[논문리뷰] Flow-GRPO: Training Flow Matching Models via Online RL
NeurIPS 2025. [Paper] [Github]
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, Wanli Ouyang
CUHK | Tsinghua University | Kuaishou Technology | Nanjing University | Shanghai AI Laboratory
8 May 2025
Introduction
강화 학습(RL)을 이용한 flow model 학습에는 몇 가지 중요한 과제가 있다.
- Flow model은 상미분 방정식(ODE) 기반의 deterministic한 생성 프로세스를 사용하기 때문에 inference 과정에서 확률적 샘플링이 불가능하다. 반면, RL은 확률적 샘플링을 통해 환경을 탐색하고, 다양한 action을 시도하며 학습하고, reward를 기반으로 성능을 향상시킨다.
- Online RL은 학습 데이터 수집을 위해 효율적인 샘플링에 의존하지만, flow model은 일반적으로 각 샘플을 생성하는 데 많은 반복적인 step을 거쳐야 하므로 효율성이 떨어진다. 이러한 문제는 모델 스케일이 클수록 더욱 두드러진다.
이러한 문제들을 해결하기 위해, 본 논문에서는 두 가지 핵심 전략을 사용하여 text-to-image (T2I) 생성을 위한 flow model에 GRPO를 통합한 Flow-GRPO를 제안하였다.
- 기존 flow model의 deterministic한 특성을 극복하기 위해 ODE-to-SDE로 전략을 채택하였다. ODE 기반 flow를 동등한 SDE 프레임워크로 변환함으로써, 원래의 marginal distribution을 유지하면서 무작위성을 도입한다.
- Online RL에서 샘플링 효율성을 향상시키기 위해, inference 시에는 전체 schedule을 유지하면서 학습 시에는 denoising step을 줄이는 *Denoising Reduction**을 적용하였다.
Method
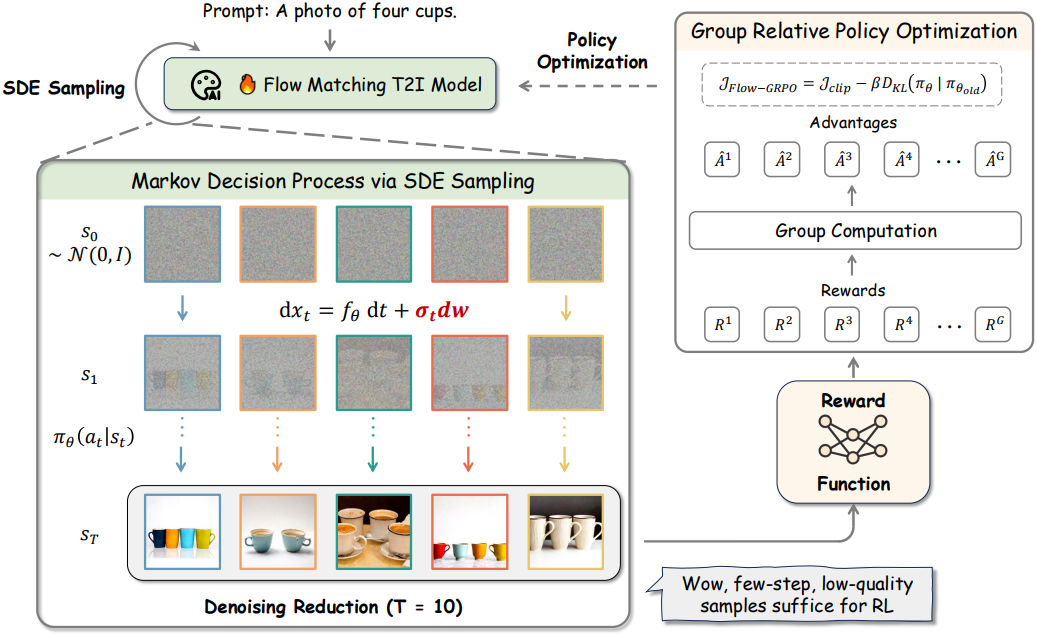
GRPO on Flow Matching
RL은 누적 reward를 최대화하는 policy를 학습하는 것을 목표로 한다. 이는 정규화된 objective를 사용하여 policy \(\pi_\theta\)를 최적화하는 문제로 표현된다.
\[\begin{equation} \max_\theta \mathbb{E}_{(\textbf{s}_0, \textbf{a}_0, \ldots, \textbf{s}_T, \textbf{a}_T) \sim \pi_\theta} \left[ \sum_{t=0}^T \left( R(\textbf{s}_t, \textbf{a}_t) - \beta D_\textrm{KL} (\pi_\theta (\cdot \vert \textbf{s}_t) \| \pi_\textrm{ref} (\cdot \vert \textbf{s}_t)) \right) \right] \end{equation}\]PPO와 같은 다른 policy 기반 방법과는 달리, GRPO는 그룹 상대적 공식을 도입하여 advantage를 추정하는 간소화된 대안을 제공한다.
프롬프트 $\textbf{c}$가 주어지면 flow model \(p_\theta\)는 $G$개의 개별 이미지 \(\{\textbf{x}_0^i\}_{i=1}^G\)와 해당 역시간 궤적 \(\{(\textbf{x}_T^i, \textbf{x}_{T-1}^i, \cdots, \textbf{x}_0^i)\}_{i=1}^G\)을 샘플링한다. 그런 다음, $i$번째 이미지의 advantage는 다음과 같이 group-level reward를 정규화하여 계산된다.
\[\begin{equation} \hat{A}_t^i = \frac{R(\textbf{x}_0^i, \textbf{c}) - \textrm{mean}(\{R(\textbf{x}_0^i, \textbf{c})\}_{i=1}^G)}{\textrm{std}(\{R(\textbf{x}_0^i, \textbf{c})\}_{i=1}^G)} \end{equation}\]GRPO는 \(\mathcal{J}_\textrm{Flow-GRPO} (\theta)\)를 최대화하여 policy 모델을 최적화한다.
\[\begin{aligned} \mathcal{J}_\textrm{Flow-GRPO} (\theta) &= \mathbb{E}_{\textbf{c} \sim \mathcal{C}, \{\textbf{x}^i\}_{i=1}^G \sim \pi_{\theta_\textrm{old}} (\cdot \vert \textbf{c})} f (r, \hat{A}, \theta, \epsilon, \beta) \\ f(r, \hat{A}, \theta, \epsilon, \beta) &= \frac{1}{G} \sum_{i=1}^G \frac{1}{T} \sum_{t=0}^{T-1} \left( \min \left( r_t^i (\theta) \hat{A}_t^i, \textrm{clip} \left( r_t^i (\theta), 1 - \epsilon, 1 + \epsilon \right) \hat{A}_t^i \right) - \beta D_\textrm{KL} (\pi_\theta \| \pi_\textrm{ref}) \right) \\ r_t^i (\theta) &= \frac{p_\theta (\textbf{x}_{t-1}^i \mid \textbf{x}_t^i, \textbf{c})}{p_{\theta_\textrm{old}} (\textbf{x}_{t-1}^i \mid \textbf{x}_t^i, \textbf{c})} \end{aligned}\]From ODE to SDE
GRPO는 advantage 추정 및 탐색을 위한 다양한 궤적을 생성하기 위해 확률적 샘플링에 의존한다. Flow model은 forward process에 deterministic한 상미분 방정식(ODE)을 사용한다.
\[\begin{equation} \textrm{d}\textbf{x}_t = \textbf{v}_t \textrm{d}t \end{equation}\]여기서 $v_t$는 Flow Matching objective를 통해 학습된다. 일반적인 샘플링 방법은 이 ODE를 discretize하여 연속적인 timestep 간에 일대일 매핑을 생성하는 것이다.
이 deterministic한 접근 방식은 두 가지 주요 측면에서 GRPO policy 업데이트 요구 사항을 충족하지 못한다.
- $r_t^i (\theta)$는 \(p(\textbf{x}_{t−1} \mid \textbf{x}_t, c)\)를 계산해야 하는데, 이는 divergence 추정으로 인해 deterministic dynamics 하에서 계산 비용이 많이 든다.
- RL은 탐색에 의존한다. 무작위성이 감소하면 학습 효율이 크게 떨어진다.
이러한 한계를 해결하기 위해, 저자들은 deterministic Flow-ODE를 모든 timestep에서 원래 모델의 marginal probability density와 일치하는 등가 SDE로 변환한다. Marginal distribution을 보존하는 reverse-time SD는 다음과 같다.
\[\begin{equation} \textrm{d}\textbf{x}_t = \left( \textbf{v}_t (\textbf{x}_t) - \frac{\sigma_t^2}{2} \nabla \log p_t (\textbf{x}_t) \right) \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \end{equation}\]($\textrm{d}\textbf{w}$는 Wiener process increment, \(\sigma_t\)는 stachasticity의 수준을 제어)
증명)
ODE $\textrm{d}\textbf{x}_t = \textbf{v}_t \textrm{d}t$에 대한 marginal probability density $p_t (\textbf{x})$는 다음과 같이 변한다. $$ \begin{equation} \partial_t p_t (\textbf{x}) = - \nabla \cdot [\textbf{v}_t (\textbf{x}_t, t) p_t (\textbf{x})] \end{equation} $$ SDE의 일반적인 형태는 다음과 같다. $$ \begin{equation} \textrm{d} \textbf{x}_t = f_\textrm{SDE} (\textbf{x}_t, t) \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \end{equation} $$ 이 SDE의 $p_t (\textbf{x})$는 Fokker–Planck equation에 의해 다음과 같이 변한다. $$ \begin{equation} \partial_t p_t (\textbf{x}) = - \nabla \cdot [f_\textrm{SDE} (\textbf{x}_t, t) p_t (\textbf{x})] + \frac{1}{2} \nabla^2 [\sigma_t^2 p_t (\textbf{x})] \end{equation} $$ ODE와 SDE의 marginal distribution이 같아지려면 두 $\partial_t p_t (\textbf{x})$가 같아야 한다. $$ \begin{aligned} - \nabla \cdot [\textbf{v}_t (\textbf{x}_t, t) p_t (\textbf{x})] &= - \nabla \cdot [f_\textrm{SDE} (\textbf{x}_t, t) p_t (\textbf{x})] + \frac{1}{2} \nabla^2 [\sigma_t^2 p_t (\textbf{x})] \\ &= - \nabla \cdot [f_\textrm{SDE} (\textbf{x}_t, t) p_t (\textbf{x})] + \frac{\sigma_t^2}{2} \nabla \cdot (\nabla p_t (\textbf{x})) \\ &= - \nabla \cdot [f_\textrm{SDE} (\textbf{x}_t, t) p_t (\textbf{x})] + \frac{\sigma_t^2}{2} \nabla \cdot (\nabla p_t (\textbf{x})) \\ \end{aligned} $$ 정리하면 $f_\textrm{SDE}$는 다음과 같다. $$ \begin{equation} f_\textrm{SDE} = \textbf{v}_t (\textbf{x}_t, t) + \frac{\sigma_t^2}{2} \nabla \log p_t (\textbf{x}) \end{equation} $$ Forward SDE $\textrm{d} \textbf{x}_t = f_\textrm{SDE} (\textbf{x}_t, t) \textrm{d}t + \sigma_t \textrm{d}\textbf{w}$에 대한 reverse-time SDE는 다음과 같다. $$ \begin{equation} \textrm{d}\textbf{x}_t = [f_\textrm{SDE}(\textbf{x}_t, t) - \sigma_t^2 \nabla \log p_t (\textbf{x}_t)] \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \end{equation} $$ $f_\textrm{SDE}$를 대입하면 reverse-time SDE는 다음과 같다. $$ \begin{aligned} \textrm{d}\textbf{x}_t &= \left[ \textbf{v}_t (\textbf{x}_t) + \frac{\sigma_t^2}{2} \nabla \log p_t (\textbf{x}_t) - \sigma_t^2 \nabla \log p_t (\textbf{x}_t) \right] \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \\ &= \left( \textbf{v}_t (\textbf{x}_t) - \frac{\sigma_t^2}{2} \nabla \log p_t (\textbf{x}_t) \right) \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \end{aligned} $$
Rectified flow의 경우, reverse-time SD는 다음과 같다.
증명)
$\textbf{x}_t = (1-t) \textbf{x}_0 + t \textbf{x}_1$에 대해 marginal score는 다음과 같다. $$ \begin{aligned} \nabla \log p_t (\textbf{x}_t) &= \mathbb{E} [\nabla \log p_{t \vert 0} (\textbf{x}_t \vert \textbf{x}_0) \mid \textbf{x}_t] \\ &= \mathbb{E} [\nabla \log \mathcal{N} (\textbf{x}_t \mid (1 - t) \textbf{x}_0, t^2 \textbf{I}) \mid \textbf{x}_t] \\ &= \mathbb{E} [ - \frac{\textbf{x}_t - (1-t) \textbf{x}_0}{t^2} \mid \textbf{x}_t] \\ &= \mathbb{E} [ - \frac{\textbf{x}_1}{t} \mid \textbf{x}_t] \\ &= -\frac{1}{t} \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t] \end{aligned} $$ Velocity field는 다음과 같다. $$ \begin{aligned} \textbf{v}_t (\textbf{x}) &= \mathbb{E} [\textbf{x}_1 - \textbf{x}_0 \mid \textbf{x}_t = \textbf{x}] \\ &= - \mathbb{E} [\textbf{x}_0 \mid \textbf{x}_t = \textbf{x}] + \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t = \textbf{x}] \\ &= - \mathbb{E} \left[ \frac{\textbf{x}_t - t \textbf{x}_1}{1-t} \mid \textbf{x}_t = \textbf{x} \right] + \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t = \textbf{x}] \\ &= -\frac{\textbf{x}}{1-t} + \frac{t}{1-t} \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t = \textbf{x}] + \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t = \textbf{x}] \\ &= -\frac{\textbf{x}}{1-t} + \frac{1}{1-t} \mathbb{E} [\textbf{x}_1 \mid \textbf{x}_t = \textbf{x}] \\ &= -\frac{\textbf{x}}{1-t} - \frac{t}{1-t} \nabla \log p_t (\textbf{x}) \\ \end{aligned} $$ Marginal score를 구하면 다음과 같다. $$ \begin{equation} \nabla \log p_t (\textbf{x}) = -\frac{\textbf{x}}{t} - \frac{1-t}{t} \textbf{v}_t (\textbf{x}) \end{equation} $$ 따라서, reverse-time SDE는 다음과 같다. $$ \begin{equation} \textrm{d}\textbf{x}_t = \left[ \textbf{v}_t (\textbf{x}_t) + \frac{\sigma_t^2}{2t} (\textbf{x}_t + (1 - t) \textbf{v}_t (\textbf{x}_t)) \right] \textrm{d}t + \sigma_t \textrm{d}\textbf{w} \end{equation} $$
Euler-Maruyama discretization을 적용하면 최종 update rule은 다음과 같다.
즉, Policy \(\pi_\theta (\textbf{x}_{t-1} \mid \textbf{x}_t, \textbf{c})\)는 isotropic Gaussian distribution이다. 따라서 \(\pi_\theta\)와 \(\pi_\textrm{ref}\) 사이의 KL divergence를 다음과 같이 closed form으로 계산할 수 있다.
\[\begin{aligned} D_\textrm{KL} (\pi_\theta \| \pi_\textrm{ref}) &= \frac{\| \bar{\textbf{x}}_{t + \Delta t, \theta} - \bar{\textbf{x}}_{t + \Delta t, \textrm{ref}} \|}{2 \sigma_t^2 \Delta t} \\ &= \frac{\Delta t}{2} \left( \frac{\sigma_t (1-t)}{2t} + \frac{1}{\sigma_t} \right)^2 \| \textbf{v}_\theta (\textbf{x}_t, t) - \textbf{v}_\textrm{ref} (\textbf{x}_t, t) \|^2 \end{aligned}\]저자들은 noise level을 제어하는 hyperparameter $a$를 사용한 \(\sigma_t\)를 사용하였다.
\[\begin{equation} \sigma_t = a \sqrt{\frac{t}{1-t}} \end{equation}\]Denoising Reduction
고품질 이미지를 생성하기 위해 flow model은 일반적으로 많은 denoising step을 필요로 하므로 online RL에서 데이터 수집 비용이 많이 든다. 그러나 저자들은 online RL 학습에서 큰 timestep이 불필요하다는 것을 발견했다. 샘플 생성 단계에서 denoising step을 크게 줄이면서도 inference 시에는 기존의 denoising step을 유지하여 고품질 샘플을 얻을 수 있다. 저자들은 학습 시에 timestep $T=10$으로 설정하고, inference 시에 SD3.5-M의 기본 설정값인 $T=40$을 사용했다.
Experiments
1. Main Results
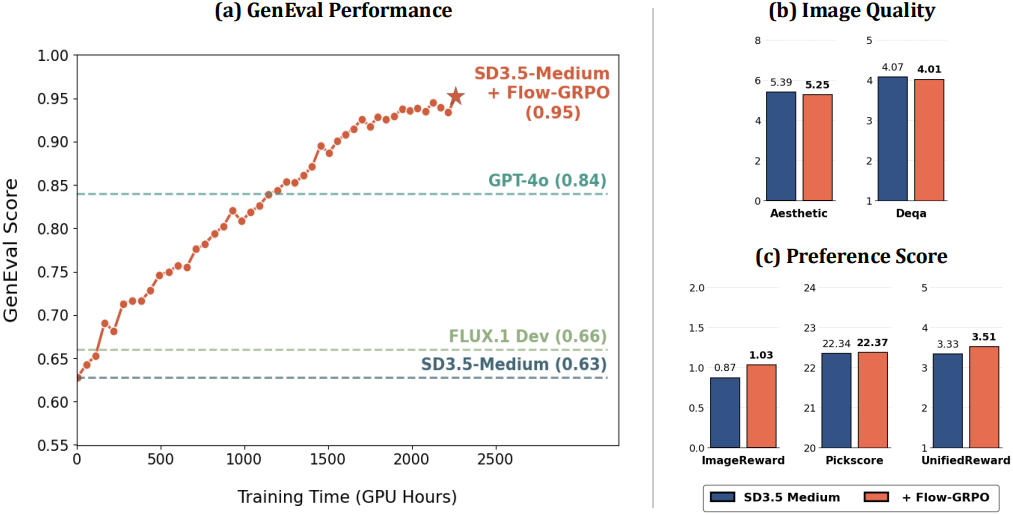
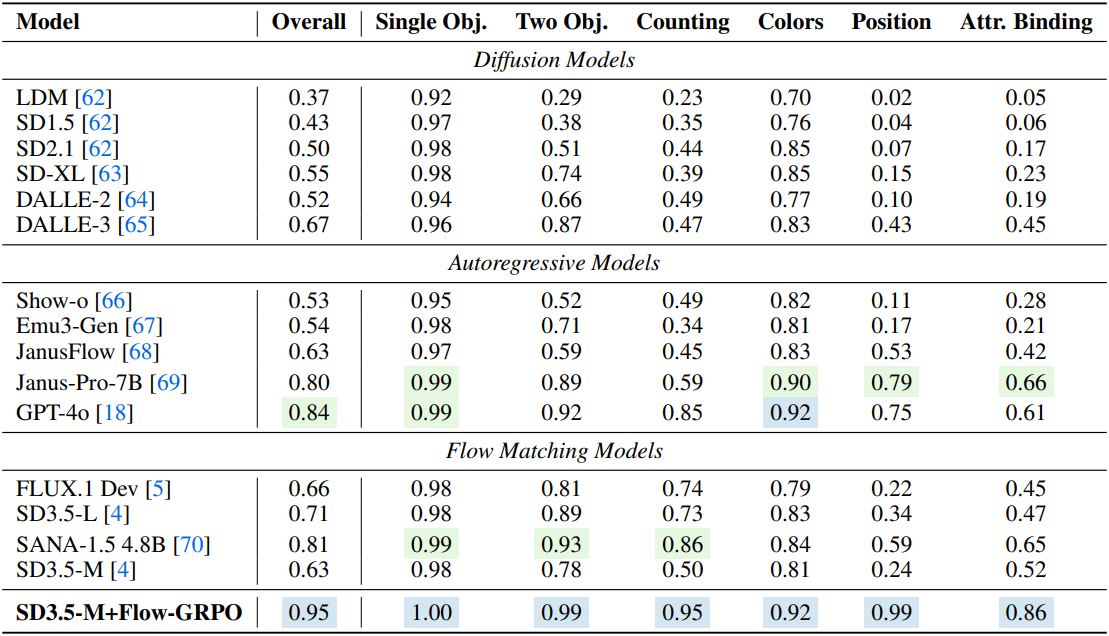
다음은 GenEval 벤치마크에 대한 비교 결과이다.

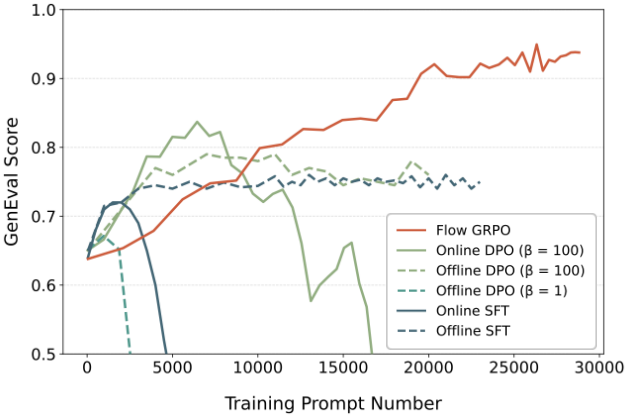
다음은 다른 정렬 방법과의 비교 결과이다. (Compositional generation)
2. Analysis
다음은 KL divergence의 영향을 비교한 결과이다.
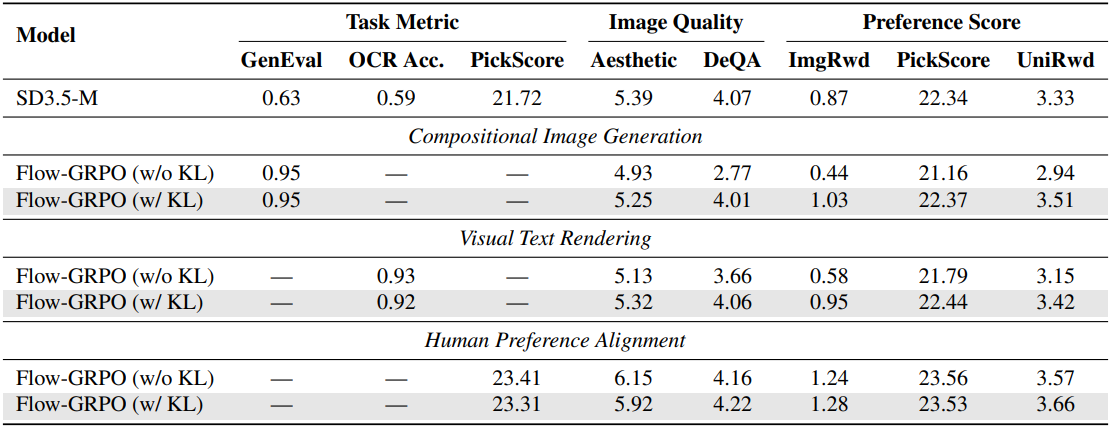

다음은 Denoising Reduction에 대한 결과이다.
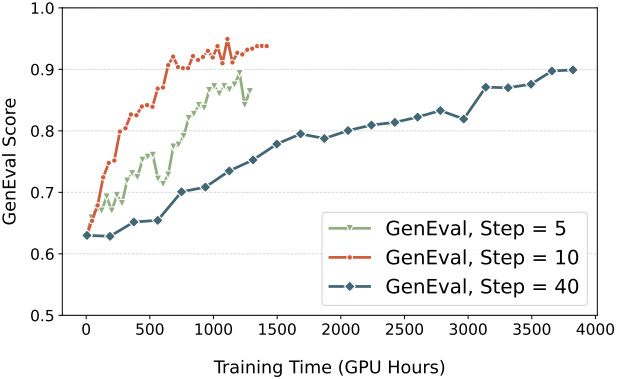
다음은 $a$에 대한 ablation study 결과이다.
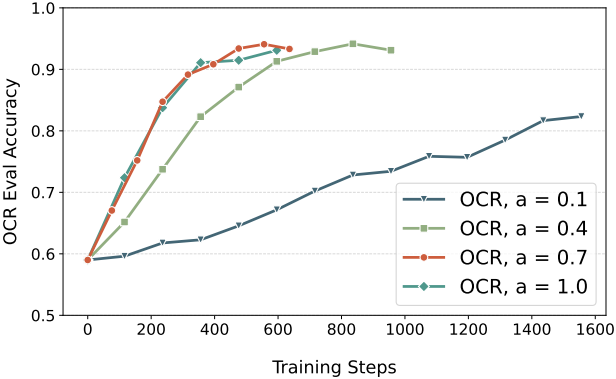
다음은 group 크기 $G$에 대한 ablation study 결과이다.
다음은 GenEval로 생성된 데이터셋으로 학습된 모델에 대한 T2I-CompBench++ 결과이다.

다음은 일반화 성능에 대한 비교 결과이다. (Unseen Objects: 처음 보는 클래스로 평가, Unseen Counting: 2~4개의 object에 대해 학습된 모델로 더 많은 object에 대해 평가)
