[논문리뷰] Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders
ICML 2026. [Paper] [Github]
Siqi Kou, Jiachun Jin, Zetong Zhou, Ye Ma, Yugang Wang, Quan Chen, Peng Jiang, Xiao Yang, Jun Zhu, Kai Yu, Zhijie Deng
Shanghai Jiao Tong University | Kuaishou Technology | Tsinghua University
15 Jan 2026
Introduction
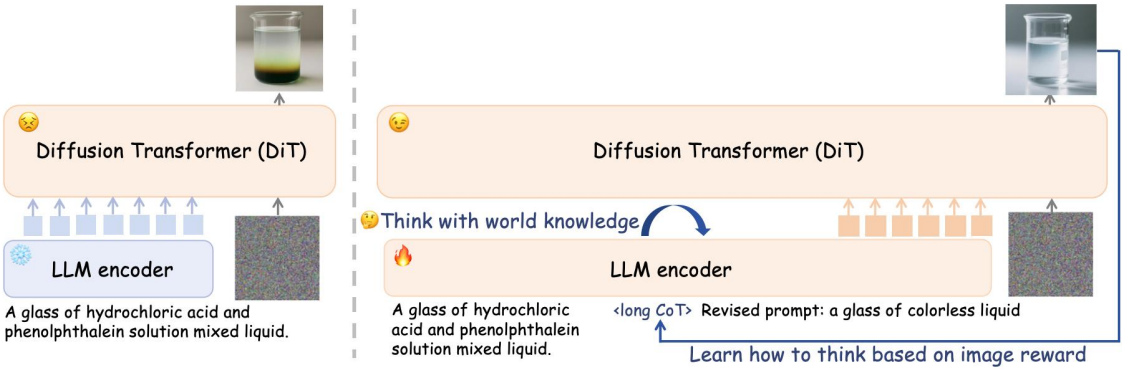
본 논문에서는 추론 기반 text-to-image diffusion을 위한 Think-Then-Generate (T2G) 패러다임을 구현하였다. 여기서 LLM 인코더는 사용자 프롬프트를 추론하고 재작성할 수 있으며, 재작성된 프롬프트의 임베딩은 DiT에 생성 조건으로 입력된다. 저자들은 이를 구현하기 위해 먼저 chain-of-thought (CoT) 추론과 재작성된 프롬프트를 포함하는 supervised fine-tuning (SFT) 데이터셋을 구축하였다. 이 데이터셋을 사용하여 LLM을 fine-tuning하여 think-then-rewrite 패턴을 획득한다.
그런 다음, 재작성된 프롬프트가 텍스트 추론과 이미지 합성을 연결하는 다리 역할을 하는 Dual-GRPO 전략을 통해 LLM 인코더와 DiT 디코더를 공동 최적화하고, end-to-end 방식으로 이미지 기반 reward를 최대화한다. 이미지 생성에서 인코더와 DiT의 역할이 서로 다르다는 점을 고려하여, 각 구성 요소에 맞게 reward objective를 조정했다. 인코더는 semantic 정렬과 개념적 이해에 최적화하고, DiT는 시각적 사실성과 미적 품질에 중점을 둔다. 이러한 최적화는 LLM에 내재된 월드 지식을 활성화할 뿐만 아니라, DiT를 텍스트 인코더의 진화된 표현 공간에 맞게 조정한다.
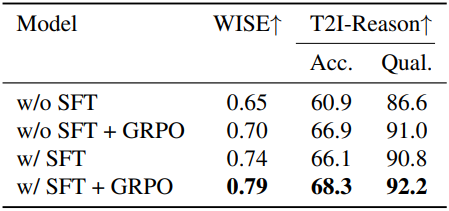
Qwen-Image에 본 방법을 적용한 결과, WISE 벤치마크에서 0.79점을 달성하여 사전 학습된 Qwen-Image보다 30% 높은 점수를 얻었다. 특히, 이 성능은 GPT-4o와 동등한 수준이다. 또한, 본 방법은 T2I-ReasonBench에서 92.2점을 달성하여 Gemini-2.0을 능가했다. 이미지 편집의 경우, Qwen-ImageEdit에 본 방법을 적용한 결과, 더욱 충실하고 세밀하며 명령에 부합하는 수정 결과를 생성할 수 있음을 정성적으로 입증했다.
Method
1. Reasoning-aware Behavior Activation
사용자 프롬프트 세트 \(Q = \{q\}\)가 주어졌을 때, 본 논문에서는 모델이 T2G 패러다임을 따르도록 하는 것을 목표로 한다. 구체적으로, 각 프롬프트에 대해 모델은 먼저 월드 지식을 활용하여 CoT 추론을 수행하고, 이를 통해 묘사될 콘텐츠를 명확하게 정의한 다음, 이 CoT를 요약하여 정제된 프롬프트를 생성한다. 이미지 생성 과정에서 정제된 프롬프트의 임베딩은 DiT의 컨디셔닝 신호로 사용된다.
저자들은 이러한 패턴을 학습시키기 위해, Gemini-2.5를 사용하여 SFT 데이터셋을 구축하였다. 이 데이터셋에 CoT 추론을 수행하도록 지시하여, 묘사될 내용을 설명적으로 추론하고 정제된 프롬프트를 생성하도록 한다. 이 선별된 데이터셋은 사용자 프롬프트 $\rightarrow$ [긴 CoT] $\rightarrow$ 정제된 프롬프트 형식을 따른다. 마지막으로, 이 선별된 데이터셋을 사용하여 텍스트 인코더를 fine-tuning한다.
Qwen2.5-VL은 T2G 패러다임에서 재작성 모델과 인코더 역할을 모두 수행한다. SFT는 Qwen2.5-VL의 재작성 기능을 활성화하지만, 인코딩 기능이 저하되는지 여부는 불분명하다. 즉, SFT가 임베딩 공간을 변경하여 DiT의 일관성 있는 이미지 생성 능력을 저해하는지 여부를 확인해야 한다.
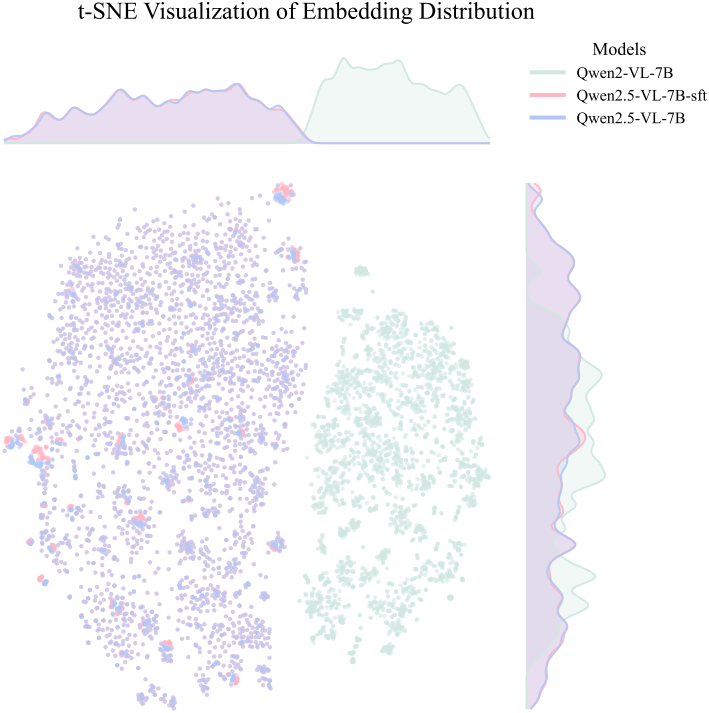
저자들은 t-SNE를 사용하여 SFT 전후의 Qwen2.5-VL 텍스트 임베딩을 시각화했다. t-SNE는 임베딩이 저차원 공간에서 겹치는지 또는 분리되는지를 보여줌으로써 분포 변화를 나타낸다. 흥미롭게도 임베딩이 완전히 겹치는 것을 보여주는데, 이는 SFT가 임베딩 공간의 분포를 보존하여 DiT가 안정적이고 합리적인 시각적 출력을 생성하는 능력을 유지함을 시사한다.
2. Dual-GRPO for LLM-DiT Composite Models
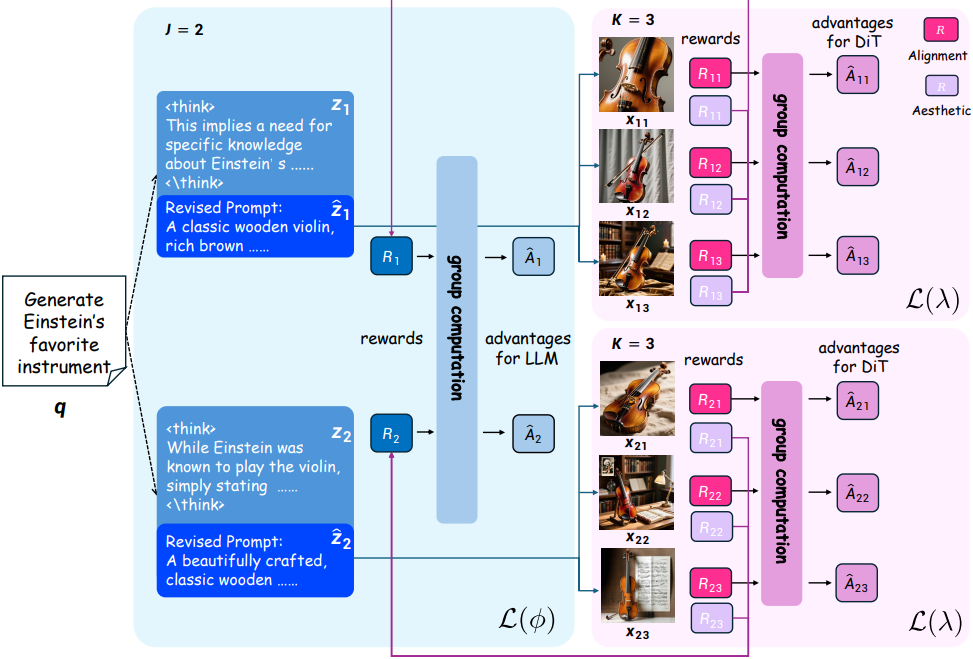
모호하거나 암시적으로 지정된 $q$가 주어졌을 때, 기존의 diffusion model은 LLM 텍스트 인코더 \(p_\phi\)를 사용하여 $q$를 latent 표현 \(p_\phi (q)\)로 인코딩한다. 이 \(p_\phi (q)\)는 DiT 디코딩의 조건 입력 \(p_\lambda\)로 사용되어 해당 이미지를 생성한다. SFT 후, LLM 인코더는 먼저 CoT 추론을 수행하여 텍스트 토큰 $\textbf{z}$를 생성하고, 이를 $\hat{\textbf{z}}$로 인코딩하여 DiT 디코딩의 조건으로 사용한다.
구체적으로, diffusion model은 \(\theta = \{\phi, \lambda\}\)로 parameterize된 복합 policy 모델로 볼 수 있다.
\[\begin{equation} \pi_\theta (o_t \mid s_t) = \begin{cases} p_\phi (z_t \mid z_{<t}, q) & t \le \ell, \\ p_\lambda (x_t \mid x_{t-1}, \hat{\textbf{z}}) & t > \ell \end{cases} \end{equation}\]그리고 rollout 궤적은 다음과 같이 표현된다.
\[\begin{equation} \textbf{o} = \{ z_1, \cdots, z_\ell x_{\ell+1}, \cdots, x_{\ell+m} \} \end{equation}\]($z_i$는 추론 예산 $\ell$을 사용하여 LLM이 $\textbf{z}$에서 생성한 $i$번째 텍스트 토큰, $x_i$는 총 반복 step이 $m$인 reverse process $\textbf{x}$의 $i$번째 예측)
Policy gradient 알고리즘을 복합 모델 \(\pi_\theta\)에 적용하기 위해 다음과 같은 objective를 최적화할 수 있다.
\[\begin{equation} \max_{\theta = \{\phi, \lambda\}} \mathbb{E}_{q \sim p(Q), \textbf{o} \sim \pi_\theta} \frac{1}{\ell + m} \left[ \sum_{t=1}^\ell R_1 (z_t, z_{<t}, q) + \sum_{t=\ell+1}^{\ell+m} R_2 (x_t, x_{t+1}, \hat{\textbf{z}}) \right] \end{equation}\]($p(Q)$는 사용자 프롬프트의 분포, $R_1$과 $R_2$는 각각 LLM과 DiT의 reward function)
GRPO 공식을 활용하기 위해 먼저 이전 policy \(\pi_{\theta_\textrm{old}}\)에서 출력 컬렉션을 샘플링한다. 구체적으로, 사용자 프롬프트 $q$가 주어지면 \(p_{\phi_\textrm{old}}\)에서 $J$개의 추론 시퀀스 \(\{\textbf{z}_j\}_{j=1}^J\)을 샘플링하고, 각 \(\hat{\textbf{z}}_j\)에 대해 \(p_{\lambda_\textrm{old}}\)에서 $K$개의 이미지 \(\{\textbf{x}_{j,k}\}_{k=1}^K\)을 샘플링한다. 이러한 계층적 샘플링 전략을 통해 한 번의 rollout 내에서 두 구성 요소 모두에 대한 group-relative advantage를 계산할 수 있다.
Dual-GRPO objective는 표준 PPO clipping 메커니즘과 KL divergence 정규화를 통합한 것이다.
\[\begin{equation} \max_{\theta = \{\phi, \lambda\}} \mathbb{E}_{q \sim p(Q), \textbf{o}_{i=1}^{J \times K} \sim \pi_{\theta_\textrm{old}}} \frac{1}{\ell + m} \left[ \sum_{t=1}^\ell \mathcal{L}_t (\phi) + \sum_{t=\ell+1}^{\ell+m} \mathcal{L}_t (\lambda) \right] \end{equation}\]\(\mathcal{L}_t (\phi)\)는 그룹 크기가 $J$인 언어 모델에 대한 표준 GRPO 공식이다.
\[\begin{equation} \mathcal{L}_t (\phi) = \frac{1}{J} \sum_{j=1}^J \left[ \min (r_{j,t} (\phi), \textrm{clip}(r_{j,t} (\phi), 1 - \epsilon, 1 + \epsilon)) \hat{A}_{j,t} \right] - \beta D_\textrm{KL} [p_\phi (z_{j,t}) \, \| \, p_{\phi_\textrm{ref}} (z_{j,t})] \\ \textrm{where} \quad r_{j,t} (\phi) = \frac{p_\phi (z_{j,t} \vert z_{j,<t}, q)}{p_{\phi_\textrm{old}} (z_{j,t} \vert z_{j,<t}, q)} \end{equation}\]LLM \(p_\phi\)에 대한 group-relative advantage \(\hat{A}_{j,t}\)는 동일한 추론 출력 \(\hat{z}_j\)에서 생성된 모든 $K$개 이미지의 reward를 집계하여 계산된다.
마찬가지로, DiT \(p_\lambda\)에 대한 loss \(\mathcal{L}_t (\lambda)\)는 추가 batch 차원 크기가 $J$이고 그룹 크기가 $K$인 Flow-GRPO 공식을 사용한다.
\[\begin{equation} \mathcal{L}_t (\lambda) = \frac{1}{J} \sum_{j=1}^J \frac{1}{K} \sum_{k=1}^K \left[ \min (r_{j,k,t} (\lambda), \textrm{clip}(r_{j,k,t} (\lambda), 1 - \epsilon, 1 + \epsilon)) \hat{A}_{j,k,t} \right] - \beta D_\textrm{KL} [p_\lambda (z_{j,t}) \, \| \, p_{\lambda_\textrm{ref}} (z_{j,t})] \\ \textrm{where} \quad r_{j,k,t} (\lambda) = \frac{p_\lambda (x_{j,k,t} \vert x_{j,k,t-1}, \hat{\textbf{z}}_j)}{p_{\lambda_\textrm{old}} (x_{j,k,t} \vert x_{j,k,t-1}, \hat{\textbf{z}}_j)} \end{equation}\]3. The Reward Function and Scheduler
GRPO를 언어 모델이나 flow matching 모델에 적용할 때, 최종 예측 결과에만 의존하는 결과 기반 reward를 사용하는 것이 일반적이며, rollout 궤적 내의 모든 중간 단계는 동일한 reward를 공유한다. 이러한 설계는 각 step이 최종 결과에 동일하게 기여한다고 암시적으로 가정하는 것으로, 궤적의 각 단계가 최종 결과의 서로 다른 측면에 영향을 미친다는 사실을 간과한다.
복합 모델이 2단계 모델이라는 점을 고려하여 각 단계의 고유한 특성에 맞는 단계별 reward function을 설계할 수 있다.
LLM 추론 단계에서 생성된 이미지의 semantic 내용 대부분은 추론 출력 \(\hat{z}\) 내에서 결정된다. 각 추론 단계에 대한 reward는 \(p_{\lambda_\textrm{old}} (\textbf{x} \mid \hat{\textbf{z}})\)에서 샘플링된 모든 $K$개의 생성된 이미지에 대한 semantic 일관성 점수 \(R_\textrm{sem}\)의 평균이다.
\[\begin{equation} R_1 (z_{j,t}, z_{j,<t}, q) = \beta_1 (\tau) \frac{1}{K} \sum_{k=1}^K R_\textrm{sem} (\textbf{x}_{j,k}, q) \end{equation}\]\(\beta_1 (\tau)\)는 reward 가중치 scheduler로, 현재 학습 step $\tau$의 함수이다. 이 scheduler를 사용하면 학습 단계별로 LLM과 diffusion model의 reward에 서로 다른 중요도를 부여할 수 있다. Advantage는 다음과 같이 계산된다.
\[\begin{equation} \hat{A}_{j,t} = \frac{R_1 (z_{j,t}, z_{j,<t}, q) - \textrm{mean}(\{R_1 (z_{j,t}, z_{j,<t}, q)\}_{j=1}^J)}{\textrm{std}(\{R_1 (z_{j,t}, z_{j,<t}, q)\}_{j=1}^J)} \end{equation}\]Diffusion 샘플링 단계에서 모델은 추론 결과를 미적으로 보기 좋고 물리적으로 일관성 있는 이미지로 렌더링해야 한다. 이전 추론 결과 \(\hat{\textbf{z}}_j\)에 컨디셔닝된 궤적 \(\textbf{x}_{j,k}\)에 대해 각 step의 reward는 최종 생성된 이미지의 미적 점수 \(R_\textrm{aes}\), 물리적 일관성 점수 \(R_\textrm{con}\), semantic 일관성 점수 \(R_\textrm{sem}\)의 가중 합으로 정의된다.
\[\begin{equation} R_2 (x_{j,k,t}, x_{j,k,t-1}, \hat{\textbf{z}}_j) = \beta_2 (\tau) (\omega_1 R_\textrm{aes} (\textbf{x}_{j,k}) + \omega_2 R_\textrm{con} (\textbf{x}_{j,k}) + \omega_3 R_\textrm{sem} (\textbf{x}_{j,k})) \end{equation}\]마찬가지로 \(\beta_2 (\tau)\)는 diffusion 샘플링 단계의 scheduler이다.
Experiments
1. Text-to-Image Generation
다음은 WISE에 대한 결과이다.
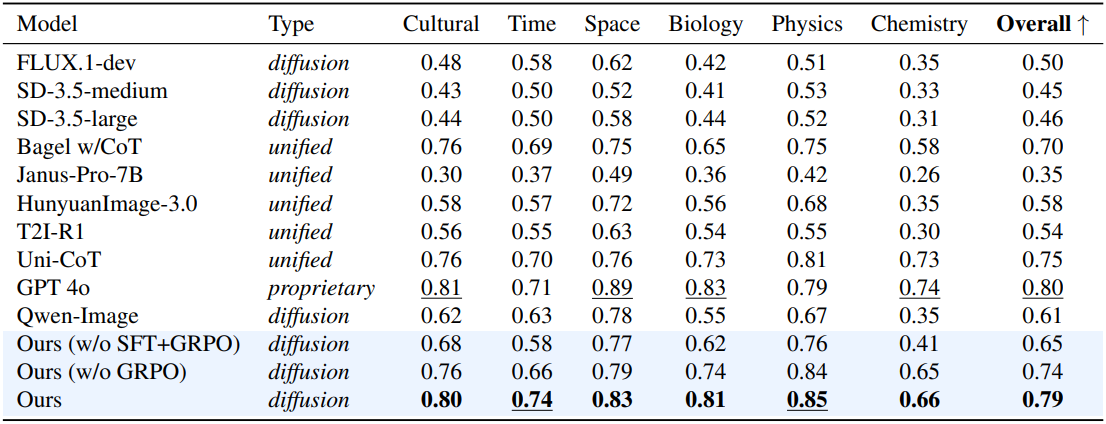
다음은 T2I-ReasonBench에 대한 결과이다.
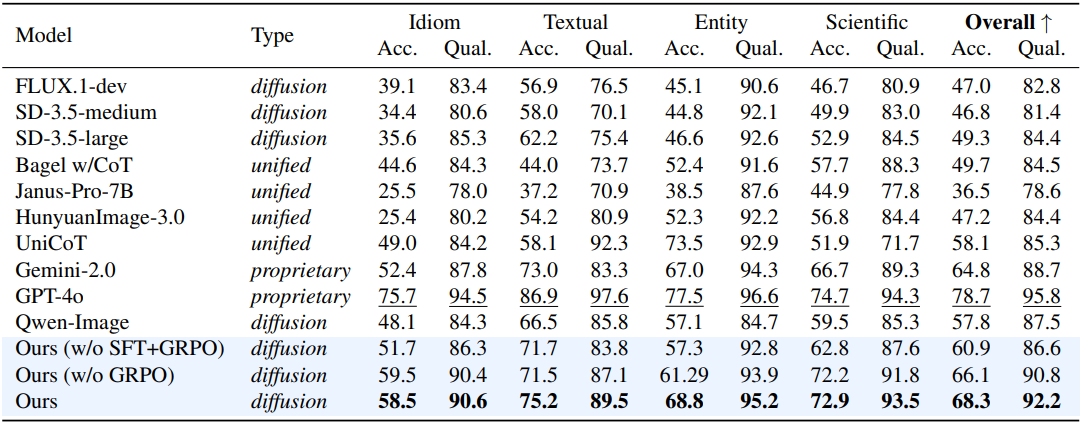
다음은 동일한 프롬프트에 대해 T2I 모델들이 생성된 이미지들을 비교한 것이다.

2. Image Editing
다음은 이미지 편집에 대한 비교 결과이다.

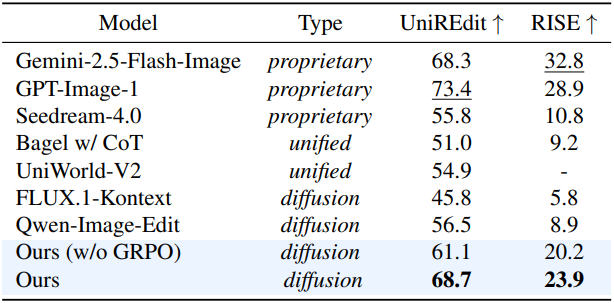
3. Ablation Studies
다음은 SFT에 대한 ablation 결과이다.