[논문리뷰] DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models
CVPR 2025. [Paper] [Page]
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, Zian Wang
NVIDIA | University of Toronto | Vector Institute | University of Illinois Urbana-Champaign
30 Jan 2025
Introduction
Physically-based rendering (PBR)과 inverse rendering은 일반적으로 별도로 고려되지만, 본 논문은 이를 함께 고려하는 것을 제안하였다. 저자들은 PBR에 대한 명확한 이해 없이 간단한 텍스트 프롬프트에서 사실적인 이미지를 렌더링하는 대규모 생성 모델의 성공에서 영감을 얻었다. 이러한 모델은 방대한 양의 데이터에서 실제 이미지의 분포를 학습하여 복잡한 조명 효과를 암시적으로 포착한다.
본 논문은 video diffusion model의 강력한 prior를 활용하여 그림자와 반사와 같은 light transport 시뮬레이션을 합성할 수 있는 범용적인 뉴럴 렌더링 엔진인 DiffusionRenderer를 제안하였다. DiffusionRenderer는 입력 geometry, material buffer, environment map에 따라 path-traced shading을 근사하는 역할을 한다. DiffusionRenderer는 실제 이미지의 분포를 고수하는 동시에 컨디셔닝 신호에 충실하도록 설계되었다. 결과적으로 모델이 입력 데이터의 불완전성을 처리하는 방법을 배우면서 정확한 장면 표현과 설명이 필요 없게 된다.
이러한 모델을 학습시키려면 일정량의 고품질의 다양한 데이터가 필요하며, robustness를 보장하기 위해 잡음이 있는 데이터가 필요하다. 따라서 먼저 inverse renderer, 즉 입력 RGB 동영상을 내재적 속성에 매핑하는 video diffusion model을 학습시킨다. Inverse renderer는 합성 데이터로만 학습되었지만 실제 시나리오에 robust하게 일반화된다. 그런 다음, 이를 사용하여 다양한 실제 동영상에 대한 pseudo-label을 생성한다. Pseudo-label이 생긴 실제 데이터와 합성 데이터를 결합하여 forward renderer를 학습시킨다.
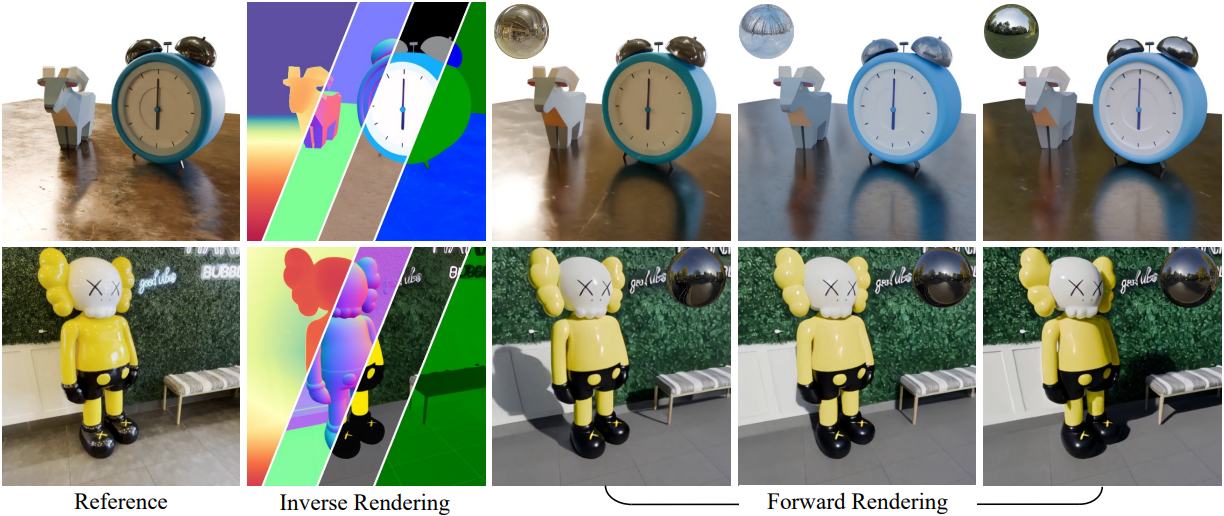
DiffusionRenderer는 SOTA 방법을 능가하며, 다양한 장면에서 이미지와 동영상을 relighting하고 명시적인 path tracing이나 3D 장면 표현 없이 일관된 그림자와 반사를 합성할 수 있다. DiffusionRenderer는 단일 동영상 입력만으로 모든 장면을 relighting할 수 있으며, material 편집이나 사실적인 물체 삽입과 같은 편집을 위한 기본 도구를 제공한다.
Method
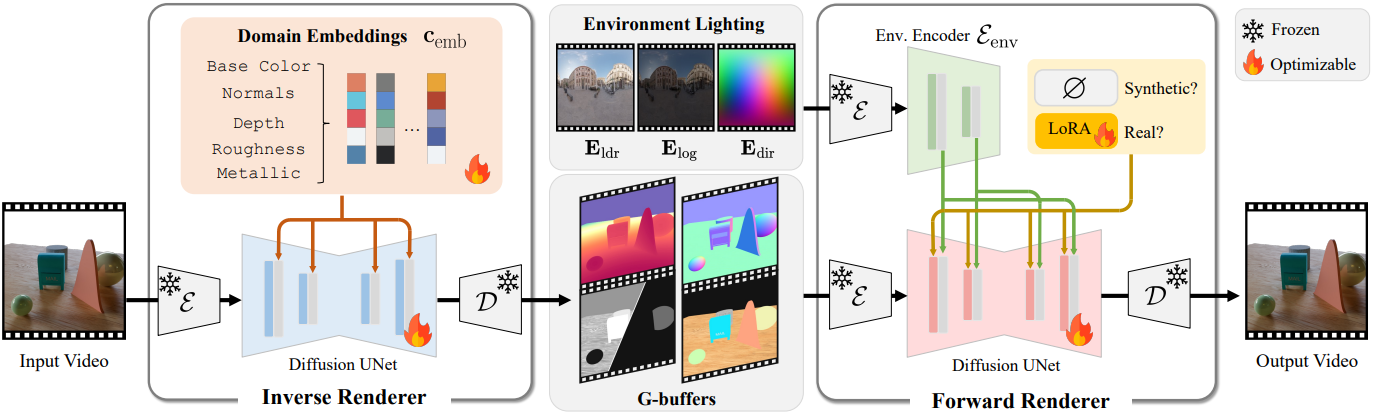
DiffusionRenderer는 neural forward rendering과 neural inverse rendering을 위해 설계된 두 개의 video diffusion model로 구성된 통합 프레임워크이다.
- Neural forward renderer: Physically-based rendering (PBR)을 근사화하여 G-buffer와 조명을 사실적인 동영상으로 변환
- Neural inverse renderer: 입력 동영상에서 geometry 및 material buffer를 재구성
1. Neural Forward Rendering
저자들은 neural forward rendering을 조건부 생성 task로 공식화하여 geometry, material, 조명을 조건으로 사실적인 이미지를 생성하였다. 데이터 중심 방식으로 light transport 시뮬레이션을 근사하기 때문에, 모델은 3D 형상이나 명시적인 path tracing이 필요하지 않으므로 실제 애플리케이션의 제약이 줄어든다.
Geometry와 material 조건
Deferred shading 기반 렌더링 시스템의 G-buffers와 유사하게, 픽셀당 장면 속성 맵을 사용하여 장면 geometry와 material을 표현한다. Geometry의 경우, 카메라 공간에서의 표면 normal $\textbf{n} \in \mathbb{R}^{F \times H \times W \times 3}$과 $[-1, 1]$로 정규화된 상대적 깊이 $\textbf{d} \in \mathbb{R}^{F \times H \times W \times 1}$을 사용하여 표현된다. Material의 경우, Disney BRDF를 따라 base color $\textbf{a} \in \mathbb{R}^{F \times H \times W \times 3}$, roughness $\textbf{r} \in \mathbb{R}^{F \times H \times W \times 1}$, metallic $\textbf{m} \in \mathbb{R}^{F \times H \times W \times 1}$을 사용한다.
조명 조건
조명은 구면 위의 모든 방향에서 조명 강도를 포착하는 파노라마 이미지인 environment map \(\textbf{E} \in \mathbb{R}^{F \times H_\textrm{env} \times W_\textrm{env} \times 3}\)으로 표현된다. 이러한 environment map은 HDR로 인코딩되는 반면, 일반적인 latent diffusion model에 사용되는 VAE는 [-1, 1] 사이의 픽셀 값에 맞게 설계되었다.
이러한 불일치를 해결하기 위해, 먼저 Reinhard tone mapping을 적용하여 HDR environment map을 LDR 이미지 \(\textbf{E}_\textrm{ldr}\)로 변환한다. 특히 intensity 피크가 있는 광원의 경우 HDR 값을 보다 효과적으로 표현하기 위해 \(\textbf{E}_\textrm{log} = \textrm{log}(\textbf{E}+1)/E_\textrm{max}\)를 계산한다. 또한 방향 인코딩 이미지 \(\textbf{E}_\textrm{dir} \in \mathbb{R}^{F \times H_\textrm{env} \times W_\textrm{env} \times 3}\)도 계산한다. \(\textbf{E}_\textrm{dir}\)에서 각 픽셀은 카메라 좌표계에서 방향을 나타내는 단위 벡터로 표현된다.
모델에서 사용되는 조명 인코딩은 3개의 파노라마 이미지 \(\{\textbf{E}_\textrm{ldr}, \textbf{E}_\textrm{log}, \textbf{E}_\textrm{dir}\}\)로 구성된다.
모델 아키텍처
본 논문의 모델은 image-to-video diffusion model인 Stable Video Diffusion을 기반으로 하며, VAE 인코더-디코더 쌍 \(\{\mathcal{E}, \mathcal{D}\}\)와 UNet 기반 denoiser \(f_\theta\)를 핵심 아키텍처로 한다. VAE 인코더 $\mathcal{E}$를 사용하여 \(\{\textbf{n}, \textbf{d}, \textbf{a}, \textbf{r}, \textbf{m}\}\)의 각 G-buffer를 별도로 latent space로 인코딩하고 이를 concat하여 픽셀 정렬된 장면 속성 latent map
\[\begin{equation} \textbf{g} = \{\mathcal{E}(\textbf{n}), \mathcal{E}(\textbf{d}), \mathcal{E}(\textbf{a}), \mathcal{E}(\textbf{r}), \mathcal{E}(\textbf{m})\} \in \mathbb{R}^{F \times h \times w \times 20} \end{equation}\]를 생성한다.
Environment map은 일반적으로 equirectangular projection이며 생성된 이미지와 픽셀이 정렬되지 않아 추가 고려가 필요하다. 저자들은 원래 텍스트/이미지 CLIP feature에서 작동하는 cross-attention layer를 가져와 조명 조건에 맞게 재활용하였다. Environment map의 공간적 디테일을 보존하기 위해 조건 신호를 다중 해상도 feature map들로 일반화한다.
구체적으로, 먼저 VAE 인코더 $\mathcal{E}$를 통해 environment map 정보를 전달하여
\[\begin{equation} \textbf{h}_\textbf{E} = \{ \mathcal{E} (\textbf{E}_\textrm{ldr}), \mathcal{E} (\textbf{E}_\textrm{log}), \mathcal{E} (\textbf{E}_\textrm{dir}) \} \in \mathbb{R}^{F \times h_\textrm{env} \times w_\textrm{env} \times 12} \end{equation}\]를 얻는다. 또한 environment map 인코더 \(\mathcal{E}_\textrm{env}\)를 사용하여 \(\textbf{h}_\textbf{E}\)를 추가로 처리한다. \(\mathcal{E}_\textrm{env}\)는 attention과 temporal layer가 제거된 diffusion UNet의 인코더 부분이며, $K$개의 레벨로 구성된 다중 해상도 feature를 다운샘플링하고 조명 조건으로 추출하기 위한 여러 개의 convolutional layer가 포함되어 있다.
\[\begin{equation} \textbf{c}_\textrm{env} = \{ \textbf{h}_\textrm{env}^i \}_{i=1}^K = \mathcal{E}_\textrm{env} (\textbf{h}_\textbf{E}) \end{equation}\]결과적으로, diffusion UNet \(\textbf{f}_\theta\)는 noise가 추가된 latent \(\textbf{z}_\tau\)와 G-buffer latent $\textbf{g}$를 입력으로 받는다. 각 UNet 레벨 $k$에서, diffusion UNet은 해당 레벨에서 latent environment map feature \(\textbf{h}_\textrm{env}^k\)를 query하고 key와 value를 기반으로 집계한다. 여러 레벨의 self-attention 및 cross-attention layer를 통해 diffusion model은 조명으로 G-buffer를 shading하는 방법을 학습할 수 있는 용량을 얻는다.
Inference하는 동안, diffusion target은 \(\textbf{f}_\theta (\textbf{z}_\tau; \textbf{g}, \textbf{c}_\textrm{env}, \tau)\)로 계산되어 반복적 denoising을 통해 사실적인 이미지를 생성할 수 있다.
2. Neural Inverse Rendering
Forward rendering과 유사하게, inverse rendering을 조건 생성 task로 공식화한다. 입력 동영상 $\textbf{I}$가 조건으로 주어지면, inverse renderer는 forward renderer가 사용하는 G-buffer \(\{\textbf{n}, \textbf{d}, \textbf{a}, \textbf{r}, \textbf{m}\}\)을 추정한다.
모델 아키텍처
입력 동영상 $\textbf{I}$는 latent space에 $\textbf{z} = \mathcal{E}(\textbf{I})$로 인코딩되고, noise가 추가된 G-buffer latent $\textbf{g}_\tau$와 concat된다.
\[\begin{equation} \textbf{g}_\tau = \alpha_\tau \textbf{g}_0 + \sigma_\tau \epsilon \end{equation}\]입력 동영상이 주어지면 inverse renderer는 하나의 모델을 사용하여 5가지 속성 \(\{\textbf{n}, \textbf{d}, \textbf{a}, \textbf{r}, \textbf{m}\}\)을 모두 생성한다. 고품질 생성을 유지하고 사전 학습된 지식을 최대한 활용하기 위해, 모든 속성을 한 번에 생성하는 대신 전용 pass에서 각 속성을 생성한다.
기존 방법들을 따라, 도메인 임베딩을 사용하여 모델에 어떤 속성을 생성해야 하는지 표시한다. 구체적으로, 최적화 가능한 도메인 임베딩 \(\textbf{c}_\textrm{emb} \in \mathbb{R}^{K_\textrm{emb} \times C_\textrm{emb}}\)을 도입한다. 여기서 \(\textrm{K}_\textrm{emb} = 5\)는 buffer 수이고 \(\textbf{C}_\textrm{emb}\)은 임베딩 벡터의 차원이다. 이미지 CLIP feature를 사용하는 cross-attention layer를 재활용하여 도메인 임베딩을 얻는다. $P$로 인덱싱된 속성을 추정할 때, 임베딩 \(\mathbb{c}_\textrm{emb}^P\)를 조건으로 제공하고 \(\textbf{f}_\theta (\textbf{g}_\tau^P; \textbf{z}, \textbf{c}_\textrm{emb}^P, \tau)\)로 diffusion target을 예측한다.
3. Data Strategy
합성 데이터 선별
모델을 학습시키려면 geometry, material, 조명 정보에 대한 쌍을 이룬 실제 데이터가 있는 고품질 동영상 데이터가 필요하다. 구체적으로, 각 동영상 데이터 샘플에는 RGB, base color, roughness, metallic, normal, depth, environment map의 쌍을 이룬 프레임이 포함되어야 한다.
\[\begin{equation} \{\textbf{I}, \textbf{a}, \textbf{r}, \textbf{m}, \textbf{n}, \textbf{d}, \textbf{E}\} \end{equation}\]이러한 buffer는 일반적으로 합성 데이터에서만 사용할 수 있으며, 대부분의 기존 데이터셋에는 이러한 buffer의 일부만 포함된다.
데이터 부족을 해결하기 위해, 저자들은 다양하고 복잡한 조명 효과를 포괄하는 방대한 양의 고품질 데이터를 생성하는 합성 데이터 생성 워크플로를 설계했다. 먼저, 3D 에셋, PBR material, HDRI environment map 컬렉션을 선별하는 것으로 시작한다.
- Objaverse LVIS split의 3D 에셋 36,500개
- 고품질 PBR material map 4,260개
- HDR environment map 766개
각 장면에서 무작위로 선택된 PBR material이 있는 평면을 배치하고, 최대 3개의 3D 물체를 샘플링하여 평면에 배치한다. 물체가 교차하는 것을 방지하기 위해 충돌 감지를 수행한다. 또한 복잡한 조명 효과를 포함하기 위해 무작위 모양과 material의 큐브, 구, 원통을 배치한다. 무작위로 선택된 HDR environment map이 장면을 비춘다. 카메라 궤도, 카메라 진동, 조명 회전, 객체 회전 및 변환을 포함한 카메라 모션을 생성한다.
OptiX 기반의 커스텀 path tracer를 사용하여 동영상을 렌더링한다. 결과적으로 GT G-buffer와 environment map을 가진 총 15만 개의 동영상이 생성되었으며, 동영상은 24개의 프레임, 512$\times$512 해상도이다. 이 데이터셋은 forward renderer와 inverse renderer를 모두 학습시키는 데 사용할 수 있다.
Real world auto-labeling
합성 데이터는 정확한 학습 신호를 제공하며, 강력한 이미지 diffusion model과 결합하면 inverse rendering에서 인상적인 일반화를 보여준다. 그러나 forward rendering 모델을 학습하는 경우, 합성 데이터만으로는 충분하지 않다. Forward renderer의 출력은 RGB 동영상이므로 합성 렌더링에 대해서만 학습하면 모델이 합성 데이터의 스타일로 편향된다. 즉, forward rendering의 경우 inverse rendering보다 더 중요한 도메인 차이가 발생한다.
실제 데이터를 수집하는 것은 복잡하고 비실용적이다. Inverse renderer가 실제 동영상으로 일반화된다는 관찰을 바탕으로, inverse renderer를 실제 동영상을 자동으로 레이블링하는 데 사용한다. 구체적으로, 다양한 환경을 특징으로 하는 대규모 실제 동영상 데이터셋인 DL3DV-10K 데이터셋을 사용한다. Inverse renderer를 사용하여 G-buffer 레이블을 생성하고, DiffusionLight을 사용하여 environment map을 추정한다. 각 동영상은 15개의 세그먼트로 나뉘며, geometry, material, 조명 속성이 자동으로 레이블링된 약 15만 개의 실제 동영상 샘플이 생성된다.
4. Training pipeline
Neural inverse renderer
먼저 합성 동영상 데이터셋인 InteriorVerse와 합성 이미지 데이터셋인 HyperSim의 조합으로 inverse renderer를 학습시킨다. HyperSim의 경우 이미지를 단일 프레임 동영상로 처리한다. 각 데이터 샘플은 동영상 $\textbf{I}$, 속성 인덱스 $P$, 장면 속성 맵 $\textbf{s}^P$로 구성된다. 장면 속성의 latent \(\textbf{g}_0^P = \mathcal{E}(\textbf{s}^P)\)에 noise가 추가되어 \(\textbf{g}_\tau^P\)가 생성된다. 모델은 다음 loss로 학습된다.
\[\begin{equation} \mathcal{L} (\theta, \textbf{c}_\textrm{emb}) = \| \textbf{f}_\theta (\textbf{g}_\tau^P; \textbf{z}, \textbf{c}_\textrm{emb}^P, \tau) - \textbf{g}_0^P \|_2^2 \end{equation}\]인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$를 고정한 채로 diffusion model 파라미터 $\theta$와 도메인 임베딩 \(\textbf{c}_\textrm{emb}\)를 fine-tuning한다. 학습되고 나면, inverse renderer는 실제 동영상의 레이블을 자동으로 생성하여 forward renderer에 대한 학습 데이터를 생성하는 데 사용된다.
Environment map encoder pre-training
Latent diffusion model의 접근 방식에 따라, 오토인코더와 유사하게 environment map에서 L2 reconstruction loss를 사용하여 environment map 인코더 및 디코더 \(\mathcal{E}_\textrm{env}\)와 \(\mathcal{D}_\textrm{env}\)를 사전 학습시킨다. 디코더 아키텍처는 업샘플링 레이어들로 구성된 UNet 디코더를 기반으로 한다. 학습 후, 디코더 \(\mathcal{D}_\textrm{env}\)를 버리고, forward renderer를 학습시키는 동안 인코더 \(\mathcal{E}_\textrm{env}\)를 고정하여 사용한다.
Neural forward renderer
합성 동영상 데이터셋과 pseudo-label이 붙은 실제 데이터의 조합에 대해 forward renderer를 학습시키고, G-buffer, 조명, RGB 동영상을 사용하여 학습시킨다. 실제 데이터는 충분한 품질이지만 여전히 부정확할 수 있다. 합성 데이터와 실제 데이터 간의 불일치를 해결하기 위해 실제 데이터로 학습시키는 동안 추가로 LoRA $\Delta \theta$를 도입한다.
RGB 동영상 $\textbf{I}$에 대한 latent \(\textbf{z}_0 = \mathcal{E}(\textbf{I})\)에 noise가 추가되어 \(\textbf{z}_\tau\)가 생성된다. 학습 loss는 다음과 같다.
\[\begin{aligned} \mathcal{L} (\theta, \Delta \theta) &= \| \textbf{f}_\theta (\textbf{z}_\tau^\textrm{synth}; \textbf{g}^\textrm{synth}, \textbf{c}_\textrm{env}^\textrm{synth}, \tau) - \textbf{z}_0^\textrm{synth} \|_2^2 \\ &+ \| \textbf{f}_{\theta + \Delta \theta} (\textbf{z}_\tau^\textrm{real}; \textbf{g}^\textrm{real}, \textbf{c}_\textrm{env}^\textrm{real}, \tau) - \textbf{z}_0^\textrm{real} \|_2^2 \end{aligned}\]5. Editing Applications
제안된 프레임워크는 inverse rendering과 forward rendering을 위한 기본 솔루션을 제공하기 때문에, inverse rendering, G-buffer 및 조명 편집, forward rendering의 3단계 프로세스를 통해 사실적인 이미지 편집이 가능하다.
예를 들어 relighting의 경우, inverse renderer에 동영상 $\textbf{I}$를 입력하면 G-buffer를 추정한다.
\[\begin{equation} \{ \hat{\textbf{n}}, \hat{\textbf{d}}, \hat{\textbf{a}}, \hat{\textbf{r}}, \hat{\textbf{m}} \} = \textrm{InverseRenderer}(\textbf{I}) \end{equation}\]사용자가 지정한 타겟 environment map \(\textbf{E}_\textrm{tgt}\)를 사용하면 렌더링 모델이 relighting된 동영상을 생성한다.
\[\begin{equation} \hat{\textbf{I}}_\textrm{tgt} = \textrm{ForwardRenderer}(\{ \hat{\textbf{n}}, \hat{\textbf{d}}, \hat{\textbf{a}}, \hat{\textbf{r}}, \hat{\textbf{m}}, \textbf{E}_\textrm{tgt} \}) \end{equation}\]마찬가지로, G-buffer를 편집하고 동영상을 렌더링하면 material 편집과 가상 물체 삽입이 가능해진다.
Experiments
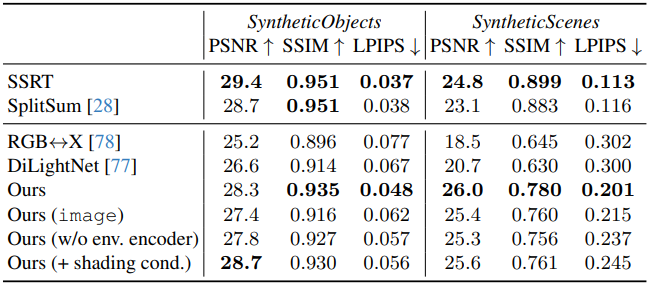
1. Evaluation of Forward Rendering
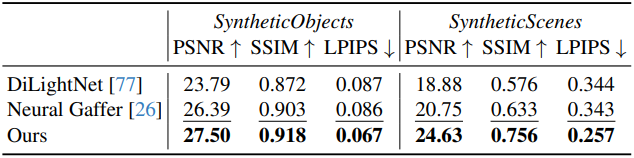
다음은 다른 방법들과 forward rendering을 비교한 결과이다.

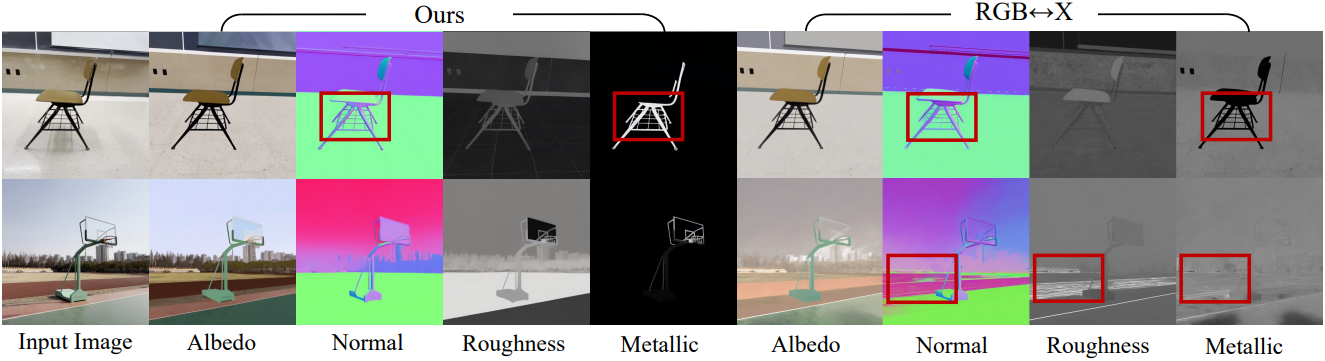
2. Evaluation of Inverse Rendering
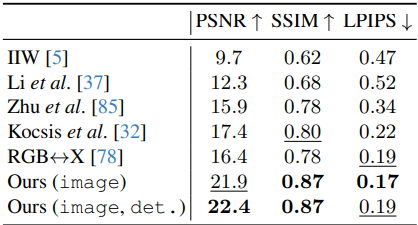
다음은 DL3DV-10K 데이터셋에서 RGB↔X와 inverse rendering 결과를 비교한 것이다.
다음은 SyntheticScenes 동영상 데이터셋에서 inverse rendering 결과를 비교한 표이다.
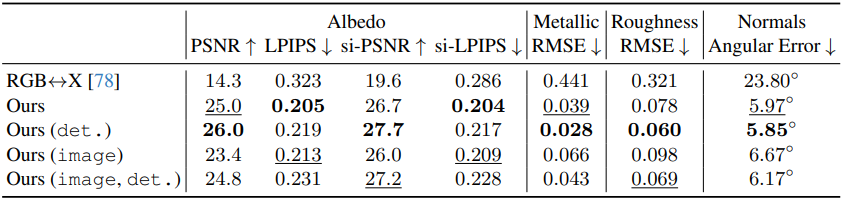
다음은 InteriorVerse 데이터셋에서 다른 방법들과 albedo 추정 결과를 비교한 표이다.
3. Evaluation of Relighting
다음은 다른 방법들과 relighting을 비교한 결과이다.

다음은 relighting에 대한 ablation 결과이다.

4. Applications
다음은 (위) material 편집과 (아래) 물체 삽입의 예시들이다.
