[논문리뷰] Shuffle the Context: RoPE-Perturbed Self-Distillation for Long-Context Adaptation
ICML 2026. [Paper]
Zichong Li, Chen Liang, Liliang Ren, Tuo Zhao, Yelong Shen, Weizhu Chen
Georgia Institute of Technology | Microsoft
15 Apr 2026
Introduction
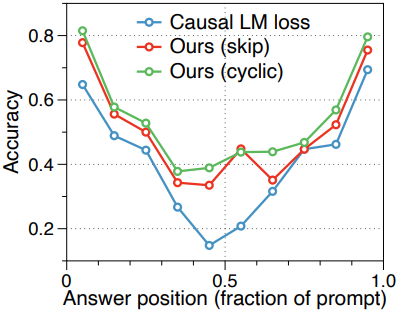
긴 컨텍스트 성능을 향상시키는 일반적인 방법은 짧은 컨텍스트로 사전 학습된 LLM을 fine-tuning하는 것이다. Fine-tuning의 효과에도 불구하고, 결과 모델은 증거 위치에 대해 여전히 취약할 수 있다. 아래 그래프는 RULER multikey-2 NIAH에서 이러한 현상을 보여준다. Fine-tuning된 baseline 모델은 위치에 대한 뚜렷한 의존성을 보이며, 정확도는 프롬프트 내 답변의 위치에 따라 달라진다.
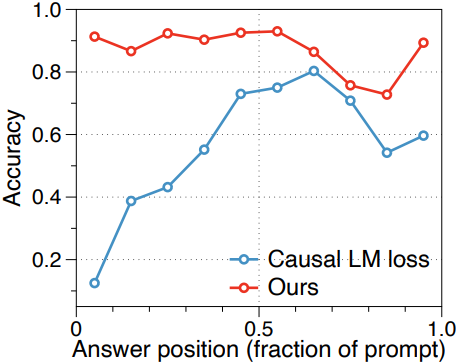
이러한 위치 민감성은 대부분의 최신 LLM이 위치 인코딩에 사용하는 rotary position embeddings (RoPE)의 관점에서 살펴볼 수 있다. RoPE는 query 벡터와 key 벡터를 위치에 따라 달라지는 각도로 회전시키므로, attention은 상대적인 offset에 따라 달라진다. 긴 컨텍스트 환경에서 이러한 위치 의존적 위상은 모델 동작이 위치 인덱스 할당 방식에 민감하게 반응하도록 만들 수 있다.
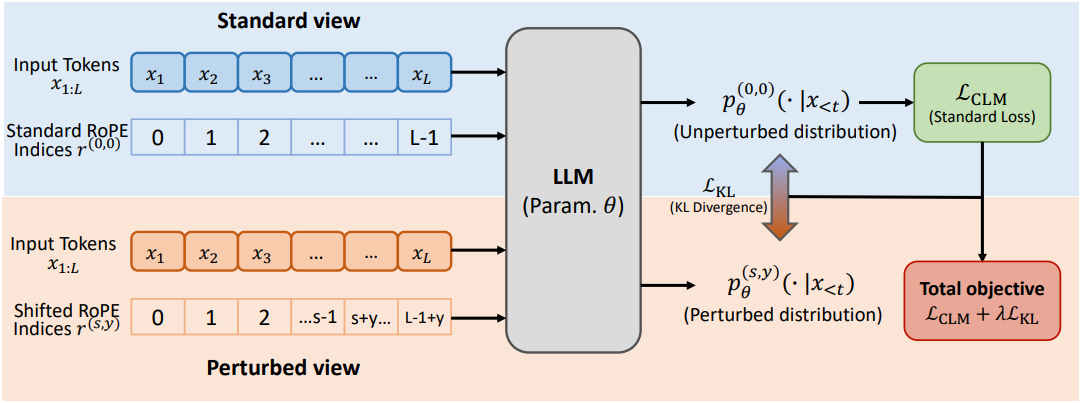
본 논문은 RoPE-Perturbed Self-Distillation이라는 간단한 정규화 기법을 제안하였다. 이 기법은 연속적인 구간에 걸쳐 RoPE 인덱스를 이동시켜 각 학습 시퀀스에 대한 변형 뷰를 생성한다. 구체적으로, 길이가 $L$인 시퀀스가 주어졌을 때, 분할 지점 $s$를 샘플링하고 suffix $[s, L-1]$에 있는 모든 토큰의 RoPE 인덱스에 offset $y$를 더한다. 이때 $[0, s-1]$은 변경하지 않는다. 이러한 perturbation은 suffix와 이전 prefix 사이의 RoPE 거리를 $y$만큼 효과적으로 증가시키므로, suffix에 있는 토큰들은 이전 컨텍스트를 더 멀리 있는 것으로 인식하게 된다.
본 논문에서는 표준 뷰와 변형 뷰, 두 번의 forward pass를 통해 모델을 학습시킨다. 표준 뷰에서는 일반적인 causal language modeling (CLM) loss를 최적화한다. 그런 다음, 변형 뷰의 다음 토큰 분포를 표준 뷰의 분포와 일치시키는 KL-divergence를 최소화함으로써 뷰 간 일관성을 확보한다. 이 때, 표준 경로에는 stop gradient가 적용된다. 이러한 방식으로 표준 뷰는 원래 인덱스 할당 하에서 안정적인 레퍼런스를 제공하고, 변형 뷰는 표준 뷰에 맞춰 학습되어 RoPE shift로 인한 예측 차이에 페널티를 부여함으로써 위치 민감도를 줄인다.
이러한 perturbation의 효과는 RoPE의 다중 주파수 구조를 통해 이해할 수 있다. 고주파 성분은 위치에 따라 빠르게 변화하여 미세한 위상 정보를 포착하는 반면, 저주파 성분은 더 느리게 변화하여 coarse한 구조 정보를 포착한다. 인덱스 이동은 주로 이동된 범위와 관련된 상호작용에서 위치에 민감한 고주파 성분을 교란시키는 반면, coarse한 구조는 상대적으로 안정적으로 유지한다. 따라서 두 뷰 간의 일치를 강제함으로써 모델은 semantic 컨텐츠나 coarse한 위치 구조와 같은 위치에 robust한 신호에 더 많이 의존하게 된다.
Method
1. Problem setting and notation
긴 컨텍스트 코퍼스 $\mathcal{D}$에서 추출한 길이 $L$의 토큰 시퀀스를 \(x_{0:L−1} = (x_0, \ldots, x_{L−1})\)이라고 하자. 각 self-attention layer에서 rotary position embeddings (RoPE)을 사용하는 파라미터 $\theta$를 갖는 autoregressive Transformer 언어 모델을 고려하자. 토큰 $x_i$에는 RoPE 인덱스 $r_i$가 할당되며, 명시적인 인덱스 벡터 \(r = (r_0, \ldots, r_{L-1}) \in \mathbb{Z}^L\)을 사용한다. $(x_{0:L−1}, r)$이 주어졌을 때, 모델은 causal mask 하에서 다음 토큰의 분포를 정의한다.
\[\begin{equation} p_\theta (\cdot \, \vert \, x_{<i}; r), \quad i = 0, \ldots, L-1 \end{equation}\]표준 long-context fine-tuning은 교란되지 않은 RoPE 인덱스 하에서 causal language modeling (CLM) loss를 최소화한다.
\[\begin{equation} r_i = i, \quad i = 0, \ldots, L-1 \\ \mathcal{L}_\textrm{CLM} (\theta) = \mathbb{E}_{x_{0:L-1} \sim \mathcal{D}} \left[ - \sum_{i=0}^{L-1} \log p_\theta (x_i \, \vert \, x_{<i}; r) \right] \end{equation}\]본 논문의 목표는 RoPE 인덱스에 대한 취약한 의존성을 줄이면서 LLM을 긴 컨텍스트에 적용하는 것이다. 이를 위해 동일한 토큰 시퀀스의 변형된 뷰, 즉 토큰 시퀀스와 causal mask는 변경하지 않고 RoPE 인덱스만 변경하는 뷰를 구성하고, self-distillation을 통해 뷰 간 예측 일관성을 유지한다. RoPE 인덱스를 변경하는 모든 변환은 뷰 생성기로 사용될 수 있다.
2. RoPE-perturbed views via skip-based index shifts
Skip-based perturbation
저자들은 분할점 $s$와 skip 길이 $y$를 사용하는 RoPE 인덱스 할당 방식을 정의하였다.
\[\begin{equation} r_i^{(s, y)} = \begin{cases} i, & \quad i < s \\ i + y, & \quad i \ge s \end{cases} \\ \textrm{where} \quad i = 0, \ldots, L-1, \; s \in [0, \ldots, L-1] \; y \in [1, \ldots, Y] \end{equation}\]각 시퀀스에 대해 $(s,y) \sim q(s,y)$를 샘플링하고 모든 RoPE layer에 동일한 인덱스를 적용한다. 저자들은 기본적으로 $Y = L$로 설정하고 $q$를 uniform distribution으로 설정하였다.
중요한 것은 토큰 시퀀스 \(x_{0:L−1}\)은 변경되지 않고 RoPE 인덱스만 수정된다는 점이다. 직관적으로 이는 인덱스 공간에 “간격”을 만든다. Suffix $[s, L-1]$의 토큰에는 더 큰 RoPE 인덱스가 할당되어 prefix $[0, s-1]$과 suffix $[s, L-1]$ 사이의 경계 간 상호 작용이 RoPE 공간에서 더 멀리 떨어져 있는 것처럼 보인다.
두 가지 뷰 구성
각 입력 \(x_{0:L−1}\)과 샘플링된 $(s,y)$에 대해 두 가지 뷰를 다음과 같이 구성한다.
- 표준 뷰: \(p_\theta^{(0,0)} (\cdot \, \vert \, x_{<i}) = p_\theta (\cdot \, \vert \, x_{<i}; r^{(0,0)})\)
- 교란된 뷰: \(p_\theta^{(s,y)} (\cdot \, \vert \, x_{<i}) = p_\theta (\cdot \, \vert \, x_{<i}; r^{(s,y)})\)
두 가지 뷰는 동일한 토큰 시퀀스에 대한 동일한 모델의 두 번의 forward pass를 의미하며, 위치 인덱스 할당만 다르다.
3. Self-distillation between perturbed and standard views
본 논문에서는 표준 forward pass를 기준으로 삼으면서, 교란된 RoPE 인덱스 하에서의 모델 예측값이 표준 인덱스 하에서의 예측값과 일치하도록 함으로써 positional robustness를 확보하고자 하였다. 구체적으로, reverse KL divergence를 최소화하는데, 이는 경험적으로 forward KL divergence보다 우수한 성능을 보인다. 목표 위치 $i$에 대해 다음과 같이 정의한다.
\[\begin{equation} \ell_i^{(s,y)} (\theta) = \textrm{KL} \left( p_\theta^{(s,y)} (\cdot \, \vert \, x_{<i}) \, \bigg\| \, \textrm{sg} \left( p_\theta^{(0,0)} (\cdot \, \vert \, x_{<i}) \right) \right) \end{equation}\]($\textrm{sg}(\cdot)$는 stop-gradient)
정규화 항의 gradient는 교란된 경로를 통해서만 흐른다. 직관적으로 표준 뷰는 teacher 역할을 한다. 즉, 표준 뷰는 원래 인덱싱 하에서 CLM loss에 의해 직접 최적화되므로 안정적인 타겟 분포를 제공하는 반면, 교란된 뷰는 이동된 인덱스 하에서 이 레퍼런스와 일치하도록 학습된다.
위치 $i < s$에 대해 모든 RoPE 인덱스를 변경하지 않으므로, 모든 $i < s$에 대해 \(\ell_i^{(s,y)} (\theta) = 0\)이다. 따라서 distillation loss는 suffix $[s, L-1]$에만 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{distill} (x_{0:L-1}; \theta) = \mathbb{E}_{(s,y) \sim q(s,y)} \left[ \frac{1}{L-s} \sum_{i=s}^{L-1} \ell_i^{(s,y)} (\theta) \right] \end{equation}\]마지막으로 데이터 분포에 대한 기대값을 구한다.
\[\begin{equation} \mathcal{L}_\textrm{CLM} (\theta) = \mathbb{E}_{x_{0:L-1} \sim \mathcal{D}} \left[ \mathcal{L}_\textrm{distill} (x_{0:L-1}; \theta) \right] \end{equation}\]전체 loss
전체 학습 loss는 표준 CLM fine-tuning과 RoPE-perturbed self-distillation regularizer를 결합한 것이다.
\[\begin{equation} \mathcal{L}_\textrm{total} (\theta) = \mathcal{L}_\textrm{CLM} (\theta) + \lambda \mathcal{L}_\textrm{KL} (\theta) \end{equation}\]($\lambda = 1$)
표준 뷰는 \(\mathcal{L}_\textrm{CLM}\)을 통해 업데이트되어 학습 과정에서 teacher 분포를 개선하는 반면, 교란된 뷰는 KL regularizer를 통해 업데이트되어 진화하는 teacher 분포에 맞춰지고 제어된 인덱스 이동에 불변하게 된다. 표준 long-context fine-tuning과 비교하여, 본 방법은 batch당 추가적인 forward pass를 수행한다.
Inference 시에는 표준 인덱스를 사용한다. 따라서 regularizer는 두 번째 모델을 도입하는 것이 아니라, 제어된 위치 perturbation 하에서 하나의 모델이 일관된 예측을 생성하도록 유도하는 역할을 한다.
4. Cyclic-shift perturbation as a working variant
Skip-based shift는 perturbation 방법 중 하나이며, 많은 RoPE 인덱스 perturbation을 사용할 수 있다. Skip-based shift 외에도, 저자들은 cyclic shift perturbation도 고려하였다.
Shift \(u \in \{0, \ldots, L − 1\}\)가 주어졌을 때, 다음과 같이 정의한다.
\[\begin{equation} r_i^{\textrm{cyc}(u)} = (i + u) \; \textrm{mod} \; L, \quad i = 0, \ldots, L-1 \end{equation}\]교란된 뷰는 \(p_\theta^{\textrm{cyc}(u)} (\cdot \, \vert \, x_{<i}) = p_\theta (\cdot \, \vert \, x_{<i}; r^{\textrm{cyc}(u)})\)로 정의되며 $u \sim q(u)$를 샘플링하여 동일한 distillation loss를 적용한다.
토큰의 상대적 순서를 유지하는 skip-based shift와 달리, cyclic shift는 인덱스 할당을 회전시켜 원래 prefix의 토큰이 시퀀스의 끝으로 매핑되도록 한다. 결과적으로, 이러한 perturbation은 더 파괴적이며 많은 토큰 쌍에 대해 먼 거리의 상대적 offset을 상당히 변경할 수 있다. 따라서 cyclic shift는 인덱스 불변성에 대한 더 강력한 스트레스 테스트 역할을 한다.
Experiments
- 모델
- Llama-3-8B-Instruct: 8K window $\rightarrow$ 64K window
- Qwen-3-4B: 32K window $\rightarrow$ 256K window
1. Main Results on Long-Context Benchmarks
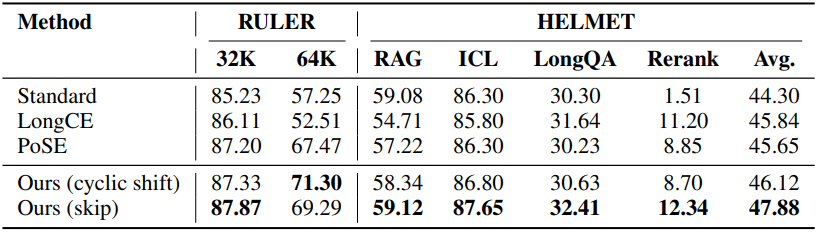
다음은 Llama-3-8B-Instruct에 대하여 평균 성능을 비교한 결과이다. (위: RULER, HELMET 64K / 아래: RULER 64K)

다음은 Qwen-3-4B에 대하여 평균 성능을 비교한 결과이다. (RULER, HELMET 128K)
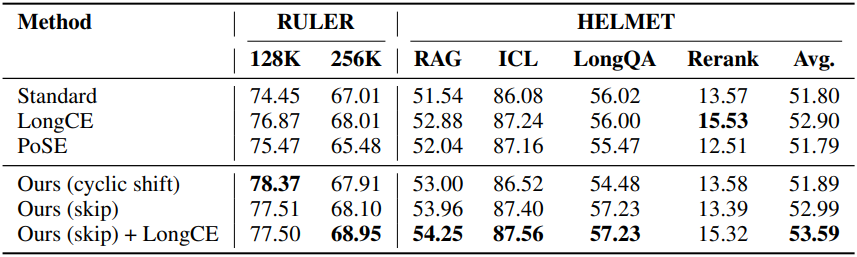
다음은 Qwen-3-4B에 대하여 위치 민감성을 비교한 결과이다. (RULER NIAH MultiKey-2)
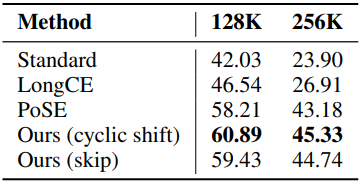
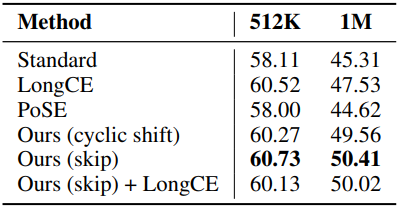
2. Length Extrapolation via YaRN
다음은 (왼쪽) Llama와 (오른쪽) Qwen에 대하여 YaRN을 사용하여 length extrapolation한 결과이다. (학습 컨텍스트 길이를 초과하는 입력 컨텍스트에 대한 성능 평가)
3. Does the Gain Survive Instruction SFT?
저자들은 본 논문의 방법이 근본적인 긴 컨텍스트 능력을 향상시키는 지 보기 위해, long-context fine-tuning된 Qwen을 1 epoch SFT하였다.
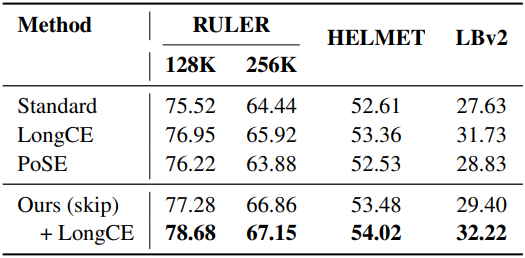
4. Short-Context Performance
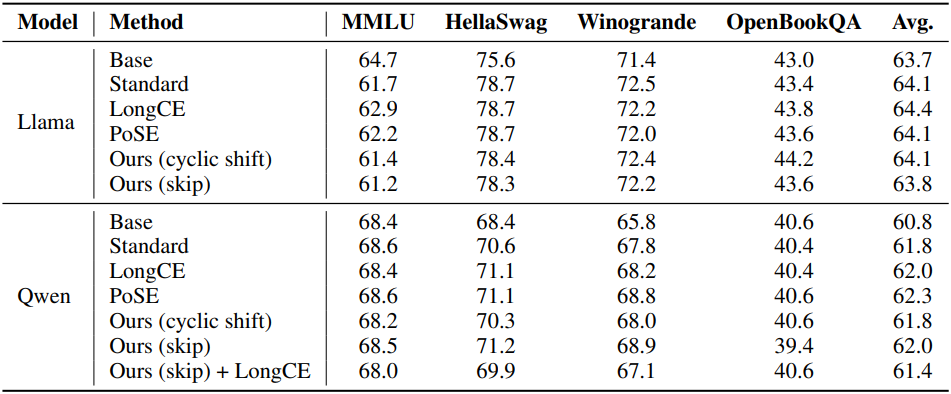
다음은 다운스트림 task 성능을 비교한 결과이다.
5. Ablations and Analysis
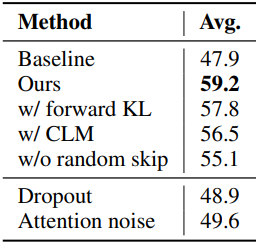
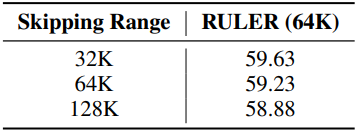
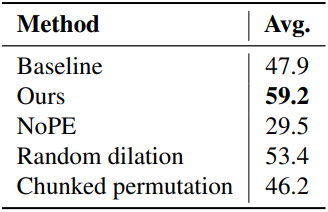
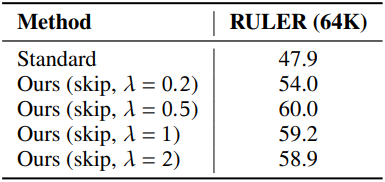
다음은 loss 디자인, skip range $Y$, RoPE perturbation, KL 계수 $\lambda$에 대한 ablation study 결과이다. 전부 Llama-3-8B-Instruct 모델을 RULER (64K)로 평가하였다.
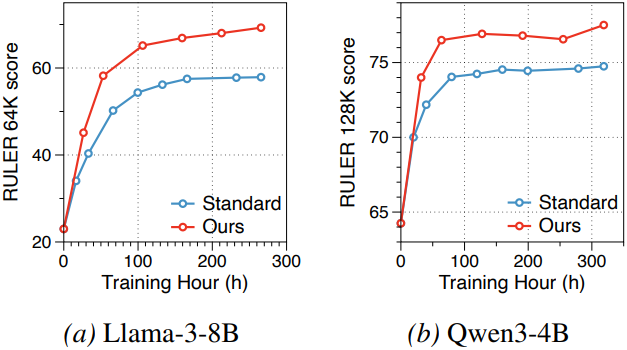
6. Compute-Matched Training Efficiency
다음은 학습 시간에 따른 성능을 비교한 그래프이다. 본 논문의 방법은 학습 시 한 번의 forward pass가 더 필요하지만, 더 빠르게 성능이 향상된다.