[논문리뷰] Self-Distillation Enables Continual Learning
ICML 2026. [Paper] [Page] [Github]
Idan Shenfeld, Mehul Damani, Jonas Hübotter, Pulkit Agrawal
MIT | Improbable AI Lab | ETH Zurich
27 Jan 2025
Introduction
최근 연구들은 continual learning을 위한 on-policy 학습의 중요성을 강조하고 있다. 모델이 현재 policy에 따라 생성된 데이터를 학습할 때, off-policy 학습에 비해 catastrophic forgetting이 현저히 감소한다. 현재까지 가장 성공적인 on-policy 접근 방식들은 피드백이 명시적인 reward function을 통해 제공되는 RL 분야에서 개발되었다. 그러나 많은 실제 환경에서는 이러한 reward를 사용할 수 없거나 명시하기 어렵다. 대신, 학습은 일반적으로 전문가의 데모 데이터셋을 기반으로 진행된다.
이러한 환경에서 지배적인 패러다임은 supervised fine-tuning (SFT)으로, 고정된 오프라인 데이터 분포 하에서 전문가의 action을 모방하도록 모델을 학습시킨다. SFT는 간단하고 scalable하지만, 본질적으로 off-policy 방식이며, 순차적인 SFT는 모델을 새로운 task나 도메인에 적용할 때 일반화 성능 저하와 심각한 catastrophic forgetting으로 이어질 수 있다. 데모 데이터셋만 사용할 수 있는 상황에서 어떻게 on-policy 학습의 이점을 얻을 수 있을까?
원칙적으로 off-policy 학습의 어려움은 데모를 통해 reward function을 먼저 학습한 다음 (inverse RL), on-policy RL을 수행함으로써 극복할 수 있다. Inverse RL은 reward를 효과적으로 복구하려면 일반적으로 reward 구조에 대한 강력한 prior가 필요하므로, RLHF와 같이 그러한 가정이 타당한 환경으로 실제 적용이 제한되어 왔다.
명시적인 reward function을 추론하는 대신, 본 논문에서는 데모로부터 직접 학습하는 on-policy distillation 프레임워크인 Self-Distillation Fine-Tuning (SDFT)을 제안하였다. SDFT는 대규모 사전 학습 모델이 강력한 in-context learning, 즉 파라미터 업데이트 없이 예제에 따라 동작을 조정하는 능력을 보인다는 관찰에 기반한다. 구체적으로, 동일한 모델을 두 가지 역할로 활용한다. 하나는 task 입력과 전문가 데모 모두에 기반한 teacher 모델이고, 다른 하나는 task 입력에만 기반한 student 모델이다. 학습 과정에서 teacher 모델의 예측은 student 모델이 생성한 궤적을 따라 distillation되어, 명시적인 reward 추론이나 오프라인 모방 없이 데모 정보를 통합하는 on-policy 업데이트를 생성한다.
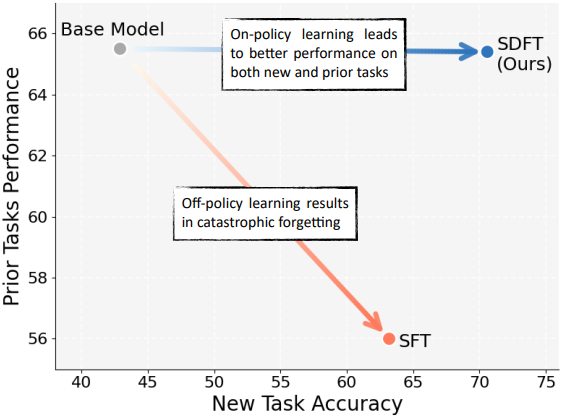
Continual learning 환경에서 SDFT는 안정적인 on-policy 업데이트를 제공하여 학습을 가능하게 하는 동시에 SFT에 비해 catastrophic forgetting을 크게 줄인다. 또한, SDFT는 in-distribution과 out-of-distribution 모두에서 일반화 성능을 향상시켜 이전 능력을 유지하는 것이 주요 목표가 아닌 환경에서도 유용하다. 세 가지 서로 다른 기술을 학습하는 순차적 학습 실험에서 SDFT는 하나의 모델이 각 기술을 순차적으로 습득하는 동시에 이전에 학습한 기술뿐만 아니라 관련 없는 기존 능력에 대한 성능도 유지하였다.
Method
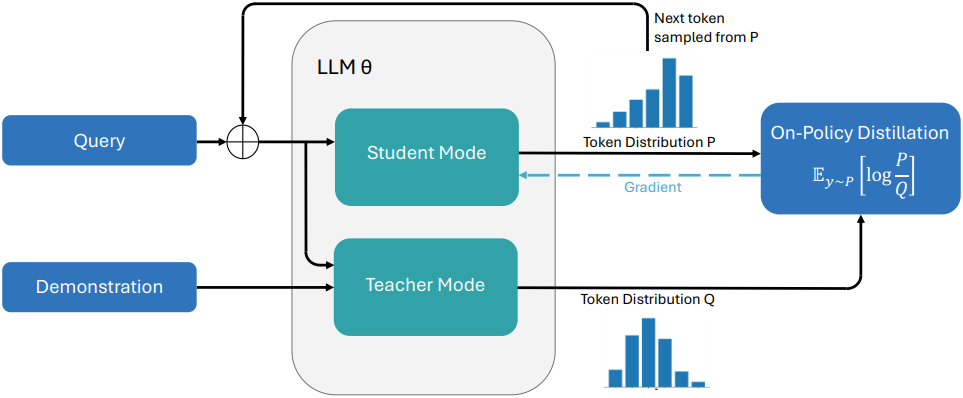
본 논문에서는 student-teacher distillation 프레임워크를 기반으로 한다. 이 프레임워크에서는 student 모델이 teacher 모델의 동작과 일치하도록 학습되며, 두 모델의 출력 분포 간의 차이를 최소화한다. 전통적인 distillation 방식은 일반적으로 더 크고 성능이 뛰어난 teacher 모델과 더 작은 student 모델을 각각 사용한다.
본 논문의 핵심은 in-context learning 능력을 활용하여 동일한 모델을 teacher와 student 모두로 사용할 수 있다는 점이다. 구체적으로, policy $\pi$를 가진 foundation model이 주어졌을 때, 전문가 데모 $c$를 조건으로 하는 teacher 모델 \(\pi(\cdot \vert x, c)\)를 구성한다 ($x$는 task 프롬프트). Student 모델은 이러한 컨디셔닝이 적용되지 않은 base model \(\pi_\theta (\cdot \vert x)\)이다.
주어진 프롬프트 $x$에 대한 teacher 모델을 구축하기 위해, 저자들은 다음과 같은 간단한 프롬프트를 사용하여 프롬프트와 데모를 모두 기반으로 모델을 컨디셔닝하였다.
<Question>
This is an example for a response to the question:
<Demonstration>
Now answer with a response of your own, including the thinking process:
이러한 프롬프트를 사용하면 policy가 c를 그대로 출력하는 것을 방지하고, 대신 모델이 in-context learning 능력을 활용하여 데모의 의도를 이해한 것을 반영하는 응답을 유도할 수 있다.
저자들은 continual learning을 위해서는 on-policy 학습이 필수적이라고 가정하였다. 따라서 teacher로부터 on-policy distillation을 사용하여 student을 학습시킨다. 모든 프롬프트 $x$에 대해, SDFT는 student policy \(y \sim \pi_\theta (\cdot \vert x)\)에서 응답을 샘플링하고 student 분포와 teacher 분포 간의 reverse Kullback-Leibler (KL) divergence를 최소화한다.
\[\begin{equation} \mathcal{L}(\theta) = D_\textrm{KL} (\pi_\theta (\cdot \vert x) \; \| \; \pi (\cdot \vert x, c)) = \mathbb{E}_{y \sim \pi_\theta (y \vert x)} \left[ \log \frac{\pi_\theta (y \vert x)}{\pi (y \vert x, c)} \right] \end{equation}\]모델의 autoregressive한 특성을 활용하면, 이 objective를 token-level loss의 합으로 분해할 수 있다. 이때 teacher 분포를 고정된 것으로 간주하고 student 파라미터 $\theta$에 대해 gradient를 계산하면, 다음과 같은 gradient 추정량을 얻을 수 있다.
\[\begin{equation} \nabla_\theta \mathcal{L} (\theta) = \mathbb{E}_{y \sim \pi_\theta} \left[ \sum_t \sum_{y_t \in \mathcal{V}} \log \frac{\pi_\theta (y_t \vert y_{<t}, x)}{\pi (y_t \vert y_{<t}, x, c)} \nabla_\theta \log \pi_\theta (y_t \vert y_{<t}, x) \right] \end{equation}\]($\mathcal{V}$는 토큰 vocabulary)
Teacher는 항상 데모 $c$로 컨디셔닝되지만, teacher의 파라미터는 여러 가지 방식으로 정의할 수 있다. 달리 언급되지 않는 한 student 파라미터의 exponential moving average (EMA)를 teacher의 파라미터로 사용한다.
1. Self-Distillation as Inverse RL
본 논문에서는 student-teacher distillation 관점에서 알고리즘을 제시하였지만, inverse RL 프레임워크에서도 해석될 수 있으며, 이 경우 implicit reward function을 최대화한다. 본 논문에서 제시하는 self-distillation objective는 전문가 데모와 모델의 in-context learning 능력에 의해 정의된 implicit reward function을 최대화하는 것과 수학적으로 동등하다.
TRPO에서는 step $k+1$에서의 policy 업데이트가 현재 policy \(\pi_k\)에 가깝게 유지되도록 제약된다.
\[\begin{equation} \pi_{k+1} = \max_\pi \mathbb{E}_{y \sim \pi} [r (y, x)] - \beta D_\textrm{KL} (\pi (\cdot \vert x) \| \pi_k (\cdot \vert x)) \end{equation}\]이 objective에 대해, optimal policy \(\pi_{k+1}^\ast\)은 다음과 같은 알려진 closed-form 표현식을 취한다.
\[\begin{equation} \pi_{k+1}^\ast (y \vert x) \propto \pi_k (y \vert x) \exp (\frac{1}{\beta} r(y,x)) \end{equation}\]이 방정식을 재배열하면 optimal policy와 이전 policy 간의 차이에 대한 함수로 reward를 표현할 수 있다.
\[\begin{equation} r(y,x) = \beta [\log \pi_{k+1}^\ast (y \vert x) - \log \pi_k (y \vert x)] + C \end{equation}\]일반적인 inverse RL 환경에서 \(\pi_{k+1}^\ast\)은 알 수 없다. 그러나 저자들의 핵심 아이디어는 모델 자체의 in-context learning 능력이 이 최적 policy에 대한 강력한 근사치를 제공한다는 것이다. 저자들은 in-context 가정을 도입하였다. 즉, 데모 $c$가 주어졌을 때, $c$로 컨디셔닝된 모델은 다음 optimal policy를 근사한다.
\[\begin{equation} \pi_{k+1}^\ast (y \vert x) \approx \pi (y \vert x, c) \end{equation}\]이는 데모를 관찰함으로써 유도된 행동 변화가 전문가의 진정한 의도를 반영한다고 가정한다. 위 식을 대입하면 reward function을 도출할 수 있다.
\[\begin{equation} r(y, x, c) = \log \pi (y \vert x, c) - \log \pi_k (y \vert x) \end{equation}\]이는 궤적 수준의 reward를 정의하지만, 모델은 autoregressive한 구조를 가지고 있다. 따라서 reward를 토큰 수준의 reward $r_t$로 분해한다.
\[\begin{equation} r_t (y_t \, \vert \, y_{<t}, x, c) = \log \frac{\pi (y_t \, \vert \, y_{<t}, x, c)}{\pi_k (y_t \, \vert \, y_{<t}, x)} \\ r(y, x, c) = \sum_t r_t (y_t \, \vert \, y_{<t}, x, c) \end{equation}\]현재 policy \(\pi_k\)에서의 policy gradient는 다음과 같다.
\[\begin{aligned} \nabla_\theta J(\pi_k) &= \mathbb{E}_{y \sim \pi_k} [r(y, x, c) \nabla_\theta \log \pi_k (y \vert x)] \\ &= \mathbb{E}_{y \sim \pi_k} \left[ \log \frac{\pi (y \vert x, c)}{\pi_k (y \vert x)} \nabla_\theta \log \pi_k (y \vert x) \right] \end{aligned}\]Policy gradient는 reverse KL divergence의 gradient와 기대값 측면에서 동일하다. 따라서, SDFT는 student의 현재 행동을 데모를 인지한 행동과 비교하여 추론된 reward를 최대화하는 on-policy RL 알고리즘으로 볼 수 있다.
2. Validating the ICL Assumption
SDFT의 핵심 가설은 전문가 데모에 기반한 모델이 해당 task에 대한 optimal policy처럼 동작하기 때문에 좋은 teacher가 될 수 있다는 가정으로 볼 수 있다. 이 근사치의 품질은 다음 두 가지 조건에 따라 달라진다.
- Optimality: Teacher의 reward 기대값은 알려지지 않은 optimal policy의 reward 기대값과 일치해야 한다. 즉, 데모를 조건으로 policy에서 추출한 샘플은 해당 task에서 거의 최대의 reward를 얻어야 한다.
- Minimal Deviation: Optimal policy \(\pi_{k+1}^\ast (y \vert x)\)는 reward를 최대화하는 모든 policy 중에서 현재 모델에 가장 가까운 policy이다. 즉, optimal reward를 달성하는 모든 policy 중에서 teacher는 KL 관점에서 \(\pi_k\)에 가까워야 한다.
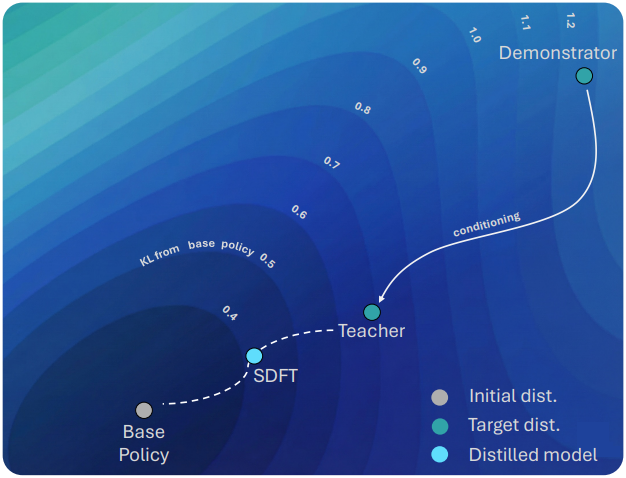
두 번째 요구 사항, 즉 현재 policy에 충실한 유지는 실제 실행 가능성을 위해 매우 중요하다. 데모를 통해 학습된 teacher 모델이 단순히 예시를 그대로 모방한다면, base model에서 크게 벗어나 on-policy 학습의 이점을 잃게 될 것이다. Teacher 모델이 가치 있는 이유는 base model에 기반을 두면서도 새롭고 task에 적합한 동작을 생성하기 때문이다. 또한, 학습된 분포와 유사한 분포는 catastrophic forgetting이 훨씬 적고 일반적인 능력을 더 잘 보존한다.
경험적 검증
이론적으로는 이러한 조건들을 검증할 수 없지만, 저자들은 각 조건을 경험적으로 평가했다. 기본 policy로는 Qwen-2.5-7B-Instruct 모델을, 데이터셋으로는 ToolAlpaca를 사용했다. 이 벤치마크에서 모델은 tool-API specification과 사용자 요청을 받아 올바른 도구 호출을 식별해야 한다.
Optimality. 데모가 없을 경우, base model은 예제의 42%만 해결한다. 하지만 적절한 데모가 제공되면, teacher는 100% 성공률을 달성한다. Reward 근접성을 추가로 검증하기 위해, 저자들은 teacher의 추론 과정 50개를 수동으로 검토했다. 모든 경우에서 최종 도구 호출이 정확했을 뿐만 아니라, 중간 사고 과정 또한 타당했다. 이는 teacher가 전문가의 출력을 단순히 복사하는 것이 아니라 올바른 추론 과정을 재구성하고 있음을 시사한다.
Minimal Deviation. 저자들은 base policy와의 KL divergence \(D_\textrm{KL} (\pi \vert \vert \pi_0)\)을 학습 중 policy \(\pi_k\)와의 거리로 측정했다. 데모 데이터로 학습된 SFT 모델과 데모 데이터로 컨디셔닝된 teacher 모델 모두에 대해 이 KL divergence 값을 비교했다. 아래 그림에서 볼 수 있듯이, SFT 모델은 base model에서 상당히 벗어나는 반면, teacher 모델은 훨씬 더 근접한 위치를 유지하며 KL divergence 값이 거의 절반 수준이다. 이는 teacher 모델이 base policy와 근접하게 유지하면서 고품질 출력을 생성한다는 것을 입증한다.
Experiments
1. On-policy learning leads to better generalization
다음은 새로운 세 가지 도메인에 대한 기술을 학습시키는 continual learning에 대한 결과이다.
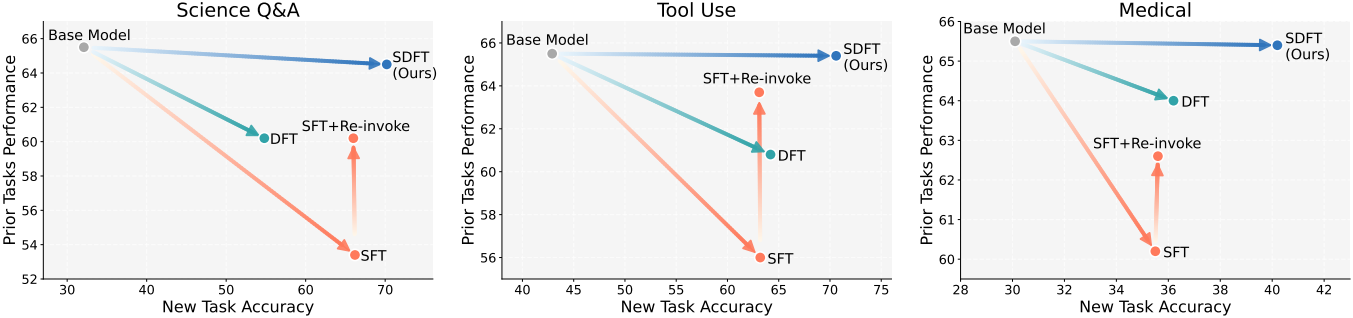
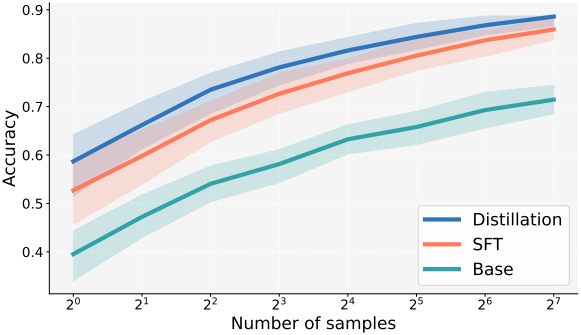
다음은 사전 학습 데이터에 없는 새로운 사실적 내용을 통합하는 continual learning에 대한 결과이다.
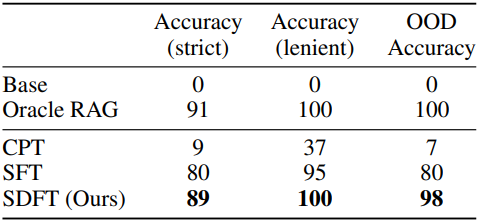
2. Learning without forgetting
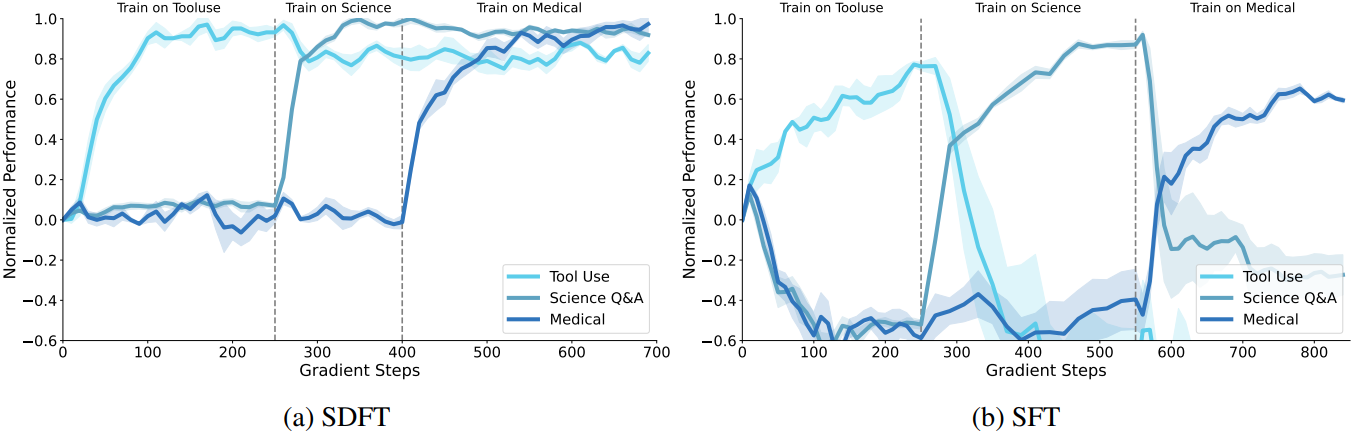
다음은 세 가지 기술을 순차적으로 학습 시켰을 때의 결과이다.
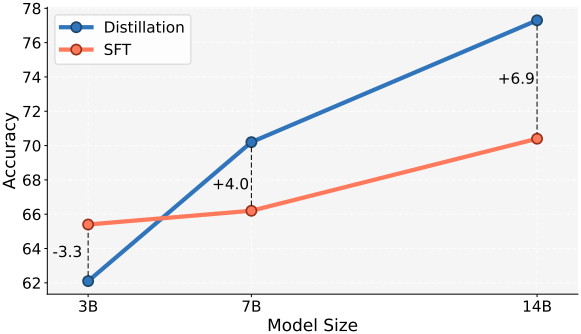
3. Effect of model size
다음은 모델 크기에 따른 성능을 비교한 결과이다.
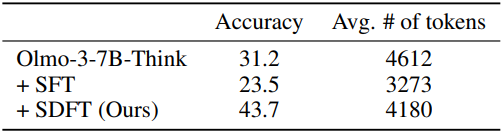
4. Training reasoning models without reasoning data
다음은 추론 모델을 추론 과정 없이 답만 사용하여 fine-tuning 하였을 때의 결과이다.
5. What drives the improvement in performance?
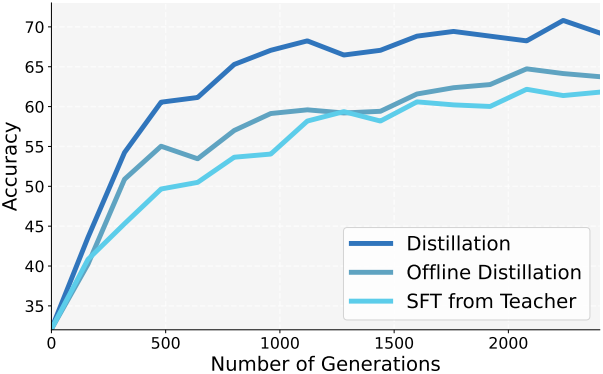
다음은 offline distillation과의 비교 결과이다.