[논문리뷰] VGGT-Ω
CVPR 2026 (Oral). [Paper] [Page] [Github]
Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schönberger, Patrick Labatut, Piotr Bojanowski, David Novotny, Andrea Vedaldi, Christian Rupprecht
Visual Geometry Group, University of Oxford | Meta AI
14 May 2026
Introduction
본 논문에서는 VGGT보다 훨씬 더 큰 데이터와 더 큰 모델 크기로 feed-forward reconstruction을 scaling할 수 있는 VGGT-Ω를 소개한다.
VGGT와 비교했을 때, VGGT-Ω는 register 사용 방식을 비롯한 여러 아키텍처적 개선 사항을 도입했다. ViT는 글로벌 정보를 전달하기 위해 적은 수의 이미지 토큰을 사용하기 때문에, 이를 보다 직접적이고 효율적으로 수행하기 위해 학습 가능한 register를 도입했다. VGGT는 이미 프레임별 register를 가지고 있지만, VGGT-Ω는 여기에 register attention을 추가했다. Register attention은 global attention layer의 일부 영역에서 프레임 간 정보 교환을 register로 제한한다. 업데이트된 register는 frame attention layer 내에서 다른 토큰과 로컬로 상호 작용하여 여러 프레임 정보를 집계하고 재분배한다. 이러한 설계는 register가 장면 전체에 대한 정보를 집계하도록 유도하며, 이러한 토큰을 장면 토큰이라고 부른다.
이 설계에는 두 가지 이점이 있다.
- Register는 유용한 글로벌 정보를 담고 있다. 특히, 명시적인 학습 없이도 register는 VLA 모델과 언어 정렬에 유용한 feature를 제공한다.
- Register attention은 효율성도 향상시킨다. Global attention은 VGGT에서 주요 계산 병목이지만, attention map은 매우 sparse하다. Register attention은 글로벌 정보를 통합함으로써 global attention을 효율적으로 대체할 수 있다. Global attention layer의 25%를 register attention으로 대체해도 성능 저하는 거의 발생하지 않으면서 학습 과정에서 FLOPs는 약 23%, 메모리는 16% 절감된다.
또한 저자들은 DPT head의 고해상도 convolutional layer가 모델 파라미터 중 극히 일부만을 차지함에도 불구하고 forward activation을 저장하는 데 GPU 메모리를 과도하게 소모한다는 점에 주목했다. 따라서 두 번째 변경 사항은 DPT head에서 메모리 사용량이 가장 많은 convolutional layer를 MLP 1개와 pixel-shuffle 연산자로 대체하는 것이다. 이 방식은 성능 저하 없이 메모리 사용량을 최소화한다.
저자들은 VGGT에서 depth map, point map, tracking feature를 직접 학습시키는 multi-task training이 유익하다는 것을 보여주었다. 이러한 이점을 얻기 위해 추가적인 dense head가 불필요하다. 세 번째 변경 사항은 multi-task loss들을 계속 사용하되, 깊이 예측에는 하나의 dense head만, 카메라 예측에는 하나의 sparse head만 유지하는 것이다.
이 세 가지 변경 사항은 학습 중 GPU 메모리를 70% 절약하고 inference 속도를 약간 향상시킨다.
효율성 외에도, 저자들은 학습 데이터의 양, 다양성, 그리고 품질이 scalability에 매우 중요하다는 것을 발견했다. 특히, 동적 콘텐츠 처리는 동영상을 훨씬 더 많이 학습에 활용할 수 있게 해주기 때문에 필수적이다. 따라서, 저자들은 고정된 동영상과 동적 동영상 모두에 대해 대규모로 주석을 생성할 수 있는 고품질 데이터 주석 생성 파이프라인을 개발했다. 이 파이프라인은 VLM 기반 사전 필터링, VGGT, COLMAP, 최신 이미지 매칭 모델, 그리고 기하학적 사후 필터링을 통합한다. 기존 데이터셋과 결합하면, 정확한 주석이 달린 총 400만 개의 다양한 장면/시퀀스를 얻을 수 있으며, 이는 VGGT보다 15배 이상 많은 수치이다.
저자들은 일반화 성능을 더욱 향상시키기 위해 self-supervised learning 프로토콜을 도입하였다. Teacher 모델과 student 모델은 supervised learning으로 학습된 VGGT-Ω 체크포인트에서 초기화된다. 두 모델은 서로 다른 augmentation과 프레임 순열을 적용하여 동일한 입력 시퀀스를 처리한다. Student 모델은 프레임 순서를 정렬한 후 teacher 모델의 예측 및 feature 분포와 일치하도록 학습되고, teacher 모델은 student 모델의 EMA를 통해 업데이트된다. 이 프로토콜을 사용하여 1,800만 개의 레이블이 없는 동영상을 학습시켰다.
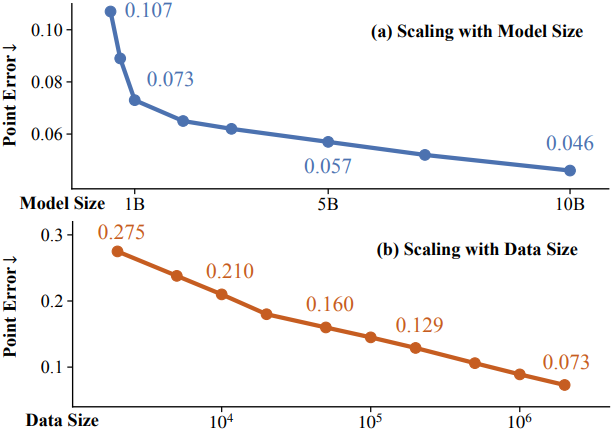
저자들은 이러한 개선을 통해 feed-forward reconstruction 모델의 scaling 특성을 조사할 수 있었다. 모델 크기를 0.2B에서 10B 파라미터로 늘리고 학습 데이터를 수천 개에서 2백만 개의 서로 다른 시퀀스로 확장함에 따라 reconstruction 정확도가 일관되게 power law와 비슷하게 향상되는 것을 관찰할 수 있다.
Method
1. A New Scalable Architecture
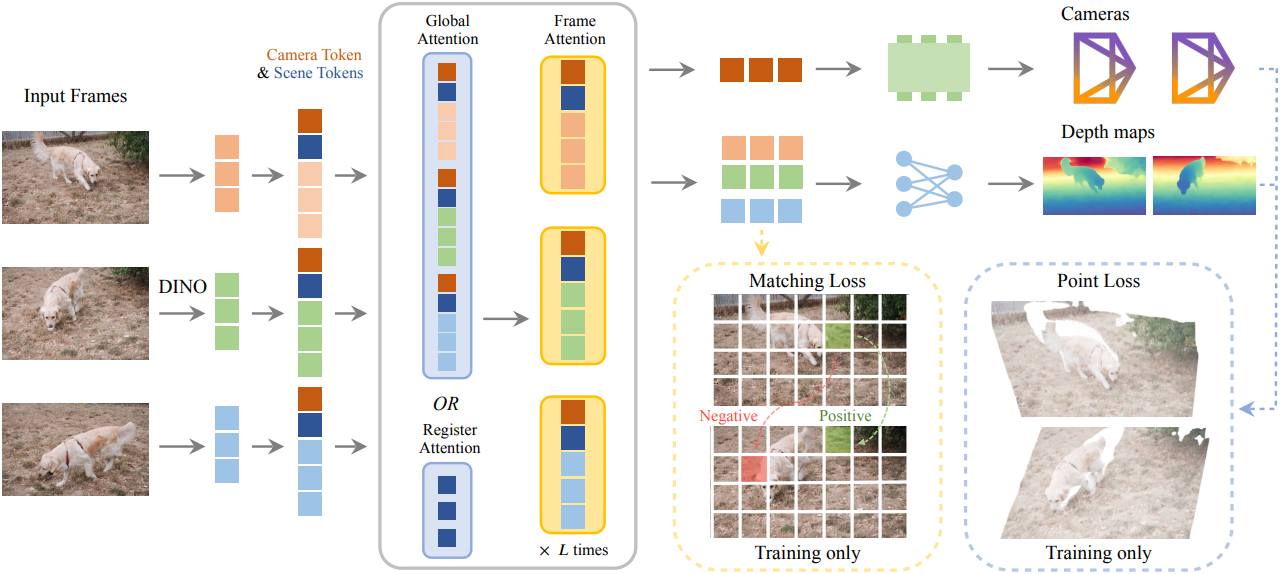
VGGT-Ω는 $N$개의 입력 이미지 \(I_1, \ldots, I_N \in \mathbb{R}^{3 \times H \times W}\)를 해당 카메라 및 depth map으로 매핑하는 feed-forward transformer $f$이다.
\[\begin{equation} ((\textbf{g}_1, D_1), \ldots, (\textbf{g}_N, D_N)) = f (I_1, \ldots, I_N) \end{equation}\]($D_i \in \mathbb{R}^{H \times W}$는 depth map, \(\textbf{g}_i = (\textbf{q}_i, \textbf{t}_i, \textbf{f}_i) \in \mathbb{R}^9\)는 rotation quaternion \(\textbf{q}_i \in \mathbb{R}^4\), translation \(\textbf{t}_i \in \mathbb{R}^3\), FOV \(\textbf{f}_i \in \mathbb{R}^2\)의 concat)
Principal point는 이미지의 중심에 있다고 가정한다. 따라서 문제 정의는 VGGT와 유사하지만, 모델이 point map이나 tracking feature를 직접 예측하지는 않는다. 네트워크 $f$는 각 이미지를 토큰으로 인코딩하고, alternating attention을 사용하여 여러 시점의 feature를 통합하고, 경량 head를 사용하여 토큰을 최종 예측값으로 매핑한다.
1.1 Feature Extraction and Tokenization
각 이미지 $I_i$는 DINOv3로 초기화된 ViT를 사용하여 tokenize되어
\[\begin{equation} \textbf{z}_i^F = \textrm{DINO} (I_i) \in \mathbb{R}^{H^\prime W^\prime \times C} \\ \textrm{where} \; H^\prime = H/r, W^\prime = W/r \end{equation}\]를 얻는다. 각 이미지 $I_i$에는 카메라 토큰 \(\textbf{z}_i^\textrm{cam} \in \mathbb{R}^{1 \times C}\)와 16개의 장면 토큰 (register) \(\textbf{z}_i^\textrm{scene} \in \mathbb{R}^{16 \times C}\)도 추가된다. 카메라 토큰은 카메라 파라미터를 예측하는 데 사용되고, register는 장면에 대한 정보를 집계한다.
또한, VGGT와 마찬가지로 카메라 토큰과 register는 두 가지 학습 가능한 파라미터 중 하나를 가질 수 있는데, 하나는 이미지 $I_i$가 레퍼런스 이미지인 경우이고 다른 하나는 그렇지 않은 경우이다. 이러한 토큰들은 concat되어 토큰 집합 $\textbf{z}$를 형성한다.
\[\begin{equation} \textbf{z} = (\textbf{z}_1, \ldots, \textbf{z}_N) \in \mathbb{R}^{N \times (H^\prime W^\prime + 17) \times C} \\ \textrm{where} \quad \textbf{z}_i = (\textbf{z}_i^F, \textbf{z}_i^\textrm{cam}, \textbf{z}_i^\textrm{scene}) \end{equation}\]1.2 Register Attention
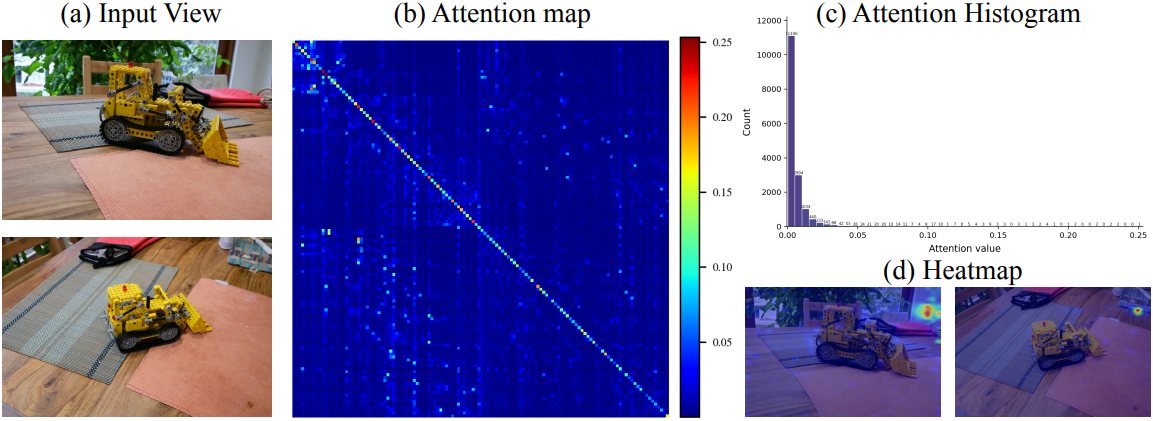
VGGT는 각 이미지 내의 frame-wise self-attention과 모든 이미지에 걸친 global self-attention을 번갈아 적용되는 alternating-attention 방식을 사용한다. Global attention은 서로 다른 프레임들이 상호 작용하는 부분이며, 따라서 여러 프레임 장면 정보가 형성되는 부분이다. 동시에, global attention은 모든 프레임의 모든 토큰에 attention하기 때문에 계산 비용이 많이 들며, 그 비용은 전체 토큰 수의 제곱에 비례한다. 또한, 아래 그림에서 볼 수 있듯이 global attention map은 일반적으로 sparse한데, 이는 적은 수의 토큰만으로도 해당 정보를 교환하기에 충분할 수 있음을 시사한다.
따라서 저자들은 global attention layer의 25%를 register attention으로 대체했다. Register attention에서는 self-attention이 모든 프레임의 register로 제한된다. 구체적으로, register attention은 register만 업데이트한다.
즉, 이 block에서는 register만 self-attention에 참여한다. 업데이트된 register는 이후 frame-wise attention block에서 각 프레임의 이미지 토큰과 상호 작용하여 집계된 장면 정보를 이미지 토큰으로 다시 재분배한다. 이는 최종 register가 글로벌 장면 정보를 보유하도록 유도하는 동시에 global attention의 비용을 줄인다.
1.3 Decoding
Attention layer에서 생성된 최종 토큰 집합 \(\textbf{z}^\prime = (\textbf{z}_1^\prime, \ldots, \textbf{z}_N^\prime)\)은 depth map과 카메라로 디코딩된다.
Depth
VGGT에서 dense한 출력을 위한 모든 디코더는 DPT layer들로 구현된다. 그러나 이러한 DPT head의 최종 convolutional block은 메모리 사용량이 많은 고해상도 feature map을 여러 개 유지한다. 이러한 비용을 줄이기 위해 입력 해상도의 1/4 이상에서 작동하는 block을 MLP 1개와 pixel-shuffle 연산자를 사용하는 경량 업샘플링 head로 대체한다. MLP는 32 채널을 출력하고, pixel-shuffle 연산자는 이 채널들을 $H^\prime \times W^\prime \times 32$에서 $4H^\prime \times 4W^\prime \times 2$로 재배열한다. 두 출력 채널은 깊이와 신뢰도에 해당한다.
또한, 저자들은 토큰을 MLP만을 사용하여 dense한 예측으로 매핑하는 디코더도 살펴보았다. 이 방식은 벤치마크에서는 잘 작동하지만, 특히 하늘이나 산과 같이 깊이가 무한하고 명확하게 정의되지 않는 원거리 구조물이 있는 야외 장면에서 예측된 depth map에 블록 형태의 아티팩트가 발생하는 문제가 있다. 따라서, 계산 비용이 저렴한 초기 저해상도 convolutional layer는 유지했다.
카메라
카메라 \((\textbf{g}_1, \ldots, \textbf{g}_N)\)는 카메라 토큰과 register \(\{(\textbf{z}_i^\textrm{cam}, \textbf{z}_i^\textrm{scene})\}_{i=1}^N\)에 가벼운 transformer를 적용한 후, 각 업데이트된 카메라 토큰에 MLP를 적용하여 공동으로 예측한다. VGGT와 달리, 카메라 head는 반복적인 개선 없이 한 번의 pass로 카메라 파라미터를 예측한다.
2. Training Losses
VGGT에서는 중복되는 dense head를 예측하는 것이 유익하였지만, 이는 학습 과정에서 많은 비용을 발생시킨다. 따라서 VGGT-Ω는 깊이 예측을 위한 하나의 dense head만 포함한다. 모델이 point map과 track을 직접 예측하지는 않지만, 관련 loss들을 통해 이러한 양들을 관리한다. 이를 통해 여러 개의 dense head를 사용하는 것과 거의 동일한 성능을 얻으면서 상당한 메모리 사용량을 절약할 수 있다.
다음과 같은 loss를 최적화한다.
\[\begin{equation} \mathcal{L} = \lambda_\textrm{cam} \mathcal{L}_\textrm{cam} + \lambda_\textrm{depth} \mathcal{L}_\textrm{depth} + \lambda_\textrm{point} \mathcal{L}_\textrm{point} + \lambda_\textrm{match} \mathcal{L}_\textrm{match} \end{equation}\]Camera loss
Camera loss \(\mathcal{L}_\textrm{cam}\)은 예측된 카메라 \(\hat{\textbf{g}}_i\)와 GT \(\textbf{g}_i\)를 \(\ell_1\) loss로 비교하며, VGGT에서 사용되는 Huber loss보다 더 안정적이다.
\[\begin{equation} \mathcal{L}_\textrm{cam} = \sum_{i=1}^N \vert \hat{\textbf{g}}_i - \textbf{g}_i \vert \end{equation}\]Depth loss
VGGT를 따라, depth loss는 확률적 불확실성과 gradient 일관성 항을 사용한다. 또한, GT에 대한 상대적 scale을 고려한다.
\[\begin{equation} \mathcal{L}_\textrm{depth} = \sum_{i=1}^N \left[ \| c_i^D \odot (1 + D_i^{-1}) \odot e_i \| + \| c_i^D \odot \nabla e_i \| \right] - \alpha \sum_{i=1}^N \log c_i^D \\ \textrm{where} \quad e_i = \hat{D}_i - D_i \end{equation}\]($c_i^D$는 uncertainty map, $\odot$은 element-wise product)
Point loss
Point map은 각 픽셀에 기준 카메라 프레임에서 해당하는 3D 점의 좌표를 할당한다. 따라서 point map은 unprojection $\pi^{-1}$을 통해 depth map과 카메라 파라미터로부터 추론할 수 있다. Point loss \(\mathcal{L}_\textrm{point}\)는 residual $e_i$를
\[\begin{equation} e_i = \pi^{-1} (\hat{D}_i, \hat{\textbf{g}}_i) − P_i \end{equation}\]로 대체하는 것을 제외하면 \(\mathcal{L}_\textrm{depth}\)와 동일하다.
Matching loss
Matching loss \(\mathcal{L}_\textrm{match}\)는 마지막 attention layer에서 출력된 토큰에 적용되며, 동일한 3D 위치에 해당하는 positive 토큰 쌍의 feature를 서로 끌어당기고 negative 쌍의 feature를 서로 밀어낸다.
\[\begin{equation} \mathcal{L}_\textrm{match} = \mathbb{E}_\textrm{pos} [-\log \sigma (s)] + \mathbb{E}_\textrm{neg} [-\log (1 - \sigma(s))] \end{equation}\]($s$는 \(\ell_2\) 정규화된 토큰 간의 코사인 유사도, $\sigma$는 sigmoid)
3. Dynamic Reconstruction
VGGT-Ω는 동적 장면 재구성을 지원하며, 이는 훨씬 더 많은 학습 데이터를 활용할 수 있게 해준다. 동적 재구성에는 움직임을 제한하는 통계적 prior가 필요하다. VGGT-Ω와 같은 데이터 기반 모델은 데이터로부터 좋은 prior를 학습할 수 있는 잠재력을 가지고 있다. 그러나 출력 표현 방식은 카메라 움직임과 장면 움직임의 결합 방식을 결정한다. 따라서 본 논문에서는 depth map과 카메라 파라미터만 예측하고 모션 마스크와 같은 명시적인 동적 출력은 피하였다.
4. Self-supervised Training
저자들은 레이블이 없는 동영상을 사용한 self-supervised learning을 위해 teacher-student 전략을 사용하였다. 구체적으로, gradient descent로 업데이트되는 student 네트워크와, student 네트워크의 EMA로만 업데이트되는 teacher 네트워크를 유지한다. 두 네트워크 모두 supervised learning으로 학습된 VGGT-Ω 체크포인트를 사용하여 초기화된다.
동영상 시퀀스가 주어지면, 동일한 프레임 세트를 두 네트워크에 입력하지만, color jittering, blurring, 랜덤 90° 회전, 랜덤 패치 마스킹, 랜덤 프레임 순서 변경 (참조 프레임 선택에 영향을 줌) 등의 독립적인 확률적 augmentation을 적용한다. 두 스트림을 공통 순서로 복원한 후, student 네트워크가 두 가지 방식으로 teacher 네트워크와 일치하도록 요구한다.
- \(\ell_2\) feature-matching loss: 여러 layer에 걸쳐 student 네트워크의 토큰과 teacher 네트워크의 토큰을 정렬한다
- Regression loss: 카메라 및 깊이 정보를 학습시킨다.
붕괴를 방지하기 위해 self-supervised learning 동안 camera head와 depth head는 고정된다. 이 distillation 방식은 외형 변화 및 프레임 순서에 대한 불변성을 보장하여 레이블이 없는 수백만 개의 동영상으로부터 효과적인 학습을 가능하게 한다.
Experiments
- 데이터셋
- Aria, Bedlam, BEHAVIOR-1K, Co3Dv2, uCo3D, DL3DV, Dynamic Replica, EDEN, EFM3D, HOT3D, Habitat, Hypersim, Mapfree, Mapillary Metropolis, MPSD, Megadepth, Megasynth, Mid-Air, Mvssynth, ParallelDomain-4D, Replica, SAIL-VOS, ScanNet Series, TartanAirV2, TartanGround, Taskonomy, UnrealStereo4K, Virtual KITTI, Waymo, WildRGBD
- VGGT에서 사용했던 Kubric과 PointOdyssey는 배경 geometry가 가짜라 제외
- 총 약 300만 개의 시퀀스가 포함, 각 시퀀스에는 10 ~ 20,000개 사이의 이미지가 포함
- 데이터 주석 생성 파이프라인
- 4천만 개의 원본 동영상을 수십만 개 규모의 고품질 3D 학습 데이터로 정제
- VLM 기반 사전 필터링 → 동적 object 제거 → feature matching, tracking → COLMAP, VGGT 기반 reconstruction → 멀티뷰 일관성 검증 → classifier 기반 품질 필터링
- 구현 디테일
- 모델 크기: 200M, 500M, 1B, 10B
- alternating-attention block 수: 12, 12, 24, 16
- hidden dimension 크기: 384, 768, 1024, 4096
- optimizer: AdamW
- iteration: 24만 (supervised 16만, self-supervised 5만, supervised 3만)
- learning rate
- supervised $2 \times 10^{-4}$, self-supervised $1 \times 10^{-4}$
- 5% linear warm-up + 95% cosine decay
- 각 batch 마다 [1, 24]에서 프레임 수 샘플링
- 종횡비: [0.33, 1.33]에서 샘플링, 픽셀 수가 512$\times$512에 가깝게 유지
- GPU: H100 96GB 128개
1. Benchmarking
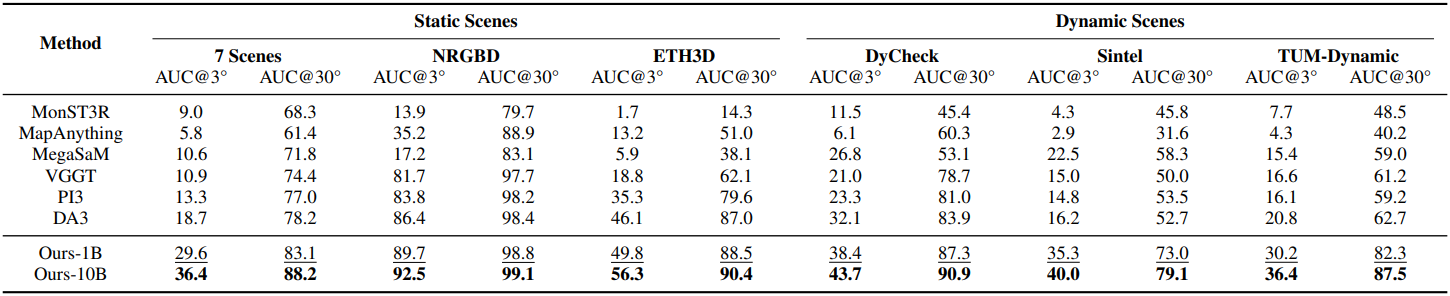
다음은 카메라 포즈 추정 결과이다.
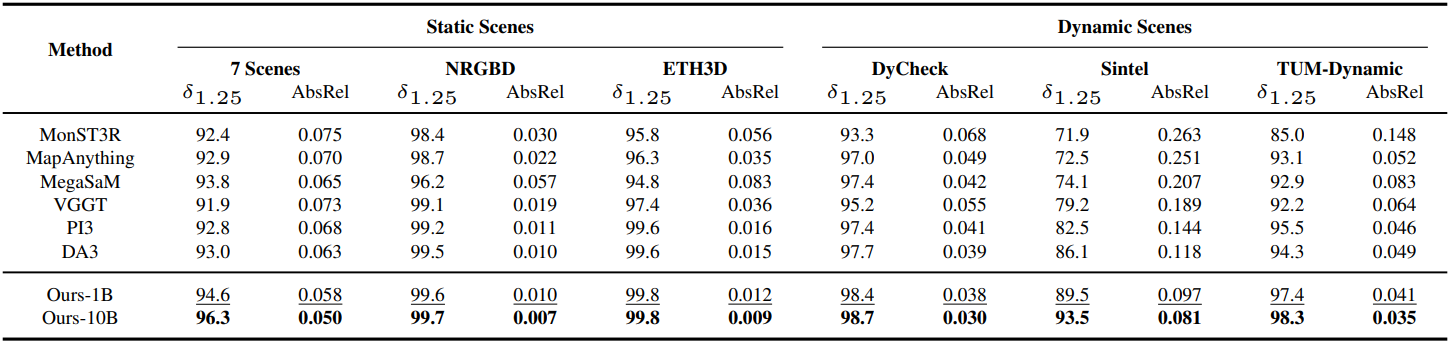
다음은 깊이 추정 결과이다.
다음은 여러 정적/동적 장면들에 대한 reconstruction 결과이다.

다음은 MegaSaM과의 비교 결과이다.

다음은 Depth Anything 3과의 비교 결과이다.

다음은 메모리 및 inference 속도 비교 결과이다.
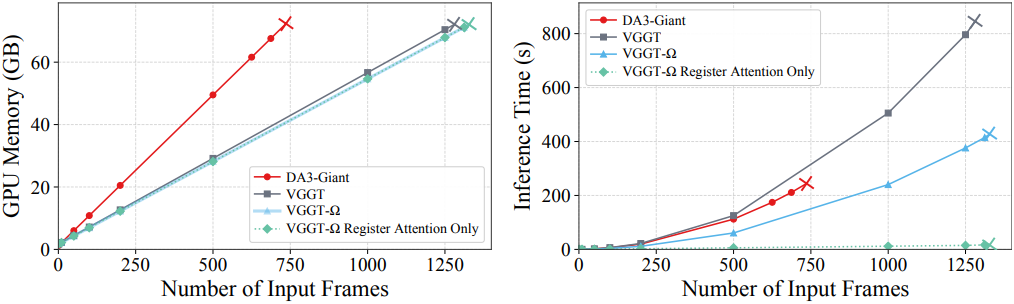
2. Applications of Registers
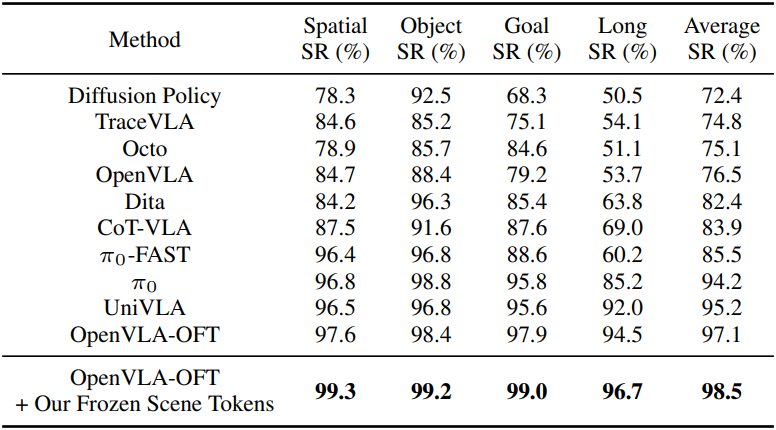
다음은 OpenVLA-OFT 입력 토큰에 VGGT-Ω의 register를 concat하여 OpenVLA-OFT를 학습시켰을 때의 결과이다.