[논문리뷰] Diffusion Adversarial Post-Training for One-Step Video Generation
ICML 2025. [Paper] [Page]
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, Lu Jiang
ByteDance Seed
14 Jan 2025

Introduction
본 논문에서는 one-step 이미지 및 동영상 생성에 대한 새로운 접근 방식을 소개한다. 본 논문의 방법은 사전 학습된 diffusion model, 특히 DiT를 초기화에 활용하고, adversarial loss를 사용하여 실제 데이터에 대해 DiT를 지속적으로 학습시킨다. 이러한 방식을 Adversarial Post-Training (APT)이라고 부르는데, 이는 post-training 단계에서 일반적으로 수행되는 supervised fine-tuning (SFT)과 유사하기 때문이다.
기존의 diffusion distillation 방법들이 사전 학습된 diffusion model을 teacher로 사용하는 것과 달리, APT는 사전 학습된 diffusion model을 초기화에만 사용한다. APT는 두 가지 이점을 제공한다.
- Teacher로부터 동영상 샘플을 미리 계산하는 데 드는 상당한 비용을 제거한다.
- Diffusion distillation 방식에서는 화질이 teacher에 의해 본질적으로 제한되는 것과 달리, APT는 사실감 향상, 미세한 디테일 강화 등 일부 평가 기준에서 teacher를 크게 능가하는 능력을 보여준다.
Diffusion model에 대한 직접적인 adversarial training은 매우 불안정하며, 특히 generator와 discriminator 모두 수십억 개의 파라미터를 포함하는 대규모 DiT인 본 논문에서는 학습 안정화를 위한 몇 가지 핵심적인 설계를 도입했다.
- Deterministic distillation을 통해 초기화된 generator를 사용
- Discriminator에 대한 여러 개선 사항 (아키텍처 변경, timestep 전반에 걸친 앙상블, 근사 R1 regularization loss)
저자들은 APT를 활용하여 현재까지 보고된 GAN 중 가장 큰 규모(약 16B)의 모델을 학습시켰으며, 이 모델은 단 한 번의 forward 평가만으로 이미지와 동영상을 모두 생성할 수 있다. 본 모델은 one-step으로 1280$\times$720, 24fps 동영상을 생성하는 데 성공한 최초의 모델이며, H100 GPU 1개에서 2초 분량의 동영상을 생성할 수 있다. 또한, 512$\times$512 또는 640×352 해상도에 최대 12fps 동영상을 4-step으로 생성하던 기존 SOTA 방식을 one-step으로 뛰어넘었다. 병렬화된 8개의 H100 GPU 환경에서는 전체 파이프라인이 실시간으로 실행된다.
Method
본 논문의 목표는 text-to-video diffusion model을 one-step generator로 변환하는 것이다. 이를 위해 GAN 알고리즘을 사용하여 실제 데이터에 대해 diffusion model을 fine-tuning한다.
1. Overview
본 논문에서는 $T$ diffusion step을 통해 이미지와 동영상을 모두 생성할 수 있는 사전 학습된 Seaweed-7B를 기반으로 방법을 구축하였다. 학습은 min-max 게임을 번갈아 사용하는 GAN 최적화 방식을 따른다. Discriminator $D$는 생성된 샘플과 실제 샘플을 분류하여 \(-\mathcal{L}_D\)를 최대화하고, generator $G$는 discriminator를 속이는 샘플을 생성하여 \(\mathcal{L}_G\)를 최소화하는 것을 목표로 한다.
\[\begin{aligned} \mathcal{L}_D &= \mathbb{E}_{\textbf{x}, c \sim \mathcal{T}} \left[ \log \sigma (D (\textbf{x}, c)) \right] + \mathbb{E}_{\textbf{z} \sim \mathcal{N}, c \sim \mathcal{T}} \left[ \log (1 - \sigma (D (G (\textbf{z}, c), c))) \right] \\ \mathcal{L}_G &= \mathbb{E}_{\textbf{z} \sim \mathcal{N}, c \sim \mathcal{T}} \left[ \log \sigma (D (G (\textbf{z}, c), c)) \right] \end{aligned}\]($\mathcal{N}$은 Gaussian 분포, $\mathcal{T}$는 (latent, 텍스트 조건) 쌍으로 구성된 학습 데이터, $\sigma$는 sigmoid)
Latent와 noise 샘플의 크기는 \(\textbf{x}, \textbf{z} \in \mathbb{R}^{t^\prime \times h^\prime \times w^\prime \times c^\prime}\)이며, $t^\prime$, $h^\prime$, $w^\prime$, $c^\prime$은 각각 시간, 높이, 너비, 채널의 차원이다.
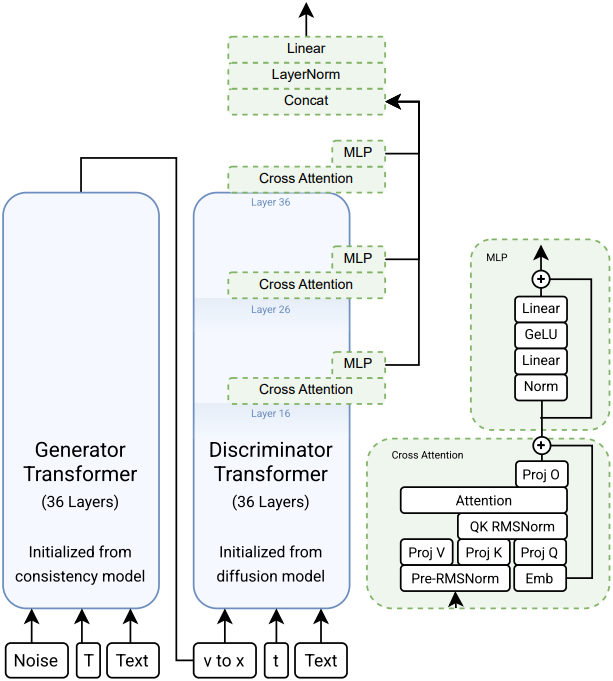
위 그림은 전체 아키텍처이다. Generator와 discriminator backbone 모두 diffusion model 아키텍처를 사용하지만, 초기화 전략은 서로 다르다. 구체적으로, 본 논문의 diffusion model은 MMDiT 아키텍처를 사용하며, 이미지와 동영상이 혼합된 데이터에 대해 latent space에서 flow-matching loss를 사용하여 학습된다. 이 모델은 총 80억 개의 파라미터를 가진 36개의 transformer block layer로 구성된다.
2. Generator
저자들은 diffusion model에 대한 직접적인 adversarial training은 붕괴로 이어진다는 것을 발견했다. 이를 해결하기 위해 먼저 MSE loss를 사용한 consistency distillation을 적용한다. 모델은 7.5의 고정된 classifier-free guidance scale과 고정된 negative prompt를 사용하여 distillation되었다.
Distillation된 모델을 $\hat{G}$라고 하자. Noise 샘플 $\textbf{z}$와 텍스트 조건 $c$가 주어졌을 때, 모델 $\hat{G}$는 velocity field $\hat{\textbf{v}}$를 예측하며, 이는 샘플 예측값 $\hat{\textbf{x}}$로 변환될 수 있다.
\[\begin{aligned} \hat{\textbf{v}} &= \hat{G}(\textbf{z}, c, T) \\ \hat{\textbf{x}} &= \textbf{z} - \hat{\textbf{v}} \end{aligned}\]생성된 샘플 $\hat{\textbf{x}}$는 매우 흐릿하지만, $\hat{G}$는 후속 adversarial training을 위한 효과적인 초기화를 제공한다. 따라서 다음과 같이 정의된 $\hat{G}$의 가중치를 사용하여 generator $G$를 초기화한다.
\[\begin{equation} G(\textbf{z}, c) := \textbf{z} - \hat{G}(\textbf{z}, c, T) \end{equation}\]후속 학습에서는 주로 one-step 생성 능력에 초점을 맞추고 항상 마지막 timestep $T$를 모델에 입력한다.
3. Discriminator
Discriminator는 실제 샘플 $\textbf{x}$와 생성된 샘플 $\hat{\textbf{x}}$를 효과적으로 구분하는 logit을 생성하도록 학습된다. 저자들은 안정적인 학습과 품질 향상을 위해 선택한 몇 가지 효과적인 디자인은 다음과 같다.
첫째, 기존 연구들을 따라 사전 학습된 diffusion model을 사용하여 discriminator backbone을 초기화하고 latent space에서 직접 작동하도록 했다. 따라서 discriminator backbone은 36개의 transformer block layer와 80억 개의 파라미터로 구성된다. 모든 파라미터를 고정하지 않고 학습시키면 성능이 향상된다. 또한, generator에서 사용한 distillation된 모델 가중치 대신 원래 diffusion model 가중치로 초기화하는 것이 더 나은 결과를 가져온다.
둘째, logit을 생성하기 위해 아키텍처를 수정했다. 구체적으로, transformer backbone의 16, 26, 36번째 layer에 새로운 cross-attention-only transformer block을 도입했다. 각 block은 하나의 학습 가능한 토큰을 query, backbone의 모든 비주얼 토큰을 key와 value로 사용하여 cross-attention을 적용하고, 하나의 토큰 출력을 생성한다. 이 토큰들은 채널 concat, 정규화, projection 과정을 거쳐 하나의 스칼라 logit 출력을 생성한다.
셋째, noise가 전혀 섞이지 않은 샘플 $\textbf{x}$, \(\hat{\textbf{x}}\)를 discriminator에 직접 제공한다. 이는 생성된 샘플에 아티팩트가 도입되는 것을 방지한다. 그러나 discriminator backbone은 diffusion model diffusion model에서 초기화되고, $t=0$에서의 확산 사전 학습 목표는 의미가 없기 때문에 discriminator에 $t=0$을 사용하면 붕괴가 발생한다. 따라서 저자들은 서로 다른 timestep 값들의 앙상블을 입력으로 사용하였다. 구체적으로, 기본 discriminator 모델을 $\hat{D}$라고 할 때, $D(\textbf{x}, c)$를 다음과 같이 정의한다.
\[\begin{aligned} D(\textbf{x}, c) &:= \mathbb{E}_{t \sim \textrm{shift}(\mathcal{U}(0,T), s)} [\hat{D}(\textbf{x}, t, c)] \\ \textrm{shift}(t, s) &:= \frac{s \times t}{1 + (s-1) \times t} \end{aligned}\]($s$는 latent 차원에 의해 결정되는 hyperparameter, 이미지의 경우 $s=1$, 동영상의 경우 $s=12$)
효율성을 위해 학습 샘플 $\textbf{x}$당 하나의 $t$를 샘플링하여 $D(\textbf{x}, c)$를 계산한다.
4. Regularized Discriminator
수십억 개의 파라미터로 구성된 discriminator는 붕괴될 위험이 있다. 따라서 안정적인 학습을 보장하는 것이 매우 중요하다. R1 regularization은 adversarial training의 수렴을 촉진하는 효과적인 기법이다. 이는 discriminator의 실제 데이터 $\textbf{x}$에 대한 gradient \(\nabla_\textbf{x}\)에 페널티를 부여하여 학습이 내쉬 균형에서 벗어나지 않도록 한다.
\[\begin{equation} \mathcal{L}_{R1} = \| \nabla_\textbf{x} D (\textbf{x}, c) \|_2^2 \end{equation}\]R1을 이용한 학습은 고차 미분 계산을 필요로 한다. 그러나 PyTorch FSDP, gradient checkpointing, FlashAttention, 기타 융합 연산자는 고차 미분 계산이나 이중 backward를 지원하지 않아 대규모 transformer 모델에서 R1을 사용하는 데 제약이 있다.
저자들은 다음과 같이 표현되는 근사 R1 loss를 제안하였다.
\[\begin{equation} \mathcal{L}_{aR1} = \| D(\textbf{x}, c) - D(\mathcal{N}(\textbf{x}, \sigma \textbf{I}), c) \|_2^2 \end{equation}\]구체적으로, 작은 분산 $\sigma$를 갖는 Gaussian noise로 실제 데이터를 교란한다. 이 loss는 discriminator의 예측값이 실제 데이터와 교란된 데이터 사이에서 서로 가까워지도록 유도하여, 실제 데이터에 대한 discriminator의 기울기를 줄이고 기존의 R1 regularization과 같은 효과를 달성한다.
최종 discriminator loss \(\mathcal{L}_D\)는 다음과 같다.
\[\begin{aligned} \mathcal{L}_D &= \mathbb{E}_{\textbf{x}, c \sim \mathcal{T}} \left[ \log \sigma (D (\textbf{x}, c)) \right] + \mathbb{E}_{\textbf{z} \sim \mathcal{N}, c \sim \mathcal{T}} \left[ \log (1 - \sigma (D (G (\textbf{z}, c), c))) \right] \\ &+ \lambda \mathbb{E}_{\textbf{x}, c \sim \mathcal{T}} \left[ \| D(\textbf{x}, c) - D(\mathcal{N}(\textbf{x}, \sigma \textbf{I}), c) \|_2^2 \right] \end{aligned}\]($\lambda = 100$, 이미지의 경우 $\sigma = 0.01$, 동영상의 경우 $\sigma = 0.1$)
Experiments
- 학습 디테일
- 1단계: 1024$\times$1024 이미지
- H100 GPU 128~256개
- batch size: 9062
- learning rate: $5 \times 10^{-6}$
- EMA decay rate: 0.995
- 2단계: 1280$\times$720, 2초 동영상
- H100 GPU 1024개 (gradient accumulation)
- batch size: 2048
- learning rate: $3 \times 10^{-6}$
- optimizer: RMSProp ($\alpha = 0.9$)
- weight decay, gradient clipping 사용 안 함
- BF16 mixed precision
- 1단계: 1024$\times$1024 이미지
1. Qualitative Evaluation
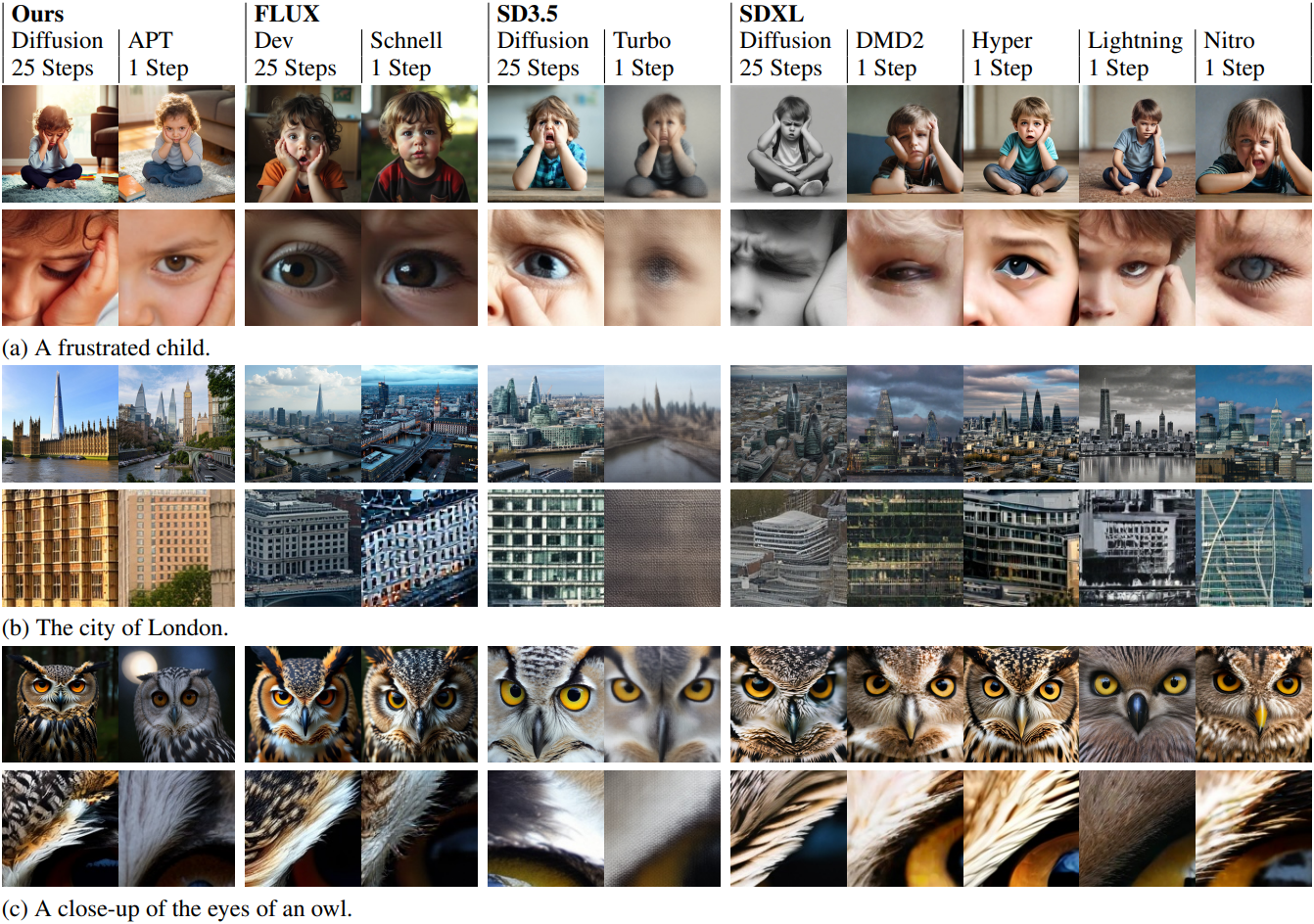
다음은 이미지 생성 결과를 대한 비교한 것이다.
다음은 동영상 생성 결과를 대한 비교한 것이다.

2. User Study
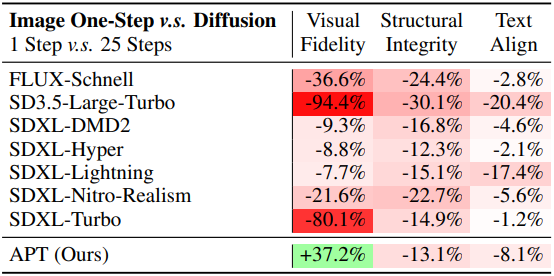
다음은 1-step 이미지 생성 모델들을 원본 25-step 모델과 비교한 결과이다.
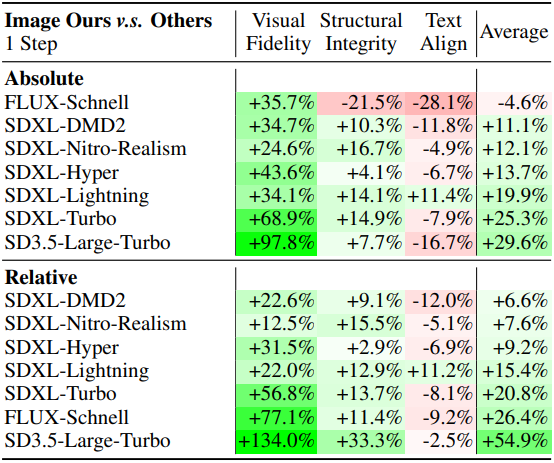
다음은 다른 SOTA 1-step 이미지 생성 모델과의 비교 결과이다.
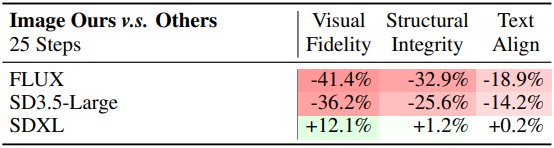
다음은 다른 SOTA 25-step 이미지 생성 모델과의 비교 결과이다.
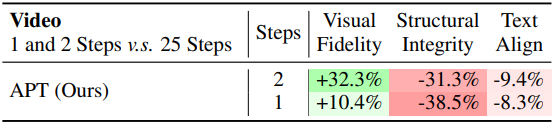
다음은 APT의 동영상 생성 성능을 원본 25-step 모델과 비교한 결과이다.
3. Ablation Study
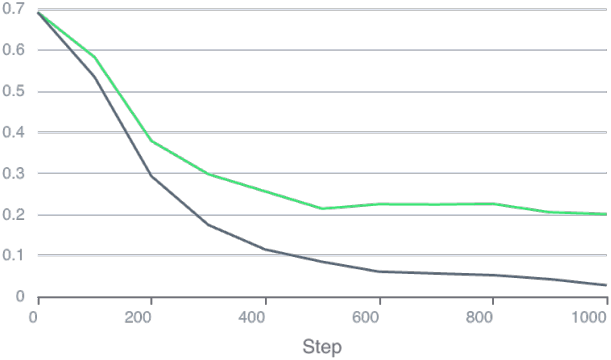
다음은 근사 R1 regularization 유무에 따른 discriminator loss를 나타낸 그래프이다. (검은색) 근사 R1 regularization을 사용하지 않았을 때는 discriminator loss가 0이 되면서 학습이 붕괴하지만, (초록색) 사용했을 때는 붕괴하지 않는다.
다음은 discriminator 디자인에 대한 ablation 결과이다.

