[논문리뷰] Finite Scalar Quantization: VQ-VAE Made Simple
ICLR 2024. [Paper] [Github]
Fabian Mentzer, David Minnen, Eirikur Agustsson, Michael Tschannen
Google Research | Google DeepMind
27 Sep 2023
Introduction
VQ-VAE를 학습할 때 목표는 입력 데이터의 압축된 semantic 표현을 유도하는 codebook $\mathcal{C}$를 학습하는 것이다. Forward pass에서 이미지 $x$는 표현 $z$로 인코딩되고, $z$의 각 벡터는 $\mathcal{C}$에서 가장 가까운 벡터로 quantization, 즉 대체된다. Quantization 연산은 미분 불가능하므로 디코더 입력의 gradient를 인코더 출력으로 복사하는 Straight Through Estimator (STE)를 사용하여 인코더에 대한 gradient를 생성한다. 또한 code 벡터를 quantization 되지 않은 표현 벡터로, 그리고 그 반대로 끌어당기기 위해 두 가지 보조 loss를 추가로 사용한다.
이는 최적화하기 어렵고, codebook 활용률 저하라는 잘 알려진 문제로 이어진다. 즉, $\mathcal{C}$의 크기가 증가함에 따라 많은 code가 사용되지 않게 된다. 이후 연구들은 다양한 기법을 사용하여 이 문제를 개선하고자 했다. 여기서 본 논문은 다음과 같은 목표를 가지고 원래의 VQ-VAE 공식을 단순화하는 데 관심이 있다.
- 보조 loss 제거
- 높은 codebook 활용률
- VQ를 바로 대체할 수 있도록 기능적 설정을 동일하게 유지
이를 위해 저자들은 scalar quantization으로 discrete code를 얻는 신경망 압축 논문들에서 영감을 얻었다. 즉, 표현 $z$의 각 스칼라 entry는 반올림을 통해 가장 가까운 정수로 독립적으로 quantize된다. 현재 대부분의 압축 논문에서는 정수 범위가 인코더에 의해 제한되지 않고 표현의 엔트로피에 의해서만 제한되는 unbounded scalar quantization을 사용한다. 다른 논문들에서는 quantizer의 범위를 제한하는 방식을 사용했다.
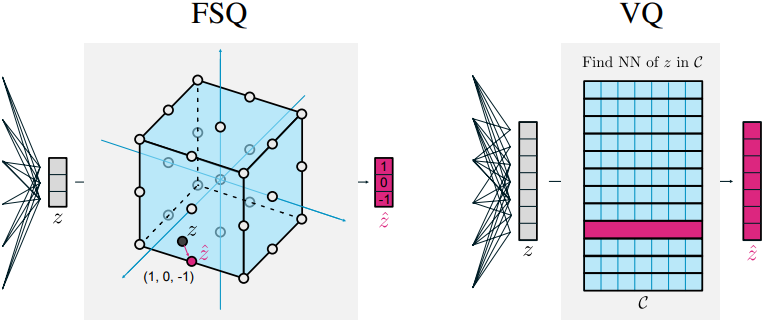
이 접근 방식을 finite scalar quantization (FSQ)라고 부른다. 중요한 통찰은 각 채널의 경계를 신중하게 선택함으로써 거의 원하는 크기의 codebook을 얻을 수 있다는 것이다. $d$개의 채널을 가진 벡터 $z$를 생각해 보자. 각 entry $z_i$를 $L$개의 값으로 매핑하면, quantize된 $\hat{z}$는 $L^d$개의 고유한 가능한 벡터 중 하나이다.
반올림 연산에 대한 gradient를 얻기 위해 VQ-VAE와 같은 STE를 사용한다. 따라서 reconstruction loss로 학습된 오토인코더 내부에 FSQ를 사용하면, 모델이 정보를 여러 quantization bin들에 분산시키도록 하는 gradient를 인코더에 전달하여 reconstruction loss를 줄일 수 있다. 결과적으로, 보조 loss 없이 모든 code를 사용하는 quantizer를 얻을 수 있다.
Method
VQ는 VQ-VAE의 고차원 latent space에서 학습 가능한 Voronoi partition을 정의하는데, 이는 VQ-VAE 입력 공간(ex. 이미지)의 복잡한 비선형 분할로 이어진다. 반면 FSQ는 훨씬 낮은 차원의 공간에서 단순하고 고정된 그리드 분할에 의존한다. VAE는 일반적인 응용 분야에서 비교적 높은 모델 용량을 가지고 있기 때문에 VQ의 비선형성이 인코더와 디코더에 흡수될 수 있다. 따라서, FSQ가 VQ와 유사한 복잡성을 가진 VAE 입력 공간 분할을 가능하게 한다.
1. Finite Scalar Quantization
$d$차원 표현 $z \in \mathbb{R}^d$가 주어졌을 때, 본 논문의 목표는 $z$를 유한한 code 집합으로 quantize하는 것이다. 이를 위해 먼저 bounding function $f$를 적용한 다음 정수로 반올림한다. 각 채널/entry가 $L$개의 고유한 값 중 하나를 취하도록 $f$를 선택한다.
\[\begin{equation} \hat{z} = \textrm{round}(f(z)) \\ \textrm{where} \quad f(z) = \lfloor L/2 \rfloor \textrm{tanh} (z) \end{equation}\]따라서 $\hat{z} \in \mathcal{C}$가 되는데, 여기서 $\mathcal{C}$는 이러한 채널별 codebook 집합의 곱으로 주어지는 codebook이며, 크기가 $\vert \mathcal{C} \vert = L^d$이다. $\mathcal{C}$의 벡터는 간단히 열거할 수 있으며, 이를 통해 임의의 $\hat{z}$에서 \(\{1, \ldots, L^d\}\)의 정수로의 일대일 대응이 가능하다. 따라서 VQ가 일반적으로 사용되는 모든 경우에 VQ를 FSQ로 대체할 수 있으며, 이때 VQ 이전과 이후 layer의 출력 및 입력 차원을 각각 적절히 조정해야 한다. $i$번째 채널이 $L_i$개의 값으로 매핑되는 경우로 일반화하면 \(\vert \mathcal{C} \vert = \prod_{i=1}^d L_i\)가 된다.
반올림 연산 전체에 걸쳐 gradient를 전파하기 위해 기울기를 1로 대체하는 STE를 사용한다. 이를 stop gradient (sg) 연산을 통해 쉽게 구현할 수 있다.
\[\begin{equation} \textrm{round_ste} (x) = x + \textrm{sg} (\textrm{round}(x) - x) \end{equation}\]2. Hyperparameters
FSQ는 채널 수 $d$와 채널당 레벨 수 $\mathcal{L} = [L_1, \ldots, L_d]$로 정의되는 hyperparameter를 가지고 있다. $d$와 $L_i$의 다양한 조합으로 동일한 codebook 크기를 만들 수 있다. 본 논문에서는 공정한 비교를 위해 FSQ로 대체하고자 하는 VQ codebook의 크기에 맞게 $d$와 $L_i$를 선택하였다. 저자들은 다양한 조합을 탐색했으며, 모든 선택이 최적의 결과를 가져오는 것은 아니라는 것을 발견했다. 그러나 모든 $i$에 대해 $L_i \ge 5$가 되도록 설정하면 모든 task에서 우수한 성능을 보였다.

3. Parameter Count
FSQ는 VQ보다 파라미터 수가 적다. VQ에서는 $\vert \mathcal{C} \vert \cdot d$ 크기의 codebook을 학습한다. 예를 들어, $\vert C \vert = 4096$이고 $d= 512$인 경우, 200만 개의 파라미터가 필요하지만, FSQ는 이 정도의 파라미터 수를 필요로 하지 않는다. 또한, FSQ의 경우 $d$가 VQ보다 훨씬 작기 때문에, FSQ 학습 시 최종 인코더 layer의 파라미터 수도 더 적다.
Experiments
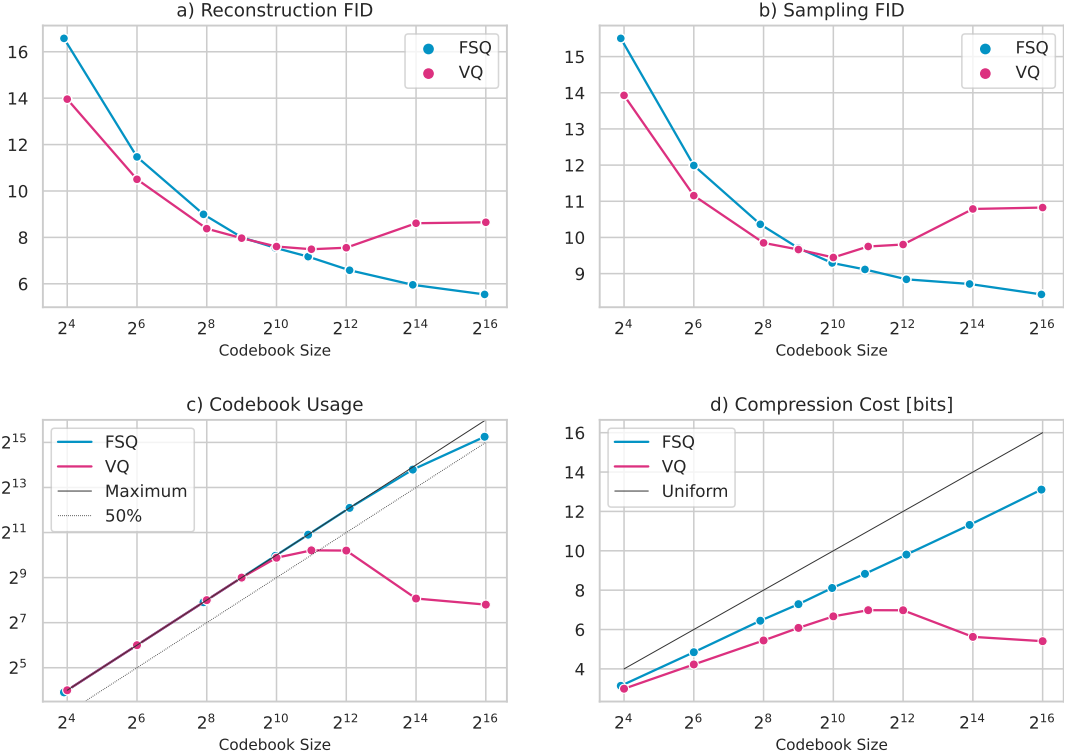
1. Tradeoff Study
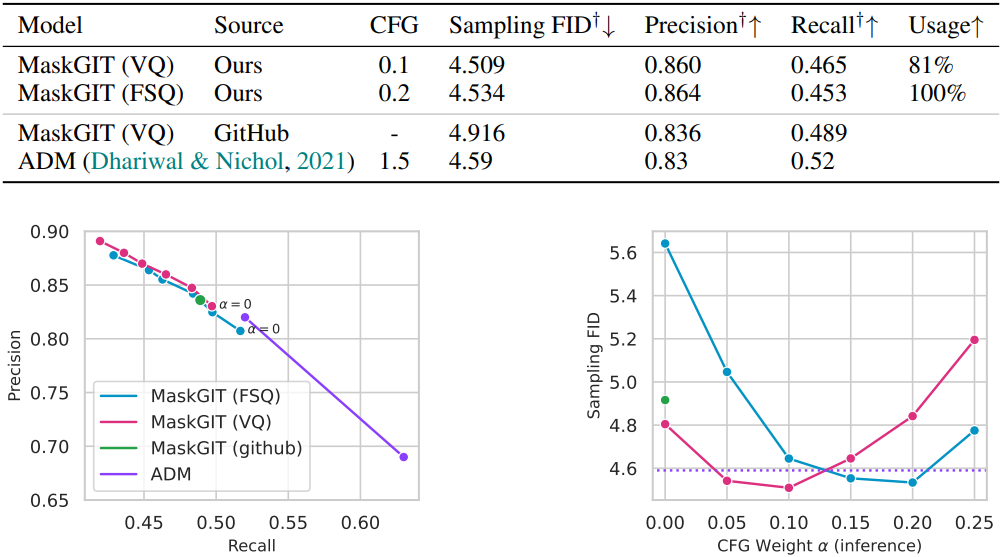
2. MaskGIT

3. UViM