[논문리뷰] Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering
ICCV 2025. [Paper] [Page] [Github]
Shanlin Sun, Yifan Wang, Hanwen Zhang, Yifeng Xiong, Qin Ren, Ruogu Fang, Xiaohui Xie, Chenyu You
University of California, Irvine | Brook University | Huazhong University of Science and Technology | University of Florida
20 Aug 2025

Introduction
최근 RGB↔X는 입력 intrinsic 채널의 유연한 조합을 수용하는 최초의 forward rendering용 diffusion model을 제안했다. 최근 DiffusionRenderer는 RGB↔X와 Neural Gaffer의 개념을 video diffusion에 통합하여 동영상에서의 intrinsic 분해 및 relighting에서 최고 수준의 성능을 달성했다. 이러한 발전에도 불구하고, 현재의 diffusion 기반 접근법은 두 가지 중요한 한계를 가지고 있다.
- 연산 비효율성
- Inverse rendering 및 forward rendering 간의 사이클 일관성 부족
본 논문에서는 inverse rendering과 forward rendering을 위한 single-step diffusion model을 각각 학습하는 동시에 두 모델 간의 사이클 일관성을 유지하는 통합 프레임워크인 Ouroboros를 제안하였다. 간단한 end-to-end fine-tuning 기법으로 경쟁력 있는 품질을 유지하면서 효과적으로 적용될 수 있음을 보여주었다. 저자들은 다양한 intrinsic map을 사용하는 여러 합성 데이터셋을 사용하여 RGB↔X에서 single-step 모델들을 fine-tuning하였다. 이 접근법은 이미지 분해 및 합성에서 SOTA 성능을 유지하면서 inference 속도를 50배 향상시켰다.
독립적으로 학습된 forward 모델과 inverse 모델의 중요한 한계는 순차적으로 적용될 때 일관되지 않은 동작으로 인해 분해된 속성이 원본 이미지를 정확하게 재구성하지 못하는 경우가 많다는 점이다. 본 논문에서는 조건부 이미지 이해 및 생성 과정에서 사이클 일관성을 구현하였다. Single-step 생성 프레임워크를 사용하면 CycleGAN과 유사하게 학습 과정에서 inverse rendering과 forward rendering 사이의 픽셀 공간에서 사이클 일관성을 간편하게 적용할 수 있다. 이 사이클 일관성 메커니즘은 self-supervision을 통해 주석이 없는 실제 데이터를 학습 프로세스에 통합하여, 쌍으로 된 주석을 사용하는 대규모의 고품질, 다양한 합성 렌더링에 대한 의존도를 줄였다.
Method
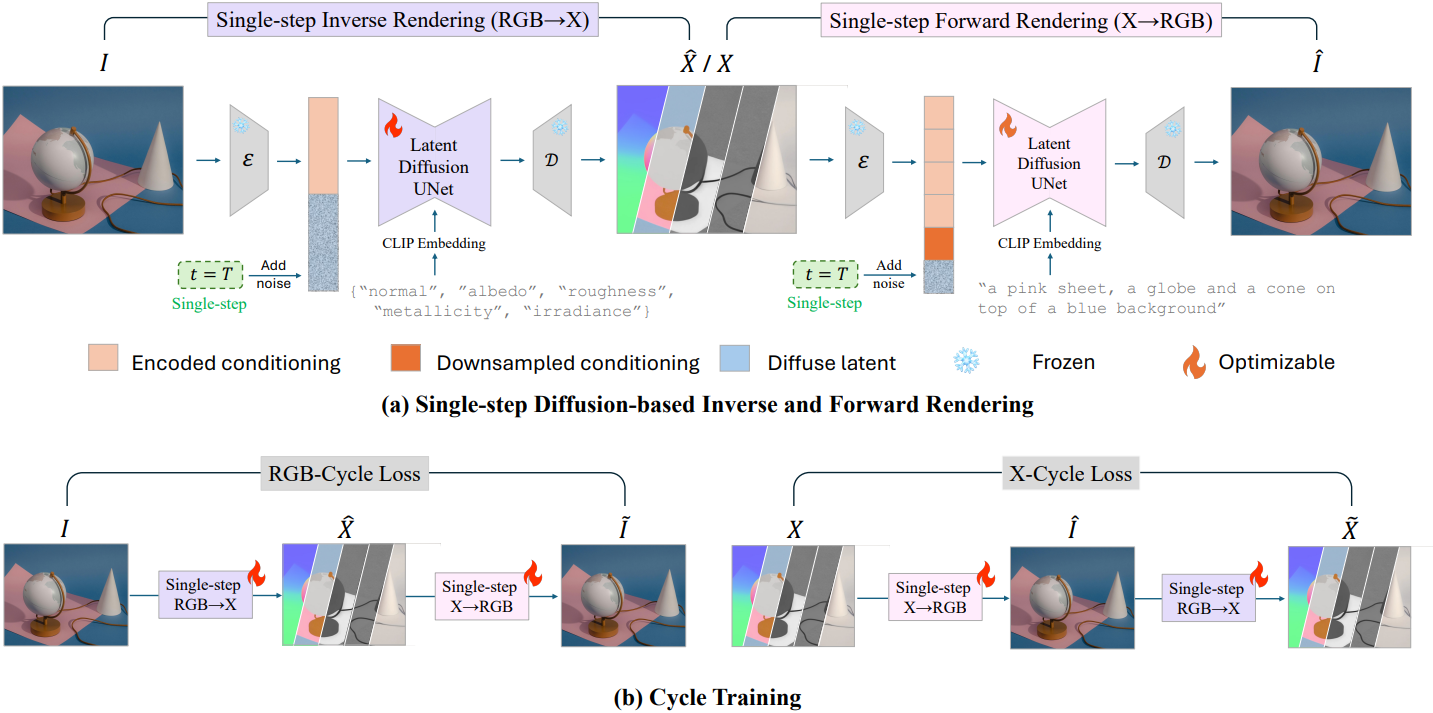
1. Finetuning Single-Step Prediction Model
저자들은 E2E에서 영감을 받아, 사전 학습된 RGB↔X diffusion model을 fine-tuning하여 single-step inference를 통해 고품질 intrinsic map을 생성하였다. RGB 이미지 $I$와 intrinsic map 세트 $X$로 구성된 데이터 $(X, I)$가 주어졌을 때, diffusion model은 하나를 조건부 입력으로 사용하여 다른 하나를 생성한다. Fine-tuning 프레임워크에서 UNet을 제외한 대부분의 diffusion 모듈은 고정된다.
Finetuning pipeline
효율적인 single-step 예측을 위해, 학습 과정에서 timestep을 $t = T$로 고정하여 모델이 가장 noise가 많은 상태에서 타겟 상태까지 한 번의 step로 noise를 제거하는 방법을 학습하도록 한다. 초기 상태로 noise가 없는 상태를 사용하는 E2E와 달리, timestep $T$에서 타겟 latent에 multi-resolution noise를 적용한다. 즉, single-step 모델은 deterministic하지 않다. 이러한 deterministic하지 않은 접근 방식은 깊이 추정이나 normal 추정처럼 더 명확한 GT를 갖는 task와는 달리, 본질적으로 여러 가지 가능한 해를 허용하는 intrinsic 분해에 특히 적합하다.
학습 중에 UNet 출력은 v-parameterization을 사용하여 latent 예측으로 변환된다.
\[\begin{equation} \hat{\textbf{z}}_0 = \sqrt{\vphantom{1} \bar{\alpha}_T} \textbf{z}_T - \sqrt{1 - \bar{\alpha}_T} \hat{\textbf{v}}_\theta \end{equation}\](\(\hat{\textbf{z}}_0\)는 예측된 denoised latent, \(\textbf{z}_T\)는 noise가 추가된 입력, \(\hat{\textbf{v}}_\theta\)는 diffusion Unet의 출력)
이 예측된 latent는 이후 VAE 디코더를 통해 원래 공간으로 디코딩되어 실제 공간과 비교된다.
Task-specific loss functions
일반적인 예측의 경우 추정된 normal $\hat{\textbf{n}}$과 GT normal $\textbf{n}$ 사이의 각도 차이에 따른 loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textbf{n} = \frac{1}{N} \sum_i \textrm{arccos} \frac{\textbf{n}_i \cdot \hat{\textbf{n}}_i}{\| \textbf{n}_i \| \cdot \| \hat{\textbf{n}}_i \|} \end{equation}\]($N$은 전체 픽셀 수)
Irradiance 예측을 위해 affine-invariant loss function을 적용한다.
\[\begin{equation} \mathcal{L}_\textbf{E} = \vert \textbf{E} - \textbf{S} \hat{\textbf{E}} - \textbf{T} \vert_F^2 \end{equation}\]($\textbf{E}$는 GT irradiance map, $\hat{\textbf{E}}$는 예측된 irradiance map, $\textbf{S}$는 scale에 해당하는 대각 행렬, $\textbf{T}$는 채널별 shift 값)
파라미터는 각 채널에 대해 least-square fitting을 통해 독립적으로 결정되며, albedo와 irradiance로 이미지를 분해하는 데 따른 모호성을 수용한다.
RGB, albedo, roughness, metallic 등 다른 모든 map의 경우 MSE를 활용한다.
\[\begin{equation} \mathcal{L}_\textrm{\{a, r, m, \textrm{RGB}\}} = \frac{1}{N} \sum_i \vert \textbf{y}_i - \hat{\textbf{y}}_i \vert_F^2 \end{equation}\]Inverse rendering의 경우, 최종 loss는 이러한 개별 intrinsic map별 loss function의 합으로 계산된다. Forward rendering의 경우, loss는 \(\mathcal{L}_\textrm{RGB}\)이다.
2. Cycle Training
초기 fine-tuning 과정을 거쳐 single-step inference가 가능한 두 개의 상호 보완적인 diffusion model을 얻는다. 하나는 inverse rendering (RGB→X)을 위한 것이고 다른 하나는 forward rendering (X→RGB)을 위한 것이다. 그러나 이 모델들은 독립적으로 학습되기 때문에 순차적으로 적용 시 사이클 일관성에 결함이 있다. 이러한 한계를 해결하기 위해, 저자들은 CycleGAN과 유사한 사이클 일관성 학습 방식을 구현하였다.
입력 쌍 $(\textbf{X}, \textbf{I})$가 주어졌을 때, 먼저 사전 학습된 모델을 사용하여 \((\hat{\textbf{I}}, \hat{\textbf{X}})\)을 생성한다. 이후, 생성된 출력을 두 번째 inference 단계의 입력으로 사용하여 \((\tilde{\textbf{X}}, \tilde{\textbf{I}})\)를 생성한다. 이를 통해 사이클 일관성 loss를 정의할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{cycle} = \mathcal{L}_{\textbf{X} \rightarrow \hat{\textbf{I}} \rightarrow \hat{\textbf{X}}} + \mathcal{L}_{\textbf{I} \rightarrow \hat{\textbf{X}} \rightarrow \hat{\textbf{I}}} = \vert \textbf{X} - \tilde{\textbf{X}} \vert^2 + \vert \textbf{I} - \tilde{\textbf{I}} \vert^2 \end{equation}\]이 추가적인 fine-tuning 단계에서는 task-specific loss와 사이클 일관성 loss를 조합하여 두 모델을 공동으로 최적화시킨다. 이 접근법은 inverse rendering과 forward rendering 프로세스 간의 양방향 일관성을 향상시키고, 사이클 구조를 활용하여 forward rendering 모델 학습 시 데이터 부족 문제를 완화한다.
3. Video Inference
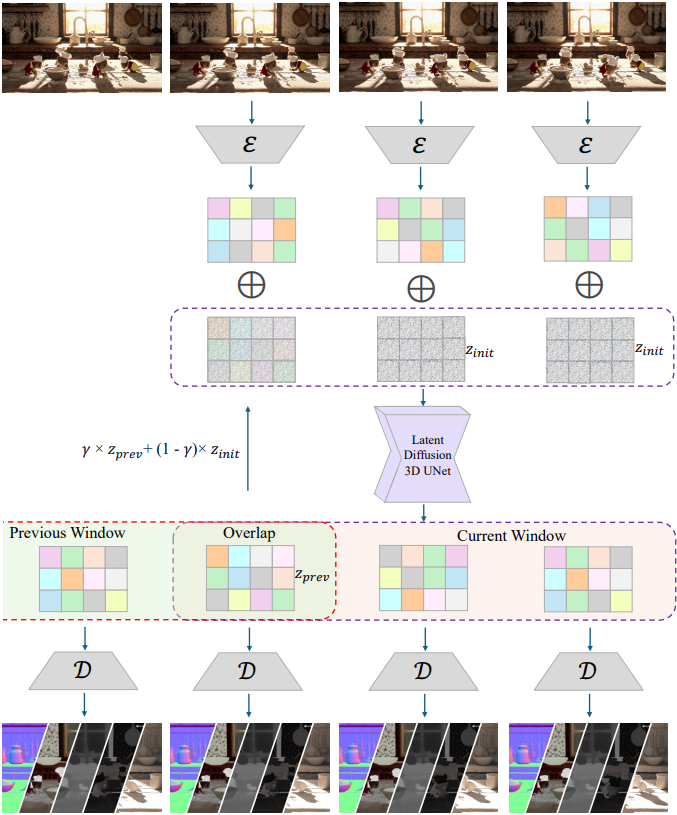
동영상의 경우, 일반적인 video diffusion model을 학습시키는 것은 자연스러운 과정이지만, 일반적으로 훨씬 더 큰 데이터셋, 더 높은 연산 비용, 그리고 더 긴 학습 시간이 필요하다. 따라서 본 논문에서는 fine-tuning 없이 사전 학습된 2D diffusion model을 활용하여 동영상 생성 기능을 구현했다.
단순하게 2D diffusion model을 프레임 단위로 적용하면 프레임 간 의존성(dependency)이 부족하여 시간적 불연속성과 깜빡임 아티팩트가 발생하는 경우가 많다. 따라서 본 논문에서는 시간 정보를 효과적으로 처리할 수 있도록 2D 아키텍처를 확장했다. 저자들은 VDM, FLATTEN과 같은 기존 연구에서 영감을 얻어, 3$\times$3 커널을 1$\times$3$\times$3 커널로 대체하여 2D convolution layer를 pseudo-3D 아키텍처로 확장했다. 또한, 여러 프레임의 패치를 flatten하고, 공간 및 시간 차원 모두에 걸쳐 attention 메커니즘을 적용하여 생성된 동영상의 일관성을 향상시켰다.
그러나 전체 동영상을 입력으로 직접 처리하고 한 번의 forward pass로 전체 동영상 출력을 생성하는 것은 GPU 메모리 제약으로 인해 상당한 어려움을 야기한다. 이러한 한계를 극복하기 위해, 저자들은 세그먼트 단위로 동영상을 처리하는 반복적 inference 전략을 채택했다. 구체적으로, 동영상을 고정된 stride를 갖는 겹치는 window로 나누고, 각 세그먼트는 pseudo-3D diffusion model을 사용하여 독립적으로 처리한다.
저자들은 세그먼트 간 시간적 일관성을 유지하기 위해 Lotus에서 영감을 받은 테크닉을 사용하였다. 이전 window에서 중첩 영역에 대하여 예측된 latent \(\textbf{z}_\textrm{prev}\)를 가져와, 미리 정의된 스케일 $\gamma$를 사용하여 노이즈 \(\boldsymbol{\epsilon}\)에 가중치를 적용한다. 결과는 다음 iteration에서 중첩 영역의 초기 latent 입력으로 사용된다.
\[\begin{equation} \textbf{z}_\textrm{init} = \gamma \cdot \textbf{z}_\textrm{prev} + (1 - \gamma) \cdot \boldsymbol{\epsilon} \end{equation}\]저자들은 경험적으로 $\gamma = 0.1$로 설정했다. 이 접근 방식은 계산 효율성을 유지하면서 동영상 세그먼트 간의 원활한 전환을 보장한다.
Experiment
1. Inverse Rendering Results
다음은 albedo 추정 성능을 비교한 결과이다.


다음은 normal 추정 성능을 비교한 결과이다.

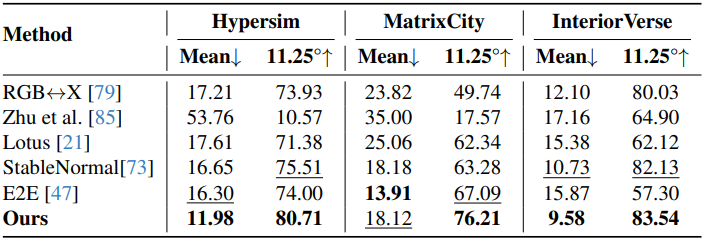
다음은 irradiance 추정 성능을 비교한 결과이다.

다음은 roughness와 metallic 추정 성능을 비교한 결과이다.

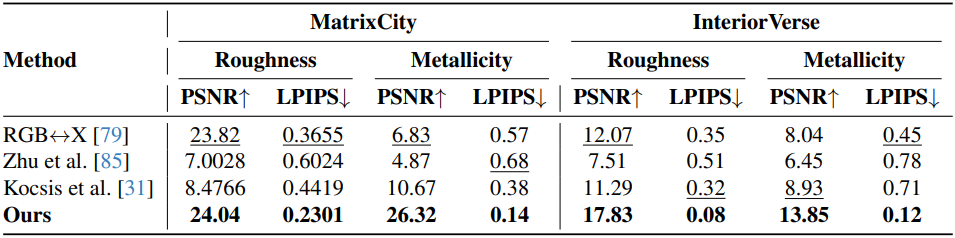
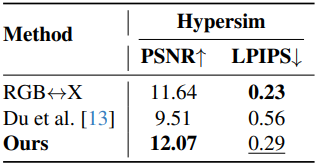
2. Forward Rendering Results
다음은 RGB↔X와 forward rendering 성능을 비교한 결과이다.
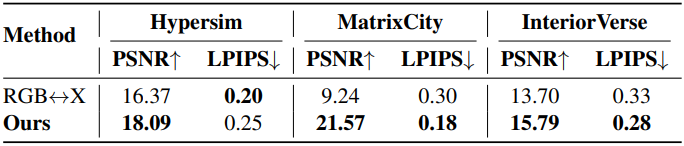
다음은 동영상 inference의 예시들이다.

3. Ablation Study on Cycle Training
다음은 RGB↔X와 실제 야외 이미지에 대하여 비교한 예시이다.

다음은 사이클 학습에 대한 ablation study 결과이다.

다음은 사이클 학습 시 현실 이미지 사용에 대한 ablation study 결과이다.

다음은 사이클 학습 시 E2E loss 사용에 대한 ablation study 결과이다.

Limitations
학습 데이터의 질과 양이 여전히 부족하다. 현재 공개된 데이터셋은 신뢰할 수 없는 intrinsic map을 포함하는 경우가 많고, 정확한 조명 정보가 부족하여 모델의 잠재력을 제한한다.