[BLOG 리뷰] Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
[Blog]
The Vicuna Team
30 Mar 2023
Introduction
Vicuna-13B는 ShareGPT에서 수집한 사용자 대화에서 LLaMA를 fine-tuning하여 학습시킨 오픈 소스 챗봇이다. GPT-4를 심사위원으로 사용한 예비 평가에서는 Vicuna-13B가 OpenAI ChatGPT와 Google Bard의 90% 이상의 품질을 달성하는 동시에 90% 이상의 예시에서 LLaMA나 Stanford Alpaca와 같은 다른 모델을 능가하는 것으로 나타났다. Vicuna-13B 학습 비용은 약 300달러이다. 온라인 데모, 코드, 모델 가중치가 공개되었다.
Overview
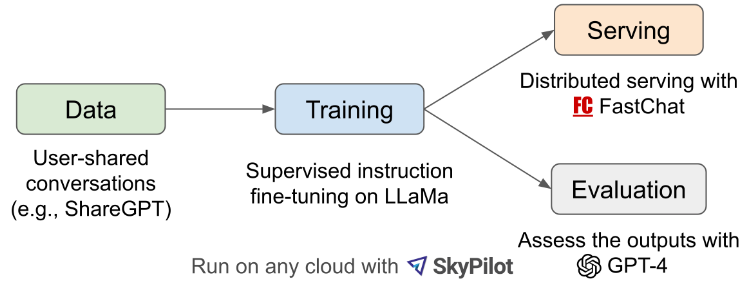
전체적인 개요는 위 그림과 같다. 먼저, 저자들은 사용자가 ChatGPT 대화를 공유할 수 있는 웹사이트인 ShareGPT.com에서 약 70,000개의 대화를 수집했다. 그런 다음, multi-turn 대화와 긴 시퀀스를 더 잘 처리할 수 있도록 Alpaca에서 제공하는 학습 스크립트를 개선하였다. 모델은 8개의 A100 GPU로 하루 동안 PyTorch FSDP를 사용하여 학습되었다.
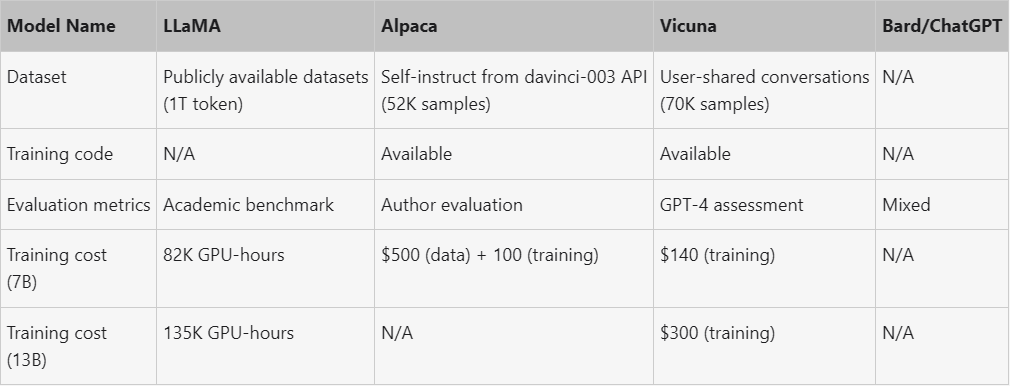
저자들은 80개의 다양한 질문 세트를 만들고 GPT-4를 활용하여 모델 출력을 판단함으로써 모델 품질에 대한 예비 평가를 수행했다. 두 모델을 비교하기 위해 각 모델의 출력을 각 질문에 대한 하나의 프롬프트로 결합한다. 그런 다음 프롬프트는 GPT-4로 전송되어 어떤 모델이 더 나은 응답을 제공하는지 평가된다. LLaMA, Alpaca, ChatGPT, Vicuna의 자세한 비교는 아래 표와 같다.
Training
Vicuna는 LLaMA 기본 모델을 fine-tuning하여 만들어졌다. 데이터 품질을 보장하기 위해 HTML을 다시 마크다운으로 변환하고 부적절하거나 품질이 낮은 샘플을 필터링하였다. 또한 긴 대화를 모델의 최대 컨텍스트 길이에 맞는 더 작은 세그먼트로 나누었다.
저자들은 스탠포드의 Alpaca를 기반으로 다음과 같은 개선 사항을 통해 모델을 구축하였다.
- Multi-turn 대화: Multi-turn 대화를 고려하여 loss를 조정하고 챗봇의 출력에 대해서만 fine-tuning loss를 계산하였다.
- 메모리 최적화: Vicuna가 긴 컨텍스트를 이해할 수 있도록 최대 컨텍스트 길이를 Alpaca의 512에서 2,048로 확장하여 GPU 메모리 요구 사항을 크게 늘렸다. Gradient checkpointing과 flash attention을 활용하여 메모리 부족 문제를 해결하였다.
- Spot instance를 통한 비용 절감: SkyPilot의 저렴한 spot instance를 활용하여 비용을 절감하였다. 이를 통해 학습 비용을 7B 모델은 500달러에서 140달러로, 13B 모델은 1,000달러에서 300달러로 절감하였다.
How To Evaluate a Chatbot?
AI 챗봇을 평가하는 것은 언어 이해, 추론 및 상황 인식을 평가해야 하기 때문에 어려운 작업이다. AI 챗봇이 더욱 발전함에 따라 현재의 공개 벤치마크로는 더 이상 충분하지 않을 수 있다. 예를 들어, 스탠포드의 Alpaca에 사용된 평가 데이터셋은 챗봇이 쉽게 답변할 수 있어 성능 차이를 식별하기 어렵게 만든다. 그 외에도 데이터 오염과 높은 비용 등의 한계점이 있다. 이러한 문제를 해결하기 위해 저자들은 챗봇 성능 평가를 자동화하는 GPT-4 기반 평가 프레임워크를 제안하였다.
먼저 페르미 문제, 역할극 시나리오, 코딩/수학 등 8가지 질문 카테고리를 고안하여 챗봇 성능의 다양한 측면을 테스트했다. 신중한 프롬프트 엔지니어링을 통해 GPT-4는 기본 모델이 어려움을 겪는 다양하고 까다로운 질문을 생성할 수 있다. 카테고리별로 10개의 질문을 선정하고 챗봇들로부터 답변을 수집한다. 그런 다음 GPT-4에게 유용성, 관련성, 정확성, 디테일을 기준으로 답변의 품질을 평가하도록 요청한다.
저자들은 GPT-4가 상대적으로 일관된 점수를 생성할 수 있을 뿐만 아니라 그러한 점수가 부여되는 이유에 대한 자세한 설명도 생성할 수 있음을 발견했다. 그러나 코딩/수학 task를 판단하는 데는 그리 좋지 않다는 점도 알아냈다.
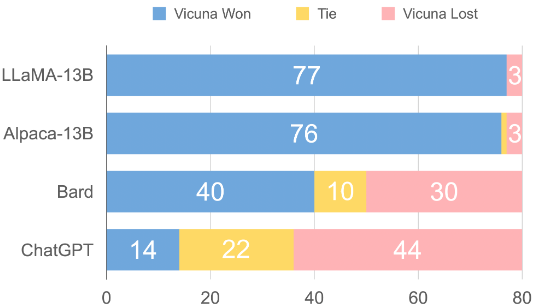
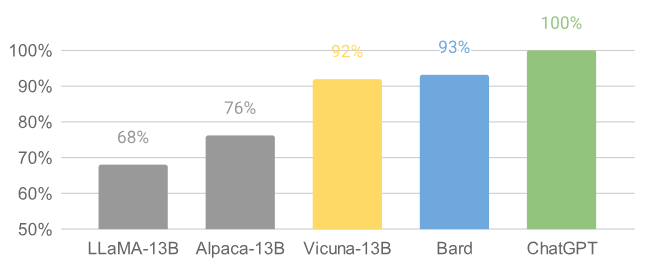
위 그림은 모든 baseline들과 Vicuna 사이의 비교 결과이다. GPT-4는 90% 이상의 질문에서 오픈소스 모델인 LLaMA, Alpaca보다 Vicuna를 선호하며, 독점 모델인 ChatGPT, Bard에 대해 경쟁력 있는 성능을 달성하였다. GPT-4는 각 응답에 10점 만점으로 정량적 점수를 할당하므로 80개 질문에 대해 각 모델에서 얻은 점수를 합산하여 각 (baseline, Vicuna) 비교 쌍의 총점을 계산할 수 있다.
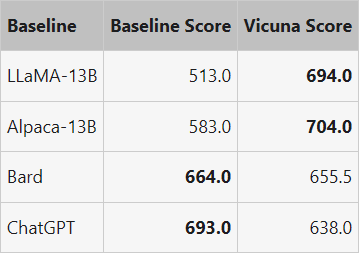
위 표에서 볼 수 있듯이 Vicuna의 총점은 ChatGPT의 92%이다.
제안된 평가 프레임워크는 챗봇 평가의 잠재력을 보여주지만 LLM은 hallucination을 일으키기 쉽기 때문에 아직 엄격하거나 성숙한 접근 방식은 아니다.
Limitations
- 추론이나 수학적 task를 잘 하지 못한다.
- 자신을 정확하게 식별하거나 출력의 사실적 정확성을 보장하는 데 한계가 있을 수 있다.
- 또한 안전성을 보장하거나 잠재적인 독성이나 편견을 완화할 만큼 충분히 최적화되지 않았다.