[논문리뷰] Residual Primitive Fitting of 3D Shapes with SuperFrusta
CVPR 2026 (Oral). [Paper] [Page] [Github]
Aditya Ganeshan, Matheus Gadelha, Thibault Groueix, Zhiqin Chen, Siddhartha Chaudhuri, Vladimir Kim, Wang Yifan, Daniel Ritchie
Brown University | Adobe Research
9 Dec 2025
Introduction
3D shape으로부터 primitive를 추론하는 것은 재구성 정확도와 간결성 사이의 근본적인 trade-off가 있다. 높은 정확도를 우선시하는 접근 방식은 종종 겹치는 primitive들의 조밀하고 중복된 구성을 생성한다. 반대로, 간결성을 강조하는 방법은 미세한 기하학적 디테일이나 곡선 구조를 포착하지 못할 수 있다. 이러한 trade-off는 두 가지 요인에 기인한다.
- 직육면체, superquadrics, 타원체와 같은 일반적으로 사용되는 primitive들은 3D 에셋의 풍부한 shape 다양성을 모델링하기 위해 많은 인스턴스를 필요로 할 수 있다.
- Inference 절차 자체에 명확한 한계가 있다. 입력 데이터의 완전한 분할을 먼저 수행하는 방법은 고정된 분할에 의존하는데, 이는 primitive가 효율적으로 표현할 수 있는 범위와 일치하지 않을 수 있다. 따라서 초기 segmentation 오차가 최종 결과물에 직접 전파되어 프로세스가 불안정해진다. 반면, 최적화 기반 접근 방식은 다양한 primitive을 처음부터 모델링해야 하는데, 이 경우 매우 non-convex한 loss landscape를 다루어야 한다.
이러한 한계를 해결하기 위해, 본 논문에서는 표현력이 뛰어난 primitive와 robust한 inference 전략을 결합한 프레임워크를 제시하였다. 핵심은 SuperFrustum이라는 analytic primitive이다. 기존 primitive들은 일반적으로 표현력, 편집 가능성, 최적화 가능성이라는 세 가지 핵심 요건 중 하나 또는 두 가지만 충족하는 경우가 많았다. 이와 대조적으로, SuperFrustum은 다음과 같은 장점이 있다.
- 원기둥, 원뿔, 구, 그리고 이들의 점점 가늘어지는 변형 또는 굽은 변형과 같은 일반적인 입체 도형을 포괄한다.
- 단 8개의 파라미터로 간결하게 parameterize된다.
- 모든 파라미터에 대해 미분 가능한 SDF를 허용하여 부드러운 블렌딩과 효과적인 inverse modeling을 가능하게 한다.
간결한 어셈블리를 구현하려면 표현력이 풍부한 primitive와 그에 걸맞게 효과적인 inference 알고리즘이 필요하다. 본 논문에서는 매우 non-convex한 reconstruction loss를 효과적으로 처리하기 위해 글로벌한 shape 분석과 로컬한 primitive 최적화를 긴밀하게 결합한 unsupervised 방식인 Residual Primitive Fitting (ResFit)을 제안하였다. ResFit은 처음부터 많은 수의 primitive를 동시에 최적화하는 대신, 먼저 입력 geometry를 분석하여 글로벌한 단서를 기반으로 초기 구조를 제안한다. 그런 다음 gradient descent를 통해 이러한 primitive를 로컬 geometry에 맞게 정제한다. 최종 어셈블리를 타겟 shape에서 빼고, 남은 residual 부분에 대해 이 과정을 반복한다. 글로벌 구조 제안과 로컬 파라미터 최적화를 번갈아 수행함으로써, ResFit은 두 신호가 서로 영향을 주고받도록 하여 간결하면서도 높은 정확도를 가진 어셈블리를 생성한다.
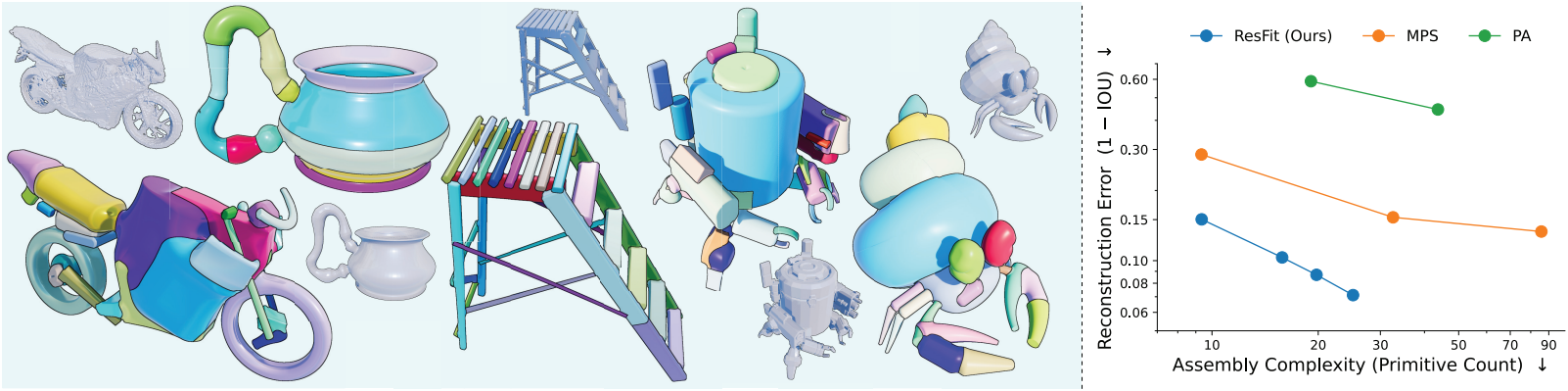
SuperFit은 다양한 3D 벤치마크에서 새로운 SOTA를 달성하였다. 기존 연구 대비 거의 절반의 primitive만을 사용하면서도 IoU를 9점 이상 향상시켜 일관적으로 더 높은 충실도의 재구성을 생성하며, 충실도와 간결성 사이의 경계를 근본적으로 변화시켰다.
Method
Primitive 어셈블리 inference task를 다음과 같이 정의한다. 3D shape $x$가 주어졌을 때, 실행 결과 $E(z)$가 입력 shape을 재구성하는 analytic primitiv들로 구성된 primitive 어셈블리 $z$를 추론하는 것이 목표이다. 각 $z$는 합성 연산자를 통해 결합되어 닫힌 표면 $E(z)$를 생성하는 primitive 시퀀스 \(\{f_{\theta_i}\}_{i=1}^{\vert z \vert}\)를 정의한다. 즉, 다음과 같은 objective를 최대화하는 것을 목표로 한다.
\[\begin{equation} z^\ast = \underset{z}{\arg \max} \mathcal{O}(x, z) \\ \mathcal{O}(x, z) = \mathcal{R} (x, E(z)) - \alpha \vert z \vert \end{equation}\]($\mathcal{R}$은 입력 shape $x$와 $E(z)$ 사이의 reconstruction 정확도를 측정하고, \(\vert z \vert\)는 primitive 수, $\alpha$는 정확도와 간결성 사이의 균형을 조절)
따라서 $\mathcal{O}$를 최대화하는 것은 적은 수의 표현 요소로 geometry를 설명하는 간결한 $z$를 선호한다.
1. ResFit : Residual Primitive Fitting
순수 최적화 기반 방법은 종종 얽힌 reconstruction 결과를 생성하는 반면, 분석 기반 접근 방식은 primitive의 표현 능력을 고려하지 않고 shape을 분할한다. 이로 인해 geometry 분석(하향식)과 primitive 표현(상향식) 사이에 단절이 발생한다. Residual Primitive Fitting (ResFit)은 shape 분석과 어셈블리 최적화를 상호 작용시켜 각 단계가 서로 영향을 주고받도록 함으로써 이러한 간극을 해소하고, 간결하면서도 기하학적으로 정확한 어셈블리를 생성한다.
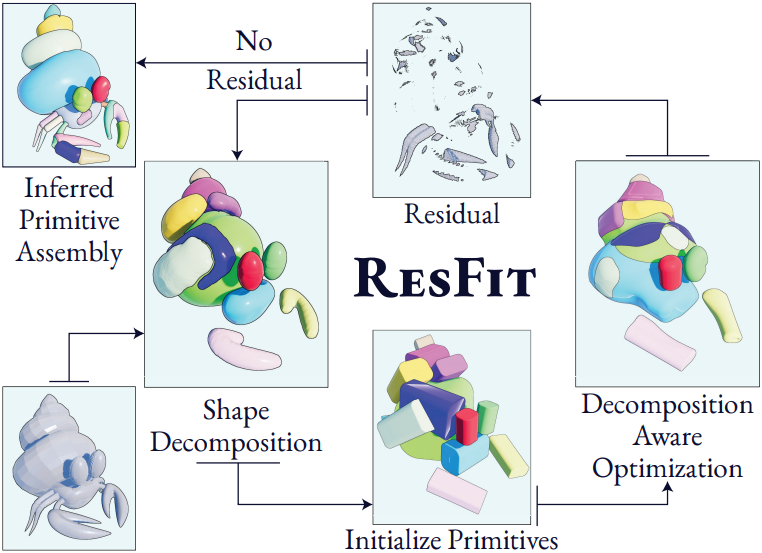
본 절차는 분석과 최적화 단계를 번갈아가며 수행한다. 분석 단계에서는 현재 잔여 볼륨을 새로운 primitive를 생성하는 영역으로 분해한다. 최적화 단계에서는 설명된 geometry와 남은 residual을 분리하여 $\mathcal{O}$를 최대화하도록 파라미터를 조정한다. 이 과정은 $\mathcal{O}$가 포화되거나 고정된 iteration 예산 $K$에 도달할 때까지 반복된다.
저자들은 반복 루프가 over-parameterization과 under-parameterization을 모두 수정할 수 있도록 몇 가지 설계 방식을 채택했다. Over-parameterization을 방지하기 위해 각 라운드마다 최소한의 primitive만 초기화하고, 간결성을 고려한 최적화를 적용한다. 이 최적화 방식에는 soft regularizer를 사용하여 fitting 과정에서 중복성을 억제하고, hard pruning을 통해 $\mathcal{O}$ 값을 저하시키는 부분을 제거하는 것이 포함된다. Under-parameterization을 해결하기 위해 primitive는 로컬 영역을 기반으로 최적화되고, 전체 어셈블리는 매 라운드마다 재최적화된다. 이러한 방식을 통해 새로운 part가 추가될 때 자체 수정이 가능해지며, 시스템은 간결하고 일관된 구조로 수렴하게 된다.
2. Expressive, Editable & Optimizable Primitive
Inverse graphics를 위한 이상적인 primitive는 다양한 형태를 표현할 수 있을 만큼 충분히 풍부하고, 직관적인 컨트롤을 통해 편집 가능하며, 최적화가 용이해야 한다. Primitive들이 이러한 조건을 충족하지 못하는 경우가 많기 때문에, 본 논문에서는 이 세 가지 요건을 모두 충족하도록 설계된 analytic primitive인 SuperFrustum을 도입하였다.

SuperFrustum은 SDF의 zero-level set이다.
이 8개의 스칼라는 anisotropic scale (\textbf{s}), profile rounding ($r$), dilation ($d$), taper ($t$), bulge ($b$), onion/shell thickness ($o$)를 직관적으로 제어한다. SuperFrustum은 직육면체, 원기둥, 원뿔, 토러스 등 광범위한 shape을 포괄하며 거의 모든 곳에서 미분 가능하므로 안정적인 gradient 기반 fitting이 가능하다.
완전한 어셈블리는 변환된 SuperFrustum들을 합성하여 형성된다. 각 인스턴스 $i$는 포즈 $(R_i, t_i)$와 shape 파라미터 \(\theta_i\)를 가지며, 이를 통해 SDF \(\textbf{g}_i (\textbf{p}) = f(R_i^\top (\textbf{p} - t_i); \theta_i)\)가 생성된다. 최종 implicit field $\mathcal{F}$는 smooth union 연산자 $U$를 재귀적으로 적용하여 얻는다. 최종 표면은 $\mathcal{F}$의 zero-level set이다.
\[\begin{aligned} \mathcal{F}_1 (\textbf{p}) &= g_1 (\textbf{p}) \\ \mathcal{F}_{k+1} (\textbf{p}) &= U (\mathcal{F}_k (\textbf{p}), g_{k+1} (\textbf{p}); \beta_k) \end{aligned}\](\(\beta_k\)는 블렌딩 선명도를 조절)
3. Shape Decomposition for SuperFrusta
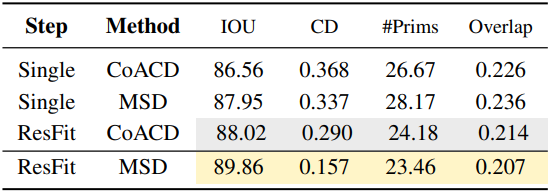
ResFit은 shape decomposition 방법을 통해 생성된 영역에서 primitive을 초기화하며, 선택한 decomposition 전략이 primitive 계열의 표현력과 일치할 때 성능이 향상된다. 저자들은 Approximate Convex Decomposition (ACD)보다 Morphological Shape Decomposition (MSD)를 변형한 방법이 SuperFrusta 초기화에 더 적합하다는 것을 발견했다.
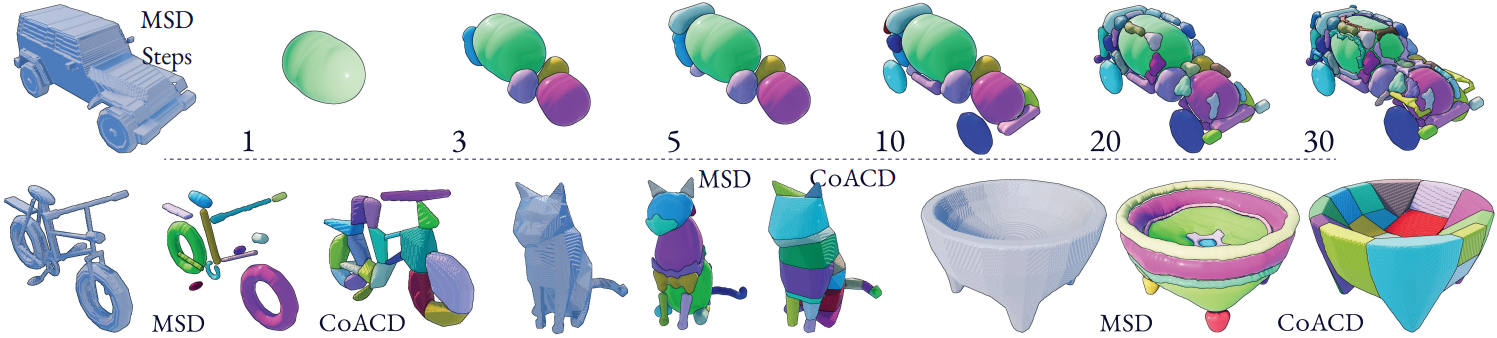
MSD는 가장 두꺼운 부분부터 벗겨내는 반복적인 기법이다. 각 step에서 MSD는 대략적으로 균일한 두께를 가진 가장 큰 연결 영역을 찾아 추출하고, 이을 shape에서 제거한 다음, 남은 부분에 대해 이 과정을 반복한다. 이 과정을 통해 primitive 초기화를 위한 두께 순서대로 정렬된 볼륨 영역 집합이 생성된다.
구체적으로, SDF $f(\textbf{p})$가 주어졌을 때, 각 iteration $k$는 반경 \(\vert \tau \vert\)까지의 erosion에서 살아남는 connected component (cc)를 찾아 가장 두꺼운 내부 영역 \(\Gamma_k\)를 식별한다.
\[\begin{equation} \Gamma_k \subseteq \{ \textbf{p} \in \Omega \mid f(\textbf{p}) \le \tau \}, \quad \Gamma_k \; \textrm{is a cc}. \end{equation}\]Threshold $\tau \le 0$은 \(\textrm{Vol}(\Gamma_k)\)가 volume fraction $\kappa$를 만족하는 최소값이다. 전체 공간적 범위를 복원하기 위해 \(\Gamma_k\)를 동일한 반지름 \(R_k = \Gamma_k \oplus B_{\vert \tau \vert}\)만큼 다시 확장한다. 이 $R_k$는 기록되고 잔여 필드를 업데이트하여 모양에서 빼진다.
\[\begin{aligned} f_1 (\textbf{p}) &= f (\textbf{p}) \\ f_{k+1} (\textbf{p}) &= f_k (\textbf{p}) \setminus R_k \end{aligned}\]이 과정을 반복하면 두께가 감소하는 순서로 정렬된 후보 영역 \(\{R_k\}\)의 시퀀스가 생성된다.
MSD는 ACD에 비해 두 가지 주요 이점을 제공한다.
- ACD의 convexity 제약 조건은 구부러지고 속이 빈 형태와 같이 하나의 SuperFrustum으로 모델링할 수 있는 non-convex 구조를 과도하게 분할한다.
- MSD는 반복적인 fitting 루프 동안 생성된 잔여 볼륨에 존재하는 노이즈가 있는 표면 아티팩트에 훨씬 더 robust하다.
분해된 각 볼륨에 대해 SuperFrustum을 생성한다. 볼륨 내에서 샘플링된 점들에 대해 PCA를 사용하여 파라미터를 초기화한다. 서로 다른 PCA 축을 따라 cylindricity 점수를 사용하여 방향을 선택한다. 그런 다음 포즈 $(R, t)$와 scale을 추론한다.
4. Decomposition-Aware Optimization
본 논문에서는 두 단계에 걸쳐 objective $\mathcal{O}$를 최대화하도록 어셈블리 파라미터를 최적화한다. 첫 번째 단계에서는 미분 가능한 방법을 사용하여 gradient descent를 통해 loss를 최소화하다. 두 번째 단계에서는 discrete한 pruning 방법을 사용하여 $\mathcal{O}$ 값을 저하시키는 primitive를 제거한다. 미분 가능한 loss는 reconstruction 정확도, 간결성, 품질을 고려하는 세 가지 구성 요소로 이루어져 있다.
Reconstruction
현재 어셈블리의 예측된 occupancy field \(\hat{o}(\textbf{p}) = \sigma(− \beta \mathcal{F}(p))\)를 GT occupancy field $o(\textbf{p})$와 비교한다. 샘플 $\textbf{p}$는 shape의 볼륨에서 균일하게 추출되며 표면 근처에서 조밀하게 추출된다. 얇고 곡률이 높은 구조를 더 잘 재구성하기 위해 각 $\textbf{p}$는 메쉬의 주곡률 $\kappa (\textbf{p})$로 가중치가 부여된다. Loss는 어셈블리 주변의 신호에 최적화를 집중하기 위해 공간 마스크 \(\mathcal{M} = \{\textbf{p} \mid \mathcal{F} (\textbf{p}) < \tau\}\) 내에서만 평가된다.
\[\begin{aligned} w(\textbf{p}) &= 1 + \sigma (\kappa (\textbf{p})) \\ \mathcal{L}_\textrm{rec} &= \frac{1}{\vert \mathcal{M} \vert} \sum_{\textbf{p} \in \mathcal{M}} w (\textbf{p}) (\hat{o} (\textbf{p}) - o (\textbf{p}))^2 \end{aligned}\]Parsimony
간결한 어셈블리를 장려하기 위해 각 primitive $i$에는 Gumbel-Softmax 분포를 통해 샘플링된 확률적 존재 변수 $q_i \in (0, 1)$이 할당된다. 그런 다음 해당 SDF field는
\[\begin{equation} f_i^\ast (\textbf{p}) = q_i f_i (\textbf{p}) + (1 − q_i) \end{equation}\]로 변조되어 존재 확률이 낮은 primitive를 부드럽게 제거한다. Parsimony loss는 활성 primitive 개수의 기대값에 페널티를 부여한다.
\[\begin{equation} \mathcal{L}_\textrm{count} = \sum_i q_i \end{equation}\]Quality
편집 용이성을 향상시키고 기하학적으로 얽히거나 과도하게 혼합된 어셈블리를 방지하기 위해, overlap loss \(\mathcal{L}_\textrm{overlap}\)와 smooth-union consistency loss \(\mathcal{L}_\textrm{union}\)을 결합한 regularizer \(\mathcal{L}_\textrm{qual}\)을 추가한다.
\[\begin{aligned} \mathcal{L}_\textrm{qual} &= \mathcal{L}_\textrm{overlap} + \mathcal{L}_\textrm{union} \\ \mathcal{L}_\textrm{overlap} &= \max (1, \sum_i \hat{o}_i (\textbf{p})) \\ \mathcal{L}_\textrm{union} &= \hat{o}(\textbf{p}) - \min (\sum_i \hat{o}_i (\textbf{p}), 1) \end{aligned}\](\(\hat{o}_i\)는 primitive $i$의 occupancy)
\(\mathcal{L}_\textrm{overlap}\)은 여러 primitive가 동시에 활성화되는 영역에 페널티를 부여하여 중복 커버리지를 방지한다. \(\mathcal{L}_\textrm{union}\)은 smooth union 어셈블리는 점유하지만 독립적인 primitive는 점유하지 않는 영역에 페널티를 부여하여 과도한 블렌딩을 방지한다.
전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{rec} + \lambda_\textrm{count} \mathcal{L}_\textrm{count} + \lambda_\textrm{qual} \mathcal{L}_\textrm{qual} \end{equation}\]Pruning
미분 가능한 최적화가 수렴한 후, discrete한 pruning 단계를 통해 어셈블리를 더욱 단순화한다. 부피나 기여도가 미미한 primitive들을 제거 대상으로 검토하고, objective $\mathcal{O}$를 개선하는 경우 해당 요소들을 greedy하게 제거한다.
Experiments
- 데이터셋: 3DGen-Prim (510개), Toys4K (500개)
- Metric
- Voxel IOU ($128^3$), Chamfer Distance (CD), Earth Mover’s Distance (EMD)
- BiSurfIoU: 타겟 shape괴 reconstruction된 shape 모두에서 샘플링된 표면 근처 포인트의 IoU 점수 평균
- Overlap: 여러 primitive가 커버하고 있는 부피 비율
- IntraPrim: 각 primitive 내에서 평균 PartField feature 분산
- InterPrim: PartField feature 중심점 간의 평균 nearest-neighbor distance
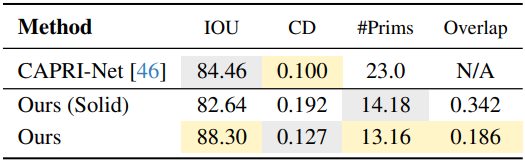
1. Parsimonious High fidelity Assemblies
다음은 어셈블리 품질에 대한 비교 결과이다.

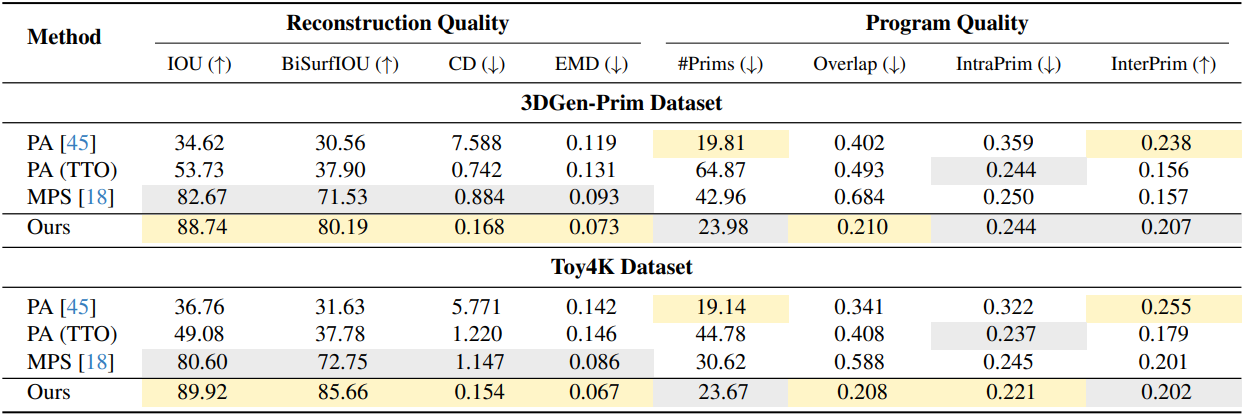
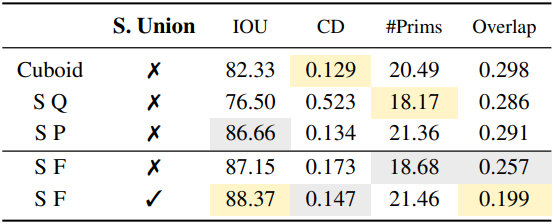
2. Ablative Analysis
다음은 primitive에 대한 ablation 결과이다.
다음은 fitting 및 decomposition에 ablation 결과이다.
3. Applications
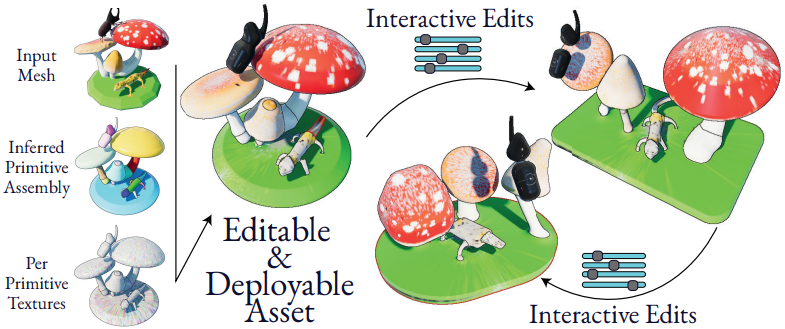
다음은 각 primitive에 spherical 2D 텍스처를 할당하고 텍스처가 적용된 메쉬에 맞춰 최적화한 예시들이다.
다음은 ABC 데이터셋에 대한 CSG inference 결과이다.

다음은 Hunyuan3D-2.1로 생성한 3D 모델에 SuperFit을 적용한 예시들이다.

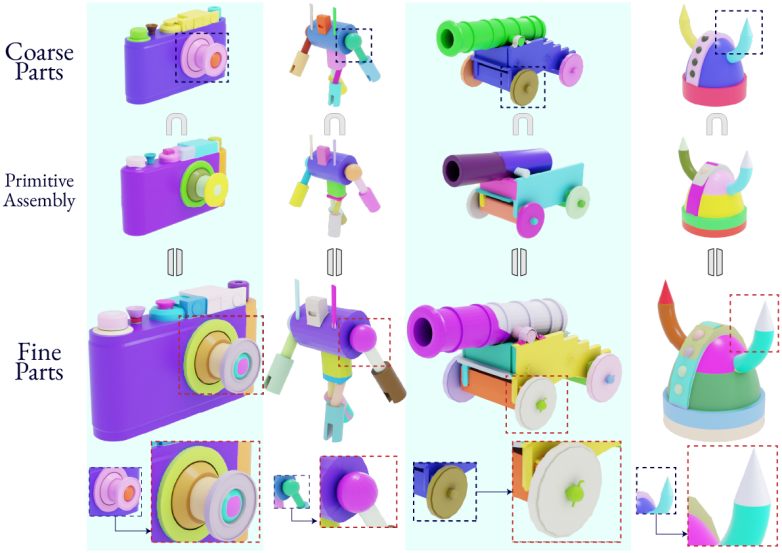
다음은 PartObjVerse 데이터셋의 coarse semantic label을 SuperFit을 활용하여 더 세밀하게 분할한 예시들이다.