[논문리뷰] In-Place Test-Time Training
ICLR 2026 (Oral). [Paper] [Github]
Guhao Feng, Shengjie Luo, Kai Hua, Ge Zhang, Di He, Wenhao Huang, Tianle Cai
ByteDance Seed | Peking University
7 Apr 2026
Introduction
Test-Time Training (TTT)은 단순히 정적인 모델의 효율성을 높이는 대신, 모델이 동적으로 파라미터를 업데이트하고 특정 컨텍스트에 적응할 수 있도록 하여 attention 메커니즘의 효율성 한계를 직접적으로 해결한다. 구체적으로, TTT는 fast weight라고 불리는 소수의 모델 파라미터를 도입하여 새로운 입력이 들어올 때마다 즉시 업데이트할 수 있도록 한다. Self-supervised reconstruction objective를 최소화함으로써, fast weight는 컨텍스트 정보를 압축하고 내재화하여 표현력이 풍부하고 실시간으로 진화하는 state 역할을 한다.
현재 LLM 생태계 내에서 TTT의 잠재력을 발휘하는 데에는 다음과 같은 중요한 장벽이 존재한다.
- 기존 TTT 방법은 Transformer 구조에 없는 추가적인 특수 레이어에 의존하는 경우가 많아 처음부터 비용이 많이 드는 사전 학습이 필요하다.
- TTT 메커니즘은 본질적으로 순차적이다. 기존 방법들은 chunk 단위 가속을 탐구했지만, TTT가 주요 token mixer 역할을 하기 때문에 성능 유지를 위해 작은 chunk에 의존해야 하므로 대규모 병렬 처리에 병목 현상이 발생한다.
- TTT의 fast weight 업데이트에 널리 사용되는 일반적인 reconstruction objective는 next-token prediction (NTP) task에 명시적으로 적합하지 않아 성능을 저해할 수 있다.
이러한 격차를 해소하기 위해, 본 논문에서는 LLM에 TTT 기능을 원활하게 부여하도록 설계된 프레임워크인 In-Place Test-Time Training (In-Place TTT)을 소개한다. 핵심 아이디어는 새로운 특수 레이어를 도입하는 대신, 기존 MLP block들을 in-place 방식으로 재활용하는 것이다. 구체적으로, In-Place TTT는 MLP block의 최종 projection 행렬을 fast weight로 간주하고 inference 중에 in-place로 업데이트한다. 이러한 방식은 모델 아키텍처를 수정할 필요가 없으므로 사전 학습된 가중치의 무결성을 유지하고, 비용이 많이 드는 재학습 없이도 즉시 적응이 가능하다.
계산 비효율성과 objective 불일치 문제를 해결하기 위해, 본 논문에서는 언어 모델링을 위한 맞춤형 적응 메커니즘을 설계했다. 비효율적인 토큰별 업데이트를 확장 가능한 chunk-wise update rule로 대체했다. 또한, 본 연구의 in-place 디자인은 attention 메커니즘과 상호 보완적으로 작동한다. 이러한 시너지 효과로 인해 작은 chunk 단위의 필요성이 사라지고, 높은 처리량을 확보할 수 있다. 동시에, 일반적인 reconstruction objective를 넘어 NTP와 명시적으로 정렬된 새로운 objective를 도입했다. NTP에 정렬된 objective가 fast weight가 autoregressive한 언어 모델링에 유용한 예측 정보를 저장하도록 유도하여, 매우 효율적이고 scalable하다.
Method
1. Overall Framework
Repurposing MLP Blocks for In-Place Adaptation
기존 TTT 방법은 주로 attention 메커니즘을 대체할 수 있는 잠재적 솔루션으로 제시해 왔다. 그러나 이러한 방법들은 일반적으로 중간 규모의 모델에서 수행되었으며, 이는 수십억 개의 파라미터를 사용하는 최신 LLM과는 매우 다른 환경이다. 따라서 LLM의 기능에 매우 중요한 학습 속성을 가진 핵심 attention 메커니즘을 교체하는 것은 위험 부담이 큰 아키텍처 변경이다. 더욱이, 무작위로 초기화된 새로운 레이어를 도입하는 것 또한 LLM의 학습된 파라미터와 충돌을 일으켜, 이러한 불균형을 해결하기 위해 비용이 많이 들고 비실용적인 재학습을 필요로 한다.
저자들의 핵심 아이디어는 이러한 문제들을 완전히 우회하는 것이다. 구성 요소를 교체하거나 추가하는 대신, 널리 사용되는 모듈인 MLP block을 fast weight로도 활용한다. Fast weight의 선택에는 제약이 없다. 즉, 어떤 파라미터든 TTT 메커니즘을 통해 업데이트되는 fast weight로 사용될 수 있다. 특히, Transformer의 MLP block은 key-value 메모리의 한 형태로 볼 수 있으며, 사전 학습 과정에서 획득한 방대한 일반 지식을 저장하는 slow weight 역할을 한다. 따라서 이 구성 요소를 활용하여 inference 시점에 동적으로 변화하는 컨텍스트 정보를 반영하는 적응형 fast weight로도 활용하는 것은 자연스러운 확장이다.
저자들은 널리 사용되는 gated MLP 아키텍처를 적용하였다. Hidden representation $\textbf{H}$가 주어졌을 때, gated MLP는
\[\begin{equation} \textbf{O} = \left( \phi (\textbf{H}\textbf{W}_\textrm{gate}^\top) \odot (\textbf{H}\textbf{W}_\textrm{up}^\top) \right) \textbf{W}_\textrm{down}^\top \end{equation}\]을 계산한다. 본 프레임워크에서는 입력 projection 행렬 \(\textbf{W}_\textrm{up}\)과 \(\textbf{W}_\textrm{gate}\)를 고정된 slow weight로 취급하고, 최종 projection 행렬 \(\textbf{W}_\textrm{down}\)을 적응 가능한 fast weight로 재활용하였다. \(\textbf{W}_\textrm{down}\)을 in-place 업데이트하는 방식을 통해 모델의 아키텍처적 무결성을 유지하고, TTT를 구조 변경 없이 가볍고 바로 적용 가능한 방식으로 전환한다.
Efficient Adaptation with Chunk-Wise Updates
아키텍처 호환성 외에도, 본 설계는 상당한 계산 효율성을 제공한다. 기존의 TTT 방식은 attention 메커니즘을 대체하는 것을 목표로 했기 때문에, 엄격한 인과관계(causality)를 적용하고 세밀한 토큰 혼합을 위해 비효율적인 토큰 단위 업데이트에 의존해야 했다. 최근 논문들에서는 가속을 위해 chunk-wise update 방식을 탐구해 왔다.
본 프레임워크 또한 이러한 trade-off를 완전히 회피한다. 본 논문에서는 MLP block만 적응시키고 attention layer는 그대로 유지하기 때문에, 토큰 단위 제약에서 벗어나 훨씬 효율적인 chunk-wise update 전략을 구현할 수 있으며, 작은 chunk 제약 또한 우회한다 (chunk 크기 512~1024에서 최적의 성능을 달성).
이 과정은 다음과 같이 진행된다. 중간 activation
\[\begin{equation} \textbf{Z} = \phi (\textbf{H}\textbf{W}_\textrm{gate}^\top) \odot (\textbf{H} \textbf{W}_\textrm{up}^\top) \in \mathbb{R}^{n \times d_\textrm{ff}} \end{equation}\]와 이에 대응하는 value target 및 output \(\textbf{V}, \textbf{O} \in \mathbb{R}^{n \times d_\textrm{model}}\)이 주어졌을 때, 이들을 크기 $C$의 $k$개의 겹치지 않는 chunk로 분할한다.
\[\begin{aligned} \textbf{Z}_{[i]} &= \textbf{Z}_{iC+1 : (i+1)C} \in \mathbb{R}^{C \times d_\textrm{ff}} \\ \textbf{V}_{[i]} &= \textbf{V}_{iC+1 : (i+1)C} \in \mathbb{R}^{C \times d_\textrm{model}} \\ \textbf{O}_{[i]} &= \textbf{O}_{iC+1 : (i+1)C} \in \mathbb{R}^{C \times d_\textrm{model}} \end{aligned}\]\(W_\textrm{down}^{(i)}\)을 chunk $i \in [k]$를 처리하기 전의 빠른 fast weight state라고 하고, \(W_\textrm{down}^{(0)} = W_\textrm{down}\)이라고 하자. 각 chunk $i$에 대해 두 가지 순차적인 연산을 수행한다.
- Apply Operation: Fast weight \(\textbf{W}_\textrm{down}^{(i)}\)의 현재 state는 chunk \(\textbf{Z}_{[i]}\)를 처리하는 데 사용된다.
- Update Operation: Fast weight \(\textbf{W}_\textrm{down}^{(i)}\)은 \(\textbf{Z}_{[i]}\)를 key로, $\textbf{V}_{[i]}$를 value로 사용하여 업데이트되며, 이는 loss function $\mathcal{L}$과 learning rate $\eta$를 사용한 gradient descent step을 통해 수행된다.
이 chunk-wise update 전략은 최신 하드웨어에 최적화되어 있다. 또한, MLP를 in-place로 적용함으로써 큰 chunk 크기 $C$를 사용하여 대량의 토큰들을 한 번에 처리할 수 있으며, 이를 통해 병렬 처리를 극대화하고 GPU 또는 TPU의 연산 능력을 활용할 수 있다.
2. LM-Aligned Objective
기존 TTT 접근 방식은 일반적으로 reconstruction objective, 예를 들어 \(\mathcal{L} (f_\textbf{W} (k), v)\)와 같이 사용하는데, 여기서 $k$와 $v$는 모두 동일한 입력 토큰 $x$의 linear projection 출력이다. 이는 모델이 현재 토큰의 표현을 단순히 암기하도록 유도한다. 저자들은 이것이 언어 모델링 task에 최적의 방법이 아니라고 주장하며, 대신 LLM의 next-token prediction (NTP)에 맞춰 objective를 정렬할 것을 제안하였다.
이를 위해 target $v$에 미래 토큰 정보를 한다. 구체적으로, target $\hat{\textbf{V}}$는 다음과 같이 계산한다.
\[\begin{equation} \hat{\textbf{V}} = \textrm{Conv1D} (\textbf{X}_0) \textbf{W}_\textrm{target} \end{equation}\](\(\textbf{X}_0 \in \mathbb{R}^{n \times d_\textrm{model}}\)는 토큰 임베딩, $\textrm{Conv1D}(\cdot)$는 1D convolution, \(\textbf{W}_\textrm{target}\)은 학습 가능한 projection 행렬)
이를 통해, target \(\hat{\textbf{V}}\)에서 미래 토큰 정보의 양을 제어할 수 있다. 예를 들어, next-token target은 \(\textbf{W}_\textrm{target}\)을 항등 변환으로 parameterize하고 $\textrm{Conv1D}(\cdot)$의 커널 가중치를 다음 토큰에 대해서는 1, 다른 토큰에 대해서는 0으로 할당함으로써 얻을 수 있다.
Loss function을 단순화하기 위해 널리 사용되는 유사도 측정 \(\mathcal{L}(\cdot, \cdot) = -\langle \cdot, \cdot \rangle_F\)을 사용한다. 이 loss function 하에서, chunk-wise 메커니즘에서의 fast weight에 대한 gradient를 직접 도출할 수 있다.
\[\begin{equation} \textbf{W}_\textrm{down}^{(i)} = \textbf{W}_\textrm{down}^{(i-1)} + \eta \hat{\textbf{V}}_{[i]}^\top \textbf{Z}_{[i]} \end{equation}\]3. Implementation Details
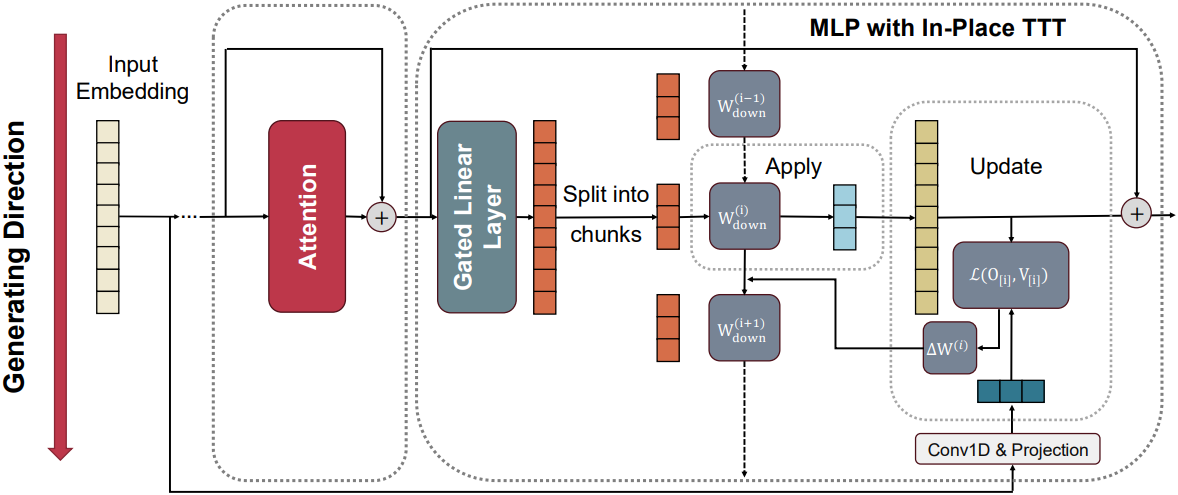
Context Parallelism (CP)을 통한 효율적인 구현
Update rule의 결합법칙적 성질로 인해 In-Place TTT는 Context Parallelism (CP) 구현에 적합하며, 이는 시퀀스를 길이 방향으로 분할하고 chunk를 동시에 처리한다. 이 과정은 세 단계로 진행된다.
- 모든 chunk \(i \in \{1, \ldots, T\}\)에 대해 중간 activation \(\textbf{Z}_{[i]}\)와 fast weight 업데이트 \(\Delta \textbf{W}_\textrm{down}^{(i)} = (\hat{\textbf{V}}_{[i]})^\top \textbf{Z}_{[i]}\)를 병렬로 계산한다.
- 각 chunk에 대한 업데이트 \(\Delta \textbf{S}_i = \sum_{j=1}^{i-1} \Delta \textbf{W}_j\)를 계산하기 위해, \([\ldots, \Delta \textbf{W}_\textrm{down}^{(i)}, \Delta \textbf{W}_\textrm{down}^{(i+1)}, \ldots]\)에 대해 한 번의 prefix sum이 수행되며, 이는 최신 가속기에서 매우 효율적이다.
- 각 chunk에 대한 유효 fast weight \(\textbf{W}_\textrm{down}^{(i-1)} = \textbf{W}_\textrm{down}^{(0)} + \eta \Delta \textbf{S}_i\)와 해당 출력 \(\textbf{O}_{[i]} = \textbf{Z}_{[i]} (\textbf{W}_\textrm{down}^{(i−1)})^\top\)를 병렬로 계산한다.
인과관계 (causality) 및 경계 처리
Chunk $i$ 자체에 대한 update delta에 미래 정보가 포함되지 않도록 하기 위해, 값을 생성할 때 1D convolution에 causal padding을 적용한다. 이를 통해 각 update delta 계산이 해당 chunk에 격리되어 병렬 스캔이 수학적으로 순차적 업데이트와 동일하게 된다. 또한, 문서 경계에서 fast weight는 사전 학습된 state로 재설정되어 독립적인 시퀀스 간의 컨텍스트 누출을 방지한다.
Experiments
1. In-Place TTT as a Drop-in Enhancement for Pre-trained LLMs
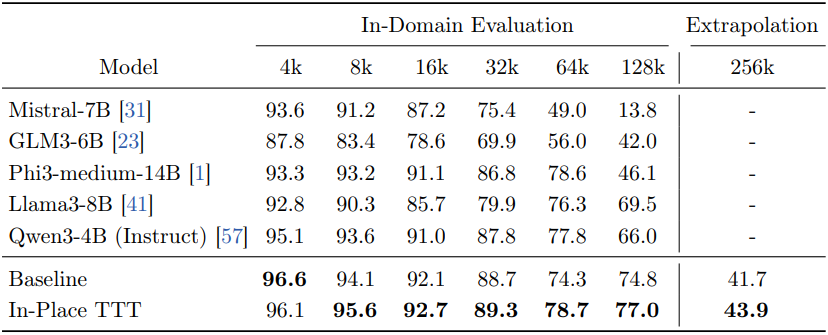
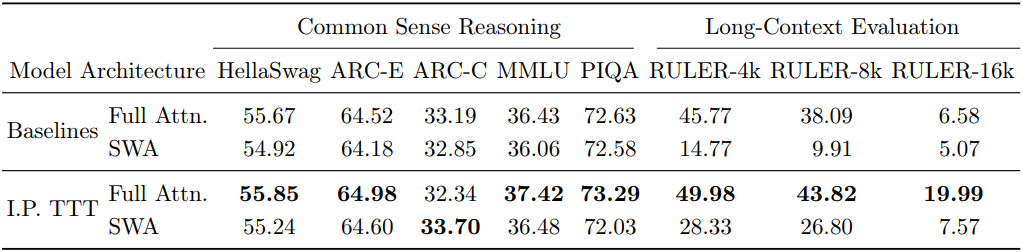
다음은 RULER 벤치마크에서의 성능을 비교한 표이다.
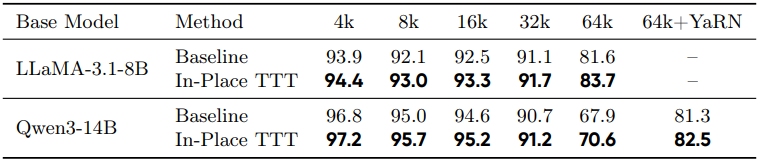
2. Pre-training from Scratch: A Comparative Analysis
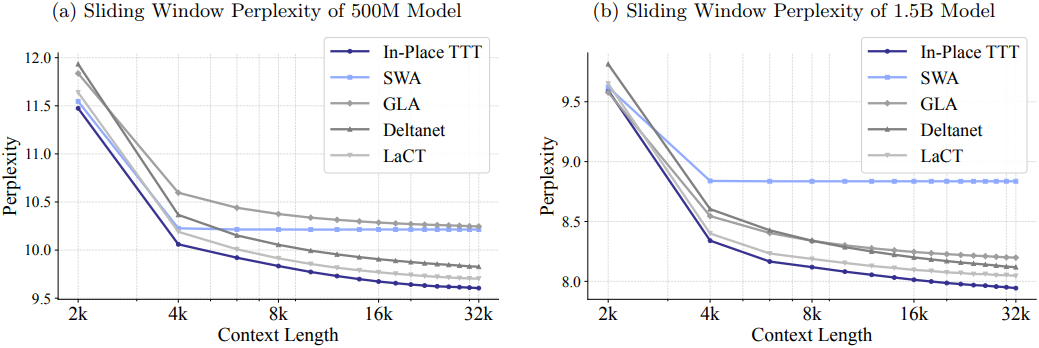
다음은 500M 모델과 1.5B 모델에 대한 Sliding Window Perplexity를 비교한 그래프이다. (SWA: sliding window attention를 사용하는 표준 Transformer)
다음은 다양한 벤치마크에서 4B 모델의 성능을 비교한 결과이다.
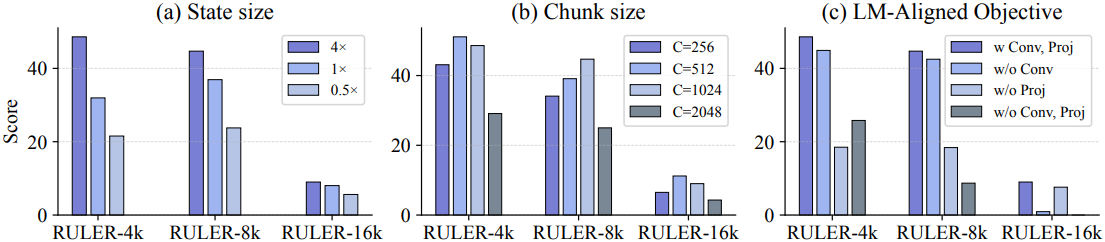
3. Ablation Studies: On the Impact of Key Design Choices
다음은 주요 설계 선택들에 대한 ablation study 결과이다. (1.7B 모델, RULER 벤치마크)
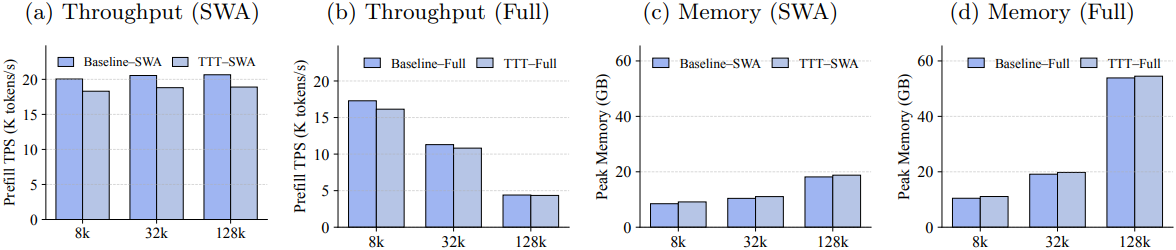
다음은 토큰 처리량과 메모리 사용량에 대한 비교 결과이다. (4B 모델)