[논문리뷰] Structured 3D Latents for Scalable and Versatile 3D Generation
CVPR 2025 (Highlight). [Paper] [Page] [Github]
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, Jiaolong Yang
Tsinghua University | USTC | Microsoft Research
2 Dec 2024
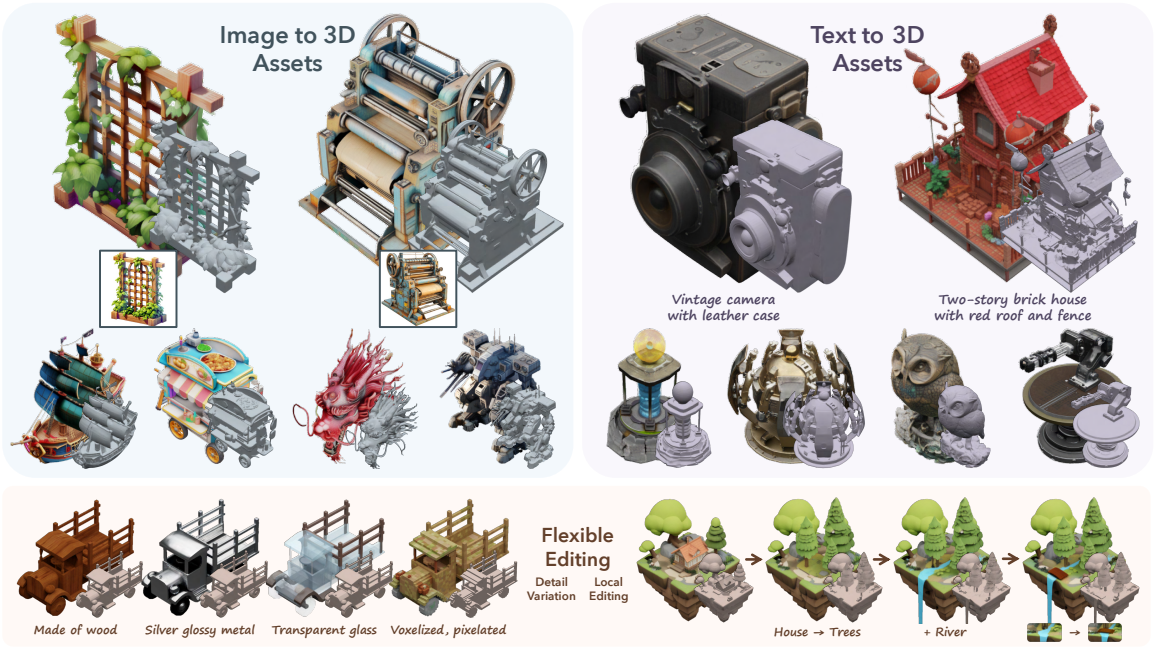
Introduction
본 논문에서는 다양한 표현 방식에 걸쳐 고품질 3D 생성을 가능하게 하고, 다양한 후속 요구사항을 수용할 수 있는 통합적인 latent space를 개발하는 것을 목표로 하였다. 이 문제는 매우 어려운 과제이며, 기존 연구에서는 거의 다뤄지지 않았다. 본 논문의 주요 전략은 latent space 설계에 명시적인 sparse 3D 구조를 도입하는 것이다. 이러한 구조는 object 주변의 로컬 voxel 내 속성을 특징화함으로써 다양한 3D 표현으로 디코딩할 수 있도록 하며, 이는 최근 3D 재구성 분야의 발전에서 입증되었다. 또한, 3D 정보가 없는 voxel을 건너뛰어 효율적인 고해상도 모델링을 가능하게 하고, 유연한 편집을 용이하게 하는 locality를 도입한다.
하지만 이러한 구조를 사용하더라도, 다양한 3D 표현으로 고품질 디코딩을 달성하는 것은 여전히 쉽지 않다. Latent 표현이 3D 에셋의 포괄적인 geometry와 외형 정보를 모두 포함해야 하기 때문이다. 이러한 문제를 해결하기 위해, 두 번째 전략은 뛰어난 3D 인식 능력과 디테일한 표현 능력을 입증한 DINOv2를 sparse 구조에 적용하는 것이다. 이 접근 방식은 전용 3D 인코더의 필요성을 없애고, 3D 데이터를 특정 표현에 맞추는 비용이 많이 드는 사전 조정 과정을 제거한다.
본 논문에서는 이러한 두 가지 전략을 바탕으로 고품질의 다용도 3D 생성을 위한 통합 3D latent 표현인 Structured LATents (SLAT)을 소개한다. SLAT은 sparse 구조와 강력한 비전 표현을 결합한다. Object 표면과 교차하는 활성 voxel에 로컬 latent를 정의하고, 이 로컬 latent는 3D 에셋의 렌더링된 뷰에서 얻은 이미지 feature를 융합 및 처리하여 인코딩한 후 활성 voxel에 적용한다. DINOv2 feature는 상세한 기하학적 및 시각적 특성을 포착하여 활성 voxel이 제공하는 coarse한 구조를 보완한다. 다양한 디코더를 적용하여 SLAT를 고품질의 다양한 3D 표현으로 매핑할 수 있다.
본 논문에서는 SLAT을 기반으로 텍스트 프롬프트 또는 이미지를 조건으로 사용하는 대규모 3D 생성 모델인 TRELLIS를 학습시켰다. 2단계 파이프라인을 적용하여 먼저 SLAT의 sparse 구조를 생성하고, 그 다음 비어 있지 않은 셀에 대한 latent 벡터를 생성한다. 핵심 모델로는 rectified flow transformer를 사용하고, SLAT의 sparsity를 처리하도록 적절히 조정했다. 엄선된 대규모 3D 에셋 데이터셋을 사용하여 최대 2B 파라미터로 TRELLIS를 학습시켰다.
Method
1. Structured Latent Representation
3D 에셋 $\mathcal{O}$에 대하여, 3D 그리드 상의 로컬 latent 집합을 정의하는 structured latent (SLAT) $\textbf{z}$를 사용하여 해당 에셋의 geometry 및 외형 정보를 인코딩한다.
\[\begin{equation} \textbf{z} = \{ (\textbf{z}_i, \textbf{p}_i) \}_{i=1}^L, \quad \textbf{z}_i \in \mathbb{R}^C, \quad \textbf{p}_i \in \{0, 1, \ldots, N-1\}^3 \end{equation}\](\(\textbf{p}_i\)는 $\mathcal{O}$의 표면과 교차하는 3D 그리드에서 활성 voxel의 위치 인덱스이고, \(\textbf{z}_i\)는 해당 voxel에 연결된 로컬 latent, $N$은 3D 그리드의 공간적 길이, $L$은 활성 voxel의 총 개수)
직관적으로, \(\textbf{p}_i\)는 3D 에셋의 대략적인 구조를 나타내고, \(\textbf{z}_i\)는 외형과 shape의 미세한 디테일을 포착한다. 이러한 SLAT들은 $\mathcal{O}$의 전체 표면을 포괄하여 전체적인 형태와 복잡한 디테일을 효과적으로 담아낸다.
3D 데이터의 sparsity로 인해 활성 voxel의 수는 그리드의 전체 크기보다 훨씬 작으므로 ($L \ll N^3$), 비교적 높은 해상도로 구성할 수 있다.
2. Structured Latents Encoding and Decoding
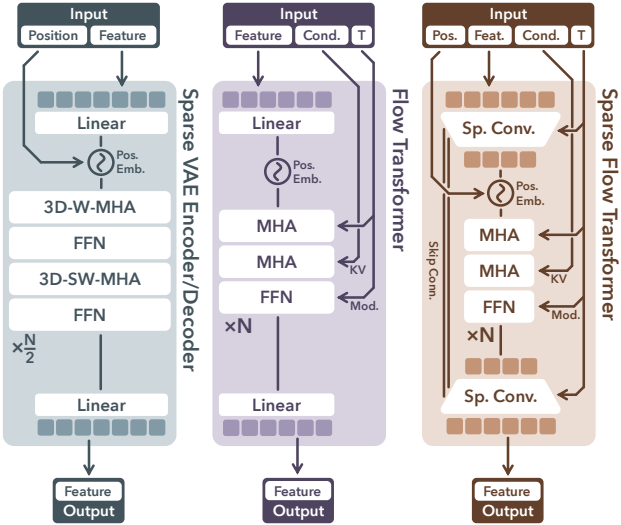
Visual feature 집계
먼저 각 3D 에셋 $\mathcal{O}$를 voxelize된 feature \(\textbf{f} = \{(\textbf{f}_i, \textbf{p}_i)\}_{i=1}^L\)로 변환한다. 여기서 \(\textbf{p}_i\)는 위에서 정의된 활성 voxel이고, \(\textbf{f}_i\)는 해당 영역의 상세한 구조 및 외형 정보를 기록하는 feature이다.
각 활성 voxel에 대한 feature 벡터 \(\textbf{f}_i\)를 도출하기 위해, $\mathcal{O}$의 멀티뷰 이미지에서 추출한 feature들을 집계한다. 구면에서 무작위로 샘플링된 카메라 시점의 이미지를 렌더링하고, 사전 학습된 DINOv2 인코더를 사용하여 feature map을 추출한다. 각 voxel은 멀티뷰 feature map에 projection되어 해당 위치의 feature를 추출하고, 이들의 평균값을 \(\textbf{f}_i\)로 사용한다. 저자들은 $\textbf{f}$를 SLAT $\textbf{z}$의 해상도 $64^3$와 일치하도록 설정하였다. 경험적으로, DINOv2 feature의 강력한 표현 능력과 활성 voxel이 제공하는 대략적인 구조 덕분에 이 해상도는 원본 3D 에셋을 높은 충실도로 재구성하기에 충분하다.
Structured latent를 위한 sparse VAE
저자들은 voxelize된 feature $\textbf{f}$를 이용하여 3D 에셋 인코딩을 위한 트랜스포머 기반 VAE 아키텍처를 도입하였다.
구체적으로, 인코더 $\mathcal{E}$는 먼저 입력 $\textbf{f}$를 SLAT $\textbf{z}$로 인코딩하고, 이어서 디코더 $\mathcal{D}$는 $\textbf{z}$를 특정 3D 표현으로 나타낸 3D 에셋으로 변환한다. 디코딩된 3D 에셋과 GT 사이에는 재구성 loss가 적용되어 인코더와 디코더를 end-to-end 방식으로 학습시키며, 정규 분포 정규화를 유도하기 위해 \(\textbf{z}_i\)에 KL 페널티가 추가된다.
인코더와 디코더는 동일한 transformer 구조를 공유한다. Sparse한 voxel을 처리하기 위해 활성 voxel에서 입력 feature를 serialize하고 voxel 위치에 기반한 sinusoidal positional encoding을 추가하여 가변 컨텍스트 길이 $L$을 갖는 토큰을 생성한 후, 이 토큰을 transformer block을 통해 처리한다. Latent의 locality 특성을 고려하여 3D 공간에서 shifted window attention을 도입하여 로컬 정보 상호작용을 강화하고, 이를 통해 full attention 구현에 비해 효율성을 향상시킨다.
다양한 형식으로 디코딩
SLAT은 \(\mathcal{D}_\textrm{GS}\), \(\mathcal{D}_\textrm{RF}\), \(\mathcal{D}_\textrm{M}\)과 같은 각각의 디코더를 통해 3D Gaussians, radiance field, 메쉬와 같은 다양한 3D 표현으로 디코딩할 수 있다. 이 디코더들은 출력 layer를 제외하고는 동일한 아키텍처를 공유하며, 각 표현에 맞춘 특정 재구성 loss를 사용하여 학습할 수 있다.
- 3D Gaussians
\(\textbf{x}_i^k = \textbf{p}_i + \textrm{tanh}(\textbf{o}_i^k)\)로 Gaussian의 위치를 계산하여 $\textbf{x}$가 voxel 내에 있도록 제한한다.
- Radiance Fields
(\(\textbf{v}_i^x, \textbf{v}_i^y, \textbf{v}_i^z \in \mathbb{R}^{16 \times 8}\), \(\textbf{v}_i^c \in \mathbb{R}^{16 \times 4}\)는 local radiance volume의 CP decomposition)
- Meshes
(\(\textbf{w}_i^j \in \mathbb{R}^{45}\)는 FlexiCubes의 파라미터, \(d_i^j \in \mathbb{R}^8\)은 voxel의 8개 꼭짓점의 SDF)
최종 출력 해상도를 $256^3$으로 높이기 위해 transformer backbone 뒤에 두 개의 convolutional upsampling block을 추가하고, 0-level isosurface에서 메쉬를 추출한다.
3. Structured Latents Generation
SLAT을 생성하기 위해 2단계 생성 파이프라인을 사용한다. 첫 번째 단계에서는 sparse한 구조를 생성하고, 두 번째 단계에서는 이에 연결된 로컬 latent를 생성한다. Latent 분포 모델링에는 rectified flow model을 사용한다.
Rectified flow models
Rectified flow model은 forward process \(\textbf{x}(t) = (1 − t) \textbf{x}_0 + t \boldsymbol{\epsilon}\)를 사용하며, timestep $t$로 데이터 샘플 \(\textbf{x}_0\)와 noise $\boldsymbol{\epsilon}$ 사이를 interpolation한다. Backward process는 time-dependent vector field \(\textbf{v}(\textbf{x}, t) = \nabla_t \textbf{x}\)로 표현되며, noisy한 샘플을 데이터 분포 방향으로 이동시킨다. 이 backward process는 conditional flow matching (CFM) objective를 최소화하는 신경망 \(\textbf{v}_\theta\)로 근사화할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{CFM} (\theta) = \mathbb{E}_{t, \textbf{x}_0, \boldsymbol{\epsilon}} \| \textbf{v}_\theta (\textbf{x}, t) - (\boldsymbol{\epsilon} - \textbf{x}_0) \|_2^2 \end{equation}\]Sparse한 구조 생성
첫 번째 단계에서는 sparse한 구조 \(\{\textbf{p}_i\}_{i=1}^L\)을 생성하는 것을 목표로 한다. 이를 신경망을 사용하여 구현하기 위해, sparse한 활성 voxel을 dense한 3D 그리드 \(\textbf{O} \in \{0, 1\}^{N \times N \times N}\)로 변환하고, voxel 값을 활성이면 1, 그렇지 않으면 0으로 설정한다.
Dense한 그리드 $\textbf{O}$를 직접 생성하는 것은 계산 비용이 많이 든다. 본 논문에서는 이를 저해상도 feature 그리드 \(\textbf{S} \in \mathbb{R}^{D \times D \times D \times C_S}\)로 압축하기 위해 3D convolutional block을 사용하는 간단한 VAE를 도입하였다. $\textbf{O}$는 대략적인 geometry만을 나타내므로, 이 압축은 거의 손실 없이 이루어져 효율성을 크게 향상시킨다. 또한, $\textbf{O}$의 discrete한 값을 rectified flow 학습에 적합한 continuous feature로 변환한다.
저자들은 feature 그리드 $\textbf{S}$를 생성하기 위한 간단한 transformer backbone \(\mathcal{G}_S\)를 도입하였다. 입력으로 사용된 dense한 noisy grid는 serialize되고, positional encoding과 결합되어 transformer에 입력되어 denoising된다. Timestep 정보는 adaLN와 gating 메커니즘을 사용하여 통합된다. 조건은 cross-attention layer를 통해 key와 value로 주입된다. 텍스트 조건의 경우, 사전 학습된 CLIP 모델의 feature를 사용한다. 이미지 조건의 경우, DINOv2 feature를 사용한다. Denoising된 feature 그리드 $\textbf{S}$는 $\textbf{O}$로 디코딩되고, 최종 구조인 활성 voxel \(\{\textbf{p}_i\}_{i=1}^L\)로 다시 변환된다.
Structured latent 생성
두 번째 단계에서는 sparse한 구조에 맞게 설계된 transformer \(\mathcal{G}_L\)을 사용하여 \(\{\textbf{p}_i\}_{i=1}^L\)이 주어졌을 때 latent \(\{\textbf{z}_i\}_{i=1}^L\)을 생성한다.
Sparse VAE 인코더에서처럼 입력 noisy latent를 직접 serialize하는 대신, DiT에서와 유사하게 더 짧은 시퀀스로 패킹하여 효율성을 향상시킨다. Sparse한 구조로 인해, latent를 $2^3$ 로컬 영역 내에 패킹하기 위해 sparse convolution을 사용하는 다운샘플링 block을 적용한 후, 여러 개의 time-modulated transformer block을 적용한다. Transformer 끝에는 다운샘플링 block과 skip connection을 통해 연결된 convolution 업샘플링 block을 추가한다. \(\mathcal{G}_S\)와 마찬가지로, timestep은 adaLN layer를 통해 통합되고, 텍스트/이미지 조건은 cross-attention을 통해 주입된다.
\(\mathcal{G}_S\)와 \(\mathcal{G}_L\)은 CFM objective를 사용하여 각각 별도로 학습된다. 학습 후, SLAT \(\textbf{z} = \{(\textbf{z}_i, \textbf{p}_i)\}_{i=1}^L\)은 두 모델에 의해 순차적으로 생성될 수 있으며, 다양한 디코더를 통해 다양한 형식의 고품질 3D 에셋으로 변환될 수 있다.
4. 3D Editing with Structured Latents
디테일 변화
구조와 latent의 분리를 통해 전체적인 geometry에 영향을 주지 않고 3D 에셋의 디테일을 다양하게 변화시킬 수 있다. 이는 에셋의 구조를 유지하고 두 번째 생성 단계에서 다른 텍스트 프롬프트를 적용함으로써 쉽게 구현할 수 있다.
영역별 편집
SLAT의 locality를 활용하여 특정 영역의 voxel과 latent만 변경하고 나머지는 그대로 두는 영역별 편집이 가능하다. 이를 위해 본 논문의 2단계 생성 파이프라인에 Repaint 알고리즘을 적용한다. 편집할 voxel의 bounding box가 주어지면, 변경되지 않은 영역과 제공된 텍스트 또는 이미지 프롬프트를 고려하여 해당 영역에 새로운 콘텐츠를 생성하도록 flow 모델의 샘플링 프로세스를 수정한다. 결과적으로, 첫 번째 단계에서는 지정된 영역 내에 새로운 구조를 생성하고, 두 번째 단계에서는 일관성 있는 디테일을 생성한다.
Experiments
- 데이터셋: Objaverse (XL), ABO, 3D-FUTURE, HSSD
- 약 50만 개의 고품질 3D 에셋
- 에셋당 150개의 이미지 렌더링, GPT-4o로 캡션 생성
- data augmentation: 텍스트는 다양한 길이로 요약, 이미지는 다양한 FoV로 렌더링
- 구현 디테일
- 학습
- optimizer: AdamW
- learning rate: $10^{-4}$
- CFG drop rate: 0.1
- batch size: 256
- step: 40만
- GPU: A100 40G 64개
- Inference
- CFG 강도: 3
- 샘플링 step: 50
- 학습
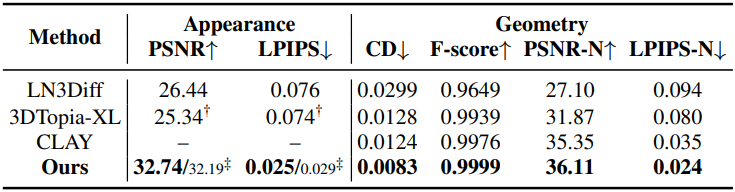
1. Reconstruction Results
다음은 재구성 성능을 비교한 결과이다.
2. Generation Results
다음은 AI가 생성한 텍스트 및 이미지 프롬프트로 생성한 3D 에셋들이다.

다음은 주어진 AI 생성 프롬프트에 대한 비교 결과이다.

다음은 Toys4k에 대한 비교 결과이다. (KD는 100배로 표기)

다음은 user study 결과이다.

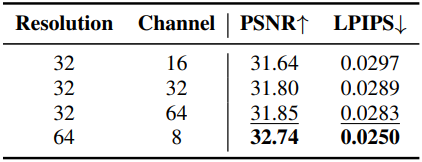
3. Ablation Study
다음은 SLAT 크기에 대한 ablation study 결과이다.
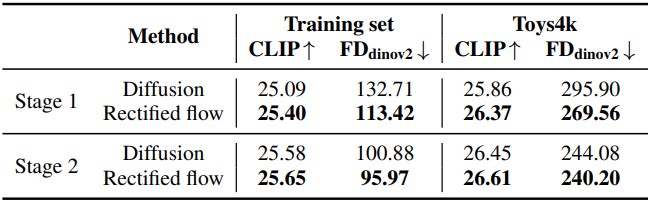
다음은 생성 패러다임에 대한 ablation study 결과이다.
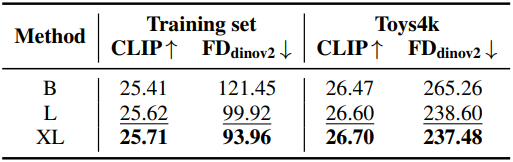
다음은 모델 크기에 대한 ablation study 결과이다.
4. Applications
다음은 주어진 구조에 대해 다양한 텍스트 프롬프트로 생성한 3D 에셋들이다.

다음은 자유로운 영역별 편집 예시이다.
