[논문리뷰] Wavelet Diffusion Models are fast and scalable Image Generators (WaveDiff)
CVPR 2023. [Paper] [Github]
Hao Phung, Quan Dao, Anh Tran
VinAI Research
29 Nov 2022
Introduction
Diffusion model은 최근에 도입되었음에도 불구하고 엄청나게 성장했으며 많은 연구 관심을 불러일으켰다. Diffusion model은 diffusion process를 되돌려 랜덤 noise 입력에서 깨끗하고 고품질의 출력을 생성한다. 이러한 기술은 다양한 데이터 도메인 및 애플리케이션에 적용되지만 이미지 생성 task에서 가장 놀라운 성공을 보여주었다. Diffusion model은 다양한 데이터셋의 생성 품질에서 SOTA GAN을 능가할 수 있다. 특히 diffusion model은 더 나은 mode coverage와 semantic map, 텍스트, 표현, 이미지와 같은 다양한 유형의 조건부 입력을 처리할 수 있는 유연한 방법을 제공한다. 이 능력 덕분에 text-to-image 생성, image-to-image translation, 이미지 인페인팅, 이미지 복원 등과 같은 다양한 애플리케이션을 제공한다. 최근의 diffusion 기반 text-to-image 생성 모델을 통해 사용자는 텍스트 입력만으로 믿을 수 없을 정도로 사실적인 이미지를 생성할 수 있어 AI 기반 디지털 아트의 새로운 시대를 열고 다양한 다른 도메인에 대한 응용이 유망하다.
Diffusion model은 큰 잠재력을 보여주지만 실행 속도가 매우 느리기 때문에 GAN처럼 널리 채택되지 못하는 치명적인 약점이 있다. DDPM은 원하는 출력 품질을 생성하기 위해 수천 개의 샘플링 step이 필요하며 단일 이미지를 생성하는 데 몇 분이 걸린다. 주로 샘플링 step을 줄여 inference 시간을 줄이기 위한 많은 기술이 제안되었다. 그러나 DiffusionGAN 이전의 가장 빠른 알고리즘은 여전히 32$\times$32 이미지를 생성하는 데 몇 초가 걸리며 이는 GAN보다 약 100배 느리다. DiffusionGAN은 Diffusion과 GAN을 단일 시스템에 결합하여 inference 속도를 향상시켰다. 이를 통해 궁극적으로 샘플링 step을 4개로 줄이고 32$\times$32 이미지를 생성하는 inference 시간을 몇 분의 1초로 단축했다. DiffusionGAN은 기존 diffusion model 중 가장 빠른 모델이다. 그럼에도 불구하고 StyleGAN에 비해 최소 4배 느리며, 출력 해상도를 높이면 속도 격차가 지속적으로 커진다. 더욱이 DiffusionGAN은 여전히 긴 학습 시간과 느린 수렴이 필요하므로 diffusion model이 아직 대규모 또는 실시간 애플리케이션에 준비되지 않았음을 보였주었다.
본 논문은 새로운 웨이블릿 기반 diffusion 방식을 도입하여 속도 격차를 해소하는 것을 목표로 한다. 본 논문의 방법은 각 입력을 저주파 성분 (LL)과 고주파 성분 (LH, HL, HH)에 대한 4개의 sub-band로 분해하는 이산 웨이블릿 변환에 의존한다. 이미지와 feature 수준 모두에 해당 변환을 적용한다. 이를 통해 출력 품질을 상대적으로 변경하지 않고 유지하면서 학습 및 inference 시간을 크게 줄일 수 있다. 이미지 수준에서는 공간 해상도를 4배 줄여 고속 향상을 얻었다. Feature 수준에서는 generator의 다양한 블록에 대한 웨이블릿 정보의 중요성을 강조한다. 이러한 디자인을 통해 약간의 컴퓨팅 오버헤드만 유발하면서 상당한 성능 향상을 얻을 수 있다.
본 논문이 제안한 Wavelet Diffusion은 CIFAR-10, STL-10, CelebA-HQ, LSUN-Church를 포함한 표준 벤치마크에 대하여 높은 생성 품질을 유지하면서 SOTA 학습 및 inference 속도를 제공하였다. Wavelet Diffusion은 대규모 및 실시간 시스템을 대상으로 diffusion model과 GAN 간의 속도 격차를 크게 줄인다.
Method
1. Wavelet-based diffusion scheme
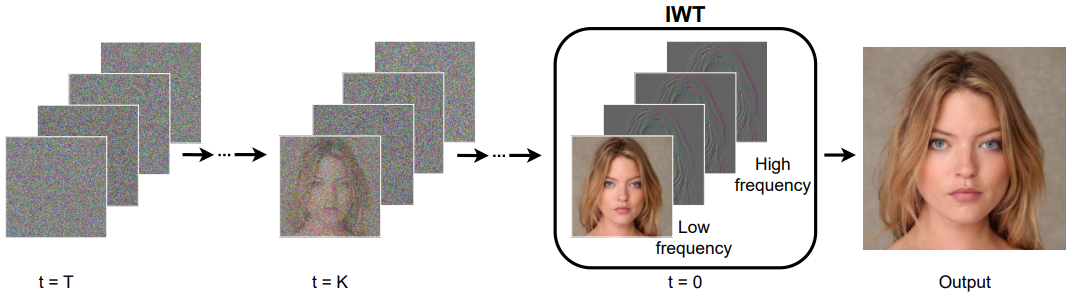
입력 이미지를 4개의 웨이블릿 sub-band로 분해하고 이를 denoising process의 단일 타겟으로 concat한다 (위 그림 참조). Diffusion model은 원본 이미지 공간이 아닌 웨이블릿 스펙트럼에서 수행된다. 결과적으로 모델은 고주파 정보를 활용하여 생성된 이미지의 디테일을 더욱 향상시킬 수 있다. 한편, 웨이블릿 sub-band의 공간적 영역은 원본 이미지보다 4배 작으므로 샘플링 프로세스의 계산 복잡성이 크게 줄어든다.
본 논문은 입력이 웨이블릿 변환의 4개의 웨이블릿 sub-band인 DiffusionGAN 모델을 기반으로 방법을 구축했다. 입력 이미지 $x \in \mathbb{R}^{3 \times H \times W}$가 주어지면 이를 낮은 sub-band와 높은 sub-band 세트로 분해하고 이를 concat하여 행렬 $y \in \mathbb{R}^{12 \times \frac{H}{2} \times \frac{W}{2}}$를 형성한다. 그런 다음 이 입력은 첫 번째 linear layer를 통해 기본 채널 $D$로 project되어 DiffusionGAN과 달리 네트워크 폭을 변경하지 않고 유지한다. 따라서 대부분의 네트워크는 공간 차원이 4배 감소하여 계산이 크게 줄어드는 이점을 얻는다.
$y_0$를 깨끗한 샘플, $y_t$를 $q(y_t \vert y_0)$에서 샘플링된 timestep $t$에서 손상된 샘플이라고 가정하자. Denoising process의 관점에서 generator는 변수 $y_t$의 튜플, latent $z \sim \mathcal{N}(0, I)$, timestep $t$를 받아 원래 신호 $y_0$의 근사치를 생성한다.
\[\begin{equation} y_0^\prime = G(y_t, z, t). \end{equation}\]예측된 잡음 샘플 $y_{t-1}^\prime$은 다루기 쉬운 posterior 분포 $q(y_{t−1} \vert y_t, y_0^\prime)$에서 추출된다. Discriminator의 역할은 실제 쌍 $(y_{t−1}, y_t)$과 가짜 쌍 $(y_{t-1}^\prime, y_t)$을 구별하는 것이다.
Adversarial objective
DiffusionGAN을 따라 adversarial loss를 통해 generator와 discriminator를 최적화한다.
\[\begin{aligned} \mathcal{L}_\textrm{adv}^D &= -\log (D (y_{t-1}, y_t, t)) + \log (D (y_{t-1}^\prime, y_t, t)) \\ \mathcal{L}_\textrm{adv}^G &= -\log (D (y_{t-1}^\prime, y_t, t)) \end{aligned}\]Reconstruction term
주파수 정보의 손실을 방지하고 웨이블릿 sub-band의 일관성을 보존하기 위해 reconstruction 항을 추가한다. 이는 생성된 이미지와 실제 이미지 간의 L1 loss로 공식화된다.
\[\begin{equation} \mathcal{L}_\textrm{rec} = \| y_0^\prime - y_0 \| \end{equation}\]Generator의 전체 목적 함수는 adversarial loss와 reconstruction loss의 선형 결합이다.
\[\begin{equation} \mathcal{L}^G = \mathcal{L}_\textrm{adv}^G + \lambda \mathcal{L}_\textrm{rec} \end{equation}\]여기서 $\lambda$는 가중치 hyperparameter이며 default로 1로 설정된다.
정의된 대로 몇 가지 샘플링 step을 거친 후 추정된 denoise된 sub-band $y_0^\prime$을 얻는다. 최종 이미지는 웨이블릿 역변환을 통해 복구될 수 있다.
\[\begin{equation} x_0^\prime = \textrm{IWT} (y_0^\prime) \end{equation}\]Algorithm 1은 샘플링 프로세스를 설명한다.

2. Wavelet-embedded networks
고주파 성분에 대한 인식을 강화하기 위해 generator를 통해 웨이블릿 정보를 feature space에 추가로 통합한다. 이는 최종 이미지의 선명도와 품질에 도움이 된다.
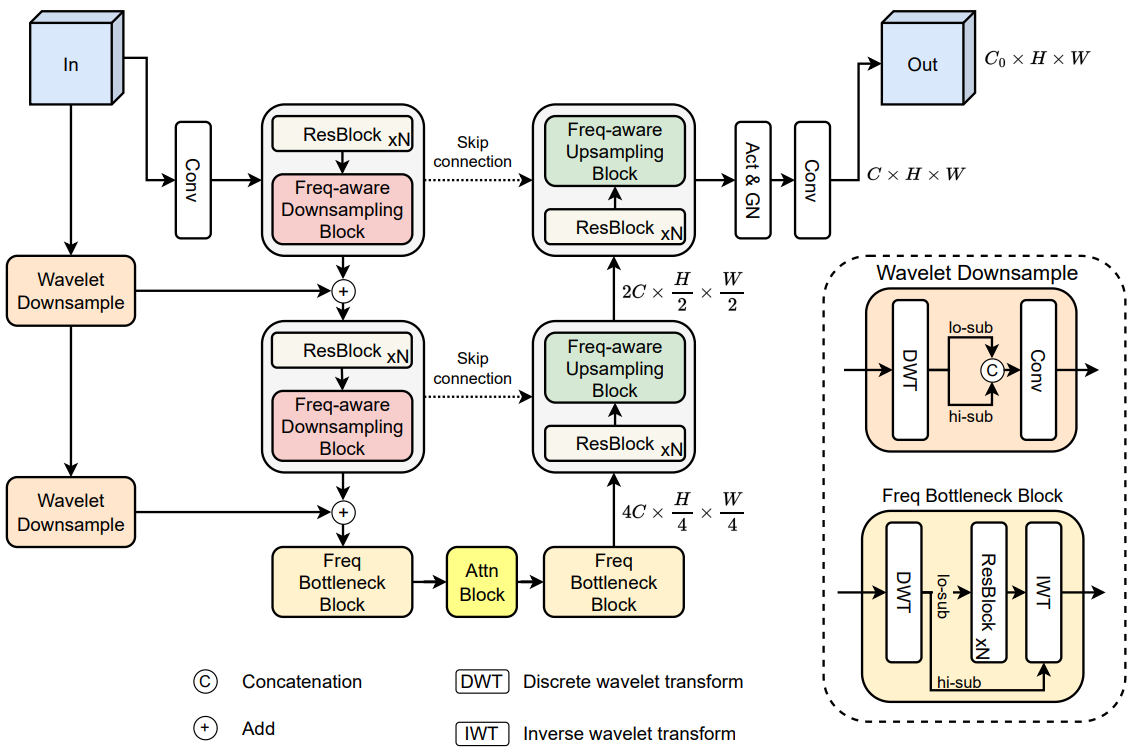
위 그림은 제안된 웨이브렛 내장 generator의 구조를 보여준다. Generator는 사전 정의된 $M$에 대하여 $M$개의 다운샘플링 블록, $M$개의 업샘플링 블록, 동일한 해상도의 블록 사이의 skip connection으로 구성된 UNet 구조를 따른다. 그러나 일반적인 다운샘플링 및 업샘플링 연산자를 사용하는 대신 frequency-aware 블록으로 대체한다. 가장 낮은 해상도에서는 저주파 성분과 고주파 성분에 대한 더 나은 attention을 위해 주파수 bottleneck을 사용한다. 마지막으로 원래 신호 $Y$를 인코더의 다양한 feature pyramid에 통합하기 위해 웨이블릿 다운샘플링 레이어를 사용하여 주파수 residual connection을 도입한다. $Y$를 입력 이미지로 표시하고 $F_i$를 $Y$의 $i$번째 중간 feature map이라 하자.
Frequency-aware downsampling and upsampling blocks
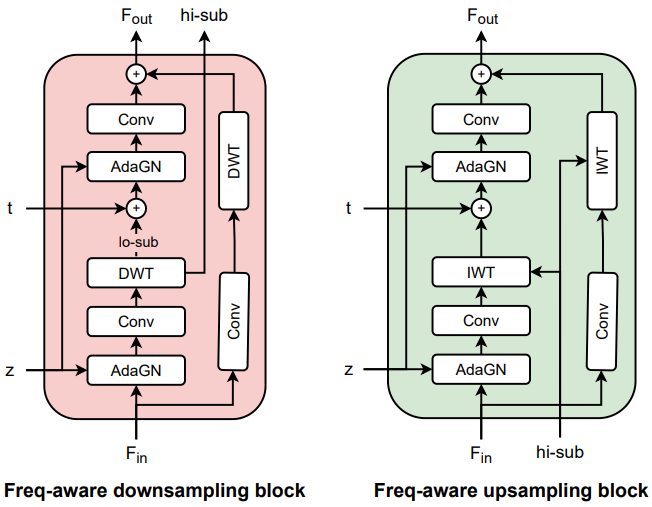
기존 접근 방식에서는 앨리어싱 아티팩트를 완화하기 위해 다운샘플링 및 업샘플링 프로세스에 블러링 커널을 사용했다. 대신에 더 나은 업샘플링과 다운샘플링을 위해 웨이블릿 변환의 고유 속성을 활용한다 (위 그림 참조). 실제로 이는 이러한 연산에 대한 고주파 정보에 대한 인식을 강화한다. 특히, 다운샘플링 블록은 입력 feature $F_i$, latent $z$, 시간 임베딩 $t$의 튜플을 받으며, 이는 다운샘플링된 feature와 고주파 sub-band를 반환하기 위해 일련의 레이어를 통해 처리된다. 이렇게 반환된 sub-band는 업샘플링 블록의 주파수 단서를 기반으로 업샘플링 feature에 대한 추가 입력으로 사용된다.
Frequency bottleneck block
주파수 bottleneck 블록은 두 개의 주파수 bottleneck 블록과 그 사이에 하나의 attention 블록을 포함하는 중간 단계에 위치한다. 각 주파수 bottleneck 블록은 먼저 feature map $F_i$를 저주파 sub-band $F_{i,ll}$와 고주파 sub-band $F_{i,H}$의 concatenation으로 나눈다. $F_{i,ll}$은 더 깊은 처리를 위해 resnet 블록에 입력으로 전달된다. 처리된 저주파 feature map과 원래의 고주파 sub-band $F_{i,H}$는 IWT를 통해 다시 원래 공간으로 변환된다. 이러한 bottleneck으로 인해 모델은 고주파 디테일을 보존하면서 저주파 sub-band의 중간 feature 표현을 학습하는 데 집중할 수 있다.
Frequency residual connection
네트워크의 원래 설계는 strided-convolution 다운샘플링 레이어를 통해 원래 신호 $Y$를 인코더의 다양한 feature pyramid에 통합한다. 대신 웨이블릿 다운샘플링 레이어를 사용하여 입력 $Y$의 residual shortcut을 해당 feature 차원에 매핑한 다음 각 feature pyramid에 추가한다. 구체적으로, $Y$의 residual shortcut은 4개의 sub-band로 분해된 다음 concat되어 feature projection을 위한 convolution layer에 공급된다. 이 shortcut은 feature 임베딩의 주파수 소스에 대한 인식을 강화하는 것을 목표로 한다.
Experiments
- 데이터셋: CIFAR-10, STL-10, CelebAHQ, LSUN-Church
- 구현 디테일
- DiffusionGAN과 동일한 학습 설정
- 샘플링 step 수
- CelebA-HQ: 2
- CIFAR-10, STL-10, LSUN-Church: 4
- 데이터셋에 따라 1개 ~ 8개의 NVIDIA A100 GPU에서 학습
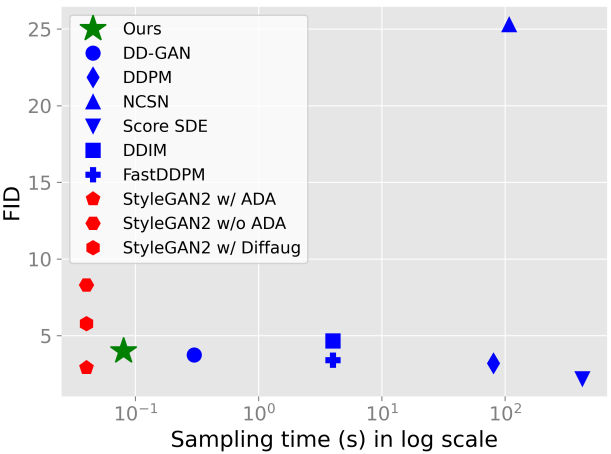
1. Experimental results
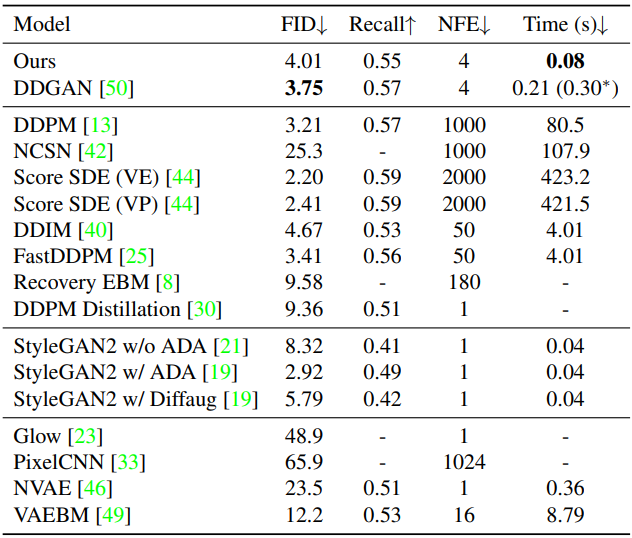
CIFAR-10
다음은 CIFAR-10 32$\times$32에서의 결과이다.

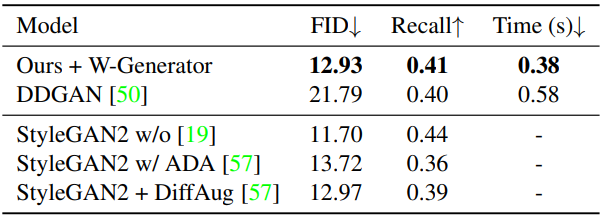
STL-10
다음은 STL-10 64$\times$64에서의 결과이다.

다음은 STL-10 64$\times$64에 대하여 학습 수렴을 비교한 그래프이다.

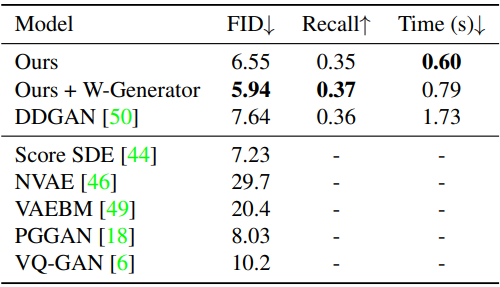
CelebA-HQ
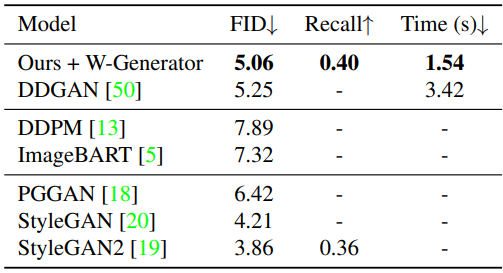
다음은 CelebA-HQ 256$\times$256에서의 결과이다.

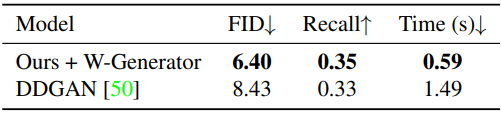
다음은 CelebA-HQ 512$\times$512에서의 결과이다.

LSUN-Church
다음은 LSUN-Church 256$\times$256에서의 결과이다.

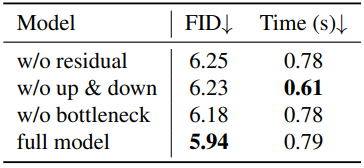
2. Ablation studies
다음은 웨이블릿 generator에 대한 ablation 결과이다. (CelebA-HQ 256$\times$256, 500 epochs)
3. Running time when generating a single image
다음은 각 벤치마크에서 단일 이미지를 생성할 때의 실행 시간을 나타낸 표이다.

4. Wavelet Diffusion이 더 빠르고 안정적으로 수렴하는 이유는 무엇인가?
- 공간 차원이 낮기 때문에 저주파 sub-band를 더 쉽게 학습한다.
- 독특한 디테일에 초점을 맞춰 희박하고 반복적인 고주파 성분을 빠르게 학습한다.