[논문리뷰] End-to-End Autoregressive Image Generation with 1D Semantic Tokenizer
ICML 2026 (Spotlight). [Paper]
Wenda Chu, Bingliang Zhang, Jiaqi Han, Yizhuo Li, Linjie Yang, Yisong Yue, Qiushan Guo
ByteDance Seed | California Institute of Technology | Stanford University
1 May 2026
Introduction
최근 discrete한 비주얼 토큰을 이용한 autoregressive (AR) 이미지 생성에 대한 연구가 활발히 진행되고 있다. 그러나 기존의 대부분의 이미지 생성 모델은 픽셀 패치의 공간적 레이아웃을 유지하는 2D 그리드 구조 tokenizer에 의존한다. 이러한 2D tokenization은 토큰 간에 본질적으로 양방향 의존성을 유발하는데, 이는 AR 모델링에 필요한 단방향 factorization과 근본적으로 맞지 않는다. 본 논문에서는 2D 구조적 의존성을 제거함으로써 보다 직관적인 비주얼 토큰 설계가 가능해진다고 주장한다.
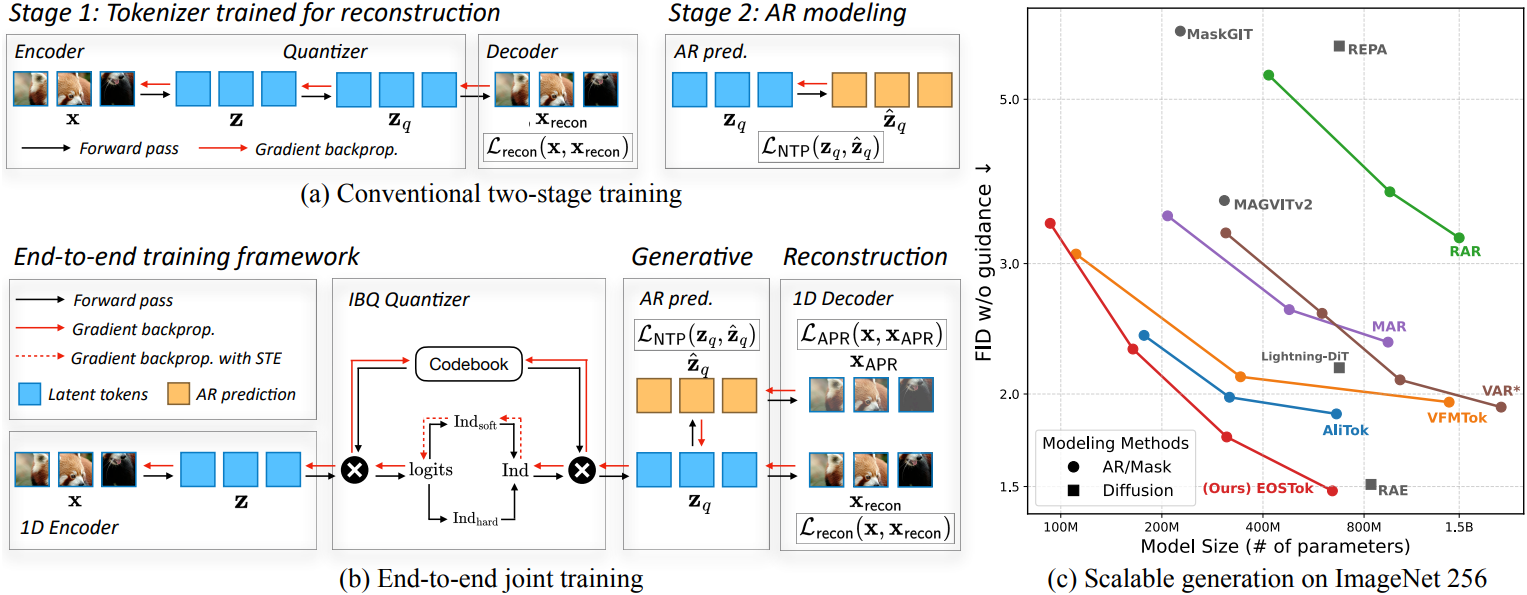
본 논문에서는 이러한 목표를 달성하기 위해 reconstruction과 AR 생성 모델링을 동시에 최적화하는 end-to-end 단일 단계 학습 패러다임을 제안하였다. Reconstruction만을 위해 tokenizer를 학습하는 기존 학습 패러다임과 달리, 본 논문에서는 reconstruction과 생성을 동시에 최적화하여 tokenizer에 직접적인 생성 피드백을 제공할 수 있도록 하였다. 저자들은 개별 토큰에 대한 next-token prediction (NTP) loss로는 픽셀 공간에서의 최종 생성 품질을 판단할 수 없다는 점을 발견했다. 이러한 한계를 극복하기 위해, Autoregressive Prediction Reconstruction (APR) loss를 설계하여 AR 모델의 teacher-forcing 예측을 픽셀 공간으로 디코딩하고 reconstruction loss를 계산하였다.
또한, 2D tokenizer의 latent space를 조절하고 diffusion model을 개선하기 위해 vision foundation model (VFM)을 사용한 기존 연구에서 영감을 받아, 1D tokenizer에 semantic VFM 표현을 효과적으로 주입하는 방법을 연구했다. 그러나 1D sequential latent space를 2D VFM 표현에 직접 정렬하면 raster 순서의 패치 정렬 시퀀스가 되어버려 성능이 저하된다. 따라서, hidden patch embedding을 VFM 표현에 정렬하는 implicit alignment 전략을 제안하였다. 이 전략은 공간 구조를 강제하지 않고 VFM에서 글로벌 semantic 정보를 sequential latent space로 추출하여 생성 품질을 크게 향상시킨다.
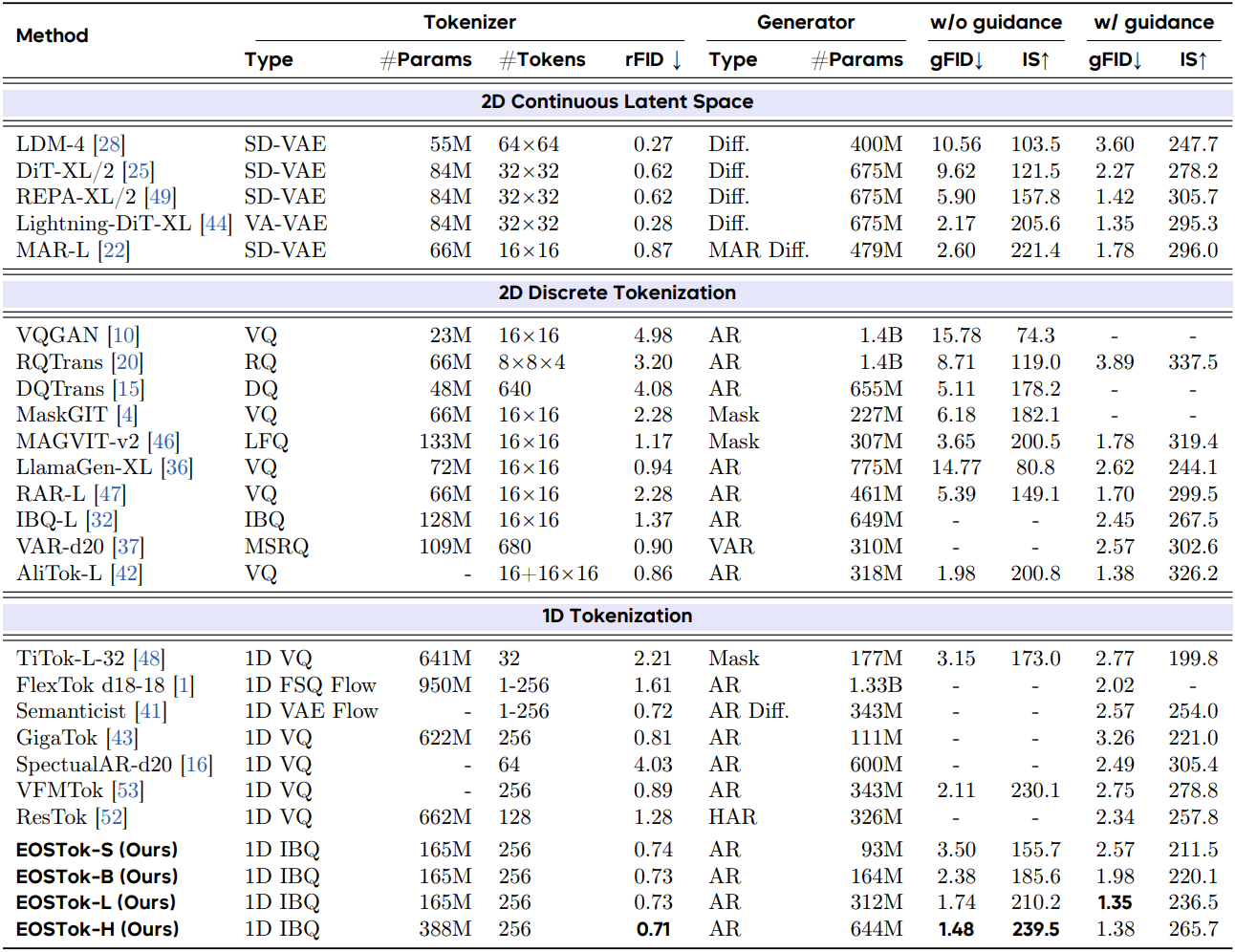
본 논문은 종합적으로 reconstruction, 생성, semantic 정렬을 동시에 최적화하는 end-to-end 1D semantic tokenizer인 EOSTok을 제시하였다. EOSTok-H (644M) 모델은 ImageNet-1K 256$\times$256 생성에서 별도의 guidance 없이도 1.48이라는 SOTA FID 점수를 달성했다.
Method
본 논문의 목표는 이미지를 순차적 latent 표현 $\textbf{z}$로 압축하는 1D vision tokenizer를 개발하는 것이다. 이 tokenizer는 AR 모델링을 용이하게 하여 \(p(\textbf{z}_n \vert \textbf{z}_{<n})\)를 예측한다.
1. 1D Vision Transformer Tokenizer
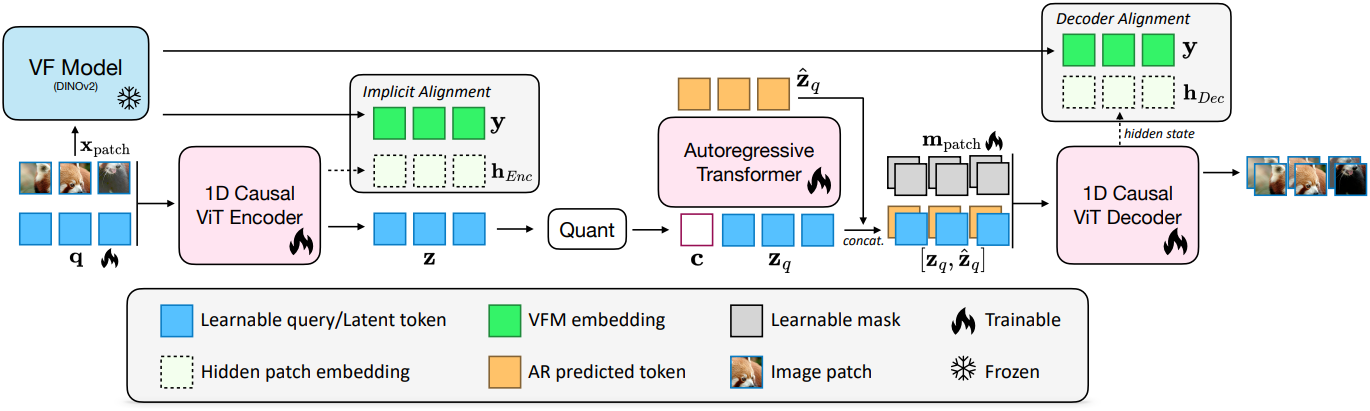
본 논문에서 제시하는 tokenizer는 TiTok과 유사한 구조를 따르는 discrete한 1D sequential latent space를 갖는 ViT 기반 오토인코더이다. 2D 그리드 이미지 패치 \(\textbf{x}_\textrm{patch} \in \mathbb{R}^{N \times D}\)는 flatten되어 $L$개의 학습 가능한 query 토큰 \(\textbf{q} \in \mathbb{R}^{L \times D}\)와 concat된다. 이 시퀀스는 causal ViT 인코더 \(\mathcal{E}_\phi\)에 입력되어 hidden patch embedding \(\textbf{h}_\textrm{Enc}\)와 1D latent 표현 $\textbf{z}$를 생성한다. \(\textbf{h}_\textrm{Enc}\)는 제거되고 $\textbf{z}$만 유지된다. $\textbf{z}$는 IBQ를 이용한 vector quantization을 통해 latent code \(\textbf{z}_q\)로 quantization된다. 대칭적으로, 1D 디코더 \(\mathcal{D}_\psi\)는 \(\textbf{z}_q\)와 마스크 토큰 \(\textbf{m}_\textrm{patch}\)를 입력으로 받아 reconstruction한다.
Quantizer
IBQ quantizer는 codebook $\mathcal{C} \in \mathbb{R}^{K \times D}$를 사용하여 \(\textrm{logits} = [\textbf{z}^\top \mathcal{C}_1, \ldots, \textbf{z}^\top \mathcal{C}_K]\)를 계산한다. Gradient propagation을 가능하게 하기 위해, IBQ는 코드 인덱스를 계산하는 데 있어 straight-through estimation 기법을 사용한다.
\[\begin{equation} \textrm{Ind} = \textrm{onehot}(\textrm{argmax} \textbf{p}) + [\textbf{p} - \textrm{stopgrad}(\textbf{p})] \\ \textrm{where} \quad \textbf{p} = \textrm{softmax}(\textrm{logits}) \end{equation}\]Quantize된 출력 표현은 \(\textbf{z}_q = \textrm{Ind}^\top \mathcal{C}\)이다. 이 1D ViT 아키텍처는 tokenization 과정에서 2D 공간 prior를 명시적으로 제거한다. 이러한 분리를 통해 AR 생성과 본질적으로 호환되는 이미지 tokenizer를 설계할 수 있다.
2. Joint Training of Reconstruction and Generation
인코더 \(\mathcal{E}_\phi\)와 디코더 \(\mathcal{D}_\psi\)를 사용하는 이미지 tokenizer를 학습시키는 task를 생각해 보자. 이 tokenizer는 이미지 $\textbf{x}$에 대해 다음과 같이 최적화된다.
\[\begin{equation} \mathcal{L}_\textrm{VQVAE} (\phi, \psi) = \mathcal{L}_\textrm{recon} (\textbf{x}, \mathcal{D}_\psi (\textbf{z}_q)) + \lambda_\textrm{reg} \mathcal{L}_\textrm{reg} \\ \textrm{where} \quad \textbf{z}_q = \mathcal{Q}(\textbf{z}) = \mathcal{Q}(\mathcal{E}_\phi (\textbf{x})) \end{equation}\](\(\mathcal{L}_\textrm{recon}\)은 L1/L2 loss, perceptual loss, GAN loss의 조합, \(\mathcal{L}_\textrm{reg}\)는 commitment loss, entropy loss 등을 포함한 quantizer를 정규화하는 loss)
기존 방식은 첫 번째 단계에서 reconstruction용 tokenizer를 학습시키고, 두 번째 단계에서 생성 모델을 학습시키는데, 이때 tokenizer의 파라미터는 고정된다. 그러나 저자들은 두 번째 단계에서 tokenizer의 파라미터를 고정하면 생성 task에 더 적합한 표현을 학습할 수 없게 된다고 주장한다. 따라서 본 논문에서는 tokenizer와 생성 모델을 처음부터 동시에 최적화하는 단일 단계 end-to-end 학습 파이프라인을 설계하였다. 전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{E2E}(\phi, \psi, \theta) = \mathcal{L}_\textrm{VQVAE} (\phi, \psi) + \lambda_\textrm{NTP} \mathcal{L}_\textrm{NTP} (\phi, \theta) \end{equation}\]($\phi$, $\psi$, $\theta$는 각각 VAE 인코더 \(\mathcal{E}_\phi\), 디코더 \(\mathcal{D}_\psi\), AR 생성 모델 \(\mathcal{G}_\theta\)의 파라미터, \(\mathcal{L}_\textrm{NTP}\)는 next-token prediction loss)
Gradient propagation
공동 학습 과정에서 AR 모델은 tokenizer에 대해 자연적으로 미분 불가능한 quantization된 토큰을 사용하여 학습된다. 따라서 AR 모델의 임베딩 레이어를 수정하여 확률 \(\textrm{Ind} \in \mathbb{R}^{L \times K}\)를 입력으로 받고, look-up 연산 대신 \(\textbf{h} = \textrm{Ind}^\top \textrm{Embed}\)로 임베딩을 계산하도록 한다. 이를 통해 \(\mathcal{L}_\textrm{NTP}\)에서 VAE 인코더 및 codebook으로의 gradient backward가 가능해진다.
NTP loss와 생성 품질 간의 격차
Tokenizer와 AR 모델을 공동 학습할 때 가장 큰 어려움은 NTP loss가 end-to-end loss가 아니라는 점이다. NTP loss는 학습 중에 끊임없이 변화하는 discrete한 토큰 공간에서 정의되므로 픽셀 공간에서의 최종 생성 품질을 반영할 수 없다.
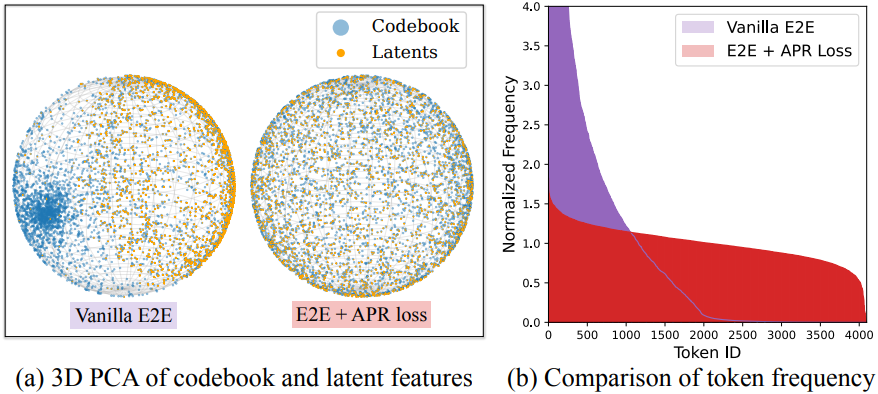
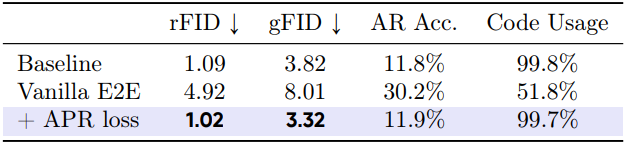
저자들은 이러한 격차를 확인하기 위해 공동 학습 프레임워크를 사용하여 모델을 학습시켰다 (Vanilla E2E). NTP loss로 tokenizer를 학습시키면 AR 예측 정확도가 크게 향상된다. 그러나 NTP loss는 latent space를 매우 적은 토큰만 사용하도록 축소하여 tokenizer의 성능을 저하시키고, 결과적으로 codebook 사용량, rFID, gFID를 급격히 감소시킨다.
NTP와 생성 품질 간의 격차 해소
이 문제를 해결하기 위해, 본 논문에서는 NTP loss와 전반적인 생성 품질 간의 격차를 줄이는 간단하면서도 효과적인 autoregressive prediction reconstruction (APR) loss를 제안하였다. Teacher forcing에서 AR 모델의 예측 토큰을 가져와 디코더를 사용하여 픽셀로 디코딩하고, GT 이미지와 비교한다. Loss function은 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{APR} (\phi, \psi, \theta) = \| \textbf{x} - \mathcal{D}_\psi (\mathcal{G}_\theta (\textbf{z}_q)) \|_2^2 \\ \textrm{where} \quad \textbf{z}_q = \mathcal{Q}(\mathcal{E}_\phi (\textbf{x})) \end{equation}\]\(\mathcal{L}_\textrm{recon}\)과 유사하게, 이 MSE loss는 perceptual loss를 통해 향상될 수 있다. 학습 과정에서 AR 예측 \(\hat{\textbf{z}}_q = \mathcal{G}_\theta (\textbf{z}_q)\)와 \(\textbf{z}_q\)를 batch 차원을 따라 concat하고, 이들을 함께 디코더에 전달한다.
APR loss는 픽셀 공간에서 tokenizer에 직접 end-to-end supervision을 제공하고, NTP loss를 의미 있는 값으로 조정한다. APR loss를 사용한 end-to-end 학습은 NTP loss만 back-propagation할 때 발생하는 잠재적 붕괴 문제를 해결한다.
3. Introduce Semantic Representation to Tokenizers
Diffusion model에서 표현 정렬의 성공에 영감을 받아, 저자들은 visual tokenization 성능 향상을 위해 vision foundation model (VFM) $f$의 semantic feature를 활용하는 아이디어를 탐구하였다. 이를 위해 1D tokenizer의 인코더와 디코더 모두에 표현 $f(\textbf{x})$를 주입하는 여러 변형을 종합적으로 조사하였다.

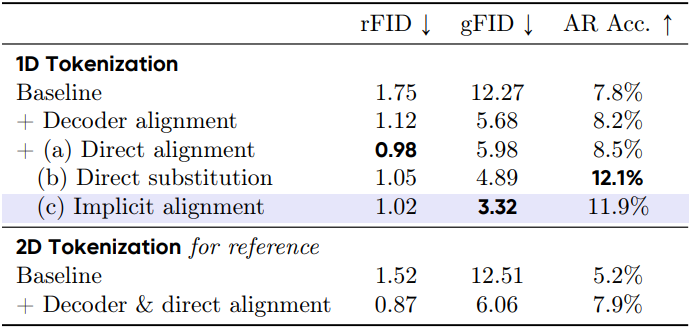
인코더에 semantic 표현 주입
- Direct alignment: Latent 토큰 $\textbf{z}$는 사전 학습된 표현 $\textbf{y} = f(\textbf{x})$에 직접 정렬된다. Loss function은 다음과 같이 정의된다.
($\ell$은 토큰 인덱스, $\mathcal{I}$는 2D feature를 $\mathbb{R}^{N \times D}$에서 $\mathbb{R}^{L \times D}$로 interpolation, $\textrm{sim}$은 코사인 유사도)
이 loss function은 1D latent code $\textbf{z}$가 공간적으로 정렬된 feature $f(\textbf{x})$와 일치하도록 강제하는데, 이는 필연적으로 2D 공간 prior를 1D tokenizer로 유출시킨다.
-
Direct substitution: VFM의 표현을 활용하는 또 다른 방법은 이를 인코더로 직접 사용하는 것이다. 이미지 패치 \(\textbf{x}_\textrm{patch}\)를 projection된 VFM feature \(\textrm{MLP}(f(\textbf{x}))\)로 대체하고, 이를 학습 가능한 query $\textbf{q}$와 concat한 다음 1D ViT 인코더에 전달한다.
-
Implicit alignment: Latent 토큰을 직접 정렬하는 대신, hidden patch embedding \(\textbf{h}_\textrm{Enc}\)를 VFM 표현 $f(\textbf{x})$에 정렬한다. 1D latent code $\textbf{z}$는 VFM 표현과 일치하도록 강제되지 않지만, 정렬된 2D hidden embedding에서 semantic 정보를 추출할 수 있다. Loss function은 다음과 같이 정의된다.
디코더 정렬
인코더에 semantic 표현을 주입하는 것 외에도, 저자들은 디코더를 VFM 표현에 정렬하는 전략을 추가로 검토하였다. 1D ViT 디코더의 reconstruction task는 2D ViT 디코더보다 훨씬 어렵다고 가정할 수 있다. 왜냐하면 latent 토큰 시퀀스와 로컬하게 정렬되는 픽셀이 아니라 글로벌하게 정보가 분포된 픽셀을 복구해야 하기 때문이다. 이는 reconstruction task보다는 조건부 생성 task에 더 가깝다. 따라서 1D ViT 디코더에 표현 정렬을 적용하면 수렴에 도움이 될 수 있다. 저자들은 REPA에서 영감을 받아 디코더의 $k$번째 layer에서 마스크 토큰의 hidden feature \(\textbf{h}_\textrm{Dec}\)를 추출하고 이를 VFM feature $f(\textbf{x})$에 정렬한다.
Semantic 정렬은 AR 생성 품질을 향상시킨다
디코더 정렬을 적용하면 1D tokenizer의 reconstruction 성능이 크게 향상되며, 이는 rFID와 gFID 모두에 반영된다. 그러나 AR 예측 정확도는 미미하게 증가하여 AR 모델링을 더 쉽게 만들지는 못한다. 1D ViT 인코더에 VFM을 활용하는 세 가지 방식 모두 reconstruction 품질을 약간 향상시킨다. 하지만 직접 정렬을 적용하면 생성 품질이 저하되는데, 이는 latent space에 2D 공간 구조를 적용하는 것이 AR 모델링에 해롭다는 가설을 뒷받침한다. 2D 공간 구조를 사용하지 않는 나머지 방법들은 생성 품질을 크게 향상시키며, AR 생성 모델의 예측 정확도도 크게 향상시킨다.
Experiments
1. Generation Results on ImageNet 256$\times$256
다음은 ImageNet 256$\times$256에서의 생성 결과이다.
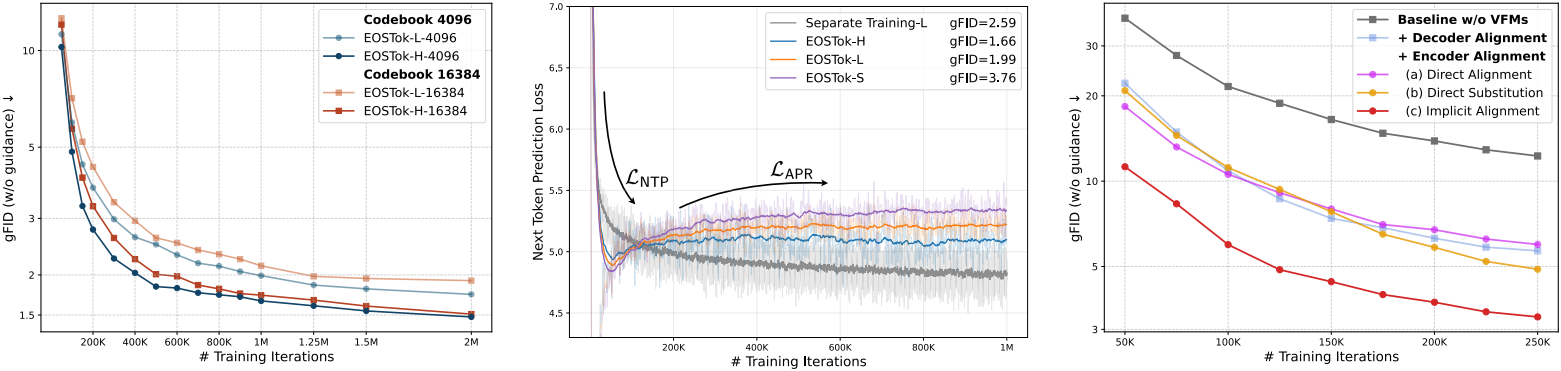
다음은 scaling 결과이다.
2. Impact of End-to-end Training
다음은 학습 시의 토큰 시퀀스 순서에 따른 성능을 비교한 결과이다.

3. Ablation Studies
다음은 시퀀스 길이에 대한 ablation study 결과이다.

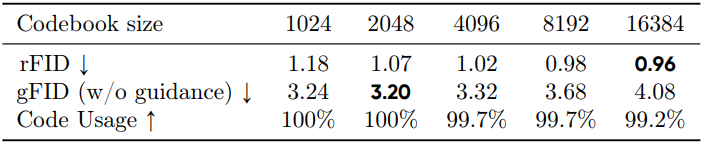
다음은 codebook 크기에 대한 ablation study 결과이다.