[논문리뷰] Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis
ICML 2026. [Paper] [Page] [Github]
Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, Robin Rombach
Black Forest Labs | MIT
6 Mar 2026

Introduction
본 논문에서는 generative objective만으로 학습된 표현을 넘어 능동적으로 표현을 강화하기 위해 self-supervised 프레임워크를 flow matching에 직접 통합하는 방안을 제안하였다. 이를 위해, 입력 토큰의 서로 다른 부분집합에 두 가지 수준의 noise를 적용하여 정보 비대칭성을 생성하는 Dual-Timestep Scheduling을 제안하였다. 이 비대칭성으로 인해 일부 토큰은 다른 토큰보다 더 심하게 손상된다. 두 번의 forward pass를 수행하는데, 첫 번째는 혼합된 heterogeneous noise가 적용된 입력에 대해, 두 번째는 모든 토큰이 두 noise level 중 낮은 level의 noise가 적용된 깨끗한 입력에 대해 수행한다. Self-supervised loss는 혼합된 입력으로부터 깨끗한 입력이 주어졌을 때 모델이 생성하는 표현을 예측한다. Heterogeneous noise가 적용된 입력에 표준 flow loss를 적용함으로써, 모델은 통합된 프레임워크 내에서 flow 기반 재구성 및 semantic feature 예측을 모두 학습할 수 있다.
본 논문에서 제시하는 Self-Flow는 외부 인코더에 의존하지 않고 모델의 내부 표현만을 활용하기 때문에 단일 모달리티 학습과 다중 모달리티 공동 학습 모두에 자연스럽게 적용될 수 있다. 표준 flow matching 방식과 비교했을 때, 본 Self-Flow는 특히 얼굴이나 손과 같은 복잡한 구조에서 구조적 일관성을 향상시키고, 텍스트 렌더링 정확도와 동영상의 시간적 일관성 또한 개선한다. Self-Flow는 오토인코더 종류에 관계없이 적용 가능하며, 다양한 오토인코더에서 일관된 성능 향상을 보여주었다.
Method
1. Motivation
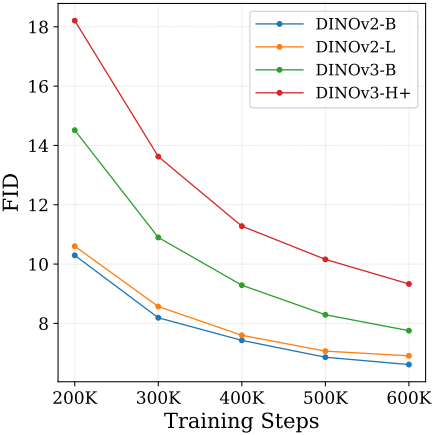
저자들은 외부 정렬 방법인 REPA scaling 실험을 통해 통합 프레임워크의 필요성을 제시하였다. 아래 그래프에서 볼 수 있듯이, 표현력이 강한 모델이 생성 품질을 일관되게 저하시킨다. 가장 작고 약한 모델인 DINOv2-B가 가장 우수한 FID를 달성하는 반면, 가장 강력한 모델인 DINOv3-H+는 가장 낮은 성능을 보인다. 이는 외부 정렬로 인해 생성 모델이 생성 목표와 일치하지 않을 수 있는 고정된 외부 표현에 의존하게 되기 때문이다. 고정된 표현에 의존하는 대신, 생성 프레임워크 자체 내에서 표현력을 강화해야 한다.
2. Dual-Timestep Scheduling
표준 flow matching에서는 모든 토큰에 균일한 noise가 적용되므로, denoising task는 종종 로컬 상관관계만으로도 해결될 수 있다. 모델 전반에 걸쳐 더 강력하고 포괄적인 표현을 학습하도록 유도하기 위해 정보 비대칭성을 도입한다. 즉, 서로 다른 토큰에 서로 다른 noise level을 적용함으로써 모델은 noise가 있는 토큰을 추론할 때 더 깨끗한 토큰을 사용하도록 유도된다. 핵심 과제는 기본적인 생성 역학을 방해하지 않고 이러한 heterogeneous noise를 도입하는 방법이다.
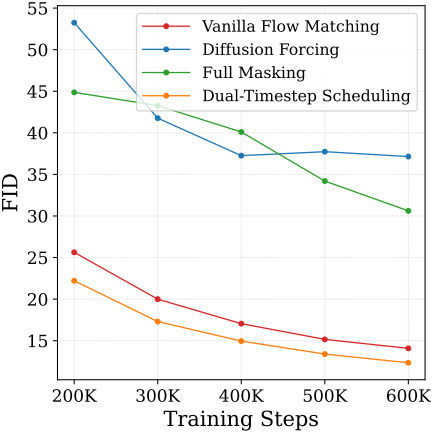
직관적인 전략 중 하나는 토큰 부분집합에 대해 $t = 1$로 무작위 설정하여 해당 토큰들을 완전히 마스킹하는 것이다. 또 다른 방법은 diffusion forcing과 유사하게 각 토큰에 대해 독립적인 noise level을 샘플링하는 것이다. 하지만, 학습과 inference 간의 차이로 인해, 단순한 마스킹과 diffusion forcing 모두 생성 품질을 상당히 저하시킨다. Inference 시에 모델은 낮은 noise level과 높은 noise level 모두에서 균일하게 noise가 포함된 입력을 denoising해야 하는데, 이는 학습 과정에서는 거의 발생하지 않는 상황이다.
본 논문은 이러한 불일치를 해결하기 위해 Dual-Timestep Scheduling을 제안하였다. 핵심 아이디어는 noise 분포에서 두 개의 timestep을 샘플링하는 것이다. 두 noise 중 더 강한 noise는 정보를 손상시키는 역할을 하고, 더 깨끗한 noise는 컨텍스트로 사용된다. 구체적으로, 입력 \(\textbf{x}_0\)가 주어졌을 때 다음과 같이 처리한다.
- 두 개의 timestep을 샘플링: $t, s \sim p(t)$
- 마스킹 비율 \(\mathcal{R}_M \le 0.5\)으로 마스크 샘플링: \(M = \{ i \in \{1, \ldots, N\} \; \vert \; u_i < \mathcal{R}_M, u_i \sim \mathcal{U}(0,1) \}\)
- Dual-Timestep $\boldsymbol{\tau}$ 계산:
이 접근 방식은 강력한 글로벌 관계를 유도하지 못하는 일반적인 homogeneous noising 방식과, 학습 중 inference 동작을 시뮬레이션하지 못하는 완전 heterogeneous noising 방식 사이에서 균형을 유지하면서 토큰별 timestep 분포를 일정하게 유지한다.
흥미롭게도 명시적인 self-supervised loss 없이 일반 flow matching 학습에 Dual-Timestep Scheduling만 적용해도 생성 품질이 약간 향상된다. 직관적으로 이는 입력에 더 깨끗한 정보가 존재하기 때문으로, 이러한 깨끗한 정보는 모델이 denoising task를 수행하는 데 도움이 되며, 결과적으로 모델이 글로벌 관계를 고려하도록 유도하여 생성 능력을 향상시키는 것으로 해석할 수 있다.
3. Self-Flow
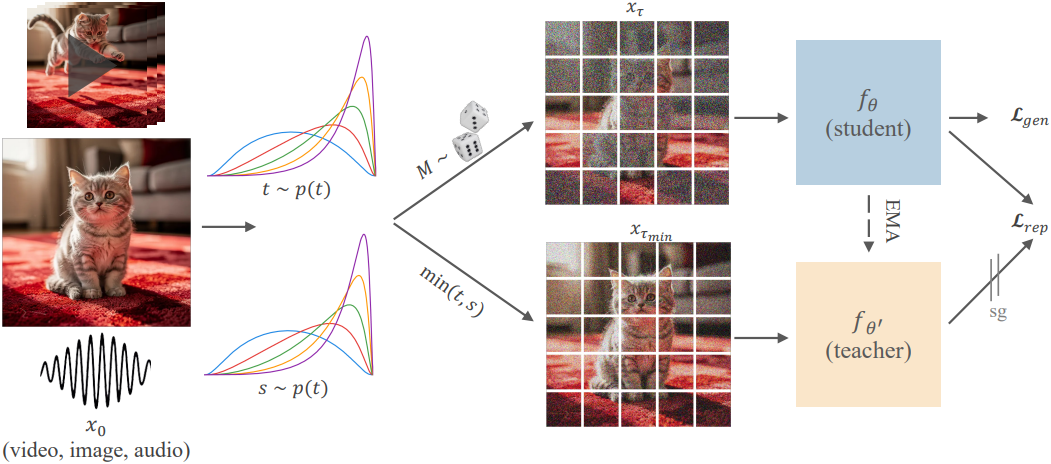
Dual-Timestep Scheduling으로 인해 발생하는 정보 비대칭성을 활용하여 모델이 더 강력한 표현을 학습하도록 유도한다. 위 그림에서 볼 수 있듯이, 두 개의 모델을 유지한다. 하나는 균일하지 않은 level의 noise가 섞인 입력 \(\textbf{x}_\boldsymbol{\tau}\)로부터 학습하는 student \(f_\theta\)이고, 다른 하나는 $τmin = min(τ) ∈ {t, s}의 noise가 섞인 더 깨끗한 입력 \(\textbf{x}_{\tau_\textrm{min}}\)을 관찰하는 EMA teacher \(f_{\theta^\prime}\)이다. 이러한 설정을 바탕으로, student가 불완전하고 손상된 입력으로부터 teacher의 feature를 재구성하도록 학습하는 feature 정렬 loss를 설계할 수 있다.
(\(h_\theta\)는 MLP projection head, $l$과 $k$는 각각 student와 teacher의 layer 인덱스 ($l < k$))
이 task를 수행하기 위해 student는 더 깨끗한 토큰을 적극적으로 활용하여 noise가 많은 토큰에 대한 표현을 추론하고, 단순한 locality를 초월하는 글로벌 연결을 형성하도록 권장된다. 전체 loss는 생성 학습과 표현 학습을 결합한 loss이다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{gen} + \gamma \cdot \mathcal{L}_\textrm{rep} \end{equation}\]Experiments
1. Single Modality Experiments
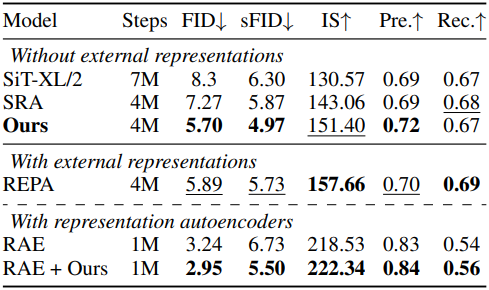
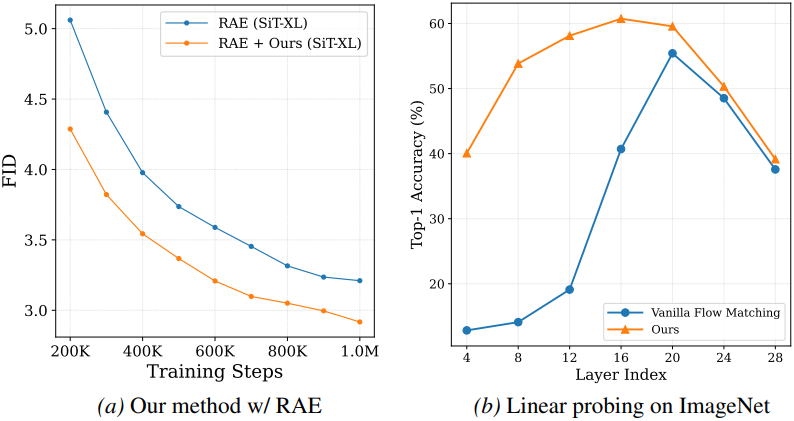
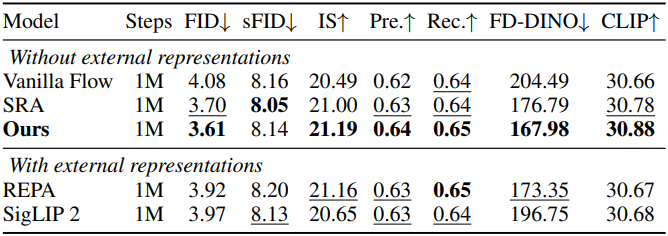
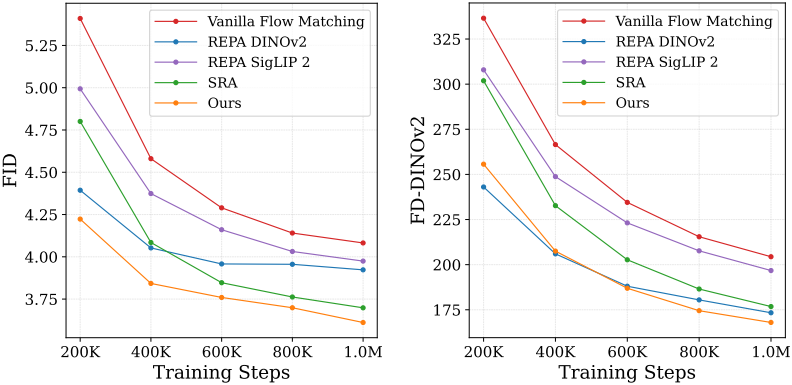
다음은 ImageNet 256$\times$256에서의 이미지 생성 결과이다.
다음은 text-to-image 생성 결과이다.
다음은 동영상 생성 결과이다.
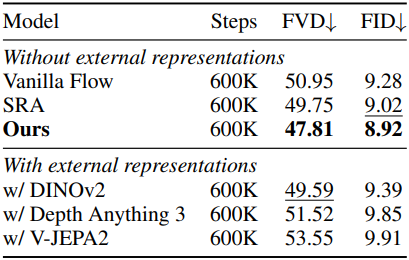
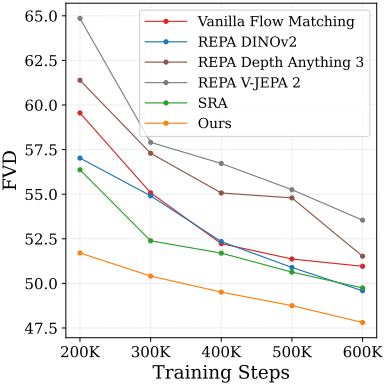
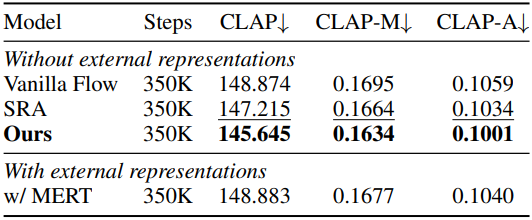
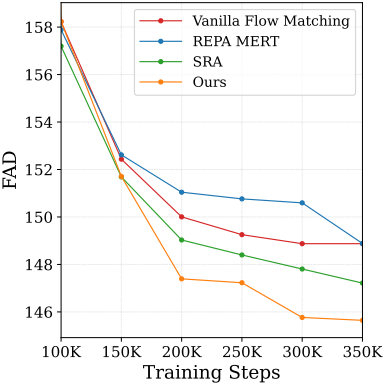
다음은 오디오 생성 결과이다.
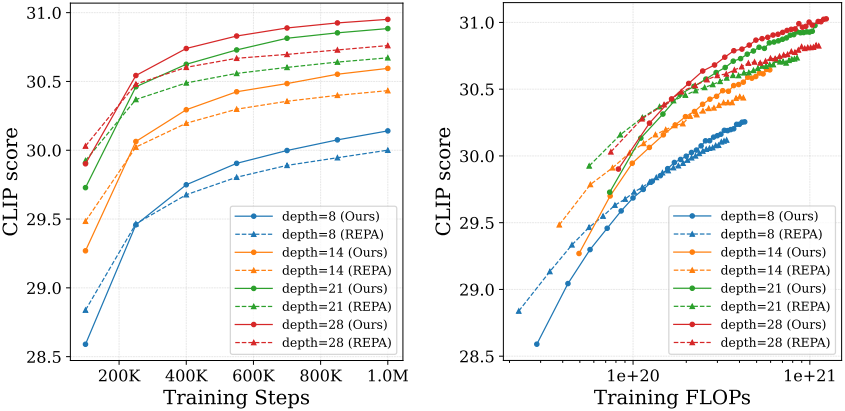
다음은 scaling 결과이다.
2. Multi-Modal Experiments
다음은 멀티모달 실험 결과이다.
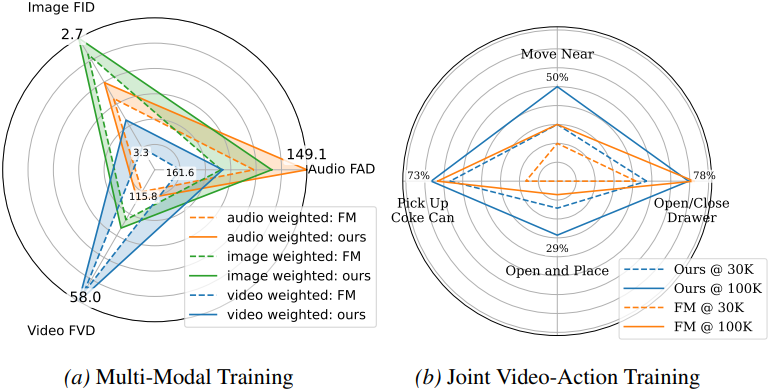
다음은 joint video-action prediction 모델에 대한 시뮬레이션 비교 예시이다.

3. Qualitative Results
다음은 타이포그래피 이미지 생성에 대한 비교 예시들이다.

다음은 (위) text-to-image와 (아래) text-to-video에 대한 비교 예시들이다.

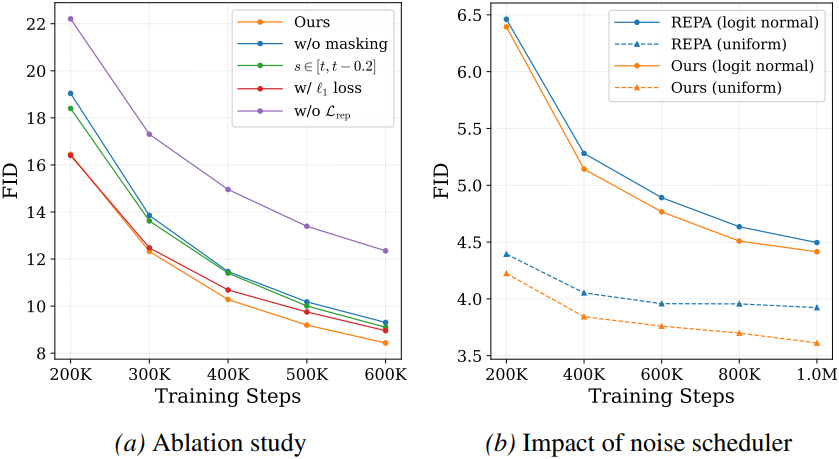
4. Ablation Study
다음은 ablation study 결과이다.