[논문리뷰] GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
arXiv 2026. [Paper] [Page]
Katharina Schmid, Nicolas von Lützow, Jozef Hladký, Angela Dai, Matthias Nießner
Technical University of Munich | Huawei Technologies
22 May 2026

Introduction
본 논문에서는 멀티뷰 3D reconstruction과 Trellis.2의 강력한 generative 3D prior를 긴밀하게 결합하는 새로운 접근 방식을 소개한다. 장면 reconstruction을 장면 청크 집합에 대한 조건부 3D 생성으로 구성함으로써, Trellis.2의 충실도, 완전성, 사실성을 계승하면서 대규모 reconstruction이 가능하다.
Trellis.2의 shape generative prior를 멀티뷰 장면 청크 생성을 지원하도록 재구성하기 위해, 본 논문에서는 순열 불변적인 방식으로 포즈를 아는 멀티뷰 이미지 정보를 생성 모델에 주입하는 projection 기반 컨디셔닝 경로를 제안하였다. 이를 통해 생성된 geometry와 공간 정렬을 정밀하게 제어할 수 있다. 합성 장면 데이터에 대한 parameter-efficient fine-tuning을 통해 사전 학습된 prior를 유지함으로써, 본 방법은 실내 장면의 충실하고 편집 가능한 PBR 메쉬를 생성하여, 현재의 reconstruction 능력과 콘텐츠 제작 시나리오에 필요한 품질 간의 격차를 크게 줄였다.
Method
본 논문에서는 카메라 intrinsic 및 extrinsic \(\{K_n, T_n\}_{n=1}^N\)과 함께 sparse하고 순서가 없는 $N$개의 RGB 이미지 \(\{I_n\}_{n=1}^N\)으로부터 완전하고 높은 충실도의 3D 장면을 재구성하는 문제를 다룬다. 출력은 PBR material이 적용된 장면 수준 메쉬 $\mathcal{M}$으로, 렌더링 및 제작 파이프라인에 직접 통합하기에 적합하다. 본 접근 방식은 장면 reconstruction을 전체 장면을 덮는 중첩된 장면 청크 집합의 공동 생성으로 간주함으로써, 멀티뷰 reconstruction과 강력한 generative 3D prior를 긴밀하게 결합한다. 이를 위해 Trellis.2의 object-level generative prior를 활용하고, 장면 청크 생성을 공간적으로 뒷받침하는 멀티뷰 컨디셔닝을 도입하여 장면 수준 생성에 맞게 재구성하였다.
1. Multi-view scene chunk generation
장면 청크
본 논문에서는 장면 청크 $c$를 자체 정규 좌표계에서 고정 크기의 3D 볼륨 $V_c = [0, 1]^3$으로 정의하고, 이를 월드 좌표계에 배치하는 translation $t_c \in \mathbb{R}^3$과 쌍을 이룬다고 가정한다. 각 청크 $c$는 $c$를 관찰하는 카메라들의 집합인 입력 뷰 \(\mathcal{V}_c \subseteq \{1, \ldots, N\}\)과 연결된다. 생성 모델 $\Phi$는 청크의 볼륨에 대한 정의와 카메라 포즈를 아는 뷰 \(\{(I_n, K_n, T_n^{-1} T_c)\}_{n \in \mathcal{V}_c}\)를 입력으로 받는다. 여기서 $T_c$는 청크를 월드 좌표계로 변환하는 변환이다. 생성 모델은 $V_c$ 내의 geometry와 외형을 나타내는 3D latent $z^{(c)}$를 생성한다.
Generative prior
본 논문에서는 SOTA 3D shape 생성 모델인 Trellis.2를 기반으로 생성 모델 $\Phi$를 구현했다. Trellis.2는 먼저 대략적인 occupancy를 예측한 후, 고정밀 shape과 PBR 텍스처를 생성하여 고품질 object를 생성한다. 이러한 요소들은 각각의 latent feature에 작용하는 flow-matching denoiser이다.
Trellis.2는 cross-attention을 통해 포즈를 모르는 단일 RGB 이미지를 입력으로 받도록 설계되었다. 생성된 콘텐츠의 위치, 방향, 크기는 입력에 의해 지정되지 않고 모델의 학습 분포에 의해 implicit하게 결정된다. 이러한 디자인은 고품질 object 생성을 가능하게 하지만, 장면 reconstruction에는 적합하지 않다. 대규모 장면을 촬영하려면 모델이 일관된 데이터셋으로 처리해야 하는 여러 뷰가 필요하며, 생성된 콘텐츠를 알려진 좌표계에 배치하여 인접한 청크들이 일관성 있게 합쳐야 하기 때문이다.
위치 기반 멀티뷰 컨디셔닝
본 논문에서는 뷰 순서에 관계없이 일정한 형태로 멀티뷰 이미지를 생성 모델 $\Phi$에 전달하는 3D 컨디셔닝 경로라는 하나의 디자인을 통해 두 가지 문제점을 모두 해결하였. 연관된 뷰들 \(\mathcal{V}_c\)를 갖는 청크 $c$가 주어졌을 때, 각 이미지를 독립적으로 인코딩하고, 결과로 얻은 뷰별 feature를 청크의 전체 볼륨에 걸쳐 3D 그리드로 변환한 다음, 순열에 관계없이 일정한 방식으로 뷰 간 집계를 수행하여 청크의 3D 컨디셔닝 $G^{(c)}$를 얻는다.
각 입력 이미지는 DINOv3로 인코딩하여 각 뷰에 대한 dense 2D feature map $F_n$을 생성한다. 각 뷰 \(n \in \mathcal{V}_c\)에 대해 $F_n$을 청크의 볼륨에 정의된 뷰별 3D feature grid \(G_n^{(c)}\)으로 변환한다. 각 voxel $x \in V_c$는 뷰의 이미지 평면으로 projection되고, 이에 해당하는 feature가 추출된다.
\[\begin{equation} \pi_n (x) = K_n T_n^{-1} (x + t_c), \quad G_n^{(c)} (x) = F_n (\pi_n (x)) \end{equation}\]이 projection 단계는 모든 컨디셔닝 feature를 청크 좌표계의 명시적인 3D 위치에 연결한다.
마지막으로, 뷰별 그리드 \(\{G_n^{(c)}\}_{n \in \mathcal{V}_c}\)는 IBRNet 방식을 사용하여 하나의 3D 컨디셔닝 그리드 $G^{(c)}$로 집계된다. 집계 결과는 뷰 간, 그리고 임의의 $\vert \mathcal{V}_c \vert$에 대해 순열 불변성을 가지므로, 뷰 순서 없이도 가변적인 수의 입력 이미지를 처리할 수 있다. 뷰별 feature \(\{f_i\}_{i=1}^N\)을 가진 각 voxel에 대해, 먼저 뷰 사이의 통계를 계산한다.
\[\begin{equation} \mu = \frac{1}{N} \sum_i f_i, \quad \sigma^2 = \frac{1}{N} \sum_i f_i^2 - \mu^2 \end{equation}\]이는 뷰 사이에 공유되는 글로벌 컨텍스트 역할을 한다. 각 뷰의 feature는 동일한 입력을 공유하는 두 개의 작은 MLP에 의해 정제되고 logit이 할당된다.
\[\begin{equation} f_i^\prime = \textrm{MLP}_\textrm{feat} ([f_i, \mu, \sigma^2]), \quad w_i = \textrm{MLP}_\textrm{weight} ([f_i, \mu, \sigma^2]) \end{equation}\]최종 voxel feature는 다음과 같다.
\[\begin{equation} f_\textrm{out} = \mu + \sum_i \alpha_i f_i^\prime \end{equation}\]\(\textrm{MLP}_\textrm{feat}\)의 마지막 layer는 0으로 초기화되어 모듈이 평균 $\mu$에서 학습을 시작한다.
컨디셔닝 주입
집계된 3D 조건 $G^{(c)}$는 denoiser $\Phi$에 각 block에 residual하게 주입되며, 초기화 시 사전 학습된 모델의 동작을 유지하기 위해 0으로 초기화된 layer를 통해 voxel-wise로 더해진다. $G^{(c)}$는 청크의 좌표계에서 직접 정의되므로 모든 컨디셔닝 신호는 명확한 위치 의미를 가지며, 뷰 일관성과 포즈 제어는 모델이 학습해야 하는 속성이 아니라 디자인의 직접적인 결과로 나타난다.
Training
$\Phi$의 가중치에 low-rank LoRA adapter를 사용하여 컨디셔닝 경로를 학습하고, 나머지 Trellis.2 파라미터는 고정한다. 학습은 합성 장면 데이터를 사용하여 수행되며, 합성 장면에서 추출한 GT 청크 latent에 대해 학습된다.
2. Scene reconstruction at test time
테스트 시점에, 이전에 보지 못한 장면의 정렬되지 않은 RGB 이미지 집합 \(\{I_n\}_{n=1}^N\)이 주어지면, 장면 수준의 PBR 메쉬 $\mathcal{M}$을 생성한다.
Scene calibration and chunking
Inference 시점에 입력 이미지는 카메라 포즈를 모르는 상태이므로, 먼저 COLMAP으로 카메라 intrinsic \(\{K_n\}\), extrinsic \(\{T_n\}\), 그리고 장면의 sparse한 포인트 클라우드 \(P \subset \mathbb{R}^3\)를 복원한다. $P$에 outlier 필터링을 적용하고, 필터링된 포인트들을 이용하여 장면의 extent \(\mathcal{B} \subset \mathbb{R}^3\)를 추정한다. 추정된 $\mathcal{B}$를 바탕으로 장면 볼륨을 청크 집합 \(\mathcal{C} = \{c_1, \ldots, c_K\}\)로 분할한다. 각 청크는 자체 정규 좌표계에서 고정 크기 정육면체 $V_c$를 차지하며, translation \(t_c \in \mathbb{R}^3\)를 통해 월드 좌표계로 이동한다. 인접한 청크들은 미리 정해진 최소 여백 $m$만큼 겹치며, 이 영역들은 공동 생성 과정에서 청크들이 정보를 교환하는 영역으로 사용된다.
글로벌 3D 컨디셔닝
각 청크별로 컨디셔닝 그리드 $G^{(c)}$를 독립적으로 계산하는 대신, 전체 장면 볼륨에 걸쳐 글로벌 컨디셔닝 그리드 $G$를 한 번 계산하고 청크별 컨디셔닝 $G^{(c)}$를 잘라내어 추출한다. 구체적으로, 뷰별 projection을 통해 각 인코딩된 이미지 $F_n$을 장면 크기의 voxel grid로 변환하고, 뷰 전체에 걸쳐 집계하여 $G$를 얻는다.
Occupancy 생성의 경우, $G$는 occupancy latent의 해상도에서 dense하게 정의된다. 반면, 예측된 occupancy 위에 정의된 더 높은 해상도의 sparse latent를 사용하는 shape 생성 및 texture 생성의 경우에는, feature lifting 및 집계 역시 해당 sparse한 고해상도 voxel 구조 상에서 수행된다. 이후 각 청크 $c$에 대한 컨디셔닝 정보 $G^{(c)}$는 $G$를 각 $V_c$ 영역으로 잘라 얻는다.
Joint chunk generation
모든 청크는 $\Phi$에 의해 하나의 flow-matching 궤적을 따라 MultiDiffusion 방식으로 공동 생성된다. 전체 장면 볼륨을 덮는 global noisy latent grid $z_t$를 유지한다. 각 step $t$에서 각 청크 $c \in \mathcal{C}$에 대해 latent crop \(z_t^{(c)}\)를 추출하고 청크별 denoiser를 적용하여 청크별 예측 \(\hat{z}_{t-1}^{(c)}\)를 얻는다. 청크별 예측은 중첩 영역에서 평균을 내어 다음 global latent grid $z_{t−1}$로 병합된다.
\[\begin{equation} z_{t-1} (x) = \frac{1}{\sum_{c \in \mathcal{C}} M_c (x)} \sum_{c \in \mathcal{C}} M_c (x) \hat{z}_{t-1}^{(c)} (x) \end{equation}\]($x$는 글로벌 장면 그리드의 voxel을 인덱싱, \(M_c (x) \in \{0, 1\}\)은 $x$가 $V_c$ 내에 있는지 여부)
이러한 집계는 생성 과정 전체에 걸쳐 청크 경계의 일관성을 유지한다. Shape 및 texture 생성의 경우, 청크 경계에 위치한 voxel들은 집계에 기여하지는 않지만, 집계의 결과에 의해 업데이트는 되도록 하였다. 이러한 방식은 시각적으로 더 자연스러운 경계 연결을 만들어낸다다. 마지막 단계가 끝나면, global latent grid $z_0$는 각각의 Trellis.2 디코더에 의해 최종적인 PBR material들을 갖는 장면 메쉬 $\mathcal{M}$으로 디코딩된다.
Experiments
- 데이터셋
- SAGE-10k: Trellis로 생성한 PBR material과 object들로 구성된 합성 실내 장면
- 3D-FRONT: SAGE-10k에 창문과 문이 없기 때문에 occupancy 생성 학습에 일부 장면 사용
1. Reconstruction Results
다음은 현실 장면에 대한 비교 결과이다.
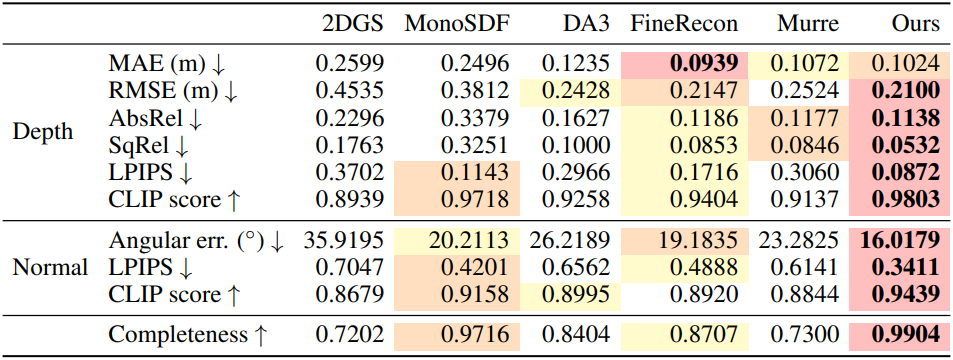


다음은 합성 장면에 대한 비교 결과이다.
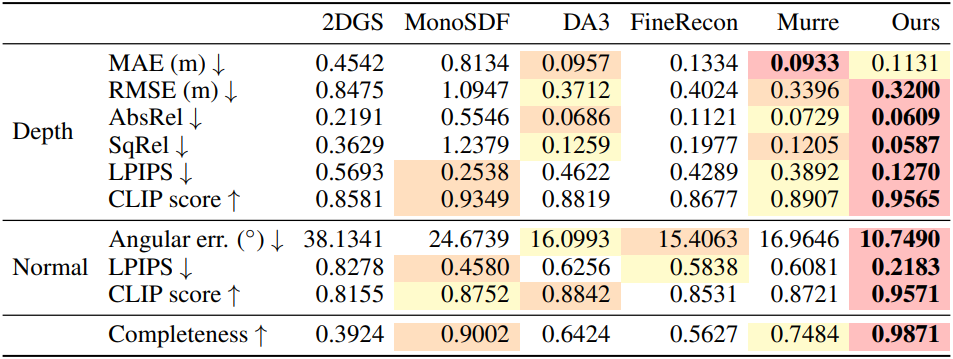

2. Ablations
다음은 3D 컨디셔닝 경로와 입력 뷰 수에 대한 ablation 결과이다. (vanilla는 사전 학습된 Trellis.2, no3Dcond는 3D 컨디셔닝 없이 fine-tuning)

3. PBR Texture and Relighting
다음은 재구성된 ScanNet++ 장면들에 대한 PBR 결과이다.

다음은 relighting 결과이다.
