[논문리뷰] Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
CVPRW 2024. [Paper]
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
University of Modena and Reggio Emilia | University of Pisa | IIT-CNR
23 Apr 2024
Introduction
최근 LLM을 비전 및 언어 컨텍스트로 확장한 Large Multimodal Model (LMM)이 등장했다. LMM은 vision-to-language adapter를 통해 비전 feature를 LLM backbone에 융합함으로써 정교한 시각적 설명이 필요한 task에 대한 광범위한 일반화가 가능해졌다.
LMM은 비전 feature를 텍스트 feature와 정렬하는 작은 어댑터를 사용하여 간단하게 탁월한 성능을 보인다. 그러나 이러한 모델이 대규모 데이터에서 학습된 LLM을 기반으로 구축되었음에도 불구하고 매우 구체적인 사용자 질문에 직면하거나 응답하는 데 어느 정도의 추론이 필요한 경우 상당한 한계가 있다. 게다가 특정 지식은 학습 데이터에 부족하기 때문에 LMM의 파라미터 내에서 인코딩하기 어렵다.
본 논문에서는 검색 모듈로 증강된 최초의 LMM을 제안하여 모델이 응답에서 다양한 정보를 활용하고 각각의 상대적 중요성을 분별하는 방법을 학습하도록 초점을 맞추었다. 특히, 모델은 외부 문서에서 적절한 정보를 검색하고 계층적 검색 방식을 사용하여 관련 구절을 식별한다. 그런 다음 이 추가 지식은 구조를 변경하지 않고 LMM에 공급되며 답변 능력이 향상된다.
본 논문은 외부 소스의 검색 기능을 활용한 최초의 LMM이며, 실험 결과는 외부 소스에서 검색하는 것의 이점과 모델 설계의 적절성을 보여준다.
Method
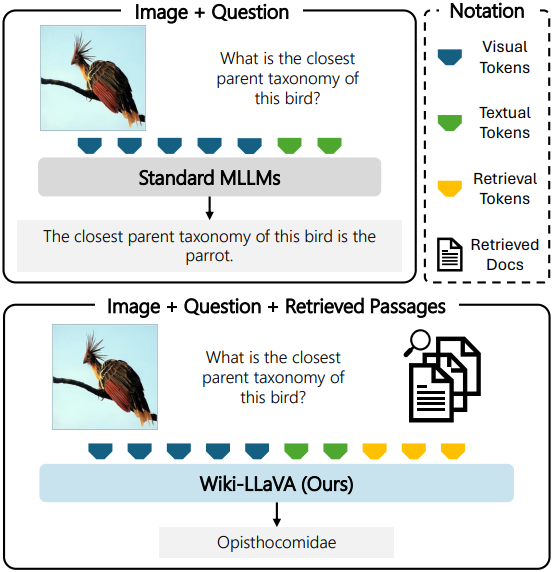
본 논문의 목표는 LMM이 이미지 콘텐츠와 사전 학습된 지식만으로는 해결할 수 없는 복잡하고 구체적인 질문에 답할 수 있는 능력을 갖추는 것이다. 이를 위해 외부 지식을 LLaVA 모델에 통합하는 Wiki-LLaVA를 제안하였다. 저자들은 모델의 디자인을 크게 변경하지 않는 대신, 검색 정보를 추가 입력 컨텍스트로 통합하여 모델의 능력을 보강하였다.
전반적으로 Wiki-LLaVA는 세 가지로 구성된다.
- 비주얼 인코더: LMM에 시각적 컨텍스트를 제공하고 외부 knowledge base에서 검색하기 위한 쿼리로 사용
- 외부 knowledge base: Wikipedia
- 계층적 검색 모듈: LMM에 대한 추가 컨텍스트로 사용할 외부 knowledge base에서 관련 문서와 구절을 검색
1. Knowledge-based Augmentation
멀티모달 통합 & Autoregressive한 생성
LMM은 일반적으로 이미지와 텍스트를 모두 포함하는 멀티모달 쿼리를 입력으로 받고 autoregressive 방식으로 텍스트 출력을 생성한다. 아키텍처는 확률 분포
\[\begin{equation} p(w_t \vert I, w_0, w_1, \ldots, w_{t−1}, \theta) \end{equation}\]를 모델링하도록 학습된다. ($\theta$는 모델의 파라미터, $I$는 입력 이미지, $w_0, \ldots, w_{t−1}$은 텍스트 프롬프트)
일반적으로 텍스트 프롬프트에는 미리 정의된 시스템 프롬프트와 사용자가 제공한 입력 이미지와 관련된 질문이 포함된다. LMM은 사용자 프롬프트, 입력 이미지, 내부 파라미터 $\theta$에 저장된 지식에만 의존하여 요청을 수용할 수 있으므로 외부 지식에 의존하는 질문에 답하기 어렵다.
본 논문은 LLaVA를 레퍼런스 LMM으로 사용한다. LLaVA는 사전 학습된 Vicuna와 사전 학습된 CLIP 기반 비주얼 인코더의 능력을 활용한다. 입력 이미지 $I$는 CLIP 비주얼 인코더 $E_v$를 사용하여 CLIP feature $Z_v = E_v (I)$를 추출한 다음 학습 가능한 MLP를 통해 proejection하여 임베딩 토큰의 시퀀스 $v_o, \ldots, v_N$을 생성한다. 이것들은 시스템 프롬프트에 추가되고 비주얼 및 텍스트 토큰의 전체 시퀀스가 LLM에 대한 입력으로 제공된다.
외부 지식을 활용한 보강
LMM을 외부 지식으로 보강하기 위해, 문서로 구성된 외부 메모리에서 관련된 텍스트 데이터를 입력 컨텍스트에 주입하여 입력 컨텍스트를 풍부하게 만든다. LMM의 분포는 검색된 추가 지식 토큰으로 컨디셔닝된다.
\[\begin{equation} p(w_t \vert \overbrace{v_o, v_1, ..., v_N}^{\textrm{Visual tokens}}, \underbrace{w_0, w_1, ..., w_{t-1}}_\textrm{System + user prompt}, \overbrace{e_0, e_1, ..., e_\tau}^\textrm{External memory tokens}) \end{equation}\]여기서 $e_0, \ldots, e_\tau$는 외부 메모리에서 검색된 추가 토큰이다. 일반 LMM과 달리 모델이 메모리에서 검색된 토큰을 활용하여 보다 구체적인 답변을 생성할 수 있도록 한다.
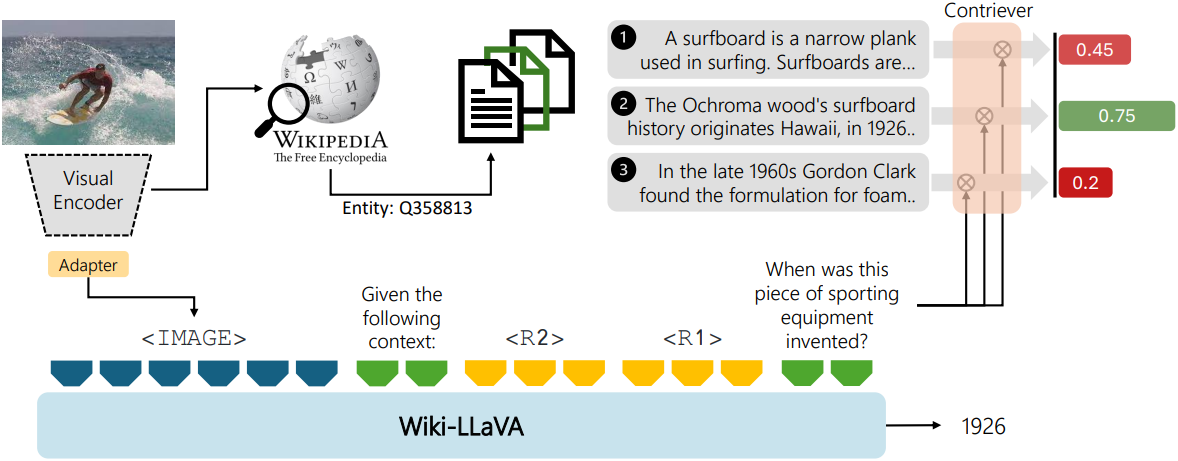
외부 메모리에서 계층적 검색
외부 메모리는 문서에서 가져온 (문서, 이미지, 텍스트-제목) triplet의 컬렉션 \(\mathcal{D} = \{(d_i, t_i)\}\)으로 구성된다. 이 메모리 내에서 계층적 2단계 검색을 수행하여 적절한 정보를 검색한다. 먼저 가장 관련성 있는 문서를 찾은 다음 특정 문서 내부의 관련 구절을 식별하여 LMM에서 추가 입력 컨텍스트로 활용한다.
첫 번째 단계에서는 입력 쿼리 이미지 $I$가 주어지면 문서 제목을 검색 가능한 키로 사용하여 외부 메모리에 대한 approximate k-NN search를 수행한다. 쿼리 이미지와 텍스트 제목 간의 유사도는 각각의 임베딩 간의 내적으로 계산되며, 이는 비주얼 CLIP 인코더 $E_v$와 텍스트 CLIP 인코더 $E_t$를 통해 다음과 같이 계산된다.
\[\begin{equation} \textrm{sim} (I_i, t_i) = E_v (I) \cdot E_t (t_i)^\top \end{equation}\]그런 다음, 검색 모듈은 검색된 항목 중 가장 관련성이 높은 항목과 연관된 상위 $k$개의 문서를 반환한다.
문서 구절 검색
두 번째 단계에서는 검색된 각 문서를 분석하여 사용자의 질문에 해당하는 가장 관련성 있는 구절을 식별한다. 각 문서는 청크 시퀀스 \(d_i = [c_{i_0}, \ldots, c_{i_\tau}]\)로 정의되며, 입력 질문이 주어지면 질문과 가장 유사도가 높은 청크를 검색한다. Contriever 아키텍처를 사용하여 선택한 문서의 각 청크와 질문 쿼리를 임베딩하고 임베딩 간의 내적으로 유사도를 계산한다. 검색된 각 문서 내에서 가장 적합한 $n$개의 구절을 검색하여 전체적으로 $k \cdot n$개의 구절을 얻는다.
컨텍스트 강화
가장 관련성 있는 청크를 찾으면, 그 청크의 내용을 LMM에 대한 추가 입력으로 사용한다. 최종 프롬프트에는 이미지 토큰, 검색된 청크, 시스템 프롬프트, 사용자 질문이 포함된다. 구절 3개를 검색하는 경우, 최종 프롬프트는 다음과 같이 정의된다.
<IMAGE>\nGiven the following context:\n
<R1>\n<R2>\n<R3>\n <QUESTION>
Give a short answer. ASSISTANT:
2. Training
사전 학습된 LMM의 원래 가중치를 사용하여 zero-shot 방식으로 작동할 수 있지만, 검색된 구절을 활용하는 능력을 증강하기 위해 모델을 fine-tuning할 수도 있다. 특히 이 경우 모델은 외부 지식이 필요한 질문-정답 쌍에 대해 학습된다. 이는 외부 지식이 필요하지 않은 이미 학습된 task에서 LMM의 능력을 잠재적으로 감소시킬 수 있으므로, 외부 지식이 필요한 질문-정답 쌍과 외부 지식이 필요하지 않은 질문-정답 쌍을 동일한 mini-batch에서 혼합하는 데이터 혼합 접근 방식을 적용한다.
Experiments
- 데이터셋: Encyclopedic-VQA, InfoSeek
- 구현 디테일
- LLaVA fine-tuning
- 각 데이터셋에 대하여 fine-tuning
- LLaVA의 성능을 유지하기 위해 LLaVA-Instruct 데이터셋에서 샘플을 보충
- 학습 가능한 파라미터 수를 줄이기 위해 LoRA 사용
- 총 batch size: 샘플 512개
- 검색
- 텍스트 문서는 각각 600자씩의 청크로 분할됨
- 하나의 비주얼 인코더(CLIP ViT-L/14@336)로 이미지 임베딩과 쿼리 feature 추출을 모두 수행
- LLaVA fine-tuning
다음은 검색 결과이다.

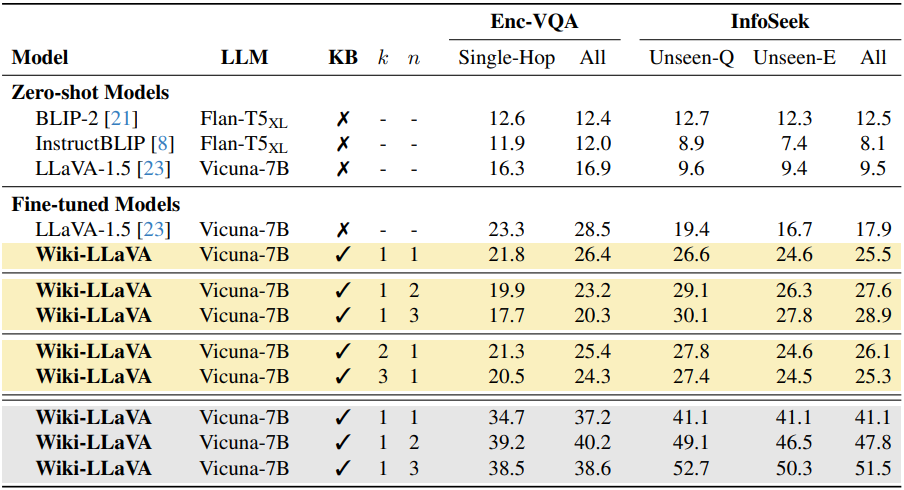
다음은 Encyclopedic-VQA test set과 InfoSeek validation set에 대한 정확도를 비교한 표이다. 노란색은 CLIP 모델로 검색을 수행한 결과이고, 회색은 GT 문서를 사용한 것이다. $k$는 검색된 문서의 수이고, $n$은 각 문서에서 검색된 청크의 수이다.
다음은 Encyclopedic-VQA와 InfoSeek에 대하여 LLaVA-1.5와 비교한 예시이다.

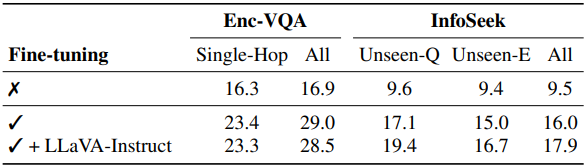
다음은 fine-tuning 중에 LLaVA-Instruct 데이터셋 사용 여부에 따른 성능을 비교한 표이다.
다음은 LLaVA-1.5에 대하여 원래의 성능이 보존되었는지를 분석한 표이다.