[논문리뷰] Memory Caching: RNNs with Growing Memory
ICML 2026. [Paper]
Ali Behrouz, Zeman Li, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, Vahab Mirrokni
Google Research | Cornell University | USC
27 Feb 2026
Introduction
RNN은 입력 시퀀스를 압축하기 위해 고정 크기의 메모리를 유지한다. 시퀀스가 길어짐에 따라 메모리 오버플로가 발생하고 성능이 저하된다. 반대로 attention은 과거의 모든 토큰을 캐싱하므로 메모리는 증가하지만 계산 비용은 제곱에 비례한다.
본 논문에서는 RNN 모델의 유효 메모리가 시퀀스 길이에 따라 증가할 수 있도록 하는 일반적인 기법인 Memory Caching (MC)을 소개한다. MC는 메모리 state의 체크포인트를 캐싱함으로써 구현된다. MC는 표준 RNN과 attention 메커니즘 사이의 유연한 중간 지점을 제공하며, \(\mathcal{O}(NL)\)의 제어 가능한 복잡도를 갖는다. 이를 통해 RNN의 $\mathcal{O}(L)$ 복잡도와 Transformer의 $\mathcal{O}(L^2)$ 복잡도 사이에서 유연한 interpolation이 가능하다.
Method
토큰 시퀀스 \(x \in \mathbb{R}^{L \times d_\textrm{in}}\)가 주어졌을 때, 시퀀스를 크기가 \(L^{(1)}, \ldots, L^{(N)}\)인 세그먼트 \(S^{(1)}, \ldots, S^{(N)}\)으로 분할하고 메모리 \(\mathcal{M}^{(1)}, \ldots, \mathcal{M}^{(N)}\)을 사용하여 각 세그먼트를 압축한다. $s$번째 세그먼트에 해당하는 메모리 업데이트 규칙은 다음과 같다.
\[\begin{equation} \textbf{k}_t = x_t W_k, \quad \textbf{v}_t = x_t W_v, \quad \textbf{q}_t = x_t W_q \\ \mathcal{M}_t^{(s)} = f \left( \mathcal{M}_{t-1}^{(s)}; \textbf{k}_t, \textbf{v}_t \right), \quad \textrm{where} \; 1 \le t \; L^{(s)} \end{equation}\]($f(\cdot)$는 update rule)
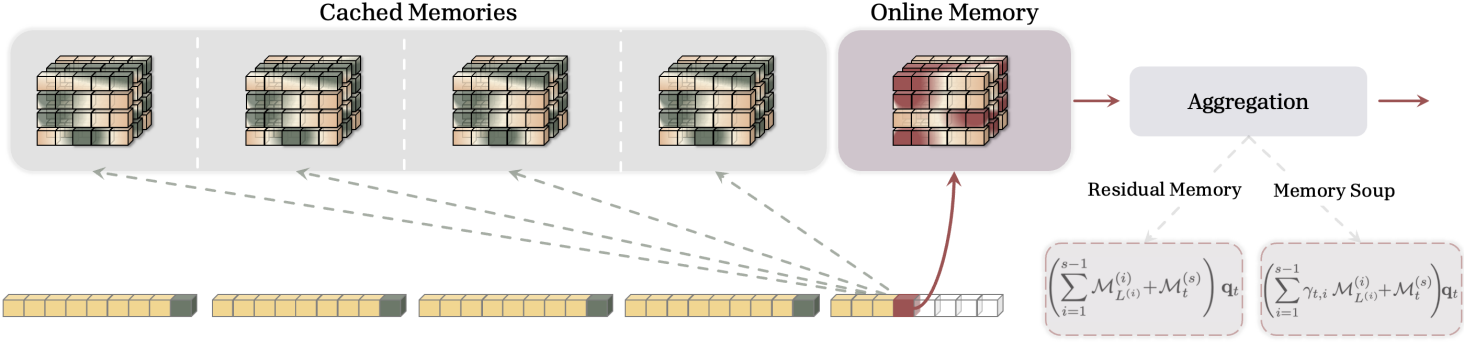
위 공식을 사용하면 메모리를 업데이트한 후 각 세그먼트에 마지막 state를 캐싱한다.
\[\begin{equation} \{ \mathcal{M}_{L^{(s)}}^{(s)} \}_{s=1}^T \end{equation}\]표준 RNN은 현재 메모리 state만 사용하여 출력을 계산한다: \(\textbf{y}_t = \mathcal{M}_t (\textbf{q}_t)\). 이와 대조적으로, 본 공식은 query \(\textbf{q}_t\)에 대한 출력을 계산하기 위해 현재 메모리와 함께 캐싱된 모든 메모리를 사용한다. 임의의 집계 함수 $\textrm{Agg}(\cdot; \cdot; \cdot)$가 주어졌을 때 출력은 다음과 같다.
\[\begin{equation} \textbf{y}_t = \textrm{Agg} \left( \{ \mathcal{M}_{L^{(1)}}^{(1)} (\cdot), \ldots, \mathcal{M}_{L^{(s-1)}}^{(s-1)} (\cdot) \}; \mathcal{M}_t^{(s)} (\cdot); \textbf{q}_t \right) \end{equation}\]($s$는 현재 세그먼트의 인덱스, \(\mathcal{M}_{L^{(i)}}^{(i)} (\textbf{q}_t)\)는 세그먼트 $i$에서 query $\textbf{q}_t$에 해당하는 정보)
1. Residual Memory
가장 간단한 $\textrm{Agg}(\cdot; \cdot; \cdot)$ 연산은 합 연산으로, 메모리 state 간의 residual connection 역할을 한다. Key, value, query와 세그먼트 $S^{(1)}, \ldots, S^{(N)}$이 주어졌을 때, 세그먼트 $s$에서 시간 $t$에서의 메모리 업데이트 및 출력 계산을 다음과 같이 정의한다.
\[\begin{equation} \mathcal{M}_t^{(s)} = f \left( \mathcal{M}_{t-1}^{(s)}; \textbf{k}_t, \textbf{v}_t \right), \quad \textrm{where} \; 1 \le t \le L^{(s)} \\ \textbf{y}_t = \underbrace{\mathcal{M}_t^{(s)} (\textbf{q}_t)}_{\textrm{Online Memory}} + \underbrace{\sum_{i=1}^{s-1} \mathcal{M}_{L^{(i)}}^{(i)} (\textbf{q}_t)}_{\textrm{Cached Memories}} \end{equation}\]Memory caching의 핵심적인 변화는 출력 계산 방식이다. 모델은 메모리 검색을 위해 현재의 온라인 메모리와 입력 query \(\textbf{q}_t\)에 대해 캐싱된 메모리 모두에 대한 forward pass를 사용한다.
Gated Residual Memory (GRM)
메모리 모듈이 선형인 경우, 즉 $\mathcal{M}$이 행렬인 경우, 캐싱된 메모리를 미리 합산할 수 있으므로, 위의 업데이트 식은 수학적으로 표준 고정 크기 메모리로 축소된다. 그러나 실제로 실험 결과는 이러한 간단한 공식조차도 모델의 성능을 향상시킬 수 있음을 보여준다. 주요 이유는 간단한 residual 메모리조차도 과거 데이터에 대한 접근성을 향상시키는 유지 연산자 역할을 하기 때문이다.
Residual 접근 방식의 또 다른 한계는 모든 캐싱된 메모리를 동일하게 취급하여 query \(\textbf{q}_t\)와의 관련성을 무시한다는 것이다. 선택적 검색을 가능하게 하기 위해 입력에 의존하는 gating을 도입한다. 세그먼트 $s$의 입력 $x_t$가 주어졌을 때, \(\gamma_t^{(i)} \in [0, 1]\)을 입력에 의존하는 파라미터로 정의하고 출력을 다음과 같이 재구성한다.
\[\begin{equation} \mathcal{M}_t^{(s)} = f \left( \mathcal{M}_{t-1}^{(s)}; \textbf{k}_t, \textbf{v}_t \right), \quad \textrm{where} \; 1 \le t \le L^{(s)} \\ \textbf{y}_t = \gamma_t^{(s)} \mathcal{M}_t^{(s)} (\textbf{q}_t) + \sum_{i=1}^{s-1} \gamma_t^{(i)} \mathcal{M}_{L^{(i)}}^{(i)} (\textbf{q}_t) \end{equation}\]\(\gamma_t^{(i)}\) 때문에 위의 공식은 해당 토큰 이전에 미리 계산할 수 없으며 다음 토큰/세그먼트에 재사용할 수도 없다. 따라서 단순 합산 방식과 달리 고정 크기 메모리로 축소되지 않으므로 모든 토큰에 대해 다시 계산해야 하며 메모리 state를 캐싱해야 한다.
\(\gamma_t^{(i)}\)를 입력 $x_t$의 linear projection으로 정의하면 \(\gamma_t^{(i)}\)는 위치 기반 필터링/포커스 역할을 하게 되는데, 이는 $x_t$의 컨텍스트가 $i$번째 세그먼트의 메모리가 얼마나 기여하는지를 결정할 뿐, 그 컨텍스트가 무엇이든 간에 영향을 받지 않는다는 것을 의미한다. 이러한 문제를 해결하기 위해, 저자들은 \(\gamma_t^{(i)}\)를 $x_t$와 $i$번째 세그먼트 $S^{(i)}$ 모두의 함수로 만들어 두 컨텍스트와 그 유사성을 모두 고려하도록 한다.
\[\begin{equation} \gamma_t^{(i)} = \langle \textbf{u}_t, \textrm{MeanPooling}(S^{(i)}) \rangle, \quad \textrm{where} \; \textbf{u}_t = x_t W_u \end{equation}\]$\textrm{MeanPooling}(\cdot)$은 세그먼트 컨텍스트를 모든 토큰의 평균으로 간단하게 표현하며, 다른 풀링 프로세스로 대체할 수도 있다. 또한 저자들은 softmax를 사용하여 \(\gamma_t^{(i)}\)를 정규화하였다.
메모리 복잡도
검색 과정에서는 현재의 온라인 메모리와 이전 모든 세그먼트의 캐싱된 메모리를 사용한다. 따라서 고정된 학습 시퀀스 길이에 대해 캐싱된 메모리의 수는 세그먼트 길이에 비례한다. 메모리 업데이트 프로세스 자체는 변하지 않으므로 $\mathcal{O}(L)$ 연산이 필요하지만, 검색 과정에서는 모든 캐싱된 메모리를 순방향으로 순회해야 하므로 토큰당 $\mathcal{O}(N)$ 연산이 필요하다. 따라서 모델의 시간 복잡도는 $\mathcal{O}(NL)$이 되며, $1 \le N \le L$이다.
$N = 1$인 경우에는 캐싱할 필요가 없으므로 단순한 RNN 모델이 된다. $N = L$인 경우에는 각 토큰이 별개의 세그먼트로 취급되므로 이전 모든 토큰의 메모리 state가 캐싱된다. 이는 attention 메커니즘의 강력한 성능을 뒷받침하는 직관적인 설명과 일맥상통한다.
2. Memory Soup
저자들은 Model Soup의 연구에서 영감을 받은 Memory Soup을 도입하였다. 핵심 아이디어는 메모리 state를 검색을 위한 하나의 메모리로 결합하는 것이다. $i$번째 세그먼트에 해당하는 캐싱된 메모리를 \(\mathcal{M}_{L^{(i)}}^{(i)}\)로 나타내고, 이를 \(\theta_{\mathcal{M}_{L^{(i)}}^{(i)}} = \{W_1^{(i)}, \ldots, W_c^{(i)}\}\)로 parameterize한다. 메모리 아키텍처는 변경되지 않으므로 $c$는 모든 메모리 state에 대해 동일하다. 따라서 메모리 캐싱을 위한 메모리 업데이트 및 검색 프로세스는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{M}_t^{(s)} = f \left( \mathcal{M}_{t-1}^{(s)}; \textbf{k}_t, \textbf{v}_t \right), \quad \textrm{where} \; 1 \le t \le L^{(s)} \\ \textbf{y}_t = \mathcal{M}_t^\ast (\textbf{q}_t) \quad \textrm{where} \; \theta_{\mathcal{M}_t^\ast} = \left\{ \sum_{i=1}^s \gamma_t^{(i)} W_i^{(i)}, \ldots, \sum_{i=1}^s \gamma_t^{(i)} W_c^{(i)} \right\} \end{equation}\]따라서 각 토큰은 입력 데이터에 따라 달라지고 변경될 수 있는 자체 검색 메모리를 가지고 있다. 실제로 위의 과정을 각 토큰이 해당 정보를 검색하기 위한 자체 메모리를 구축하는 메모리 시스템으로 해석할 수 있다.
메모리 모듈 $\mathcal{M}$이 선형일 때, Memory Soup은 수학적으로 GRM과 동일하다. 이는 연산의 선형성으로 인해 가중치를 souping한 다음 query를 적용하는 것이 개별 메모리에 query를 적용한 다음 출력을 앙상블하는 것과 동일하기 때문이다. 비선형 메모리 모듈(ex. Titans)의 경우 동일성이 깨진다. Memory Soup은 파라미터 자체를 interpolation하여 입력에 따라 달라지는 새로운 메모리 모듈 \(\mathcal{M}_t^\ast\)를 구성하고, 특정 timestep에 맞게 특화된 비선형 검색 함수를 효과적으로 생성한다.
3. Sparse Selective Caching (SSC) of Memories
앞서 설명한 방법들은 과거에 캐싱된 모든 메모리를 처리하므로, 매우 긴 시퀀스의 경우 상당한 메모리 오버헤드가 발생할 수 있다. 본 논문에서는 각 토큰이 문맥에 따라 캐싱된 메모리의 부분집합을 선택하는 Sparse Selective Caching (SSC)을 도입하여 효율성을 향상시켰다.
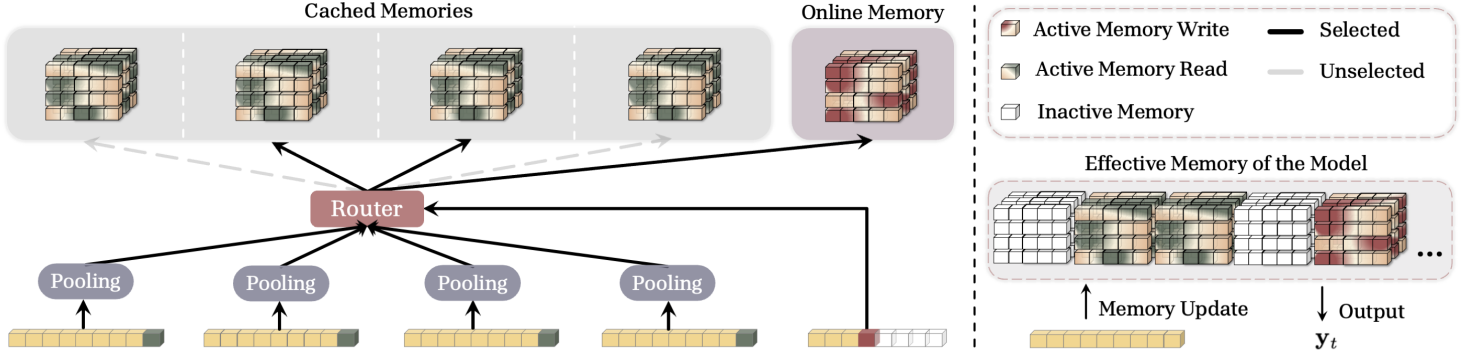
구체적으로, Mixture of Expert (MoE)에서 영감을 받아, 토큰과 각 세그먼트의 컨텍스트와의 유사성을 기반으로 캐싱된 메모리의 부분집합을 선택하는 router를 사용한다. \(\gamma_t^{(i)}\)와 동일하게, 각 세그먼트 $S^{(i)}$의 query $x_t$에 대한 관련성 점수를 다음과 같이 정의한다.
관련성 점수가 주어지면 router는 캐싱된 메모리 중 관련성이 가장 높은 $k$개를 선택한다.
\[\begin{equation} \mathcal{R}_t = \textrm{argTop-k} \left( \{ \textbf{r}_t^{(i)} \}_{i=1}^{s-1} \right) \end{equation}\]그런 다음, \(\mathcal{R}_t\)와 현재 온라인 메모리를 검색에 사용한다.
\[\begin{equation} \mathcal{M}_t^{(s)} = f \left( \mathcal{M}_{t-1}^{(s)}; \textbf{k}_t, \textbf{v}_t \right), \quad \textrm{where} \; 1 \le t \le L^{(s)} \\ \textbf{y}_t = \gamma_t^{(s)} \mathcal{M}_t^{(s)} (\textbf{q}_t) + \sum_{i \in \mathcal{R}_t} \gamma_t^{(i)} \mathcal{M}_{L^{(i)}}^{(i)} (\textbf{q}_t) \end{equation}\]이 공식에서는 각 세그먼트의 \(\textrm{MeanPooling}(S^{(i)})\)를 미리 계산할 수 있으므로 관련성 점수 계산과 각 토큰에 대한 Top-k 세그먼트 선택은 간단하게 병렬화할 수 있다. 또한 이러한 계산은 GPU/TPU 내에 캐싱된 메모리 state를 저장할 필요가 없다. 따라서 이 프로세스는 각 토큰에 대해 선택된 메모리만 로드하면 되므로 학습 및 inference 모두에서 메모리 사용량을 향상시킬 수 있다.
SSC에 대한 흥미로운 해석 중 하나는 이를 sparse한 통합 메모리 모듈로 보는 것이다. SSC는 각 토큰에 대해 메모리 쓰기 연산(토큰 저장)을 위한 파라미터 부분집합과 검색을 위한 더 큰 부분집합이 활성화되는, 메모리가 확장되는 모델로 볼 수 있다. 이는 메모리가 이전 메모리와 간섭 없이 정보를 저장하고, 효율적이고 적응적으로 정보를 검색할 수 있도록 한다. 여기서 세그먼트 크기는 통합 메모리에서 함께 활성화되는 block의 크기를 결정한다.
4. Caching Checkpoints or Independent Compressors?
단일 메모리의 체크포인트를 캐싱할 것인지, 아니면 각 세그먼트의 정보를 압축하기 위해 독립적인 메모리 모듈의 집합을 사용할지에 대한 설계상의 선택이 있다. 즉, 여기에는 두 가지 관점이 있다.
최적화 관점. 연상 메모리를 학습하시키는 과정이며 시퀀스 내의 토큰들은 학습 데이터 샘플에 해당한다. 따라서 과거 지식을 잊어버리는 것을 방지하기 위해, 학습(최적화 과정) 전반에 걸쳐 메모리의 체크포인트를 캐싱한다.
\[\begin{equation} \mathcal{M}_0^{(s)} (\cdot) = \mathcal{M}_{L^{(s-1)}}^{(s-1)} (\cdot) \end{equation}\]즉, 각 세그먼트의 메모리가 이전 세그먼트의 마지막 state에서 시작한다.
압축 관점. 이전 세그먼트의 메모리를 캐싱할 때 해당 세그먼트의 정보를 압축하여 표현하고자 한다. 따라서 forward pass \(\mathcal{M}_{L^{(s)}}^{(s)} (\textbf{q}_t)\)는 $s$번째 세그먼트에서 \(\textbf{q}_t\)에 대응하는 정보를 나타내게 된다. 서로 다른 세그먼트 간 메모리 간섭을 피하기 위해 각 세그먼트마다 독립된 메모리가 사용된다. 즉, 세그먼트 $s$에 대한 메모리가 \(\mathcal{M}_{L^{(s-1)}}^{(s-1)} (\cdot)\)과 독립적인 초기 포인트 \(\mathcal{M}_0^{(s)} (\cdot)\)에서 시작된다.
실제로 이 두 가지 선택 각각에는 고유한 장단점이 있다.
Experiments
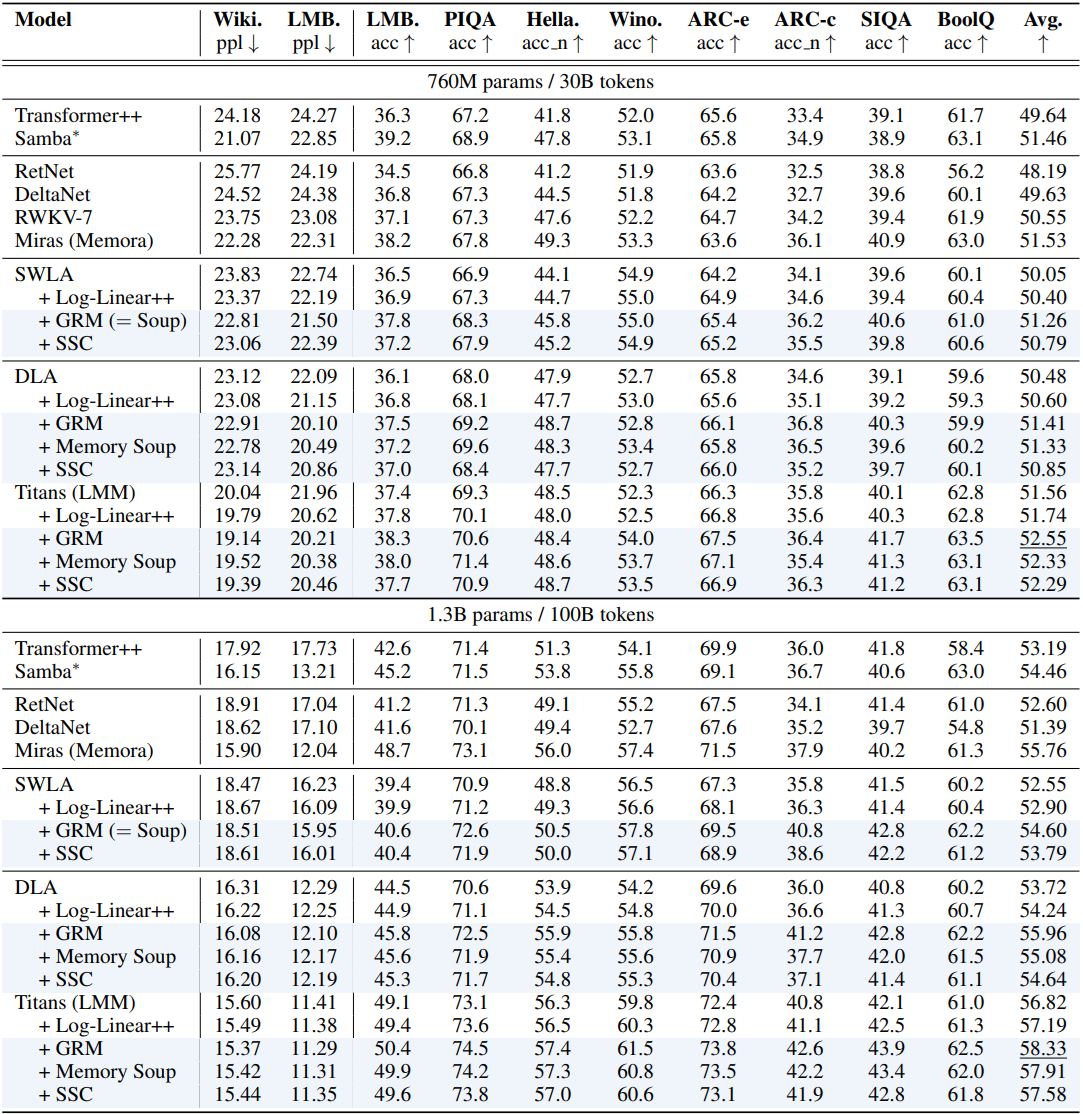
1. Language Modeling
다음은 언어 모델링 및 상식 추론에 대한 비교 결과이다.
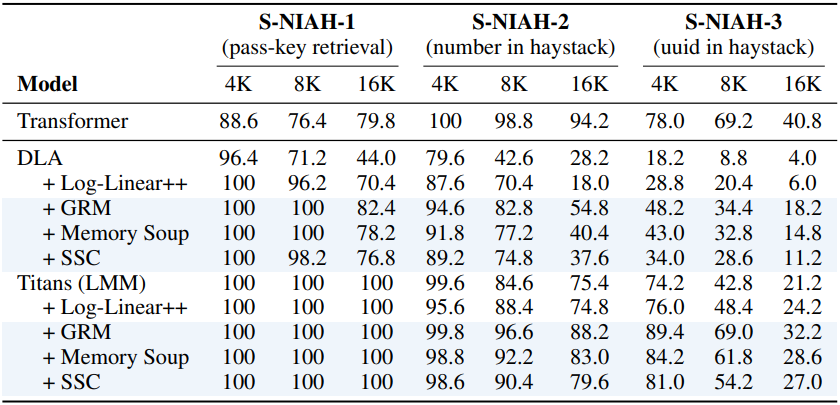
2. Needle-In-A-Haystack Tasks
다음은 세 가지 난이도에 대한 Needle-In-A-Haystack 비교 결과이다.
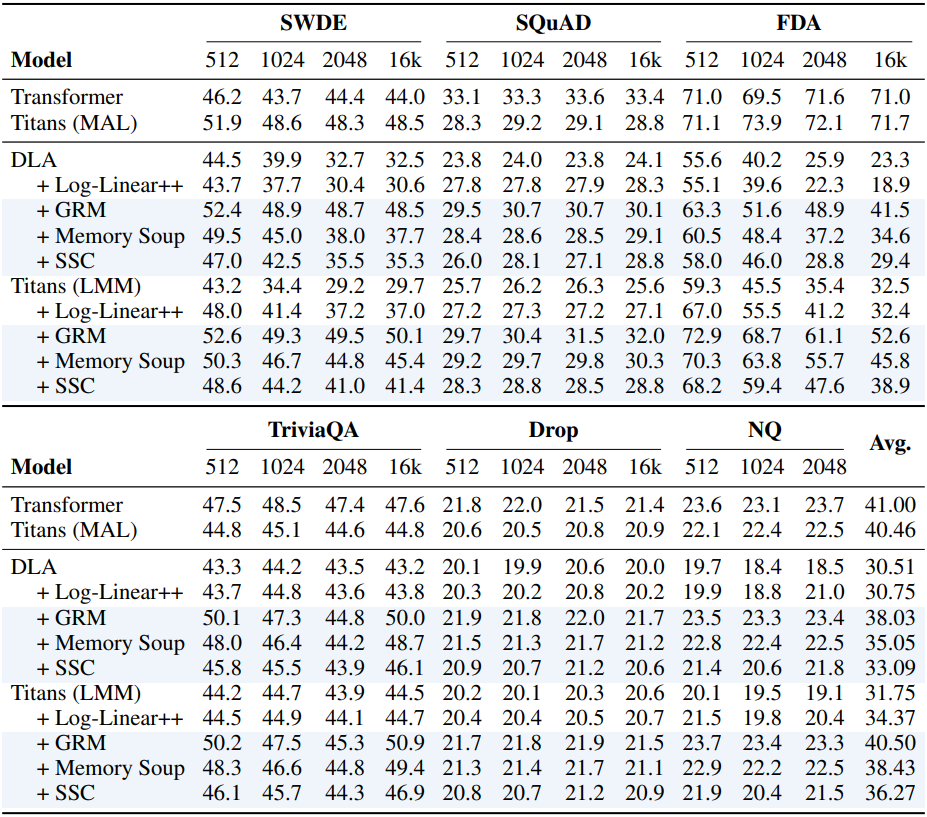
3. In-context Retrieval Tasks
다음은 입력 길이에 따른 검색의 정확도를 비교한 결과이다.
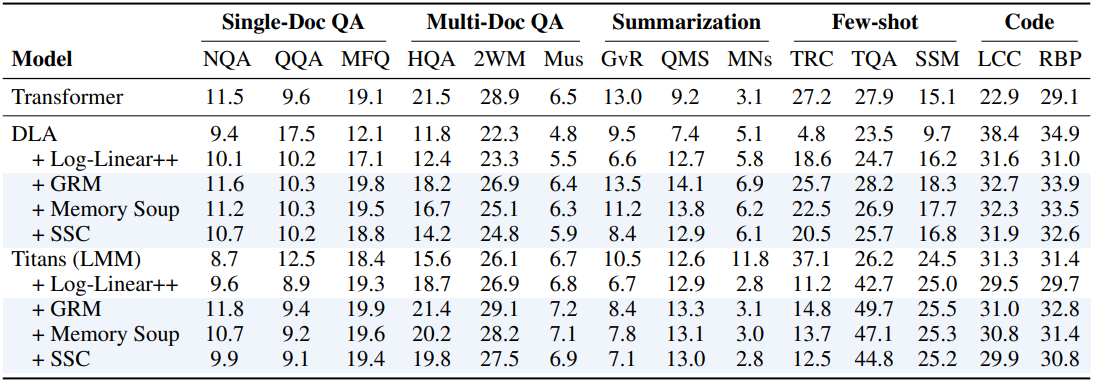
4. Long Context Understanding Tasks
다음은 LongBench 정확도를 비교한 결과이다.
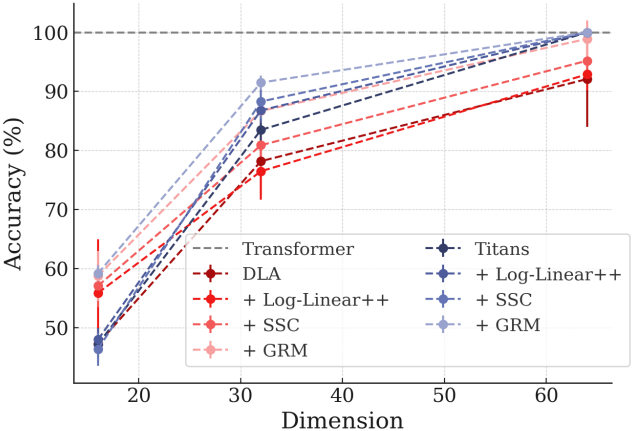
5. Multi-Query Associative Recall (MQAR)
다음은 5개의 seed에 대한 평균 MQAR 정확도를 비교한 그래프이다.
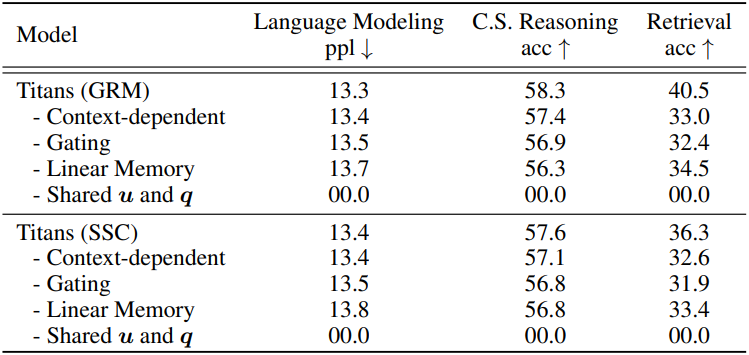
6. Ablation Studies
다음은 ablation study 결과이다.
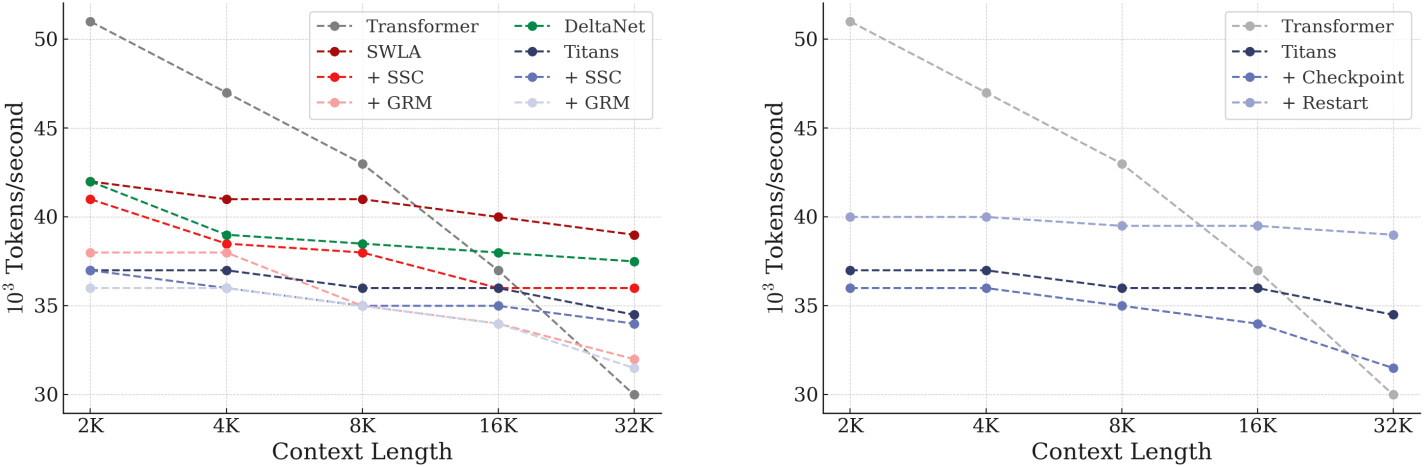
7. Efficiency
다음은 학습 시 토큰 처리량을 비교한 그래프이다.