[논문리뷰] PartField: Learning 3D Feature Fields for Part Segmentation and Beyond
ICCV 2025. [Paper] [Page] [Github]
Minghua Liu, Mikaela Angelina Uy, Donglai Xiang, Hao Su, Sanja Fidler, Nicholas Sharp, Jun Gao
NVIDIA | University of Toronto | Vector Institute | UCSD
15 Apr 2025
Introduction
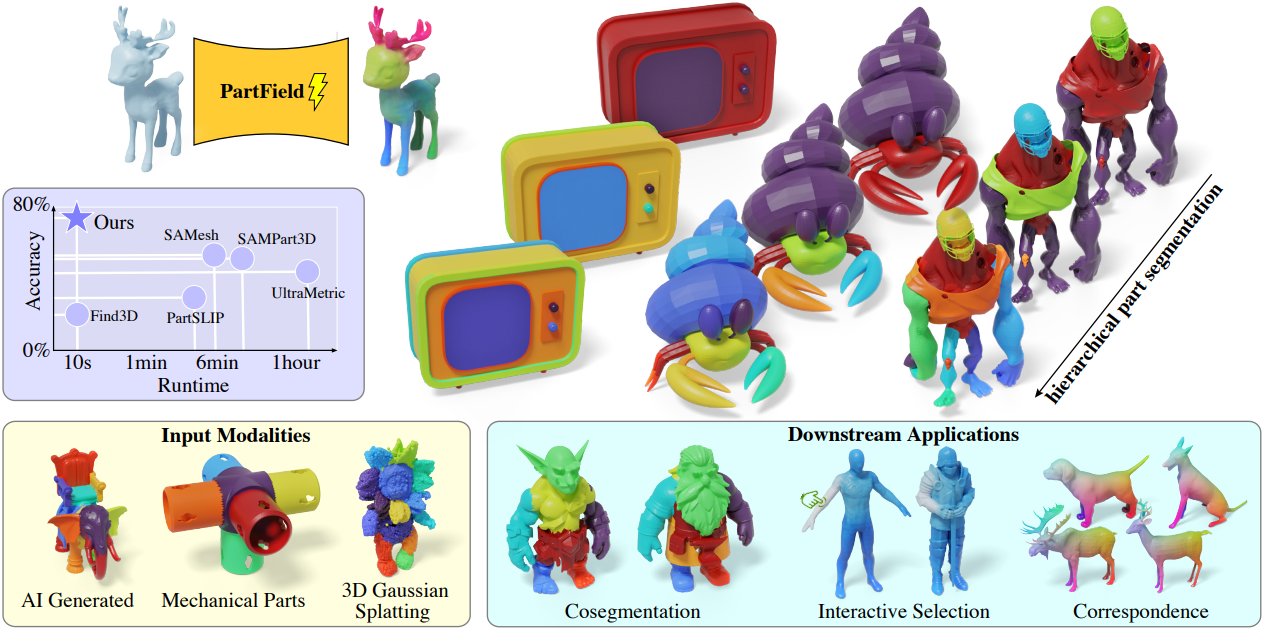
본 논문에서는 3D part와 그 계층 구조를 학습하는 PartField 모델을 제안하였다. 3D shape을 입력으로 받으면, PartField는 feedforward 방식으로 continuous 3D feature field를 예측한다. Part 템플릿이나 텍스트에 의존하는 대신, PartField feature 간의 거리를 통해 part의 개념을 도출한다. 즉, 유사한 feature를 가진 점들은 같은 part에 속할 가능성이 높다. 학습된 feature는 어느 위치에서든 continuous하게 조회할 수 있으며, 클러스터링을 통해 shape의 계층 구조를 생성하거나 다른 다운스트림 응용 분야에 활용할 수 있다.
PartField는 기존 2D foundation model에서 이미지 마스크로 예측된 part proposal 또는 기존 데이터셋에서 제공된 명시적인 3D supervision을 사용하여 part proposal들을 매칭하도록 학습된다. 이러한 part proposal에는 제약 조건이 없으며, 다양한 기준에 따라 어떤 세분성 수준에서도 정의할 수 있다. PartField는 신중하게 선택된 contrastive objective를 활용하여 동일한 part의 샘플이 서로 다른 part의 샘플보다 더 유사하도록 유도한다. 이는 다양한 part 세분성과 part 개념의 차이를 극복하여 대규모 데이터셋에서 학습을 가능하게 한다.
3D feedforward 모델을 사용함으로써 PartField는 inference 속도를 획기적으로 향상시킬 뿐만 아니라 일관성이 없고 노이즈가 많은 레이블에 대한 robustness도 확보하였다. Shape 간 supervision을 명시적으로 통합하지는 않았지만, PartField 모델이 shape에 관계없이 일관된 feature space를 생성한다. 이는 다운스트림 응용 분야에 유용한 특성이다.
PartField는 class-agnostic part segmentation task에서 최신 baseline 모델들보다 성능이 20% 이상 향상되었으며, 속도는 10배 이상 빨라졌다. 이를 통해 고품질의 계층적 part 분해가 가능하다. 모델은 실제 환경의 메쉬, 포인트 클라우드, 3D Gaussian splat 등 다양한 모달리티에 적용할 수 있다. Feature field의 일관성은 part segmentation 외에도 co-segmentation, 선택, correspondence 설정과 같은 다양한 용도로 활용될 수 있도록 한다.

Method

3D shape $S$가 입력으로 주어지면, PartField는 part의 구조와 part들의 계층 구조를 인코딩하는 continuous 3D feature field를 feedforward 방식으로 예측한다. 이 feature field는 임의의 3D 점 $\textbf{p}$를 $n$차원 latent feature $f(\textbf{p}; S)$으로 매핑한다. Part의 개념은 두 점 사이의 feature 거리로 모델링된다. 두 점 \(\textbf{p}_a\)와 \(\textbf{p}_b\)가 같은 part에 속한다면, 이들의 feature 벡터 \(f(\textbf{p}_a; S)\)와 \(f(\textbf{p}_b; S)\)는 latent feature space에서 서로 가까워야 한다.
1. Training Part Proposals and Point Triplets
Part Proposals
본 논문에서는 2D 및 3D 데이터 모두에서 part proposal을 추출하였다. Part proposal은 어떤 점들을 그룹화하여 하나의 part를 구성해야 하는지에 대한 힌트를 제공한다. 각 part proposal $P$는 shape의 부분집합에 레이블을 지정하며, 이는 shape의 해당 부분이 동일한 부분에 속함을 나타낸다. 미리 정의된 part 템플릿을 가정하지 않으므로, part proposal은 반드시 semantic하게 연관될 필요는 없다. Part proposal은 다양한 세분성으로 제공될 수 있으며, 다양한 기준에 따라 정의될 수 있다.
2D proposal의 경우, 대규모의 레이블 없는 데이터셋에서 3D shape의 멀티뷰 RGB 이미지와 normal 이미지를 렌더링한다. 그런 다음 SAM2를 적용하여 2D 마스크를 예측하고, 이를 다시 shape에 projection한다. 포인트 프롬프트를 dense하게 샘플링하고, 각 마스크는 하나의 proposal을 생성한다. 여러 마스크에서 생성된 proposal은 서로 겹칠 수 있으며, 다양한 세분성 수준을 포함한다. 3D proposal의 경우, 기존 3D 데이터셋에서 제공되는 part 주석을 활용한다. 마찬가지로, 레이블이 계층적 구조를 갖는 경우 proposal이 겹칠 수 있다.
2D proposal과 3D proposal은 서로를 보완한다. SAM2에서 생성된 2D proposal은 대규모의 레이블 없는 데이터셋에서의 학습을 가능하게 하고 모델에 오픈월드 처리 능력을 부여하는 반면, 3D proposal은 내부 구조에 대한 완벽한 supervision을 제공하고 유용한 인간의 semantic 주석을 포착한다.
3D Point Triplets
Part proposal을 얻은 후, 학습 중에 이러한 proposal에서 3D point triplet을 실시간으로 샘플링하여 triplet 기반 contrastive loss를 적용한다. 구체적으로, 주어진 shape $S$와 해당 shape에 대한 part proposal $P$에 대해, \(\textbf{p}_a\)와 \(\textbf{p}_b\)는 $P$에서, \(\textbf{p}_c\)는 $P$ 외부에서 추출되는 3D point triplet \(\{(\textbf{p}_a, \textbf{p}_b, \textbf{p}_c)\}\)을 샘플링한다.
\[\begin{equation} \textbf{p}_a, \textbf{p}_b \in P \subset S, \quad \textbf{p}_c \in S \setminus P \end{equation}\]2D proposal의 경우, triplet의 모든 점은 해당 뷰에서 shape의 보이는 2D 픽셀에서 샘플링된 다음, 알려진 카메라 포즈와 depth를 사용하여 3D로 unprojection된다. 이는 2D 마스크가 형상의 보이는 표면에 대한 supervision에만 기여한다는 것을 의미한다. 3D proposal의 경우, 점들은 shape 및 part의 내부 공간을 포함하여 3D geometry에서 직접 샘플링된다.
2. Contrastive Learning with Negative Sampling
Contrastive triplet loss의 핵심 아이디어는 part proposal 내에서 positive point \(\textbf{p}_a\)와 \(\textbf{p}_b\)가 서로 가깝도록 유도하고, negative point \(\textbf{p}_c\)는 서로 멀리 떨어지도록 하는 것이다. 그러나 part 레이블링의 계층적이고 스케일이 모호한 특성으로 인해 이러한 loss의 설계 및 scaling이 복잡해진다.
즉, 유효한 두 part proposal이 세분화 수준에 따라 동일한 part 또는 다른 part에 점을 할당할 수 있다. 기존 방법에서는 공간에 명시적인 scale 파라미터를 사용하였지만, 데이터 전반에 걸쳐 이 scale를 일관되게 설정하는 것은 어려울 수 있다.
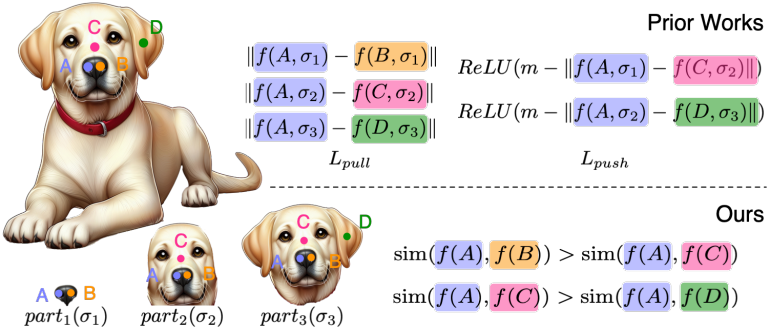
대신, 저자들은 SimCLR에서 영감을 받은 상대적 접근 방식을 채택하여 supervision 개념을 약화시키고, 단순히 \(\textbf{p}_a\)가 \(\textbf{p}_c\)보다 \(\textbf{p}_b\)에 더 가깝도록, 그리고 \(\textbf{p}_b\)의 경우에도 마찬가지로 하도록 유도한다. Contrastive loss는 다음과 같다.
($\tau$는 학습 가능한 temperature)
Feature 간 거리를 직접 최소화하는 것과는 달리, 이 접근 방식은 멀티스케일 proposal을 처리할 때 발생하는 충돌을 피하고, 명시적인 scaling 조건이 필요하지 않으며, 다양한 출처의 대규모 데이터셋에서 학습을 가능하게 한다.
Hard Negative Sampling
Triplet을 형성할 때 positive point \(\textbf{p}_a\)와 \(\textbf{p}_b\)는 균일하게 샘플링되는 반면, negative point \(\textbf{p}_c\)는 학습 효율성을 위해 세 가지 전략을 혼합하여 샘플링된다. 세 가지 전략은 모두 part proposal에 포함되지 않는 영역, 즉 2D 이미지 뷰에서 보이는 표면 중 마스킹되지 않은 표면, 또는 3D에서 레이블되지 않은 영역에서 추출된다.
- uniform: 균일하게 샘플링
- 3D-hard: 유클리드 공간에서 \(\textbf{p}_a\)에 더 가까운 점을 선호
- feature-hard: feature space에서 \(\textbf{p}_a\)에 더 가까운 점을 선호
효율성을 위해, 저자들은 각 \(\textbf{p}_a\)에 대해 많은 \(\textbf{p}_c\)로 contrastive loss를 병렬로 평가하고, \(\textrm{sim} (f(\textbf{p}_a), f(\textbf{p}_c))\) 항을 합산한다. 이러한 샘플들의 조합은 특히 part 경계 근처에서 정확도를 향상시킨다.
3. Feedforward Model
기존 방법들은 shape별 최적화를 통해 2D 예측 또는 prior를 추출하는 방식을 사용했지만, 본 논문에서는 feedforward 3D 모델 $f(\textbf{p}, S)$를 학습시켰다. 이러한 접근 방식은 다음과 같은 여러 가지 이점을 제공한다.
- 빠른 inference 속도
- Shape 내부까지 매끄럽게 확장되는 일관되고 완전한 3D feature field
- 특히 2D 모델에서 발생하는 노이즈가 많고 일관성이 없는 part proposal에 대한 robustness
- Shape 간에 자연스럽게 상관관계를 가지는 통합된 feature space
Architecture
입력 shape은 깨끗한 메쉬, 실제 메쉬, 포인트 클라우드, Gaussian splat 등 다양한 형태로 제공될 수 있으며, 이러한 shape들은 샘플링되어 3D 포인트 클라우드를 생성한다. 이 포인트 클라우드는 모델의 입력으로 사용되며, 모델은 임의의 공간적 위치에서 평가할 수 있는 triplane 형태로 인코딩된 feature field를 출력한다. PVCNN 인코더가 각 포인트의 feature를 추출하고, 세 개의 축 정렬된 2D 평면에 projection하여 초기 triplane 표현을 생성한다. 이 triplane은 2D CNN을 통해 다운샘플링되고, flatten되고, transformer를 거친 후, transposed 2D CNN을 통해 다시 triplane으로 업샘플링된다. 마지막으로, 임의의 3D 쿼리에 대해 triplane에서 해당 feature들을 추출하고 합산하여 해당 점의 feature field를 평가한다.
4. Inference and Clustering
Inference 시에는 학습된 신경망을 한 번 적용하여 feature field triplane을 생성한 다음, 원하는 대로 part feature를 샘플링한다. 예를 들어, 고해상도 입력 메쉬의 각 면이나 shape 내부에서 샘플링할 수 있다. 메쉬 기반 decomposition의 경우, 각 면에서 dense하게 점을 샘플링하고 이러한 점들의 feature 평균을 면 feature로 사용한다. 네트워크는 3D 포인트 클라우드를 입력으로 받지만, 다른 3D 모달리티에도 적용할 수 있다 (ex. 3D Gaussian).
그런 다음, 클러스터링 알고리즘을 적용하여 3D shape의 part-aware decomposition을 얻을 수 있다. 다양한 설정에 따라 다양한 클러스터링 전략이 필요할 수 있다. $k$-means clustering은 간단하고 빠르지만, agglomerative clustering은 메쉬 연결성에 대한 명확한 결과를 제공한다. 본 논문에서는 기본적으로 면 인접성에 의해 유도된 연결성을 기반으로 메쉬 면에 agglomerative clustering을 적용하였다.
Experiments
- 데이터셋: Objaverse, PartNet
- 구현 디테일
- feature field 차원: 448
- triplane 해상도: $512^2$, 128채널
- transformer: layer 6개, 입력 해상도 $128^2$
- batch size: GPU당 2
- GPU: A100 8개로 2주 소요
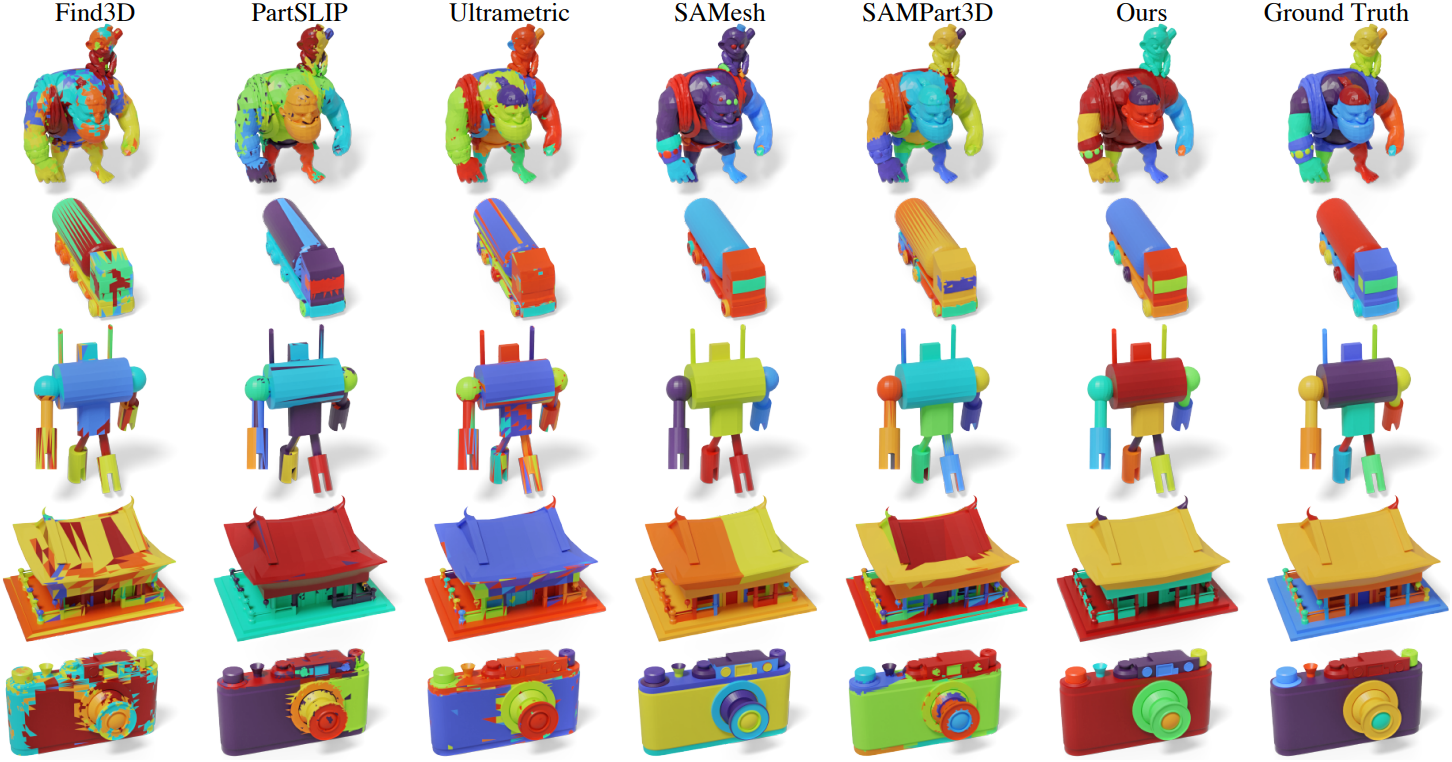
1. Comparison of Class-Agnostic Segmentation
다음은 PartObjaverse-Tiny에 대한 class-agnostic part segmentation 결과이다.
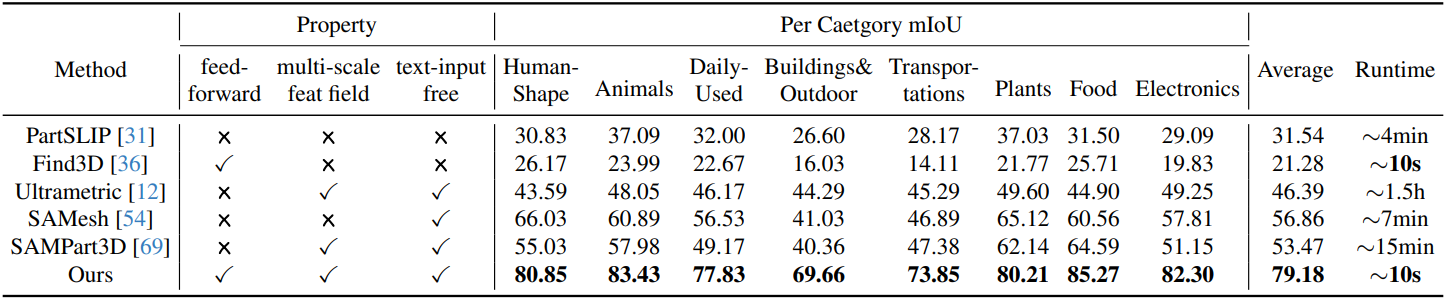
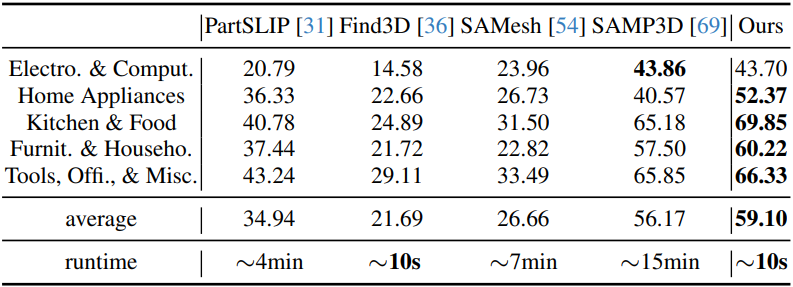
다음은 PartNetE test set에 class-agnostic part segmentation 결과이다.
2. Applications
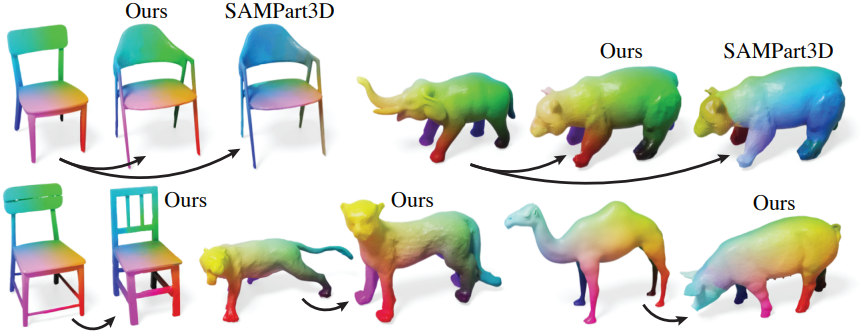
다음은 hierarchical part decomposition 결과이다.

다음은 사용자가 클릭한 점과 다른 영역의 유사도를 나타낸 예시이다.
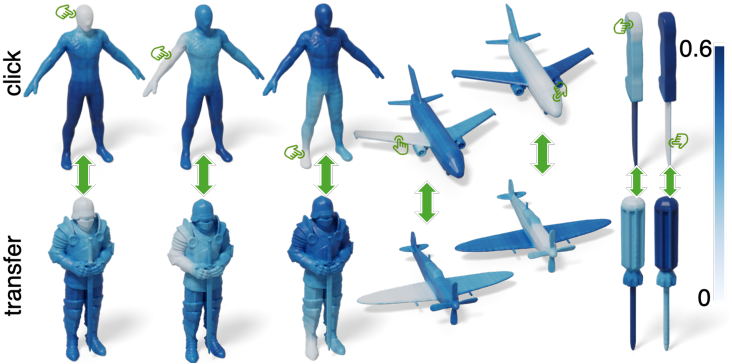
다음은 co-segmentation 결과이다.

다음은 두 shape 사이의 correspondence를 찾은 예시들이다.
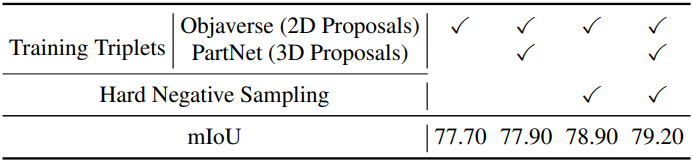
3. Ablations
다음은 ablation study 결과이다.