[논문리뷰] TEXGen: a Generative Diffusion Model for Mesh Textures
SIGGRAPH Asia 2024. [Paper] [Page] [Github]
Xin Yu, Ze Yuan, Yuan-Chen Guo, Ying-Tian Liu, JianHui Liu, Yangguang Li, Yan-Pei Cao, Ding Liang, Xiaojuan Qi
The University of Hong Kong | VAST | Beihang University | Tsinghua University
22 Nov 2024

Introduction
대규모 모델의 최근 성공은 주로 두 가지 핵심 요인에 기인한다.
- 모델 크기와 데이터 양이 증가함에 따라 확장 가능하고 효과적인 네트워크 아키텍처
- 일반화를 용이하게 하는 대규모 데이터셋
본 논문에서는 일반화 가능하고 고품질의 메쉬 텍스처링을 위해 모델 크기와 데이터를 확장하여 대규모 생성 모델을 구축하는 잠재력을 탐구하였다.
본 논문은 메쉬 텍스처링을 위한 대규모 생성 모델인 TEXGen을 소개한다. TEXGen은 확장 가능하고 고해상도 디테일을 보존하기 때문에 생성을 위한 표현으로 UV 텍스처 맵을 사용한다. 더 중요한 것은 렌더링 loss에만 의존하지 않고 GT 텍스처 맵에서 직접 학습하여 diffusion 기반 학습과 호환되고 전반적인 생성 품질이 향상된다는 것이다. Diffusion model을 활용하여 메쉬 텍스처 분포를 학습하려고 시도했던 방법들이 있었지만, 어느 것도 end-to-end 학습이나 feed-forward inference를 달성하지 못해 오차가 누적되고 확장성 문제가 발생했다.
저자들은 메쉬 표면에서 효과적인 feature 상호 작용을 수행하기 위해 2D UV space에서 convolution 연산을 통합한 다음, 3D space에서 작동하는 sparse convolution들과 attention layer들을 통합하는 확장 가능한 2D-3D 하이브리드 네트워크 아키텍처를 제안하였다. 이 간단하면서도 효과적인 아키텍처는 몇 가지 주요 이점을 제공한다.
- UV space에서 convolution 연산을 적용함으로써 네트워크는 로컬 및 고해상도 디테일을 효과적으로 학습한다.
- 계산을 3D space로 끌어올림으로써 네트워크는 UV parameterization 프로세스에 의해 사라지는 글로벌한 3D 의존성과 이웃 관계를 학습하여 글로벌한 3D 일관성을 보장할 수 있다.
이 하이브리드 디자인을 통해 3D 연속성을 유지하면서도 관리 가능한 계산을 위해 3D space에서 sparse feature들을 사용할 수 있으므로 아키텍처를 확장할 수 있다. 저자들은 단일 뷰 이미지와 텍스트 프롬프트에 따라 feed-forward 방식으로 고해상도 텍스처(ex. 1024$\times$1024 텍스처 맵)를 직접 합성할 수 있는 대규모 텍스처 diffusion model을 학습시켰다. 또한, 사전 학습된 모델은 텍스트 기반 텍스처 합성, 인페인팅, sparse view에서의 텍스처 완성 등 다양한 응용이 가능하다.
Method
1. Representation for Texture Synthesis
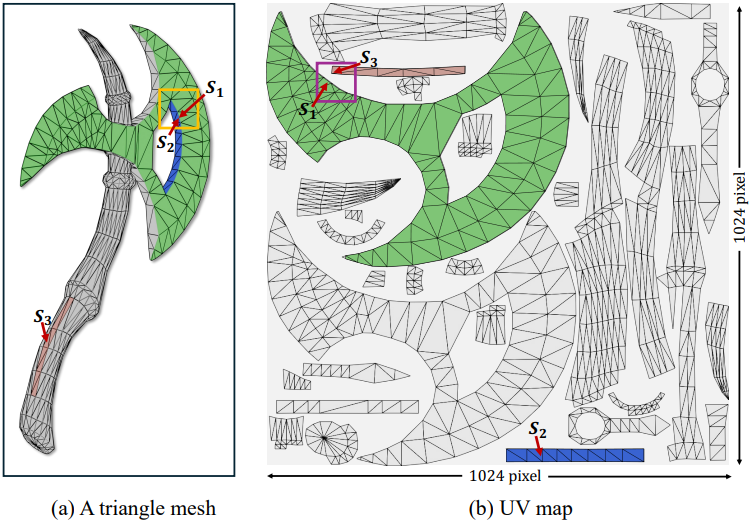
표면은 근본적으로 3차원 공간에 포함된 2차원 신호로 볼 수 있다. 결과적으로 메쉬 구조를 처리하기 위한 전통적인 기술은 UV 매핑으로, 3D 구조를 컴팩트한 2D 표현으로 평면화한다. 이 변환을 통해 텍스처와 같은 3D 속성을 재구성하여 2D 평면에 표현할 수 있다. 2D UV space는 개별 섬 내의 이웃 의존성을 효과적으로 포착하여 그리드 구조 덕분에 텍스처 생성을 위한 계산 효율성을 향상시킨다. 또한 텍스처 맵의 명시적 특성은 직접적인 학습을 용이하게 하여 diffusion model과의 통합에 적합하다.
2D UV 텍스처 맵의 이러한 장점에도 불구하고, 이러한 접근 방식은 UV 매핑에 내재된 단편화로 인해 필연적으로 여러 섬 간의 글로벌한 3D 일관성을 잃는다. 위 그림에서 볼 수 있듯이, 섬 $S_1$과 $S_2$는 3D 표면에서는 인접하지만 UV 맵에서는 멀리 떨어져 있다. 반대로, UV 맵에서 인접한 $S_1$과 $S_3$는 3D 표면에서 물리적 연결을 공유하지 않는다.
이러한 단편화로 인해 기존 이미지 기반 모델에서 feature 추출이 부정확해질 수 있다. 저자들은 이 문제를 해결하기 위해 2D UV 공간의 장점과 3D 포인트를 통합하여 글로벌 일관성과 연속성을 유지하는 새로운 모델을 제안하였다. 이를 통해 표현을 상호 연결하고 개선하여 고해상도 2D 텍스처 맵을 생성하는 데 효과적인 학습을 촉진한다.
2. Model Construction
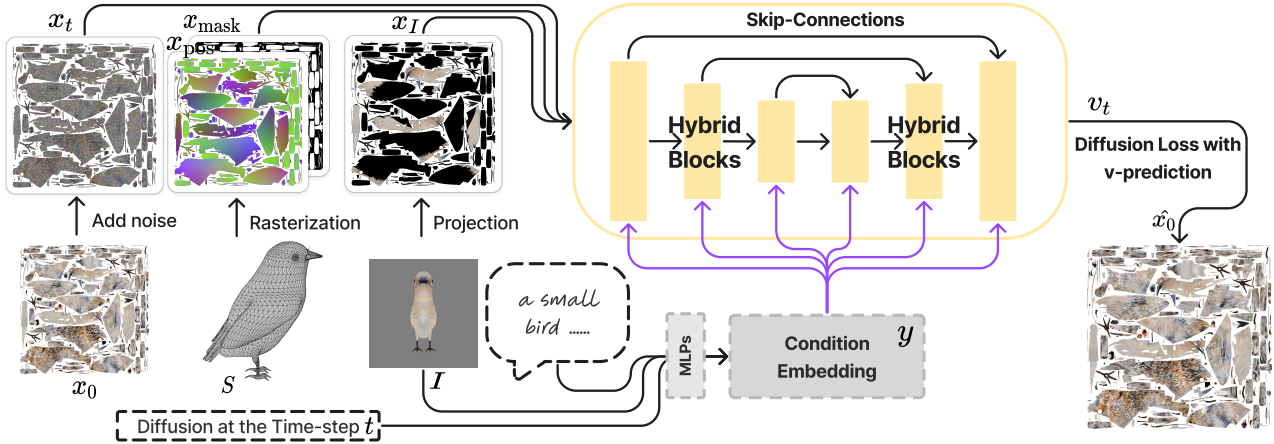
단일 이미지나 텍스트 프롬프트와 같은 특정 조건이 주어지면 반복적인 noise 제거를 수행하여 고품질 2D 텍스처 맵을 생성하는 diffusion model을 학습할 수 있다. 모델의 핵심은 2D와 3D 공간 모두에서 feature를 학습하는 하이브리드 2D-3D 네트워크이다.
텍스트 프롬프트는 사용자가 생성된 콘텐츠에서 원하는 속성을 지정할 수 있는 직관적인 인터페이스를 제공하여 모델을 더 쉽게 접근하고 사용자 의도에 대응할 수 있도록 한다. 반면, 이미지 컨디셔닝은 텍스트만으로는 간과할 수 있는 픽셀 수준의 디테일을 캡처하여 생성 프로세스를 정확하게 제어하여 diffusion model에 대한 더 강력한 guidance를 제공한다. 게다가 풍부한 텍스처가 있는 이미지는 diffusion process에서 귀중한 prior 역할을 하여 보다 효과적인 학습을 촉진할 수 있다. Text-to-image 모델을 사용하여 텍스트만으로 이미지를 생성하는 것이 가능하므로 텍스트와 이미지 모두에 대한 조건을 선택하여 학습시킨다. Inference 시에는 이미지 데이터를 포함하거나 생략할 수 있다.
Network
학습 파이프라인은 diffusion 기반 접근 방식을 활용한다. 각 denoising step에서 네트워크는 noise가 적용된 텍스처 맵 $x_t$, 위치 맵 \(x_\textrm{pos}\), 마스크 맵 \(x_\textrm{mask}\), 단일 이미지 $I$, 텍스트 프롬프트 $c$, timestep $t$를 입력받고 $x_t$에서 noise를 제거한다. 이미지 $I$를 네트워크에 통합하는 것은 두 가지 다른 방법으로 이루어진다.
- 이미지 픽셀의 projection: 이미지 픽셀을 표면으로 다시 projection하여 추가 입력으로 사용되는 부분 텍스처 맵 $x_I$를 도출한다.
- 글로벌 임베딩 추출: CLIP의 이미지 인코더와 텍스트 인코더를 사용하여 각각 글로벌 이미지 임베딩과 글로벌 텍스트 임베딩을 추출한다.
학습 가능한 timestep 임베딩은 다양한 $t$ 값을 수용하며, 별도의 MLP를 통해 처리된 후 결합되어 글로벌 조건 임베딩 $y$를 형성한다. 이 임베딩은 네트워크 내의 feature들을 조절하여 조건별 정보를 통합한다. 네트워크는 속도 $v_t$를 예측하는데, 이는 noise $\epsilon$의 예측 또는 $x_0$의 예측으로 동등하게 변환될 수 있다. 본 논문의 아키텍처는 UNet 프레임워크를 기반으로 한다. 그러나 각 단계에서 hybrid 2D-3D block을 통합하여 고유하게 향상시킨다. 이러한 적응을 통해 네트워크는 텍스처 맵의 고유한 특성을 능숙하게 관리할 수 있다.
Hybrid 2D-3D block
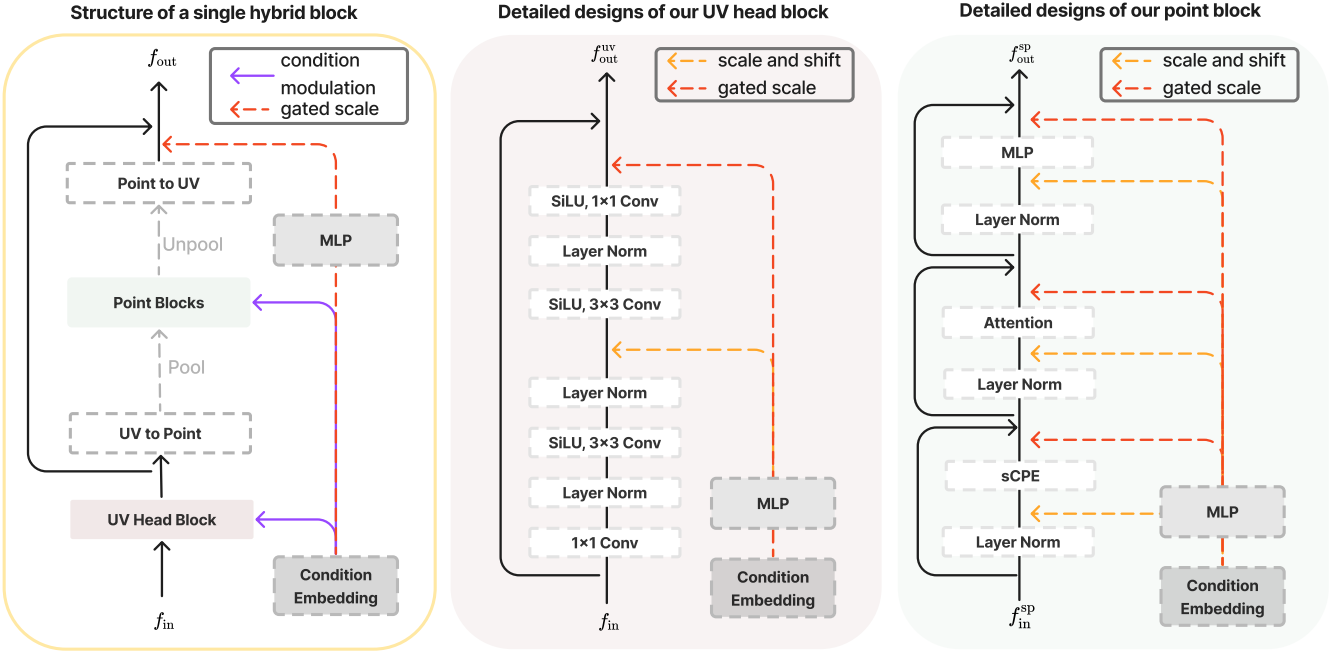
디자인의 핵심은 효율적인 feature 학습을 용이하게 하는 hybrid 2D-3D block이다. Hybrid block은 UV head와 여러 3D point cloud block으로 구성된다. 입력 UV feature $f_\textrm{in}$은 먼저 2D convolution block을 통해 처리되어 UV space에서 로컬 feature를 추출한다. 2D convolution은 이웃과 가중치를 설정하는 데 있어 3D convolution이나 point cloud KNN 검색보다 계산적으로 더 효율적이어서 더 높은 해상도로 확장할 수 있다. 게다가, 섬 내에서 2D convolution은 인접한 feature의 집계가 체적 이웃이 아닌 표면 이웃을 기반으로 하도록 보장한다. 따라서 이 단계는 고해상도 정보의 보존을 효율적으로 보장한다.
UV space에서 섬들 사이에 3D 연결을 설정하기 위해, rasterization을 사용하여 출력 UV feature \(f_\textrm{out}^\textrm{uv}\)를 3D space로 다시 매핑하여 3D point cloud feature \(f_\textrm{in}^\textrm{point}\)로 재구성한다. 3D space에서의 주요 목적은 고해상도의 디테일 feature를 추출하는 대신 3D 이웃 관계와 글로벌한 구조적 feature를 획득하여 3D 일관성을 개선하는 것이다. 결과적으로, 비교적 sparse한 feature들을 사용하고 효율적인 모듈을 설계하여 확장성을 보장한다.
Serialized attention
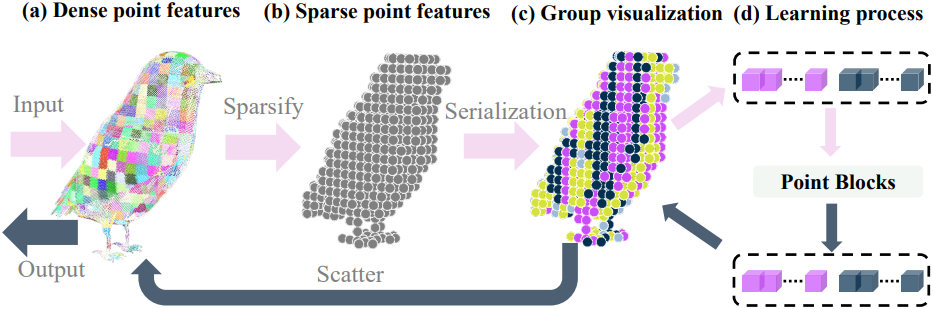
입력 dense point feature \(f_\textrm{in}^\textrm{point}\)에 대해, grid-pooling을 채택하여 point의 개수를 sparsify하고 \(f_\textrm{in}^\textrm{sp}\)을 얻는다. 그런 다음 풀링된 feature는 토큰으로 처리되고 학습을 위해 point attention layer에서 처리된다. 효율성을 높이기 위해 패치 기반 attention을 용이하게 하는 Serialized Attention을 활용한다. 구체적으로, point feature들은 space-filling curve에 의해 정의된 코드를 기반으로 여러 그룹으로 분할된다.
Position encoding
위치 인코딩은 3D 위치 정보를 모델에 통합하는 데 중요한 역할을 한다. 처음에 저자들은 attention layer 바로 앞에 sparse convolution layer를 통합하는 xCPE를 구현했다. 그러나 이 접근 방식은 Transformer 차원이 증가함에 따라 비효율적이고 시간이 많이 걸린다.
이러한 비효율성을 해결하기 위해 저자들은 sparse convolution을 전에 linear layer를 사용하여 입력의 채널 차원을 줄이는 sCPE라는 수정된 접근 방식을 개발했다. 그런 다음, 다른 linear layer를 사용하여 채널 차원을 다시 원래 크기로 키워 skip connection의 feature 차원과 일치시킨다.
Condition modulation
2D block과 3D block 모두에서 글로벌 조건 임베딩을 사용하여 중간 feature를 변조하고 조건부 정보를 주입한다. 특히 DiT에서 영감을 받아 MLP를 사용하여 조건 임베딩 $y$에서 변조 벡터 $\gamma$와 $\beta$를 학습시킨다. 이러한 벡터는 채널 차원에서 중간 feature를 scale 및 shift하는 데 사용된다.
\[\begin{equation} f_\textrm{mod} = (1 + \gamma) \cdot f_\textrm{in} + \beta \end{equation}\]또한 skip connection의 feature와 융합하기 전에 출력 feature를 scaling하는 gated scale $\alpha$도 학습시킨다.
\[\begin{equation} f_\textrm{fuse} = \alpha \cdot f_\textrm{out} + f_\textrm{skip} \end{equation}\]학습된 sparse point feature \(f_\textrm{out}^\textrm{sp}\)는 그리드 분할을 기반으로 dense한 좌표들로 분산되어 \(f_\textrm{out}^\textrm{point}\)가 된다. Skip-connected UV feature와 융합하기 전에, 조건 임베딩 $y$에서 gated scale $\alpha^\textrm{point}$도 학습시켜 point feature를 scaling한다. 최종 융합된 feature는 다음과 같다.
\[\begin{equation} f_\textrm{out} = f_\textrm{out}^\textrm{uv} + \alpha^\textrm{point} \cdot f_\textrm{out}^\textrm{point} \end{equation}\]3. Diffusion Learning
실제 텍스처 맵 $x_0$가 주어지면 무작위로 timestep \(t \in \{0, 1, \ldots, 1000\}\)를 샘플링하고 텍스처 맵에 noise를 추가한다.
\[\begin{equation} x_t = \sqrt{\vphantom{1} \bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \end{equation}\]구체적으로, Stable Diffusion의 noise scheduler를 사용하고, zero-terminal SNR을 채택하여 $t = 1000$일 때 \(\bar{\alpha}_t = 0\)이 되도록 noise scheduler를 scaling한다. 이는 초기 시작 지점에서 학습과 inference 사이의 격차를 없애는 데 도움이 된다. 학습하는 동안, 확률 $p = 0.2$로 텍스트 임베딩과 이미지 임베딩을 무작위로 제거하여 inference 중에 classifier-free guidance를 활용할 수 있다.
네트워크 출력 \(x_\textrm{out}\)의 경우, $v$-prediction을 사용하여 diffusion loss를 계산한다.
\[\begin{aligned} v_t &= \sqrt{\vphantom{1} \bar{\alpha}_t} \epsilon - \sqrt{1 - \bar{\alpha}_t} x_0 \end{aligned}\]($\lambda_t$는 soft-min-SNR 가중치)
특히, $v$-prediction 출력에서 예측 샘플 \(\hat{x}_0\)를 얻고 멀티뷰 렌더링에 LPIPS loss를 적용한다.
\[\begin{equation} \mathcal{L}_\textrm{render} = \frac{1}{N} \sum \textrm{LPIPS} (\hat{I}_i, I_i) \end{equation}\](\(\hat{I}_i\)는 예측된 텍스처 맵 \(\hat{x}_0\)를 사용하여 임의의 시점에서 렌더링된 이미지, $I_i$는 대응되는 GT 이미지)
최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{diff} + 0.5 \mathcal{L}_\textrm{render} \end{equation}\]4. Texture Generation
학습 후, denoising network는 3D 메쉬에 대한 고품질 텍스처 맵을 생성할 준비가 되었다. UV space에서 Gaussian noise로 텍스처 맵을 초기화한 후, 조건부 정보를 사용하여 반복적으로 noise를 제거하고 최종 텍스처 맵을 생성한다. Inference를 가속화하기 위해 30 step의 DDIM 샘플링을 사용한다. 흥미롭게도, 단일 뷰 이미지와 텍스트 프롬프트로 모델을 학습시켰지만 다른 시나리오와 애플리케이션으로 일반화할 수 있다.
Text-to-texture
텍스트 프롬프트만 제공된 경우 임의로 메쉬 시점을 선택하고 depth map을 렌더링한 다음 ControlNet을 사용하여 해당 단일 뷰 이미지를 생성할 수 있다.
이런 식으로 텍스트에서 텍스처를 생성할 수 있기 때문에 텍스트 조건부 모델 대신 이미지 조건부 모델을 학습시키는 것이다. 텍스트에서 이미지는 쉽게 얻을 수 있지만, 텍스트 조건부 모델은 이미지에서 제공하는 제어 능력이 부족하다.
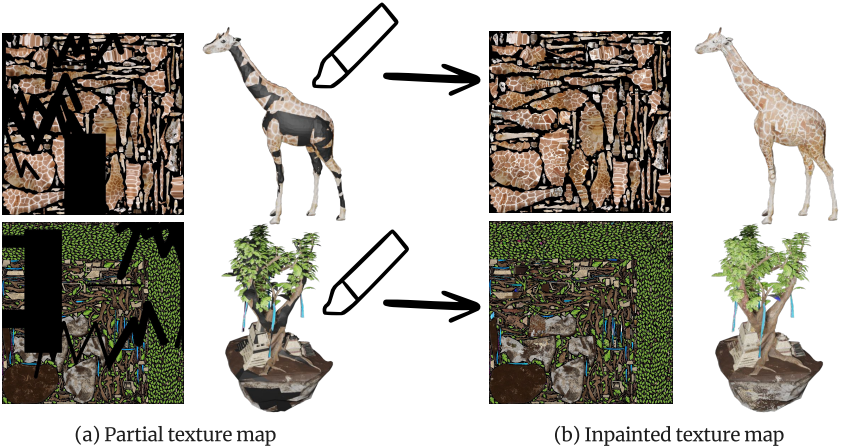
텍스처 인페인팅
학습하는 동안 단일 뷰 이미지의 픽셀 정보가 UV space로 다시 projection되어 부분적인 초기 텍스처 맵이 생성된다. 네트워크는 처음 보는 부분을 채우도록 학습되었다. 이 능력을 사용하면 모델이 텍스처 인페인팅 모델로 기능할 수 있다.
구체적으로, 사용자가 제공한 부분 텍스처 맵과 마스크를 $x_I$로 가져와서 인페인팅을 위해 네트워크에 입력할 수 있다. 테스트 중에 필요한 이미지 임베딩의 경우, 학습에 이미지 임베딩을 무작위로 제거하는 것이 포함되어 있으므로 임베딩을 0으로 설정한다.
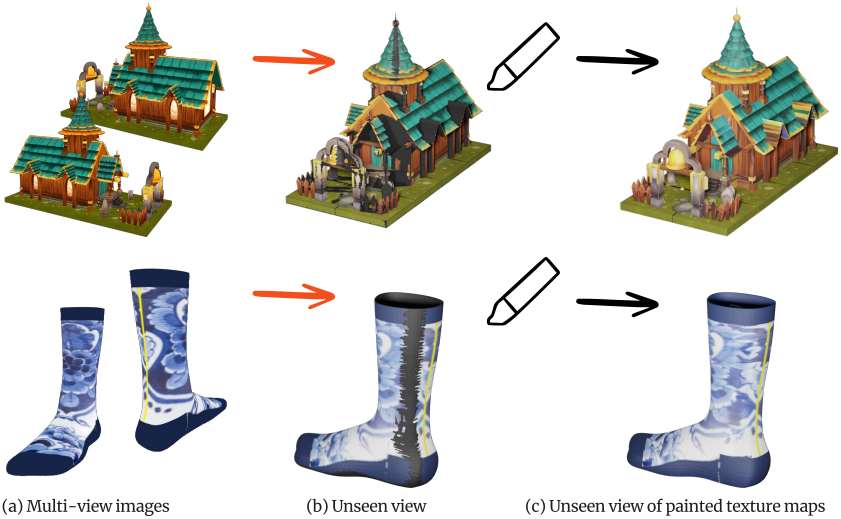
Sparse view로부터 텍스처 완성
몇 개의 sparse view 이미지가 제공되면. 단순히 각 이미지를 projection하고 융합하고 이미지 임베딩 추출을 위해 하나의 이미지를 무작위로 선택한다. 모델은 가려진 부분의 텍스처를 채우고 전체 텍스처 맵을 복구할 수 있다.
Experiments
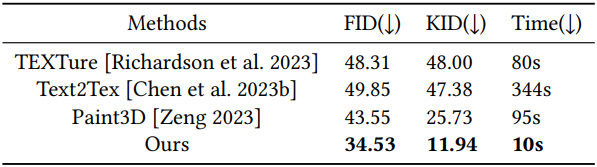
1. Main Results and Comparisons
다음은 텍스처 생성 예시들이다.

다음은 SOTA 방법들과 비교한 결과이다.

2. Applications
다음은 TEXGen으로 모든 메쉬를 텍스처링한 실내 장면이다. 각 메쉬에 대한 깊이 제어를 사용하여 ControlNet으로 단일 뷰를 생성하고 TEXGen으로 모두 페인팅한 것이다.

다음은 텍스트 조건부 생성에 대한 user study 결과이다. (MLLM Score는 Claude 3.5-sonnet로 측정)

다음은 TEXGen으로 텍스처를 인페인팅한 예시들이다.
다음은 sparse view로부터 텍스처를 완성한 예시들이다.
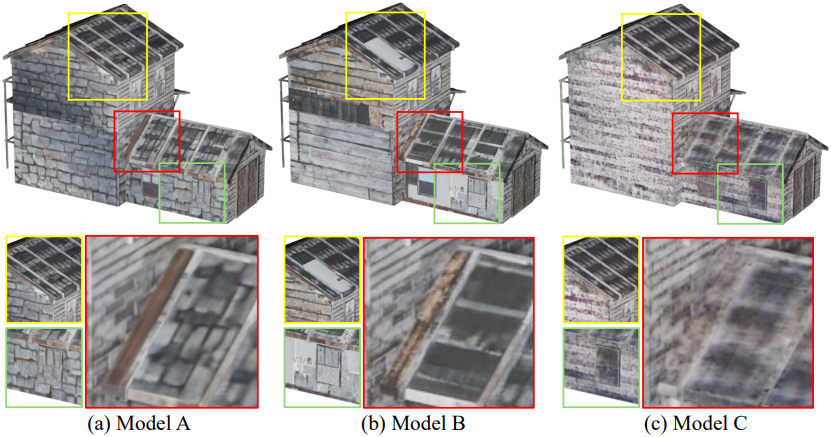
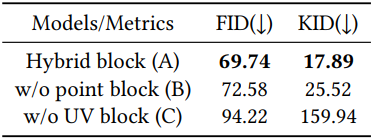
3. Model Analysis
다음은 하이브리드 디자인에 대한 ablation 결과이다.
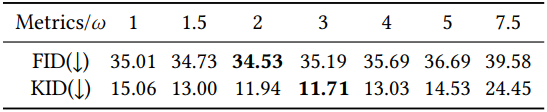
다음은 classifier-free guidance 가중치에 대한 ablation 결과이다.