 번째 단계에서는 사전 학습된 VGGT를 사용하여 글로벌 및 로컬 수준 모두에서 재구성 기반 멀티뷰 조건을 제공한다. 다음 단계에서는 글로벌 geometry와 시점별 로컬 조건을 각각 SS Flow와 SLAT Flow에 입력하여 멀티뷰를 고려한 생성을 수행한다. 마지막으로, 생성된 이미지를 사용하여 VGGT에서 추정된 카메라 포즈를 더욱 정밀하게 다듬고, 픽셀 수준의 정렬 제약 조건을 도입하여 입력 시점과 디테일한 geometry 및 텍스처 측면에서 높은 일관성을 갖는 재구성 결과를 얻는다.
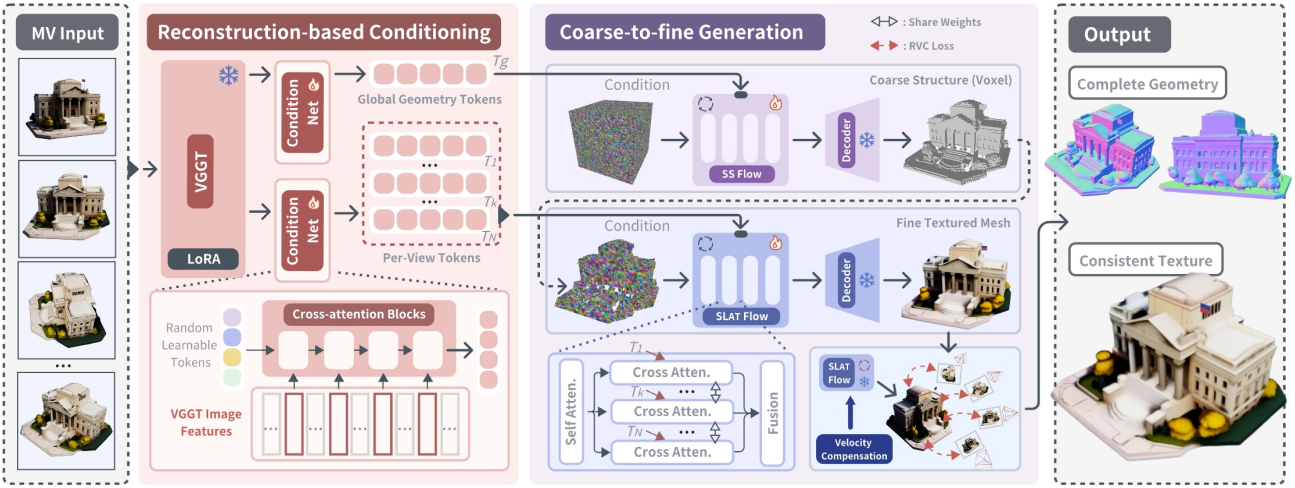
2. Reconstruction-based Conditioning
글로벌한 geometry 조건
먼저 VGGT feature \(\phi_\textrm{vggt}\)를 글로벌 geometry 표현으로 집계하여 SS Flow 조건으로 사용하고, 이를 통해 보다 정확한 coarse 구조를 생성한다. 고정 길이의 토큰 리스트 $T_g$는 Condition Net을 통해 \(\phi_\textrm{vggt}\)로부터 집계된다. 랜덤 초기화된 학습 가능한 토큰 리스트 \(T_\textrm{init}\)에서 시작하여, 4개의 transformer cross-attention block이 \(\phi_\textrm{vggt}\)를 \(T_\textrm{init}\)과 점진적으로 융합하여 $T_g$를 생성한다.
\[\begin{equation} T^{i+1} = \textrm{CrossAttn} \left( Q(T^i), K(\phi_\textrm{vggt}), V(\phi_\textrm{vggt}) \right), \quad i \in \{0, 1, 2, 3\} \end{equation}\](\(T^0 = T_\textrm{init}\), $T^3 = T_g$, $Q(\cdot)$, $K(\cdot)$, $V(\cdot)$는 각각 query, key, value projection을 위한 linear layer)
SS Flow의 학습 단계에서는 VGGT layer를 고정하고 조건 네트워크를 DiT와 함께 학습시킨다.
로컬한 뷰별 조건
하나의 토큰 조건은 geometry 및 텍스처 생성에 필요한 디테일을 제한적으로 제공할 수 있다. 본 논문에서는 geometry 및 텍스처 디테일 모두에 대한 세밀한 생성을 위해 뷰별 로컬 토큰을 SLAT Flow 조건으로 제공하는 Condition Net 설계를 채택했다. 각 뷰에 대해 랜덤 토큰 리스트 $T_k$가 초기화되고 Condition Net에 입력되어 뷰별 토큰 리스트 $T^k$가 생성된다.
\[\begin{equation} T_k^{i+1} = \textrm{CrossAttn} \left( Q(T_k^i), K(\phi_k^\textrm{vggt}), V(\phi_k^\textrm{vggt}) \right), \quad i \in \{0, 1, 2, 3\}, \; k \in \{n\}_{n=1}^N \end{equation}\](\(\phi_k^\textrm{vggt}\)는 $k$번째 뷰의 VGGT feature)
\(\{T_k\}_{k=1}^N\)은 SLAT Flow로 전송되어 디테일한 생성을 위해 뷰별 object 외형에 대한 guidance를 제공한다.
3. Coarse-to-Fine Generation
전체 생성 과정은 세 단계로 구성된다.
- 글로벌한 geometry 조건을 사용한 SS Flow로 coarse한 구조 생성
- 로컬한 뷰별 조건을 사용한 SLAT Flow로 디테일 생성
- 렌더링을 고려한 픽셀 정렬 기반 정밀화 (inference 단계에서만)
Reconstruction-conditioned Flow
Reconstruction prior를 생성에 통합하기 위해 TRELLIS의 SS Flow와 SLAT Flow는 각각 글로벌한 geometry 조건 $T_g$와 로컬한 뷰별 조건 \(\{T_k\}_{k=1}^N\)을 사용하여 coarse diffusion과 fine diffusion을 가이드한다. 첫 번째 단계에서는 각 SS DiT block에서 조건 $T_g$와 noisy SS latent 간의 cross-attention을 계산한다. 두 번째 단계에서는 noisy SLAT과 각 뷰의 조건 $T_k$ 간의 cross-attention을 수행하고 각 SLAT DiT block에서 가중 합을 수행한다.
\[\begin{equation} y_{j+1} = \sum_{k=1}^N \textrm{CrossAttn} \left( Q(y_j^\prime), K (T_k), V(T_k) \right) \cdot w_k, \quad j \in \{m\}_{m=1}^M \end{equation}\]($M$은 SLAT DiT block 개수, $y_j^\prime$은 noisy SLAT $y_j$에 대한 self-attention layer 출력, $w_k \in (0, 1)$는 cross-attention 결과를 입력으로 하는 MLP로 계산된 융합 가중치)
Rendering-aware Velocity Compensation
저자들은 생성 결과와 입력 뷰 간의 픽셀 정렬 일관성을 더욱 높이기 위해, 입력에 따라 diffusion 궤적을 제약하는 rendering-aware velocity compensation (RVC) 기법을 개발했다. 먼저 두 번째 단계의 생성 결과를 사용하여 VGGT로 카메라 포즈를 추정한다. $t < 0.5$일 때, 정제된 카메라 포즈 추정치로부터 SLAT을 $O_t$로 디코딩하고 렌더링을 수행한다. 렌더링된 이미지와 입력 이미지 간의 차이를 다음과 같이 계산한다.
\[\begin{equation} \mathcal{L}_\textrm{RVC} = \mathcal{L}_\textrm{SSIM} + \mathcal{L}_\textrm{LPIPS} + \mathcal{L}_\textrm{DreamSim} \end{equation}\]부정확한 포즈 추정의 영향을 배제하기 위해, 해당 loss가 0.8보다 높은 이미지에 대해서는 해당 loss를 제거한다. \(\mathcal{L}_\textrm{RVC}\)를 최소화함으로써, 각 SLAT denoising step에서 예측된 속도를 다음과 같이 계산된 \(\Delta v_t\)로 반복적으로 보정한다.
\[\begin{equation} \Delta v_t = \frac{\partial \mathcal{L}_\textrm{RVC}}{\partial \hat{x}_0} \frac{\partial \hat{x}_0}{\partial v_t} = -t \frac{\partial \mathcal{L}_\textrm{RVC}}{\partial \hat{x}_0} \\ \textrm{where} \quad \hat{x}_0 = x_t - t \cdot v_t \end{equation}\]다음 step \(x_{t_\textrm{prev}}\)의 noisy SLAT은 다음과 같이 업데이트될 수 있다.
\[\begin{equation} x_{t_\textrm{prev}} = x_t - (t - t_\textrm{prev}) (v + \alpha \cdot \Delta v) \end{equation}\]($\alpha$는 hyperparameter)
이러한 방식으로 입력 이미지는 각 로컬 SLAT 벡터에 대한 denoising 경로를 찾는 데 강력하고 명확한 guidance 역할을 하며, 이는 모든 입력 이미지와 디테일적으로 일치하는 더욱 정확한 3D 결과를 도출한다.
Experiments
1. Results
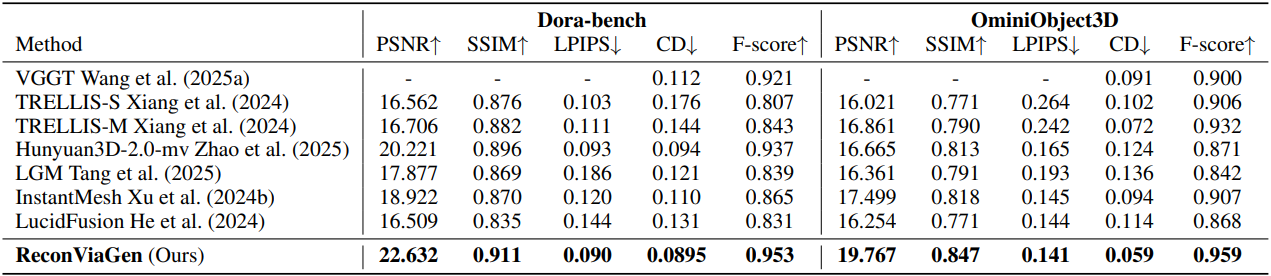
다음은 Dora-bench와 OminiObject3D에 대한 비교 결과이다.

다음은 in-the-wild 샘플들에 대한 비교 결과이다.

2. Ablation Study
다음은 ablation study 결과이다.

