[논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
ICML 2026. [Paper] [Page] [Github]
Xiaoxuan He, Siming Fu, Zeyue Xue, Weijie Wang, Ruizhe He, Yuming Li, Dacheng Yin, Shuai Dong, Haoyang Huang, Hongfa Wang, Nan Duan, Bohan Zhuang
Zhejiang University | Joy Future Academy | Tsinghua University
15 May 2026
Introduction
Video diffusion model을 미적 품질, 물리적 타당성, 프롬프트를 충실히 만족하는 지 등 인간의 선호도에 맞추는 것은 여전히 중요한 과제이다. Flow-GRPO나 Dance-GRPO와 같은 최근 방법들은 GRPO를 동영상 생성에 성공적으로 적용하여 생성 품질을 크게 향상시켰다.
그러나 근본적인 계산상의 장벽이 여전히 존재한다. Video diffusion model은 긴 denoising 궤적에 걸쳐 시공간 latent를 통해 gradient를 backpropagation해야 한다. 기존 GRPO 방식들은 모든 timestep에서 전체 궤적에 대한 gradient를 계산해야 한다. 이는 엄청난 메모리 소비를 초래하고 학습 처리량을 심각하게 제한한다. 14B 동영상 모델을 정렬하는 데에는 일반적으로 수백 일의 GPU hour가 소요된다.
효율성 개선 방법들은 sliding window 서브샘플링을 통해 계산 비용을 줄이려고 시도하였다. 즉, 연속적인 timestep 중 일부만을 사용하여 학습하는 것이다. 이러한 방식은 계산량을 줄여주지만, 심각한 학습 불안정성을 보이며 최적화 성능을 저해한다. 핵심 문제는 두 가지이다.
- Advantage 그룹 내에서 timestep을 혼합하면 실제 policy 신호를 가리는 혼란스러운 분산이 발생시킨다.
- Timestep에 따라 변하는 gradient scaling factor로 인해 서로 다른 timestep이 파라미터 업데이트에 일관성 없이 기여하여 최적화가 불안정해진다.
본 논문에서는 one-step 학습 프레임워크인 Flash-GRPO를 제시하였다. Flash-GRPO는 학습당 단 하나의 timestep만을 사용하여 전체 궤적 성능을 달성하였다.
첫 번째 문제를 해결하기 위해, 저자들은 iso-temporal grouping을 제안하였다. 이는 주어진 프롬프트에 대한 모든 rollout이 동일한 timestep을 공유하도록 하면서 초기 noise만 다르게 하는 방법이다. 이를 통해 advantage 계산이 분해되어 policy로 인한 분산과 timestep으로 인한 분산을 분리하고, 동일한 denoising 조건에서 상대적 성능 비교가 이루어지도록 한다. 시간적 다양성은 전체 batch에 걸쳐 계층적 샘플링을 통해 보존된다.
저자들은 policy gradient가 SDE discretization에서 발생하는 time-dependent scaling factor를 내재적으로 포함하며, timestep에 따라 큰 차이가 난다는 점을 발견했다. 이는 초기 timestep이 실제 중요도와 관계없이 파라미터 업데이트를 지배하는 심각한 최적화 불균형을 초래한다. 따라서 모든 timestep의 기여도를 균등하게 하고 discretization으로 인한 편향을 제거하기 위해, 명시적인 1로 정규화하는 temporal gradient rectification을 도입하였다.
Method
1. Iso-Temporal Grouping for Precise Credit Assignment
표준 동영상 생성 사전 학습은 샘플당 무작위로 선택된 하나의 timestep에서 vector field를 최적화함으로써 높은 효율성을 달성하였다. 저자들은 GRPO 정렬 단계에서 이러한 효율성을 재현하기 위해 one-step 학습 패러다임을 채택했다. 그러나 동영상 모델에 one-step GRPO를 그대로 적용하면 timestep에 의해 reward 분산이 왜곡되는 중요한 통계적 문제가 발생한다.
근본적인 문제는 reward \(R(\textbf{x}_0, \textbf{c})\)와 noise level $t$ 사이의 내재적인 상관관계에 있다. 프롬프트 그룹 내의 각 샘플에 독립적인 랜덤 timestep이 할당되는 단순한 one-step 전략에서는 group baseline이 다양한 $t$에서 발생하는 reward의 평균이 된다.
\[\begin{equation} \mu_\textrm{naive} = \frac{1}{G} \sum_{i=1}^G R (\textbf{x}_0^i (\textbf{x}_{t_i}), \textbf{c}) \end{equation}\]이러한 timestep의 이질성은 교란 변수로 작용한다. Reward 분산은 policy 생성 품질과 각 timestep의 내재적 난이도를 모두 반영한다. 결과적으로 advantage 추정치가 불안정하고 신뢰할 수 없게 되어 효과적인 policy 최적화를 저해한다.
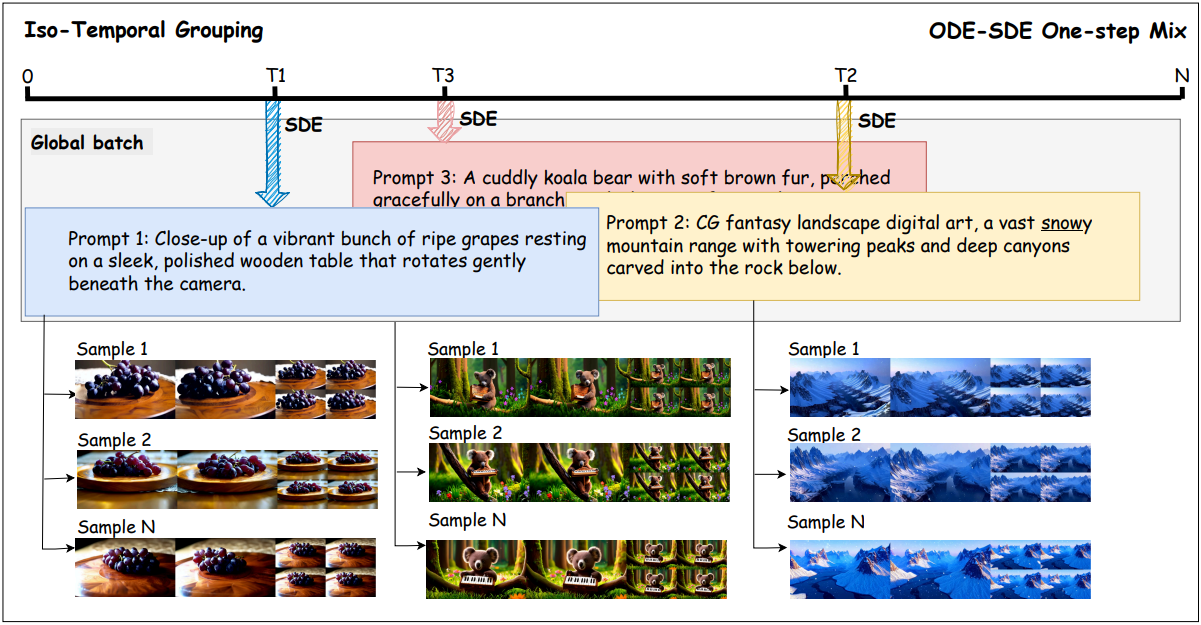
이러한 혼란 효과를 제거하기 위해, 저자들은 iso-temporal grouping을 제안하였다. $B$개의 프롬프트 \(\{\textbf{c}_k\}_{k=1}^B\)로 구성된 학습 batch에서, 각 프롬프트 \(\textbf{c}_k\)에는 서로 다른 timestep \(t_k \sim \mathcal{U}[0,T]\)가 할당된다. 각 프롬프트 그룹 내에서, 모든 $G$개의 rollout은 동일한 timestep $t_k$를 공유하지만, 서로 다른 Gaussian noise \(\epsilon_i\)로 초기화된다.
각 프롬프트 그룹은 서로 다른 timestep을 가질 수 있으며, 이를 통해 전체 batch에 걸쳐 시간적 다양성을 확보한다. Denoising 시에서 각 프롬프트 그룹은 지정된 timestep $t_k$에서 single-step ODE-to-SDE를 수행한다. 선택된 timestep은 탐색 및 gradient 계산을 위해 SDE 샘플링을 사용하고, 나머지 모든 timestep은 더 높은 품질의 생성과 더 정확한 reward 신호를 생성하기 위해 ODE를 사용한다.
각 프롬프트 그룹 내에서 동일한 timestep을 적용함으로써 policy 성능을 timestep 난이도와 분리한다. 즉, 동일한 그룹 내의 샘플은 동일한 denoising 조건에서 비교되므로, 성능 향상은 timestep에 따른 교란 요인이 아닌 생성 품질을 반영한다.
학습 과정에서 각 프롬프트 그룹에 대해 ODE-to-SDE 전환 timestep $t_k$에서만 policy gradient를 계산한다. 이를 통해 gradient가 batch 전체에 걸쳐 다양한 timestep을 포함하는 동시에 각 그룹 내에서 정확한 advantage 추정을 유지할 수 있다.
2. Temporal Gradient Rectification
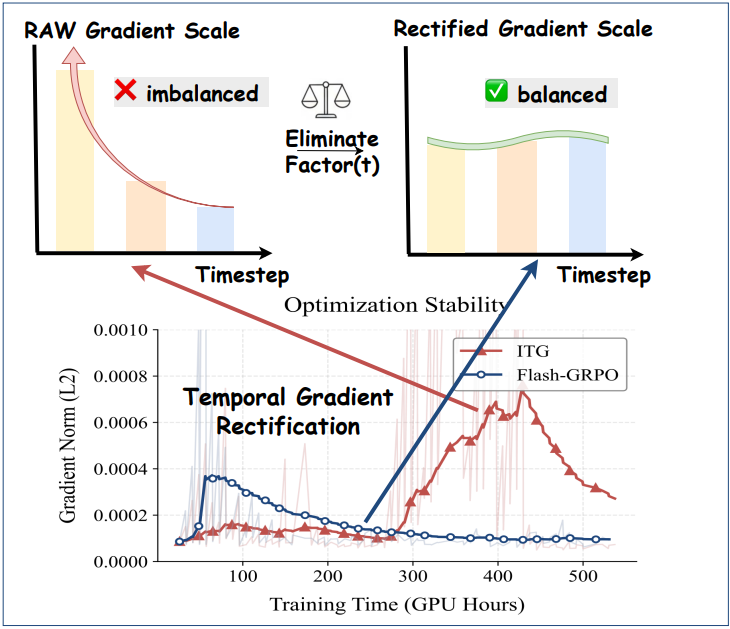
Gradient 크기는 timestep에 따라 변하는 scaling factor에 의해 implicit하게 조절되어, 다양한 timestep에 걸쳐 학습할 때 심각한 최적화 불안정성을 초래한다. 결정적으로, 이러한 불균형은 생성 품질이나 reward 신호 강도를 반영하는 것이 아니라 discretization 방식의 결과물이다.
이 현상을 이해하기 위해 reverse process에 대한 policy gradient를 계산해보자. Timestep $t$에서의 표준 RL objective는 다음과 같다.
Reverse-time SDE의 Euler-Maruyama discretization에 의해 유도된 Gaussian transition kernel 하에서, 이전 state \(\textbf{x}_{t-1}\)은 다음과 같이 모델링된다.
\[\begin{aligned} \textbf{x}_{t-1} &= \boldsymbol{\mu}_\theta (\textbf{x}_t, t) + \sigma_t \sqrt{\Delta t} \cdot \boldsymbol{\epsilon} \\ \boldsymbol{\mu}_\theta (\textbf{x}_t, t) &= \textbf{x}_t + \left[ \textbf{v}_\theta (\textbf{x}_t, t) + \frac{\sigma_t^2}{2t} (\textbf{x}_t + (1-t) \textbf{v}_\theta (\textbf{x}_t, t)) \right] \Delta t \end{aligned}\]이를 score function에 대입하고 gradient 항을 전개하면 다음과 같다.
\[\begin{aligned} \nabla_\theta \log p_\theta (\textbf{x}_{t-1} \mid \textbf{x}_t) &= \nabla_\theta \left( - \frac{\| \textbf{x}_{t-1} - \boldsymbol{\mu}_\theta (\textbf{x}_t, t) \|^2}{2 \sigma_t^2 \Delta t} \right) \\ &= \frac{\textbf{x}_{t-1} - \boldsymbol{\mu}_\theta (\textbf{x}_t, t)}{\sigma_t^2 \Delta t} \nabla_\theta \boldsymbol{\mu}_\theta (\textbf{x}_t, t) \\ &= \frac{\sigma_t \sqrt{\Delta t} \boldsymbol{\epsilon}}{\sigma_t^2 \Delta t} \textbf{x}_{t-1} - \boldsymbol{\mu}_\theta (\textbf{x}_t, t) \\ &= \frac{\boldsymbol{\epsilon}}{\sigma_t \sqrt{\Delta t}} \cdot \Delta t \left( 1 + \frac{\sigma_t^2 (1-t)}{2t} \right) \nabla_\theta \textbf{v}_\theta (\textbf{x}_t, t) \\ &= \underbrace{\left( \frac{\sqrt{\Delta t}}{\sigma_t} + \frac{\sigma_t \sqrt{\Delta t} (1-t)}{2t} \right)}_{\lambda (t)} \boldsymbol{\epsilon} \cdot \nabla_\theta \textbf{v}_\theta (\textbf{x}_t, t) \end{aligned}\]Policy gradient는 본질적으로 timestep에 따라 달라지는 계수 \(\lambda (t) = \frac{\sqrt{\Delta t}}{\sigma_t} + \frac{\sigma_t \sqrt{\Delta t} (1-t)}{2t}\)에 의해 scaling된다. Batch 내의 서로 다른 프롬프트가 서로 다른 timestep에서 학습되는 Flash-GRPO 프레임워크에서 \(\lambda (t)\)는 implicit하고 이질적인 weighting factor로 작용한다. \(\sigma_t\)와 $t$가 diffusion 궤적을 따라 변함에 따라 \(\lambda (t)\)는 굉장히 크게 변동할 수 있으며, 따라서 서로 다른 timestep에서 샘플링된 프롬프트는 매우 불일치한 크기로 파라미터 업데이트에 기여하게 된다.
이러한 문제를 해결하기 위해, 저자들은 time-dependent scaling factor를 명시적으로 정규화하는 Temporal Gradient Rectification을 제안하였다. 구체적으로, gradient를 \(1 / \lambda (t)\)로 rescaling하여 모든 timestep에서 \(\lambda (t) \rightarrow 1\)이 되도록 한다. Clipping되지 않은 rectified policy loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{TGR} (\theta) = \frac{1}{G} \sum_{i=1}^G \frac{\hat{A}_t^i}{\lambda (t)} \cdot r_t^i (\theta) \end{equation}\]이 보정 방법은 timestep에 관계없이 모든 프롬프트가 파라미터 업데이트에 동등하게 기여하도록 보장한다. 그 결과, 학습 안정성이 크게 향상되고 reward가 일관되게 증가한다.
Experiments
1. Performance on VBench Quality Metrics
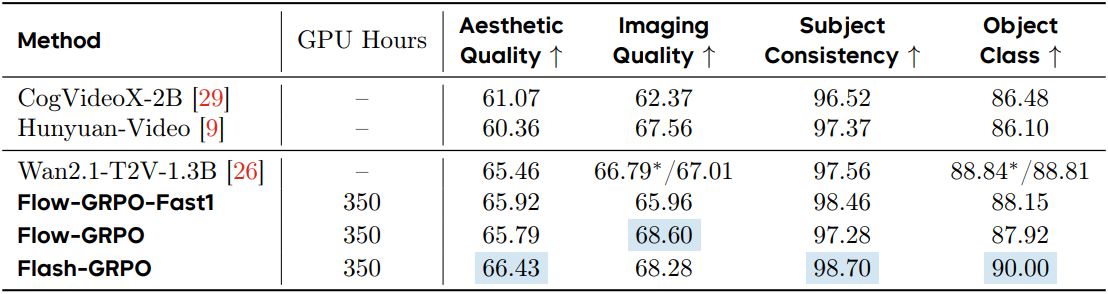
다음은 VBench로 동영상 품질을 자세히 비교한 결과이다.
2. Visual Comparison
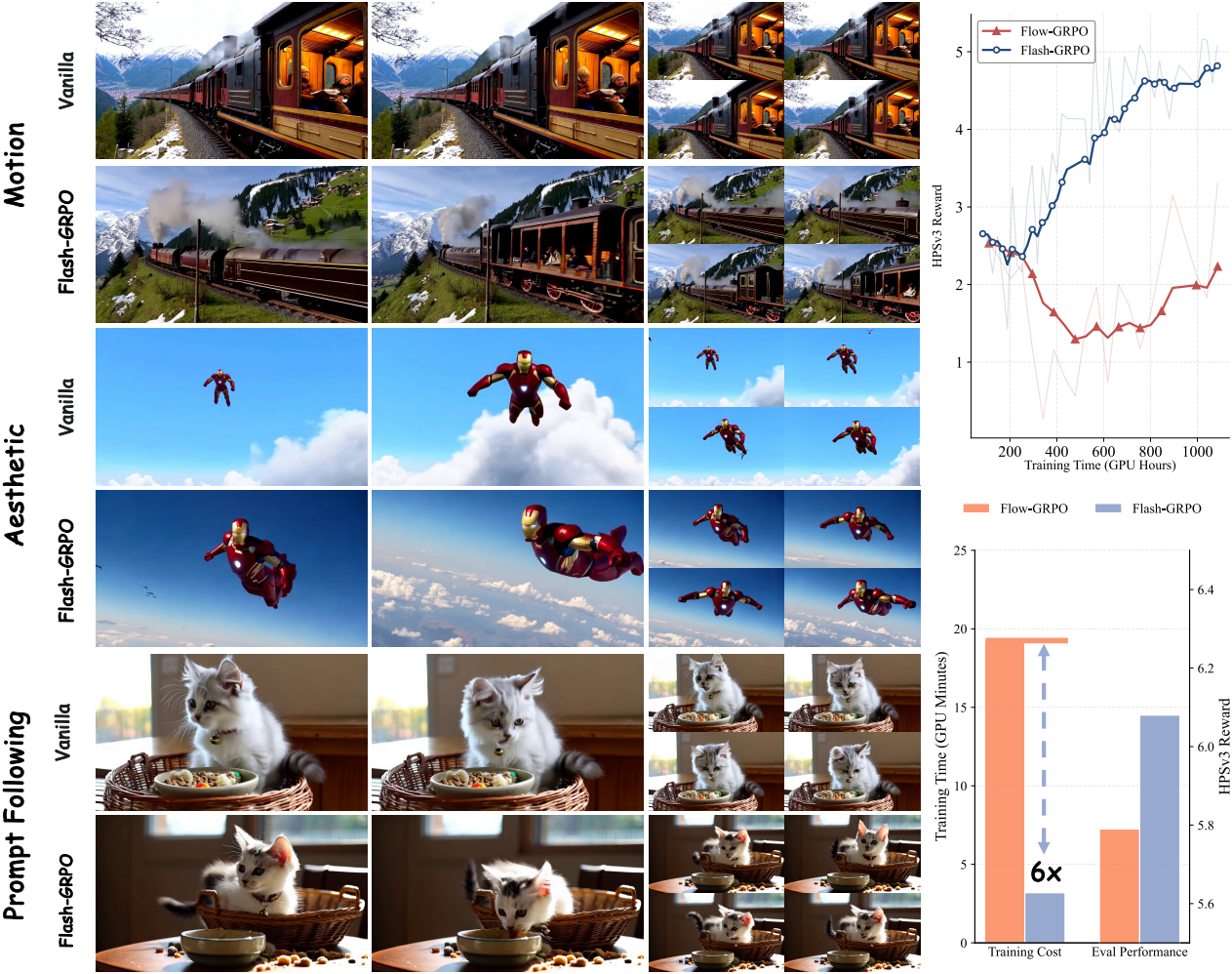
다음은 Wan2.1과 정성적으로 비교한 결과이다.

3. Ablation Study
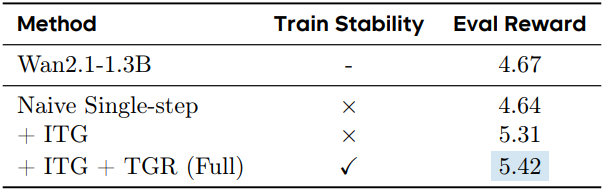
다음은 ablation study 결과이다.
4. Analysis
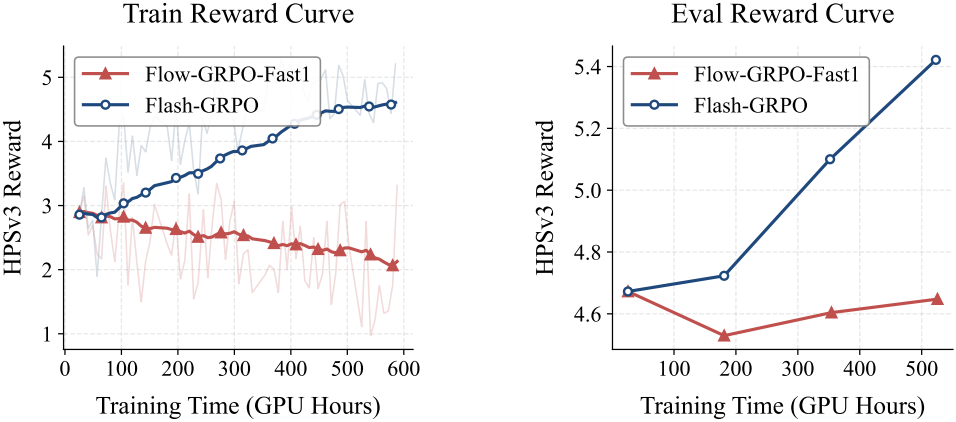
다음은 Flow-GRPO-Fast1과 reward를 비교한 결과이다.
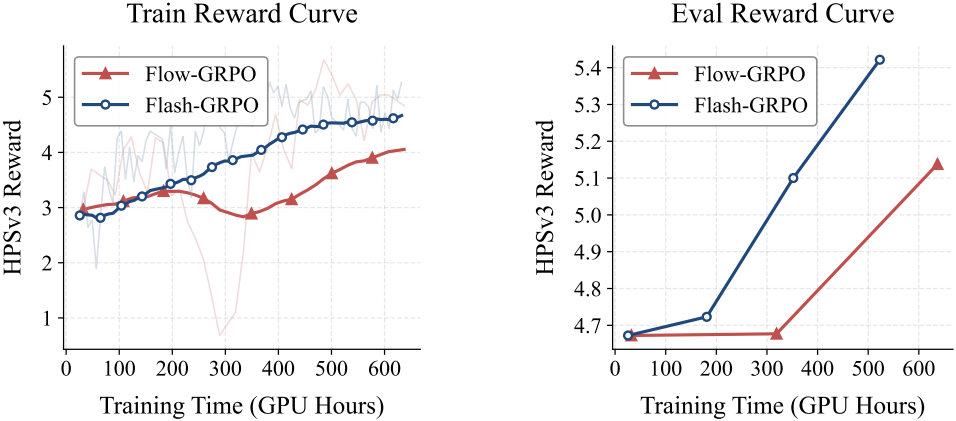
다음은 Flow-GRPO와 reward를 비교한 결과이다.
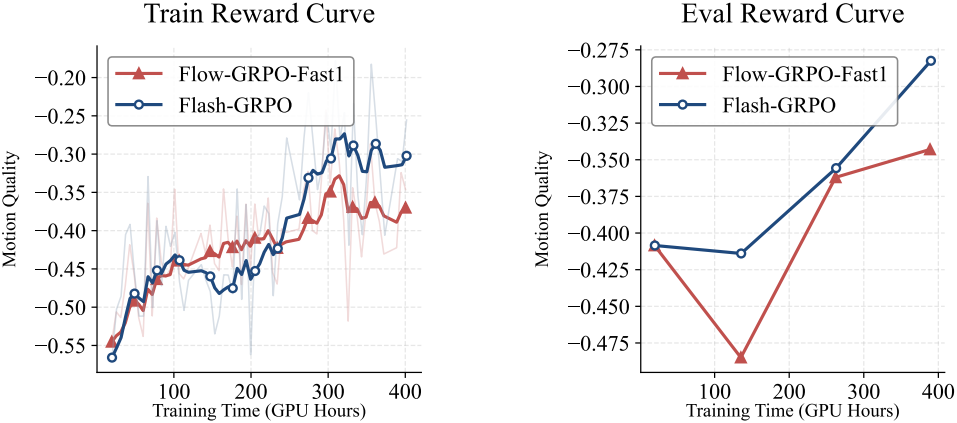
다음은 Flow-GRPO-Fast1과 모션 품질을 비교한 결과이다.