[논문리뷰] Mask-Free Video Instance Segmentation (MaskFreeVIS)
CVPR 2023. [Paper] [Github]
Lei Ke, Martin Danelljan, Henghui Ding, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu
ETH Zurich | HKUST
28 Mar 2023

Introduction
Video Instance Segmentation (VIS)은 지정된 카테고리 집합에서 동영상의 모든 객체를 공동으로 감지, 추적, 분할해야 한다. 이 어려운 task를 수행하기 위해 SOTA VIS 모델은 VIS 데이터셋의 완전한 동영상으로 학습된다. 그러나 동영상 주석은 특히 객체 마스크 레이블과 관련하여 비용이 많이 든다. 대략적인 다각형 기반 마스크 주석도 동영상 bounding box에 주석을 추가하는 것보다 몇 배 더 느리다. 값비싼 마스크 주석으로 인해 기존 VIS 벤치마크의 확장이 어려워지고 적용되는 객체 카테고리 수가 제한된다. 이는 유난히 데이터를 많이 사용하는 경향이 있는 최신 transformer 기반 VIS 모델의 경우 특히 문제가 된다. 따라서 저자들은 마스크가 없는 설정에서 weakly supervised VIS의 문제를 연구하여 완전한 마스크 주석의 필요성을 다시 검토하였다.
Box-supervised instance segmentation 모델이 존재하지만 이미지용으로 디자인되었다. 이러한 weakly supervise되는 단일 이미지 방법은 마스크 예측을 학습할 때 시간적 단서를 활용하지 않으므로 동영상에 직접 적용하면 정확도가 낮아진다. Weakly supervised learning의 소스로서 동영상에는 장면에 대한 훨씬 더 풍부한 정보가 포함되어 있다. 특히 동영상은 시간적 마스크 일관성 제약 조건을 준수한다. 즉, 여러 프레임에 걸쳐 동일한 객체에 해당하는 영역은 동일한 마스크 레이블을 가져야 한다. 본 논문에서는 VIS의 마스크 없는 학습을 위해 이 중요한 제약 조건을 활용하였다.
본 논문은 마스크 주석이 없는 고성능 VIS를 위해 MaskFreeVIS를 제안한다. 시간적 마스크 일관성을 활용하기 위해 Temporal KNN-patch Loss (TK-Loss)를 도입하였다. 동일한 동영상 개체에 해당하는 영역을 찾기 위해 TK-Loss는 먼저 패치별 매칭을 통해 프레임 전체에 걸쳐 대응성을 구축한다. 각 대상 패치에 대해 매칭 점수가 충분히 높은 인접 프레임의 상위 $K$개의 매칭 항목만 선택된다. 그런 다음 마스크 일관성을 높이기 위해 발견된 모든 매칭 항목에 시간적 일관성 loss가 적용된다. 특히, 목적 함수는 $1:K$로 매칭된 영역을 촉진하여 동일한 마스크 확률에 도달할 뿐만 아니라 엔트로피 최소화를 통해 마스크 예측을 확실한 전경 또는 배경 예측에 적용한다. 일대일 매칭을 가정하는 flow 기반 모델과 달리 본 논문의 접근 방식은 견고하고 유연한 $1:K$ 대응을 구축하며, 추가 모델 파라미터나 inference 비용을 도입하지 않는다.
TK-Loss는 아키텍처 수정이 필요 없이 기존 VIS 방법에 쉽게 통합된다. 학습 중에 TK-Loss는 동영상 마스크 생성을 supervise할 때 기존 동영상 마스크 loss를 대체한다. 동영상 클립을 통해 시간적 일관성을 더욱 강화하기 위해 TK-Loss는 조밀한 프레임별 연결을 사용하는 대신 순환 방식으로 사용된다. 이는 무시할 수 있는 성능 저하로 메모리 비용을 크게 줄인다.

Method
본 논문은 동영상이나 이미지 마스크 레이블을 사용하지 않고 VIS를 해결하기 위하여 MaskFreeVIS를 제안하였다. 본 논문의 접근 방식은 일반적이며 Mask2Former나 SeqFormer와 같은 SOTA VIS 방법을 학습시키는 데 직접 적용할 수 있다.
1. MaskFreeVIS
Temporal Mask Consistency
이미지는 장면의 하나의 스냅샷을 구성하는 반면, 동영상은 시간에 따라 변하는 여러 스냅샷을 제공한다. 그리하여 영상은 장면의 연속적인 변화를 묘사한다. 물체와 배경이 움직이고, 변형되고, 가려지고, 조명의 변화, 모션 블러, 노이즈 등이 점진적인 변형을 통해 밀접하게 연관된 일련의 서로 다른 이미지로 이어진다.
물체나 배경에 속하는 장면의 작은 영역을 생각해 보자. 이 영역의 projection에 해당하는 픽셀은 동일한 물리적 객체 또는 배경 영역에 속하므로 모든 프레임에서 동일한 마스크 예측을 가져야 한다. 그러나 앞서 언급한 영상의 동적인 변화는 상당한 모양 변화를 가져오며 자연스러운 형태의 data augmentation 역할을 한다. 동일한 객체 영역에 해당하는 픽셀이 시간적 변화 하에서 동일한 마스크 예측을 가져야 한다는 사실은 마스크 supervision에 사용할 수 있는 강력한 제약, 즉 시간적 마스크 일관성을 제공한다.
시간적 마스크 일관성 제약을 활용하는 데 어려움이 있는 이유는 동영상 프레임 간의 신뢰할 수 있는 대응을 설정하는 문제 때문이다. 물체는 종종 빠른 움직임, 변형 등을 겪어 상당한 모양 변화를 가져온다. 또한 장면의 영역이 가려지거나 한 프레임에서 다른 프레임으로 이미지 밖으로 이동할 수 있다. 그러한 경우에는 대응이 존재하지 않는다. 마지막으로, 동영상은 하늘과 땅과 같은 동질적인 영역에 의해 지배되는 경우가 많기 때문에 일대일 대응 설정에 오차가 발생하기 쉽고 심지어 잘못 정의되기 쉽다.
Optical flow로 알려진 후속 동영상 프레임 간의 조밀한 일대일 대응을 설정하는 문제는 오랫동안 인기 있는 연구 주제이다. 그러나 optical flow 추정을 통해 시간적 마스크 일관성을 강화하려고 시도할 때 두 가지 주요 문제에 직면한다.
- Optical flow의 일대일 가정은 가려짐, 동질 영역, 단일 가장자리와 같은 경우에는 적합하지 않으며, 대응이 존재하지 않거나, 정의되지 않거나, 모호하거나, 불분명하거나, 결정하기 매우 어렵다.
- SOTA optical flow 추정은 대규모 계산 및 메모리 요구 사항이 있는 크고 복잡한 심층망에 의존한다.
본 논문은 optical flow를 사용하는 대신 시간적 마스크 일관성 제약 조건을 효과적으로 적용하는 간단하고 효율적이며 파라미터가 없는 접근 방식을 설계하는 것을 목표로 하였다.
Temporal KNN-patch Loss
Temporal KNN-patch Loss (TK-Loss)는 프레임 전반에 걸쳐 간단하고 유연한 대응 추정을 기반으로 한다. Optical flow와 달리 공식을 일대일 대응으로 제한하지 않는다. 대신에 $1:K$ 대응을 확립한다. 여기에는 기존의 일대일 ($K = 1$)이 포함된다. 그러나 이를 통해 가려짐의 경우 존재하지 않는 대응 ($K = 0$), 동질 영역의 경우 일대다($K \ge 2$)의 경우도 처리할 수 있다.
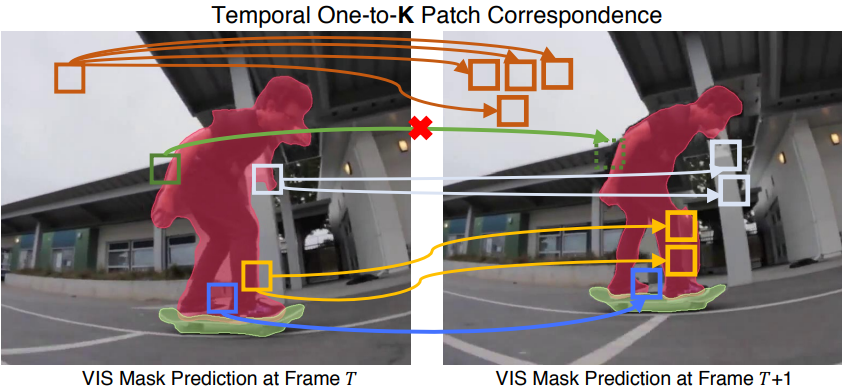
일치하는 항목이 여러 개 발견된 경우 위 그림과 같이 유사한 모양으로 인해 동일한 객체 또는 배경에 속하는 경우가 가장 많다. 이는 s더 조밀한 supervision을 통해 마스크 일관성 목적 함수에 더욱 도움이 된다. 이 접근 방식은 계산 오버헤드를 무시할 수 있고 학습 가능한 파라미터가 없어 구현이 간단하다. 본 논문의 접근 방식은 아래 그림과 같으며 4가지 주요 단계로 구성된다.
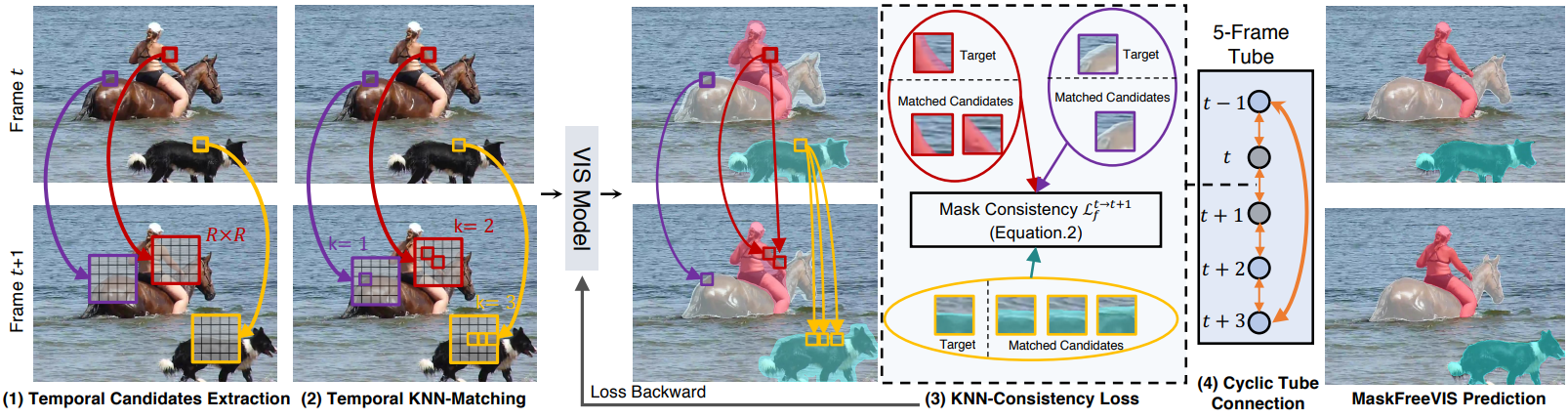
1) Patch Candidate Extraction: $X_p^t$를 프레임 $t$의 공간 위치 $p = (x, y)$에 중심을 둔 $N \times N$ 타겟 이미지 패치라 하자. 본 논문의 목표는 동일한 객체 영역을 나타내는 프레임 번호 $\hat{t}$에서 대응되는 위치 집합 \(S_p^{t \rightarrow \hat{t}} = \{\hat{p}_i\}_i\)를 찾는 것이다. 이를 위해 먼저 $| p − \hat{p} | \le R$이 되는 반경 $R$ 내에서 후보 위치 $\hat{p}$를 선택한다. 이러한 윈도우 패치 검색은 철저한 글로벌 검색을 피하기 위해 인접 프레임 간의 공간적 근접성을 활용한다. 빠른 구현을 위해 모든 타겟 이미지 패치 $X_p^t$에 대해 윈도우 검색이 병렬로 수행된다.
2) Temporal KNN-Matching: 간단한 거리 계산을 통해 후보 패치들을 매칭한다.
\[\begin{equation} d_{p \rightarrow \hat{p}}^{t \rightarrow \hat{t}} \| X_p^t - X_{\hat{p}}^{\hat{t}} \| \end{equation}\]저자들은 실험을 통해 $L_2$-norm이 가장 효과적인 패치 매칭 메트릭임을 알아냈다. 가장 작은 패치 거리 \(d_{p \rightarrow \hat{p}}^{t \rightarrow \hat{t}}\)와 일치하는 상위 $K$개를 선택한다. 마지막으로 최대 패치 거리 $D$를 \(d_{p \rightarrow \hat{p}}^{t \rightarrow \hat{t}} < D\)로 적용하여 신뢰도가 낮은 매칭 항목을 제거한다. 나머지 매칭 항목들은 각 위치 $p$에 대해 집합 $S_p^{t \rightarrow \hat{t}} = {\hat{p}_i}_i$을 형성한다.
3) Consistency loss: $M_p^t \in [0,1]$를 프레임 $t$의 위치 $p$에서 평가된 객체의 예측된 이진 인스턴스 마스크라 하자. 시간적 마스크 일관성 제약을 보장하기 위해 시공간적 지점 $(p, t)$와 $S_p^{t \rightarrow \hat{t}}$에서 추정된 해당 지점 사이의 일관되지 않은 마스크 예측에 페널티를 적용한다. 특히 다음 목적 함수를 사용한다.
\[\begin{equation} \mathcal{L}_f^{t \rightarrow \hat{t}} \frac{1}{HW} \sum_p \sum_{\hat{p}_i \in S_p^{t \rightarrow \hat{t}}} \mathcal{L}_\textrm{cons} (M_p^t, M_{\hat{p}_i}^{\hat{t}}) \\ \textrm{where} \; \mathcal{L}_\textrm{cons} (M_p^t, M_{\hat{p}}^{\hat{t}}) = -\log (M_p^t M_{\hat{p}}^{\hat{t}} + (1-M_p^t)(1-M_{\hat{p}}^{\hat{t}})) \end{equation}\]\(\mathcal{L}_\textrm{cons} (M_p^t, M_{\hat{p}}^{\hat{t}})\)은 두 예측이 모두 배경이나 전경을 정확하게 나타내는 경우에만 최소값 0을 얻는다. 따라서 목적 함수는 동일한 확률 값 \(M_p^t, M_{\hat{p}}^{\hat{t}}\)를 달성하기 위해 두 개의 마스크 예측을 촉진할 뿐만 아니라 특정 전경 또는 배경 예측을 수행한다.
4) Cyclic Tube Connection:
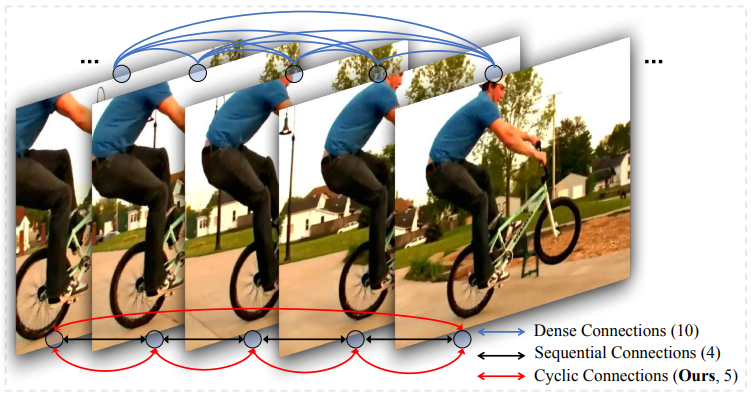
Temporal tube가 $T$ 프레임으로 구성되어 있다고 가정하자. 위 그림에서와 같이 순환 방식으로 전체 tube에 대한 시간적 loss를 계산한다. 시작 프레임은 끝 프레임에 연결되어 시간적으로 가장 먼 두 프레임에 걸쳐 직접적인 장기 마스크 일관성을 도입한다. 전체 tube에 대한 시간적 TK-Loss는 다음과 같다.
프레임 간의 조밀한 연결과 비교했을 때, 순환 loss는 성능이 유사하지만 메모리 사용량을 크게 줄인다.
2. Training MaskFreeVIS
Joint Spatio-temporal Regularization
MaskFreeVIS를 학습시키기 위해 시간적 마스크 일관성을 위한 TK Loss 외에도 기존의 공간적 weak segmentation loss들을 활용하여 프레임 내 일관성을 공동으로 적용한다.
공간적 일관성: 이미지 bounding box와 픽셀 색상에서 공간적 약한 supervision 신호를 탐색하기 위해 box projection loss \(\mathcal{L}_\textrm{proj}\)와 pairwise loss \(\mathcal{L}_\textrm{pair}\)를 활용하며, supervised mask learning loss를 대체한다. \(\mathcal{L}_\textrm{proj}\)는 객체 마스크의 projection $P^\prime$을 이미지의 $x$축과 $y$축에 적용하여 ground-truth 박스 마스크와 일치하도록 한다. $T$ 프레임이 있는 temporal tube의 경우 tube의 모든 예측 프레임 마스크를 다음과 같이 동시에 최적화한다.
\[\begin{equation} \mathcal{L}_\textrm{proj} = \sum_{t=1}^T \sum_{d \in \{x, y\}} D(P_d^\prime (M_p^t), P_d^\prime (M_b^t)) \end{equation}\]여기서 $D$는 dice loss이며, $P^\prime$은 $x$축과 $y$축에 대한 projection 함수이다. $M_p^t$와 $M_b^t$는 각각 프레임 $t$에서 예측된 인스턴스 마스크와 대응되는 ground-truth 박스 마스크이다. 여기서는 명확성을 위해 객체 인스턴스 인덱스를 생략했다.
반면에 pairwise loss \(\mathcal{L}_\textrm{pair}\)는 단일 프레임의 이웃 픽셀을 공간적으로 제한한다. 색상 유사도가 $\sigma_\textrm{pixel}$인 위치 $p_i^\prime$와 $p_j^\prime$의 픽셀에 대해 다음과 같이 예측 마스크 레이블이 일관되도록 강제한다.
\[\begin{equation} \mathcal{L}_\textrm{pair} = \frac{1}{T} \sum_{t=1}^T \sum_{p_i^\prime \in H \times W} \mathcal{L}_\textrm{cons} (M_{p_i^\prime}^t, M_{p_j^\prime}^t) \end{equation}\]두 공간적 loss는 가중치 $\lambda_\textrm{pair}$로 결합된다.
\[\begin{equation} \mathcal{L}_\textrm{spatial} = \mathcal{L}_\textrm{proj} + \lambda_\textrm{pair} \mathcal{L}_\textrm{pair} \end{equation}\]시간적 일관성: 시간적 마스크 일관성을 활용하기 위해 TK-Loss를 \(\mathcal{L}_\textrm{temp}\)로 채택한다. 동영상 분할 최적화를 위한 전반적인 시공간적 목적 함수 \(\mathcal{L}_\textrm{seg}\)는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{seg} = \mathcal{L}_\textrm{spatial} + \lambda_\textrm{temp} \mathcal{L}_\textrm{temp} \end{equation}\]Integration with Transformer-based Methods
Box-supervised segmentation loss에 대한 기존 연구들은 Faster R-CNN이나 CondInst와 같은 1단계 또는 2단계 detector와 결합되어 단일 이미지 예시만 다루었다. 그러나 SOTA VIS 방법은 transformer를 기반으로 한다. 이러한 연구들은 loss를 평가할 때 예측된 인스턴스 마스크가 마스크 주석과 일치해야 하는 집합 예측을 통해 object detection을 수행한다. 마스크 없는 VIS 학습을 transformer와 통합하기 위해 한 가지 주요 수정 사항은 이 인스턴스 시퀀스 매칭 단계에 있다.
박스 시퀀스 매칭에는 ground-truth bounding box만 사용할 수 있으므로 초기 시도로 먼저 추정된 인스턴스 마스크에서 bounding box 예측을 생성한다. 그런 다음 VIS 방법에서 사용되는 순차적 박스 매칭 비용 함수를 사용한다. 전체 시퀀스에 대한 매칭 비용을 계산하기 위해 각 개별 bounding box에 대한 $L_1$ loss와 일반화된 IoU loss가 프레임 전체에서 평균화된다. 그러나 저자들은 프레임별 평균화의 매칭 결과가 하나의 이상치(outlier) 프레임에 의해 쉽게 영향을 받을 수 있다는 것을 관찰했다. 특히 weak segmentation 설정에서는 학습 중 불안정성과 성능 저하로 이어진다.
앞서 언급한 프레임별 매칭을 사용하는 대신, 저자들은 weak segmentation 설정에서 실질적인 개선을 가져오는 시공간 박스-마스크 매칭을 경험적으로 찾았다. 먼저 각 예측 인스턴스 마스크를 bounding box 마스크로 변환하고 ground-truth 박스를 박스 마스크로 변환한다. 그런 다음 ground-truth 박스 마스크 시퀀스와 예측된 박스 마스크 시퀀스에서 각각 동일한 수의 점을 무작위로 샘플링한다. Mask2Former와는 달리 시퀀스 매칭 비용을 계산하기 위해 dice IoU loss만 채택한다. 저자들은 cross-entropy가 픽셀당 오차를 누적하여 큰 객체와 작은 객체 사이의 불균형 값을 초래한다는 것을 발견했다. 대조적으로, 객체당 정규화된 IoU loss는 균형 잡힌 메트릭으로 이어진다.
Image-based MaskFreeVIS Pre-training
대부분의 VIS 모델은 COCO instance segmentation 데이터셋트에서 사전 학습된 모델에서 초기화된다. 저자들은 마스크 supervision을 완전히 제거하기 위해 박스 supervision만 사용하여 COCO에서 MaskFreeVIS를 사전 학습하였다. Mask2Former의 원래 GT mask loss를 대체하기 위해 단일 프레임의 공간 일관성 loss를 채택하는 동시에 COCO에서도 동일한 이미지 기반 학습 설정을 따른다. 따라서 저자들은 실험에서 두 가지 학습 설정을 제공한다. 하나는 학습 중에 이미지와 동영상 마스크를 모두 제거하고 다른 하나는 COCO 마스크 주석으로 사전 학습된 가중치를 채택한다. 두 경우 모두 동영상 마스크 주석이 사용되지 않는다.
Experiments
- 데이터셋: YTVIS 2019/2021, OVIS, BDD100K MOTS
- 구현 디테일
- Mask2Former와 SeqFormer를 채택
- 기존 방법과 동일하게 학습 일정과 설정을 유지
- Temporal KNN-patch Loss
- 패치 크기: 3$\times$3
- 탐색 반경: $R = 5$
- $K = 5$
- matching threshold: 0.05
- optimizer: AdamW
- learning rate: $10^{-4}$
- weight decay: 0.05
- batch size: 16
1. Ablation Experiments
Comparison on Temporal Matching Schemes
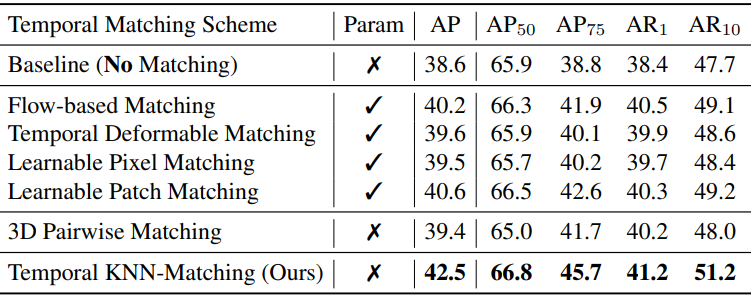
다음은 마스크 없는 학습 설정에서 다양한 시간적 매칭 방식에 대한 비교 결과이다. (YTVIS2019 val)
Effect of Temporal KNN-patch Loss
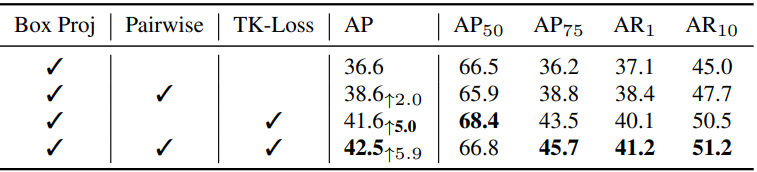
다음은 공간적 pairwise loss와 TK-Loss에 대한 ablation 결과이다.
다음은 pairwise loss, TK-Loss, ground-truth 동영상 및 이미지 마스크를 사용한 Mask2Former에 대한 정성적 비교 결과이다.

Analysis of Temporal KNN-patch Loss
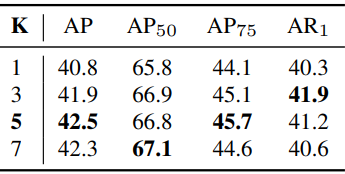
다음은 $K$에 대한 ablation 결과이다.
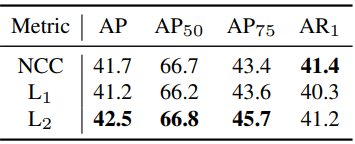
다음은 패치 매칭 메트릭에 대한 ablation 결과이다.
다음은 탐색 반경 $R$에 대한 ablation 결과이다.
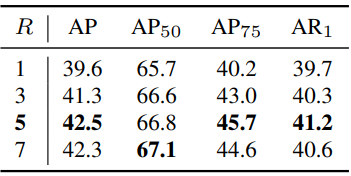
다음은 패치 크기 $N$에 대한 ablation 결과이다.
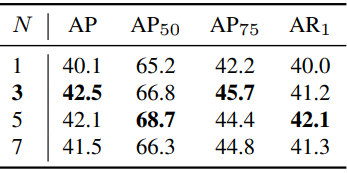
Effect of the Cyclic Tube Connection
다음은 tube 연결 방식에 대한 ablation 결과이다.
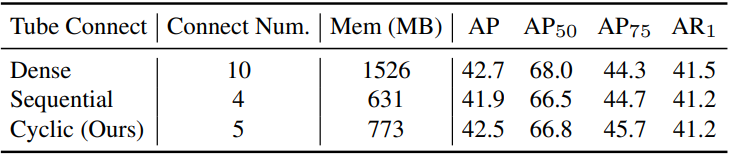
Comparison on Sequence Matching Functions
다음은 집합 매칭 비용 함수에 대한 ablation 결과이다. (YTVIS2019 val)
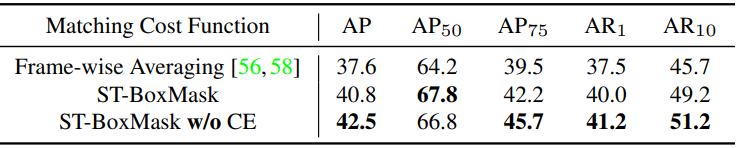
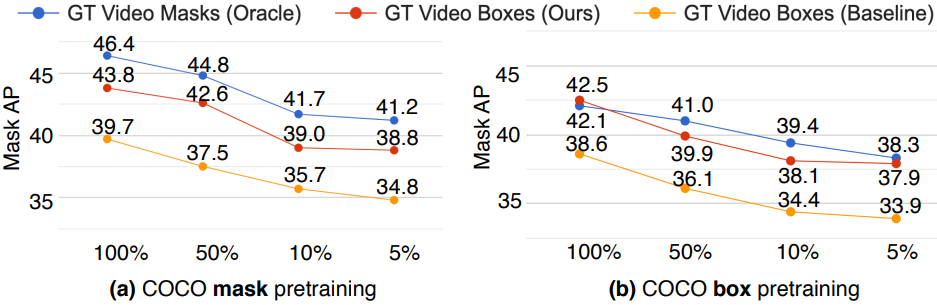
Training on Various Amounts of Data
다음은 YTVIS 학습 데이터에 대한 다양한 비율에 대한 ablation 결과이다. (YTVIS2019 val)
2. Comparison with State-of-the-art Methods
YTVIS 2019/2021
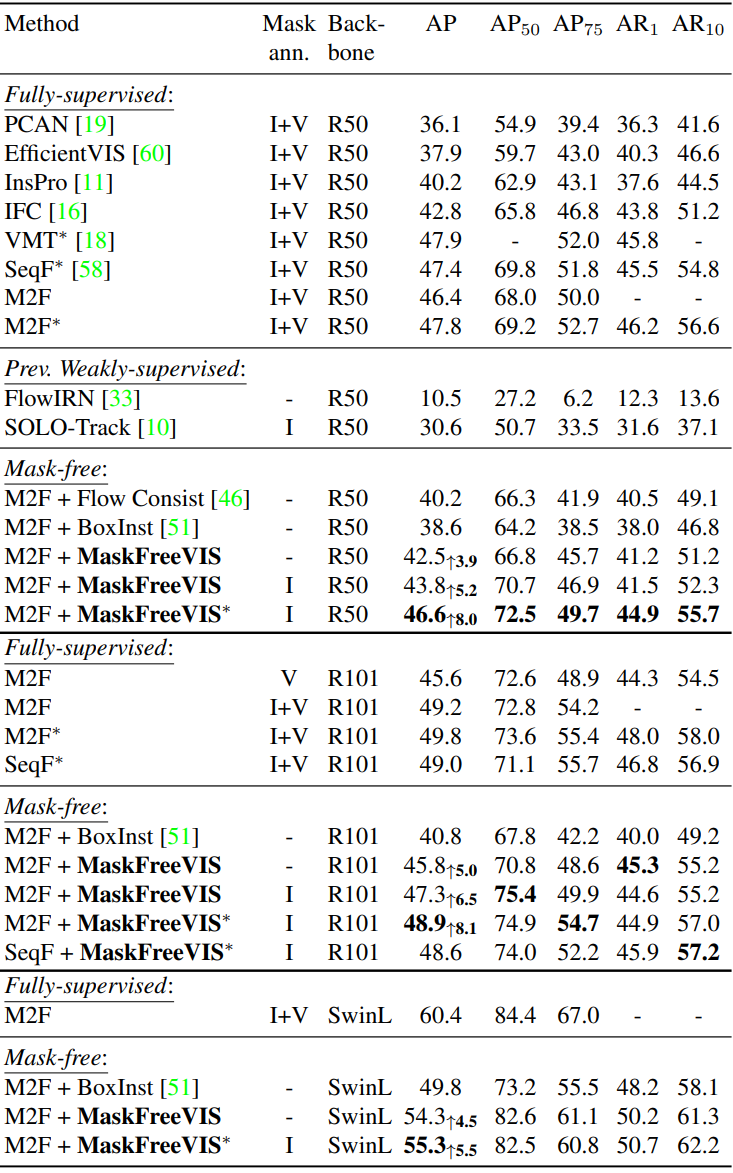
다음은 YTVIS 2019에서 SOTA 방법들과 비교한 표이다.
- I: COCO mask 사전 학습 모델을 초기화로 사용
- V: 학습 중 YTVIS 동영상 마스크를 사용
- $\ast$: 공동 학습을 위해 COCO 이미지의 pseudo mask 사용
- M2F: Mask2Former
- SeqF: SeqFormer
다음은 YTVIS 2021에서 SOTA 방법들과 비교한 표이다.

OVIS
다음은 R50 사용하여 OVIS에서 SOTA 방법들과 비교한 표이다.
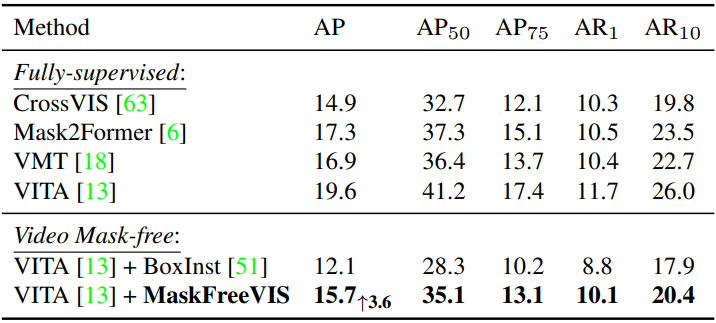
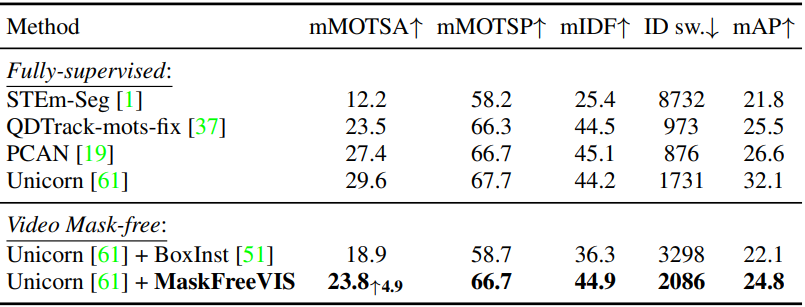
BDD100K MOTS
다음은 BDD100K에서 SOTA 방법들과 비교한 표이다.