[논문리뷰] Byte Latent Transformer: Patches Scale Better Than Tokens
ACL 2025. [Paper] [Github]
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, Srinivasan Iyer
Meta AI | University of Washington | University of Chicago
13 Dec 2024
Introduction
본 논문에서는 byte 데이터로부터 학습하는 tokenizer가 없는 아키텍처인 Byte Latent Transformer (BLT)를 소개한다. BLT는 최초로 대규모 환경에서 tokenization 기반 모델과 동등한 성능을 달성하면서 효율성과 robustness를 크게 향상시켰다. 기존 LLM은 tokenization 단계를 제외하고는 거의 end-to-end로 학습된다. Tokenization은 byte를 고정된 토큰 집합으로 그룹화하는 휴리스틱 전처리 단계이다. 이러한 토큰은 문자열 압축 방식에 편향을 주어 도메인/모달리티 민감도, 입력 노이즈 민감도, 철자법 지식 부족, 다국어 불균형과 같은 단점을 초래한다.
컴퓨팅 자원을 효율적으로 할당하기 위해, 본 논문에서는 byte를 패치로 그룹화하는 동적이고 학습 가능한 방법과, byte 및 패치 정보를 혼합하는 새로운 모델 아키텍처를 제안하였다. Tokenization과 달리, BLT는 패치에 대한 고정된 vocabulary를 사용하지 않는다. 임의의 byte 그룹은 학습된 가벼운 인코더 및 디코더 모듈을 통해 latent 패치 표현으로 매핑된다.
Tokenization 기반 LLM은 모든 토큰에 동일한 양의 연산 능력을 할당한다. 이는 토큰에 압축 휴리스틱이 적용되기 때문에 효율성을 위해 성능을 희생하는 결과를 초래한다. 본 아키텍처의 핵심은 모델이 필요한 곳에 동적으로 연산 능력을 할당해야 한다는 점이다. BLT 아키텍처는 두 개의 작은 byte-level 로컬 모델과 하나의 큰 글로벌 latent transformer로 구성된 총 3개의 transformer block이 있다. byte를 패치로 그룹화하고 연산 능력을 동적으로 할당하는 방법을 결정하기 위해 BLT는 다음 byte 예측의 엔트로피를 기반으로 데이터를 분할하여 상대적으로 균일한 정보 밀도를 가진 byte 그룹을 생성한다.
본 논문에서는 최대 8B 파라미터와 4T 학습 byte를 사용하는 byte-level 모델에 대한 최초의 FLOP 제어 scaling 연구를 수행하였다. 이를 통해 고정 vocabulary에 대한 tokenization 없이 byte 단위로 모델을 end-to-end 방식으로 scaling할 수 있음을 보여주었다. 전반적으로 BLT는 inference 시 최대 50% 더 적은 FLOP을 사용하면서 Llama 3의 성능을 달성하였다. 또한 byte를 직접 처리함으로써 데이터의 long-tail 모델링 성능이 크게 향상되었다. BLT 모델은 tokenizer 기반 모델보다 노이즈가 있는 입력에 더 robust하며, 다양한 task에서 향상된 문자 수준 이해 능력을 보여주었다.
Patching
데이터 처리의 계산 비용은 주로 메인 transformer가 실행하는 step 수에 의해 결정된다. BLT에서는 주어진 patching function을 사용하여 데이터를 인코딩하는 데 필요한 패치의 개수가 이에 해당한다. 따라서 패치의 평균 크기는 학습 및 inference 과정에서 데이터 처리 비용을 결정하는 주요 요인이다.

Strided Patching Every K Bytes
byte를 그룹화하는 가장 간단한 방법은 MegaByte에서처럼 고정 크기 $k$의 패치로 나누는 것이다. 이는 학습 및 inference 구현이 용이하고, 평균 패치 크기를 쉽게 변경할 수 있어 연산 비용을 쉽게 제어할 수 있도록 한다. 그러나 연산 능력이 가장 필요한 곳에 동적으로 할당되지 않으며, 코드에서 공백만 예측하는 경우 transformer step을 낭비하고, 수학 연산과 같이 정보가 밀집된 경우 충분한 연산 능력을 할당하지 못할 수 있다. 또한, 동일한 byte 시퀀스가 일관성 없이 문맥에 맞지 않게 patching되는 문제가 발생한다. 예를 들어, 동일한 단어가 서로 다른 방식으로 분할될 수 있다.
Space Patching
Spacebyte은 모든 공백 byte 뒤에 새로운 패치를 생성하였다. 이는 시퀀스 전체에서 단어가 동일한 방식으로 patching되고, 공백 뒤에 오는 경우가 많은 어려운 예측에 연산이 할당되도록 한다. 그러나 모든 언어와 도메인을 원활하게 처리할 수 없으며, 가장 중요한 것은 패치 크기를 변경할 수 없다는 점이다.
Entropy Patching: Using Next-Byte Entropies from a Small Byte LM
규칙 기반 휴리스틱에 의존하는 대신, 본 논문에서는 엔트로피 추정치를 사용하여 패치 경계를 도출하는 entropy patching 기법을 도입하였다. 구체적으로, BLT의 학습 데이터에 대해 작은 byte-level autoregressive 언어 모델을 학습시키고, byte vocabulary $\mathcal{V}$에 대한 언어 모델 분포 $p_e$ 하에서 byte 엔트로피 $H(x_i)$를 계산한다.
\[\begin{equation} H(x_i) = \sum_{v \in \mathcal{V}} p_e (x_i = v \vert \textbf{x}_{<i}) \log p_e (x_i = v \vert \textbf{x}_{<i}) \end{equation}\]본 논문에서는 엔트로피 $H(x_i)$가 주어졌을 때 패치 경계를 식별하는 두 가지 방법을 실험했다.
- 글로벌 엔트로피 threshold보다 높은 지점을 식별
- 이전 엔트로피에 비해 상대적으로 높은 지점을 식별
패치 경계는 데이터 로딩 중에 실행되는 간단한 전처리 단계에서 식별된다.
BLT Architecture
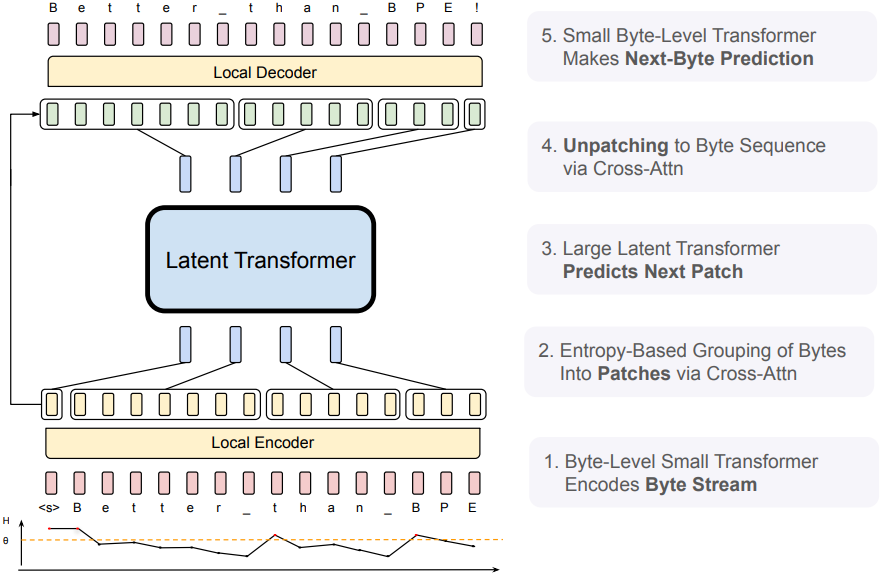
1. Latent Global Transformer Model
Latent Global Transformer $\mathcal{G}$는 \(l_\mathcal{G}\)개의 layer를 가진 autoregressive transformer로, latent 입력 패치 표현 시퀀스 $p_j$를 출력 패치 표현 시퀀스 $o_j$로 매핑한다. 이 글로벌 모델은 block-causal attention mask를 사용하여 현재 문서 내의 현재 패치까지만 attention을 적용하도록 제한한다.
2. Local Encoder
로컬 인코더 모델 $\mathcal{E}$는 \(l_\mathcal{E} \ll l_\mathcal{G}\)개의 layer로 구성된 가벼운 transformer 기반 모델로, 주요 역할은 입력 byte 시퀀스 $b_i$를 표현력이 풍부한 패치 표현 $p_j$로 효율적으로 매핑하는 것이다. Transformer 아키텍처와의 주요 차이점은 각 transformer layer 뒤에 cross-attention layer가 추가된 것으로, 이 layer는 byte 표현을 패치 표현으로 통합하는 기능을 한다.
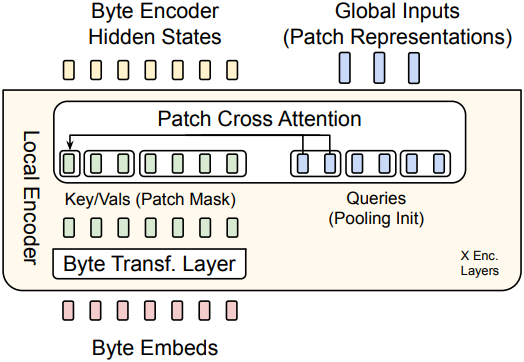
먼저, 입력 byte 시퀀스 $b_i$는 \(\mathbb{R}^{256 \times h_\mathcal{E}}\) 행렬을 사용하여 $x_i$로 임베딩된다. $x_i$는 선택적으로 해시 임베딩 형태의 추가 정보로 보강된다. 일련의 transformer layer와 cross-attention layer가 교대로 배열되어 이러한 표현을 $\mathcal{G}$에서 처리되는 패치 표현 $p_i$로 변환한다. Transformer layer는 local block causal attention mask를 사용한다. 각 byte는 일반적으로 동적 패치 경계를 넘을 수 있지만 문서 경계를 넘을 수 없는 고정된 \(w_\mathcal{E}\)개의 선행 byte를 처리한다.
Encoder Hash n-gram Embeddings
각 step $i$에서 robust하고 표현력이 풍부한 표현을 생성하는 핵심 요소는 이전 byte에 대한 정보를 통합하는 것이다. BLT에서는 byte $b_i$를 개별적으로 모델링하는 동시에 byte $n$-gram의 일부로도 모델링함으로써 이를 달성하였다. 각 step $i$에 대해 먼저 byte $n$-gram을 구성한다.
\[\begin{equation} g_{i,n} = \{b_{i-n+1}, \ldots, b_i\}, \quad \textrm{where} \; n = 3, \ldots, 8 \end{equation}\]다음으로, 모든 byte $n$-gram을 해시 함수를 통해 고정 크기의 임베딩 테이블 \(E_n^\textrm{hash}\)의 인덱스에 매핑하는 해시 $n$-gram 임베딩을 도입한다. 이렇게 얻은 임베딩을 byte의 임베딩에 더한 후 정규화하여 로컬 인코더 모델의 입력으로 사용한다.
\[\begin{equation} e_i = x_i + \sum_{n=3, \ldots, 8} E_n^\textrm{hash} (\textrm{Hash}(g_{i,n})) \end{equation}\]$e_i$를 $n$-gram 크기의 개수에 1을 더한 값으로 정규화한다.
Encoder Multi-Headed Cross-Attention
본 논문에서는 Perceiver 아키텍처의 입력 cross-attention 모듈을 따르지만, 주요 차이점은 latent 표현이 고정된 latent 표현 집합이 아닌 가변적인 패치 표현에 대응한다는 점이다. 또한 각 패치를 구성하는 byte에만 attention한다. 이 모듈은 각 패치 $p_j$에 대응하는 query 벡터로 구성되며, 이 벡터는 패치 $p_j$에 대응하는 byte 표현들을 pooling하여 초기화된다. 그 후 linear projection \(\mathcal{E}_C \in \mathbb{R}^{h_\mathcal{E} \times (h_\mathcal{E} \times U_\mathcal{E})}\)가 수행된다. (\(U_\mathcal{E}\)는 인코더 cross-attention head 개수)
패치 $p_j$에 대응하는 byte 시퀀스를 \(f_\textrm{bytes} (p_j)\)라고 하면, 다음과 같이 계산된다.
\[\begin{aligned} P_{0,j} &= \mathcal{E}_C (f_\textrm{bytes} (p_j)) \\ Q_j &= W_q (P_{l-1, j}), \; K_i = W_k (h_{l-1, i}), \; V_i = W_v (h_{l-1, i}) \\ P_l &= P_{l-1} + W_o \left( \textrm{softmax} \left( \frac{QK^\top}{\sqrt{d_k}} \right) V \right) \\ h_l &= \textrm{Encoder-Transformer-layer}_l (h_{l-1}) \end{aligned}\]$P$는 글로벌 모델에서 처리될 패치 표현이다. 각 $Q_j$는 패치 $j$의 byte에 해당하는 key와 value에만 attention하는 전용 마스킹 전략을 사용한다. $Q$, $K$, $V$에 대해 multi-head attention을 사용하고 패치 표현의 차원 \(h_\mathcal{G}\)가 일반적으로 \(h_\mathcal{E}\)보다 크기 때문에, cross-attention을 수행할 때 $P_l$을 \(h_\mathcal{E}\) 차원의 여러 head로 유지하고, 나중에 이러한 표현들을 \(h_\mathcal{G}\) 차원으로 결합한다. 또한, query, key, value에 pre-LayerNorm을 적용하고, 이 cross-attention 모듈에서는 위치 임베딩을 사용하지 않으며, cross-attention block 주변에 residual connection을 사용한다.
3. Local Decoder
로컬 인코더와 유사하게, 로컬 디코더 $\mathcal{D}$는 \(l_\mathcal{D} \ll l_\mathcal{G}\)개의 layer로 구성된 가벼운 transformer 기반 모델로, 글로벌 패치 표현 $o_j$의 시퀀스를 byte $y_i$로 디코딩한다. 로컬 디코더는 이전에 디코딩된 byte의 함수로 byte 시퀀스를 예측하므로, 입력으로 로컬 인코더가 byte 시퀀스에 대해 생성한 hidden 표현을 받는다. 디코더는 cross-attention layer와 transformer layer를 교대로 적용되었다. Cross-attention layer는 transformer layer 이전에 적용되어 패치 표현으로부터 byte 표현을 먼저 생성하고, transformer layer는 생성된 byte 시퀀스에 대해 연산을 수행한다.
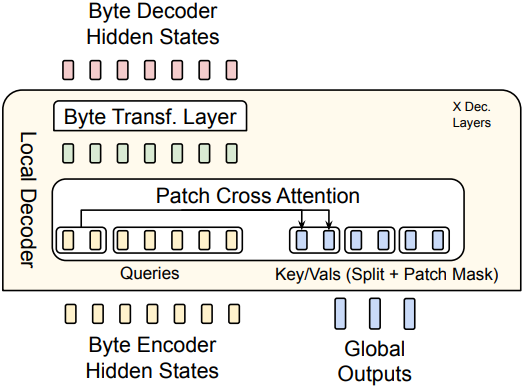
Decoder Multi-headed Cross-Attention
디코더 cross-attention에서는 query와 key/value의 역할이 서로 바뀐다. 즉, byte 표현이 query가 되고 패치 표현이 key/value가 된다. Cross-attention의 초기 byte 표현은 마지막 인코더 레이어 \(h_{l_\mathcal{E}}\)의 byte 임베딩으로 초기화된다. 이후 layer $l$에 대한 byte 표현 \(d_{l, i}\)는 다음과 같이 계산된다.
\[\begin{aligned} D_0 &= h_{l_\mathcal{E}} \\ Q_i &= W_q (d_{l-1, i}), \; K_i = W_k (\mathcal{D}_C (o_j)), \; V_i = W_v (\mathcal{D}_C (o_j)) \\ B_l &= D_{l-1} + W_o \left( \textrm{softmax} \left( \frac{QK^\top}{\sqrt{d_k}} \right) V \right) \\ D_l &= \textrm{Decoder-Transformer-layer}_l (B_l) \end{aligned}\](\(\mathcal{D}_C\)는 split 연산)
로컬 인코더 cross-attention과 마찬가지로, attention에 여러 개의 head를 사용하고, pre-LayerNorm을 적용하며, 위치 임베딩을 사용하지 않고, cross-attention 모듈 주변에 residual connection을 사용한다.
Experiments
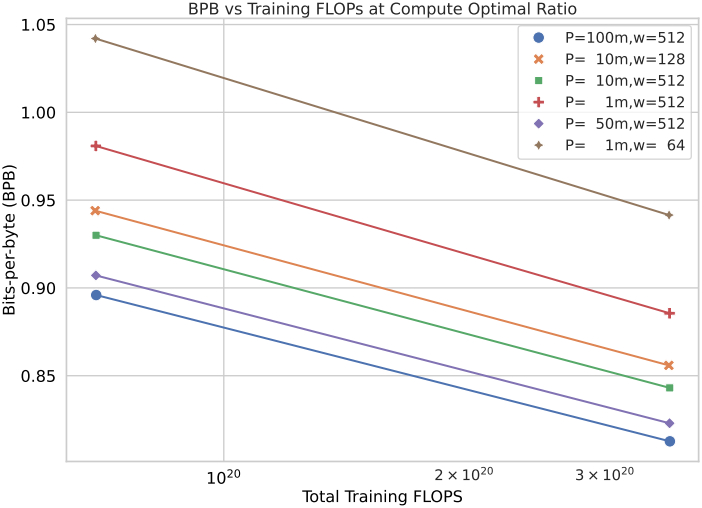
1. Scaling Trends
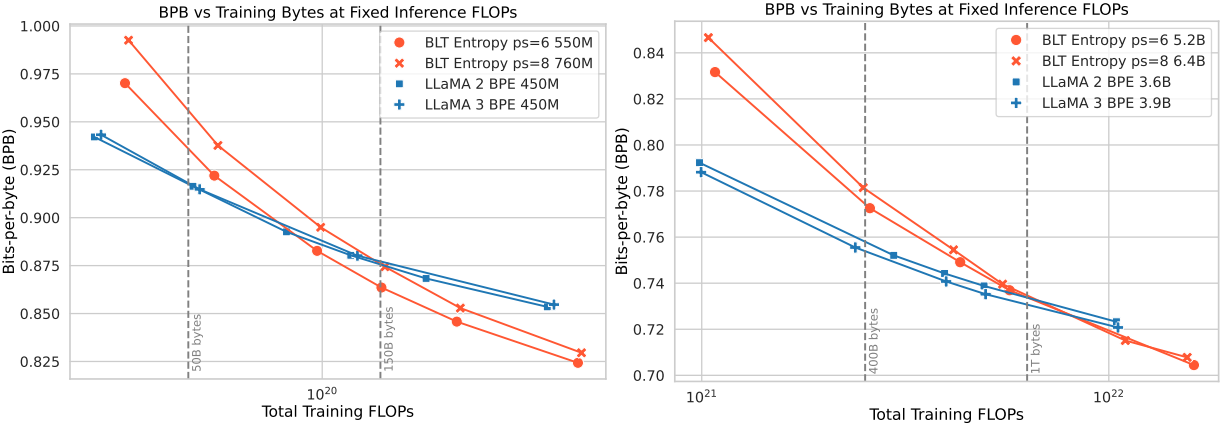
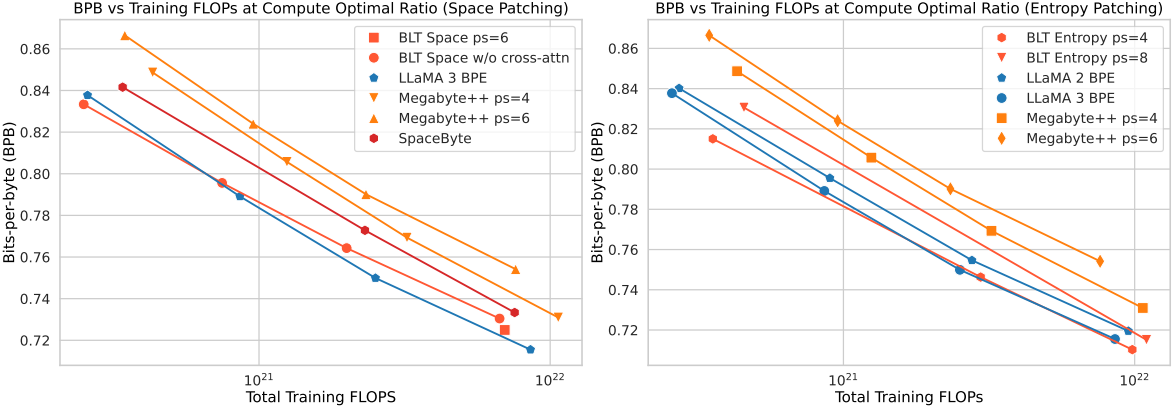
다음은 다른 모델들과 BLT의 scaling trend를 비교한 그래프이다.
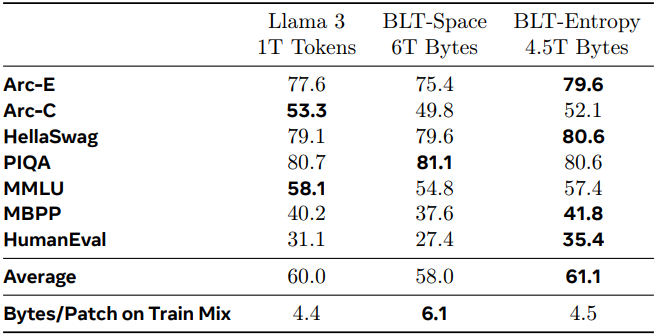
다음은 동일한 FLOP 예산에 대해 학습된 모델들을 비교한 결과이다.
2. Byte Modeling Improves Robustness
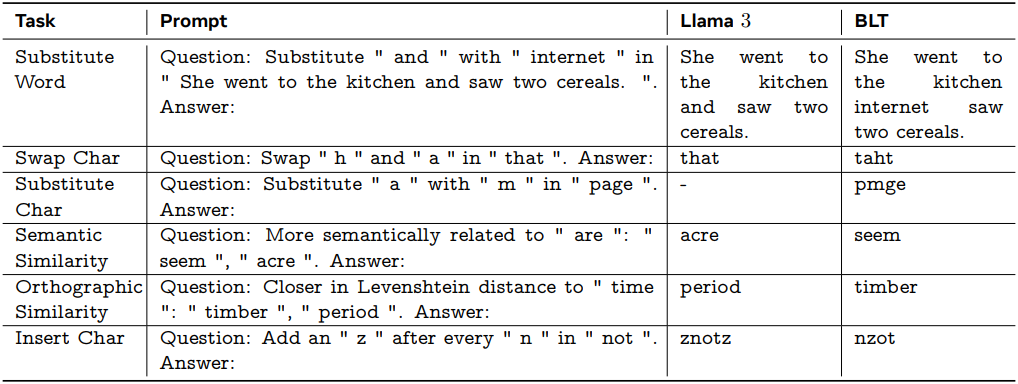
다음은 문자 수준의 task들에 대한 결과이다.
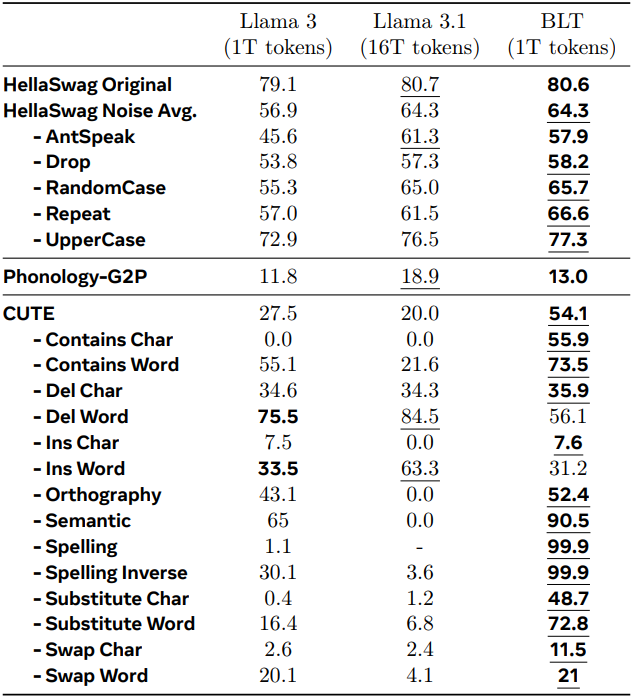
다음은 CUTE 벤치마크에 대한 출력 응답을 비교한 것이다.
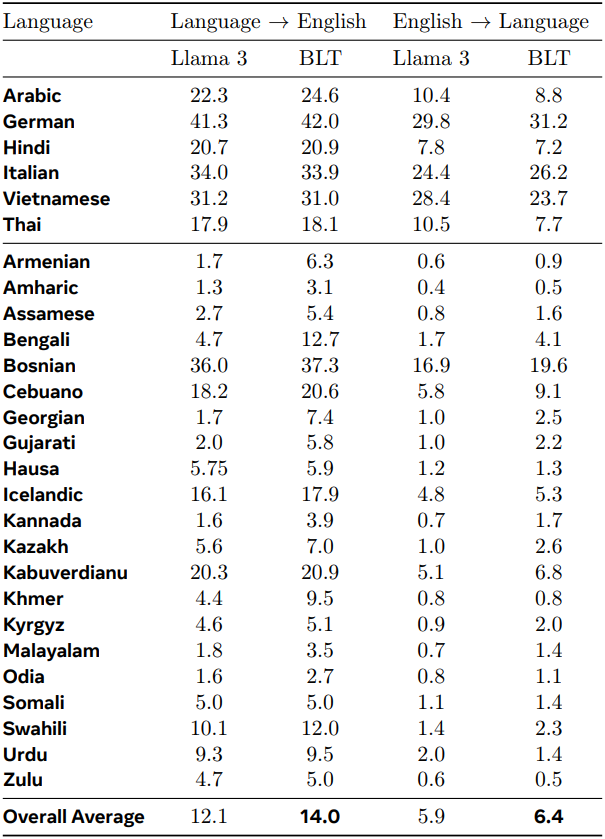
다음은 FLORES-101 번역 벤치마크에 대한 결과이다.
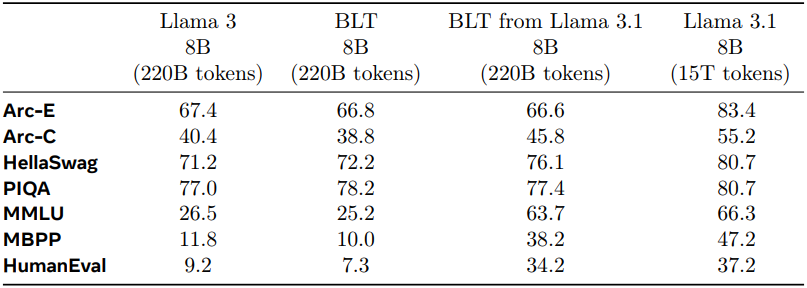
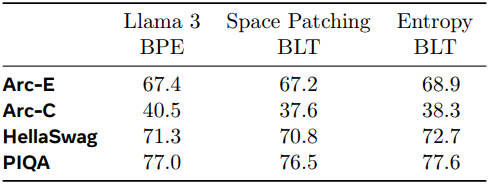
다음은 Llama 3의 사전 학습된 파라미터로 BLT의 글로벌 모델을 초기화하였을 때의 결과이다.
3. Ablations
다음은 엔트로피 모델 크기와 context window 길이에 대한 ablation 결과이다.
다음은 patching 방법에 대한 ablation 결과이다.
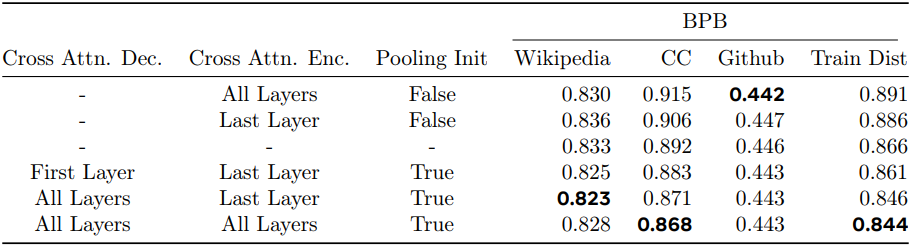
다음은 cross-attention에 대한 ablation 결과이다.
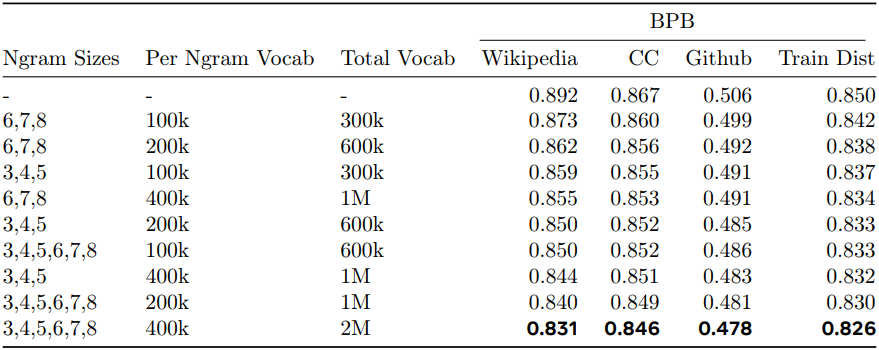
다음은 $n$-gram 해시 임베딩에 대한 ablation 결과이다.