[논문리뷰] Masked-attention Mask Transformer for Universal Image Segmentation (Mask2Former)
CVPR 2022. [Paper] [Page] [Github]
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar
Facebook AI Research (FAIR) | University of Illinois at Urbana-Champaign (UIUC)
2 Dec 2021
Introduction
Image segmentation은 픽셀 그룹화 문제를 연구한다. 픽셀을 그룹화하기 위한 다양한 semantic으로 인해 panoptic, instance, semantic segmentation과 같은 다양한 유형의 segmentation task로 이어졌다. 이러한 task들은 semantic만 다르지만 현재 방법은 각 task에 대한 특수 아키텍처를 개발한다. FCN을 기반으로 하는 픽셀별 분류 아키텍처는 semantic segmenation에 사용되는 반면, 각각 단일 카테고리와 연관된 이진 마스크 세트를 예측하는 마스크 분류 아키텍처는 instance segmenation을 지배한다. 이러한 전문화된 아키텍처는 각 개별 task를 향상시켰지만 다른 task로 일반화할 수 있는 유연성이 부족하다. 예를 들어, FCN 기반 아키텍처는 instance segmenation에 어려움을 겪으며 semantic segmenation과 비교하여 instance segmenation을 위한 다양한 아키텍처의 진화로 이어진다. 따라서 모든 task에 대해 각각의 전문화된 아키텍처에 대해 중복된 연구와 최적화 노력이 소요된다.
이러한 단편화를 해결하기 위해 최근 연구에서는 동일한 아키텍처로 모든 segmenation task를 처리할 수 있는 범용 아키텍처를 설계하려고 시도했다. 이러한 아키텍처는 일반적으로 end-to-end 집합 예측 목적 함수 (ex. DETR)를 기반으로 하며 아키텍처, loss, 학습 절차를 수정하지 않고도 여러 task를 성공적으로 처리한다. 범용 아키텍처는 동일한 아키텍처를 갖고 있음에도 불구하고 여전히 다양한 task와 데이터셋에 대해 개별적으로 학습된다. 유연성이 있는 것 외에도 범용 아키텍처는 최근 semantic segmenation과 panoptic segmenation에 대한 SOTA 결과를 보여주었다. 그러나 최근 연구들은 여전히 전문화된 아키텍처를 발전시키는 데 초점을 맞추고 있다. 이는 왜 범용 아키텍처가 전문화된 아키텍처를 대체하지 않았는가라는 질문을 제기한다.
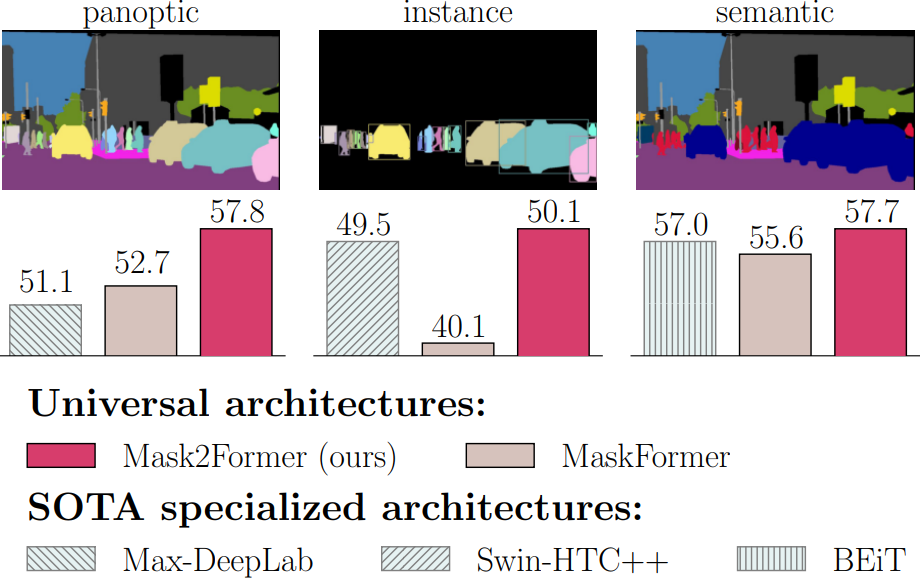
위 그림에서 볼 수 있듯이 기존 범용 아키텍처는 모든 segmenation task를 처리할 수 있을 만큼 유연하지만 실제로 성능은 최고의 전문 아키텍처에 비해 뒤떨어진다. 뒤떨어지는 성능 외에도 범용 아키텍처는 학습하기가 더 어려우며, 일반적으로 고급 하드웨어와 훨씬 긴 학습이 필요하다. 예를 들어, MaskFormer 학습은 40.1 AP에 도달하는 데 300 epochs가 걸리며 32G 메모리가 있는 GPU에 단일 이미지만 넣을 수 있다. 대조적으로, 특화된 Swin-HTC++는 단 72 epochs에서 더 나은 성능을 얻는다. 성능 및 학습 효율성 문제 모두 범용 아키텍처 배포를 방해한다.
본 연구에서는 다양한 segmenation task에서 특수 아키텍처보다 성능이 뛰어나면서도 모든 task에 대해 쉽게 학습할 수 있는 Masked-attention Mask Transformer (Mask2Former)라는 범용 image segmenation 아키텍처를 제안한다. 본 논문은 backbone feature extractor, 픽셀 디코더, transformer 디코더로 구성된 간단한 메타 아키텍처를 기반으로 구축했다. 또한 더 나은 결과와 효율적인 학습을 가능하게 하는 주요 개선 사항을 제안하였다.
- 예측된 세그먼트를 중심으로 localize된 feature에 attention을 제한하는 Transformer 디코더에서 masked attention을 사용한다. 이는 그룹화를 위한 특정 semantic에 따라 객체 또는 영역이 될 수 있다. 이미지의 모든 위치에 attend하는 표준 Transformer 디코더에 사용되는 cross-attention과 비교할 때, masked attention은 더 빠른 수렴과 향상된 성능으로 이어진다.
- 모델이 작은 객체/영역을 분할하는 데 도움이 되는 멀티스케일 고해상도 feature를 사용한다.
- Self-attention과 cross-attention 순서 전환, query feature 학습 가능화, dropout 제거 등의 최적화 개선을 제안한다. 이 모든 것이 추가 컴퓨팅 없이 성능을 향상시킨다.
- 무작위로 샘플링된 소수의 포인트에 대한 마스크 loss를 계산하여 성능에 영향을 주지 않고 학습 메모리를 3배 절약했다. 이러한 개선 사항은 모델 성능을 향상시킬 뿐만 아니라 학습을 훨씬 쉽게 만들어 컴퓨팅이 제한된 사용자가 범용 아키텍처에 더 쉽게 접근할 수 있게 해준다.
Masked-attention Mask Transformer
1. Mask classification preliminaries
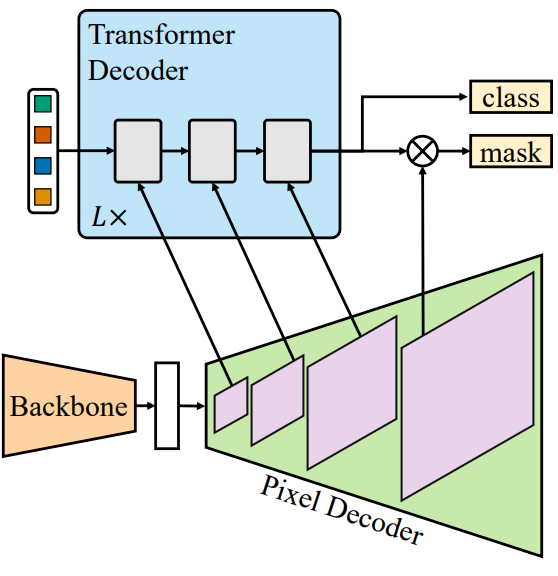
마스크 분류 아키텍처는 $N$개의 해당 카테고리 레이블과 함께 $N$개의 이진 마스크를 예측하여 픽셀을 $N$개의 세그먼트로 그룹화한다. 마스크 분류는 다른 semantic을 다른 세그먼트에 할당하여 모든 segmenation task를 처리할 수 있을 만큼 충분히 범용적이다. 그러나 문제는 각 세그먼트에 대해 좋은 표현을 찾는 것이다. 예를 들어 Mask R-CNN은 semantic segmenation에 대한 적용을 제한하는 표현으로 bounding box를 사용한다. DETR에서 영감을 받아 이미지의 각 세그먼트는 $C$차원 feature 벡터 (“object query”)로 표현될 수 있으며 설정된 예측 목적 함수로 학습된 Transformer 디코더로 처리될 수 있다. 간단한 메타 아키텍처는 세 가지 구성 요소로 구성된다.
- 이미지에서 저해상도 feature를 추출하는 backbone
- Backbone 출력에서 저해상도 feature를 점진적으로 업샘플링하여 고해상도 픽셀별 임베딩을 생성하는 픽셀 디코더
- Object query를 처리하기 위해 이미지 feature를 작동하는 Transformer 디코더
최종 이진 마스크 예측은 object query를 사용하여 픽셀별 임베딩에서 디코딩된다. 이러한 메타 아키텍처의 성공적인 인스턴스화 중 하나는 MaskFormer이다.
2. Transformer decoder with masked attention
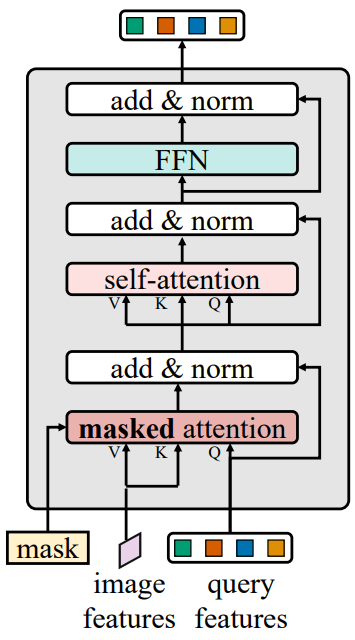
Mask2Former는 앞서 언급한 메타 아키텍처를 채택하고 제안된 Transformer 디코더 (위 그림 참조)가 표준 아키텍처를 대체한다. Transformer 디코더의 주요 구성 요소에는 전체 feature map에 attend하는 대신 각 query에 대해 예측된 마스크의 전경 영역 내로 cross-attention을 제한하여 localize한 feature를 추출하는 masked attention 연산자가 포함된다. 작은 객체를 처리하기 위해 고해상도 feature를 활용하는 효율적인 멀티스케일 전략을 사용한다. 라운드 로빈 방식으로 픽셀 디코더의 feature pyramid에서 연속적인 Transformer 디코더 레이어로 연속적인 feature map을 공급한다. 마지막으로 추가 계산을 도입하지 않고도 모델 성능을 향상시키는 최적화 개선 사항을 통합한다.
2.1 Masked attention
Context feature는 image segmenation에 중요한 것으로 나타났다. 그러나 최근 연구에 따르면 Transformer 기반 모델의 느린 수렴은 cross-attention layer의 글로벌 컨텍스트에 기인하는 것으로 나타났다. 왜냐하면 cross-attention이 localize된 객체 영역에 attend하는 방법을 배우려면 많은 학습이 필요하기 때문이다. 저자들은 로컬 feature가 query feature를 업데이트하기에 충분하고 self-attention을 통해 컨텍스트 정보를 수집할 수 있다고 가정하였다. 이를 위해 각 query에 대해 예측된 마스크의 전경 영역 내에서만 attend하는 cross-attention의 변형인 masked attention을 제안한다.
표준 cross-attention (residual path 포함)은
\[\begin{equation} X_l = \textrm{softmax} (Q_l K_l^\top) V_l + X_{l-1} \end{equation}\]를 계산한다. 여기서 $l$은 레이어 인덱스이고, $X_l \in \mathbb{R}^{N \times C}$는 $l$번째 레이어의 $N$개의 $C$차원 query feature를 의미하며, $Q_l = f_Q (X_{l−1}) \in \mathbb{R}^{N \times C}$이다. $X_0$는 Transformer 디코더에 대한 입력 query feature를 나타낸다. $K_l, V_l \in \mathbb{R}^{H_l W_l \times C}$는 각각 $f_K (\cdot)$과 $f_V (\cdot)$로 변환된 이미지 feature이고, $H_l$과 $W_l$은 이미지 feature의 공간 해상도이다. $f_Q$, $f_K$, $f_V$는 선형 변환이다.
Masked attention은 다음과 같이 attention 행렬을 변조한다.
\[\begin{equation} X_l = \textrm{softmax} (\mathcal{M}_{l-1} + Q_l K_l^\top) V_l + X_{l-1} \end{equation}\]또한, feature 위치 $(x, y)$에 있는 attention mask $\mathcal{M}_{l-1}$은 다음과 같다.
\[\begin{equation} \mathcal{M}_{l-1} (x, y) = \begin{cases} 0 & \quad \textrm{if} \; M_{l-1} (x, y) = 1 \\ - \infty & \quad \textrm{otherwise} \end{cases} \end{equation}\]여기서, \(M_{l−1} \in \{0, 1\}^{N \times H_l W_l}\)은 이전 $(l − 1)$번째 Transformer 디코더 레이어의 resize된 마스크 예측의 이진화된 출력 (임계값 0.5)이다. $K_l$과 동일한 해상도로 resize된다. $M_0$은 $X_0$에서 얻은 이진 마스크 예측이다. 즉, query feature를 Transformer 디코더에 공급하기 전이다.
2.2 High-resolution features
고해상도 feature는 특히 작은 객체의 경우 모델 성능을 향상시킨다. 그러나 이는 계산적으로 까다롭다. 따라서 계산량 증가를 제어하면서 고해상도 feature를 도입하기 위한 효율적인 멀티스케일 전략을 제안한다. 항상 고해상도 feature map을 사용하는 대신 저해상도 feature와 고해상도 feature로 구성된 feature pyramid를 활용하고 멀티스케일 feature의 해상도를 한 번에 하나의 Transformer 디코더 레이어에 공급한다.
구체적으로, 원본 이미지의 1/32, 1/16, 1/8 해상도로 픽셀 디코더에서 생성된 feature pyramid를 사용한다. 각 해상도에 대해 sinusoidal 위치 임베딩 $e_\textrm{pos} \in \mathbb{R}^{H_l W_l \times C}$과 학습 가능한 scale-level 임베딩 $e_\textrm{lvl} \in \mathbb{R}^{1 \times C}$을 추가한다. 위 그림에 표시된 대로 해당 transformer 디코더 레이어에 대해 최저 해상도부터 최고 해상도까지 이를 사용한다. 이 3-layer Transformer 디코더를 $L$번 반복한다. 따라서 최종 Transformer 디코더에는 $3L$개의 레이어가 있다. 구체적으로, 처음 3개 레이어는 해상도 $H_1 = H/32$, $H_2 = H/16$, $H_3 = H/8$, $W_1 = W/32$, $W_2 = W/16$, $W_3 = W/8$의 feature map을 받는다. 여기서 $H$와 $W$는 원본 이미지 해상도이다. 이 패턴은 모든 후속 레이어에 대해 라운드 로빈 방식으로 반복된다.
2.3 Optimization improvements
표준 Transformer 디코더 레이어는 qeury feature를 self-attention, cross-attention, feed-forward network (FFN) 순서로 처리하는 세 가지 모듈로 구성된다. 또한 query feature ($X_0$)은 Transformer 디코더에 입력되기 전에 0으로 초기화되며 학습 가능한 위치 임베딩과 연결된다. 또한, residual connection과 attention map 모두에 dropout이 적용된다.
Transformer 디코더 디자인을 최적화하기 위해 다음 세 가지 개선 사항을 적용한다.
- 계산을 보다 효율적으로 만들기 위해 self-attention과 cross-attention (masked attention)의 순서를 전환한다. 첫 번째 self-attention 레이어에 대한 query feature는 이미지 독립적이며 이미지의 신호가 없다. Self-attention을 적용하면 정보가 풍부해질 가능성이 없다.
- Query feature $X_0$도 학습 가능하게 만들고 (학습 가능한 query 위치 임베딩을 계속 유지함) 학습 가능한 query feature는 Transformer 디코더에서 마스크 $M_0$를 예측하는 데 사용되기 전에 직접 supervise된다. 저자들은 이러한 학습 가능한 query feature가 region proposal network처럼 작동하고 마스크 proposal을 생성하는 feature를 가지고 있음을 발견했다.
- 저자들은 dropout이 필요하지 않으며 일반적으로 성능이 저하된다는 사실을 발견했다. 따라서 디코더에서 dropout을 완전히 제거한다.
3. Improving training efficiency
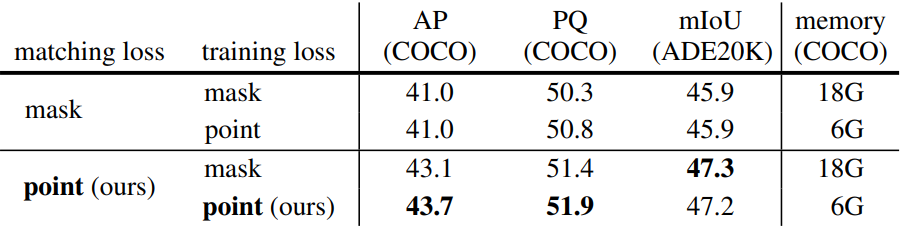
범용 아키텍처 학습의 한 가지 제한 사항은 고해상도 마스크 예측으로 인해 메모리를 많이 소비하므로 메모리 친화적인 특수 아키텍처보다 접근성이 낮다는 것이다. 예를 들어 MaskFormer는 32G 메모리가 있는 GPU에 단일 이미지만 넣을 수 있다. 전체 마스크 대신 무작위로 샘플링된 $K$개의 점에서 계산된 마스크 loss를 사용하여 segmenation 모델을 학습할 수 있음을 보여주는 PointRend와 Implicit PointRend를 기반으로 매칭 loss와 최종 loss 계산 모두에서 샘플링된 포인트를 사용하여 마스크 loss를 계산한다.
구체적으로, 이분 매칭을 위한 비용 매트릭스를 구성하는 매칭 loss에서 모든 예측 마스크와 ground truth 마스크에 대해 동일한 $K$개의 포인트의 집합을 균일하게 샘플링한다. 예측과 일치된 ground truth 간의 최종 loss에서 중요도 샘플링을 사용하여 다양한 예측 쌍과 ground truth에 대해 서로 다른 $K$개의 포인트의 집합을 샘플링한다. 본 논문은 $K = 12544$, 즉 $112 \times 112$개의 포인트로 설정했다. 이 새로운 학습 전략은 학습 메모리를 이미지당 18GB에서 6GB로 3배 효과적으로 줄여 계산 리소스가 제한된 사용자가 Mask2Former에 더 쉽게 접근할 수 있게 해준다.
Experiments
- 데이터셋: COCO, ADE20K, Cityscapes, Mapillary Vistas
1. Main results
Panoptic segmentation
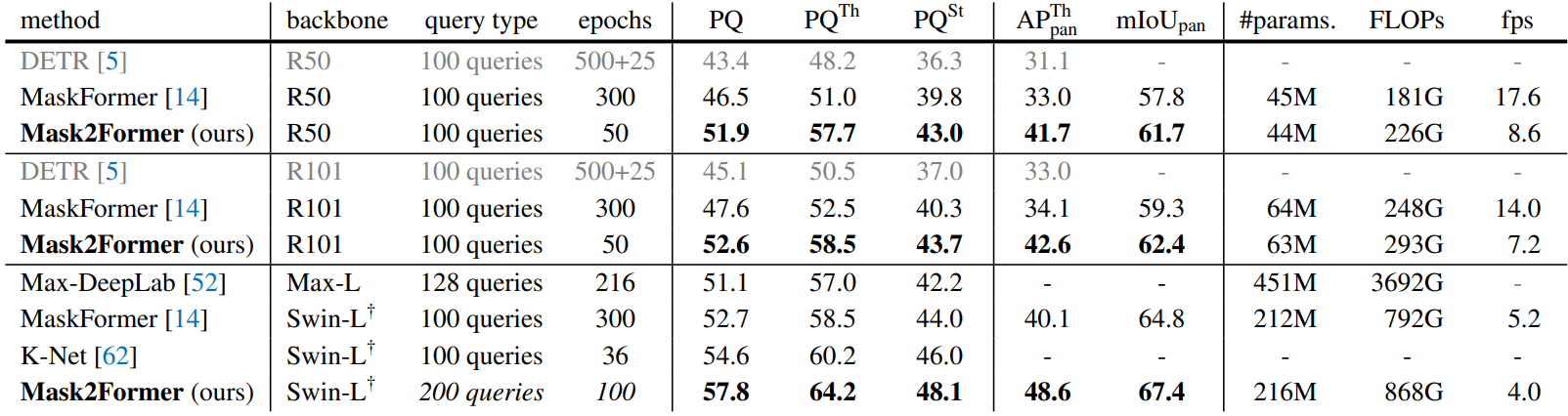
다음은 133개의 카테고리의 COCO panoptic val2017에서 panoptic segmentation 성능을 비교한 표이다.
Instance segmenation
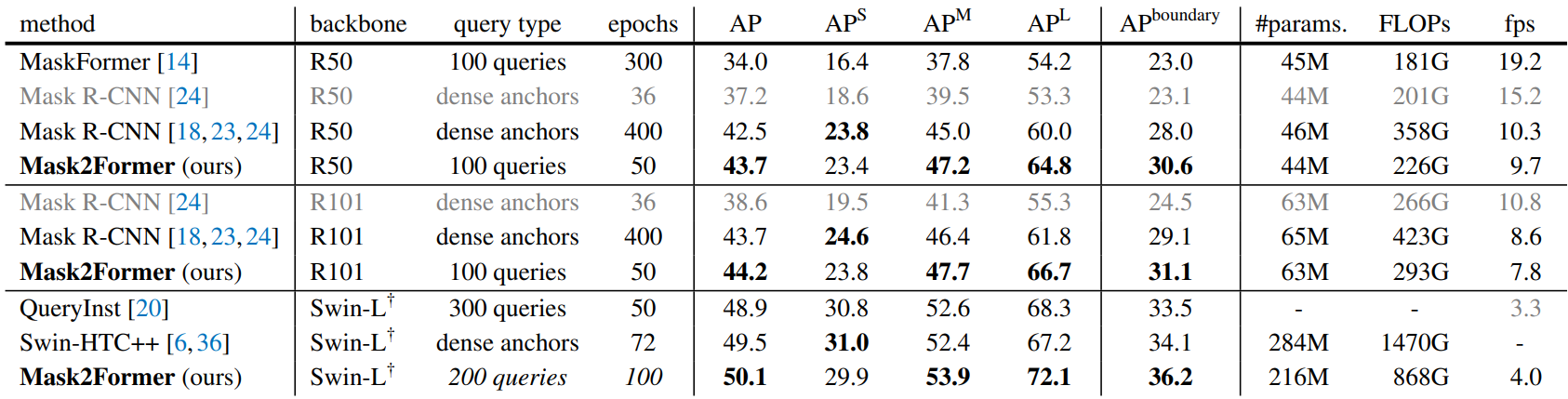
다음은 80개의 카테고리의 COCO val2017에서 instance segmentation 성능을 비교한 표이다.
Semantic segmentation
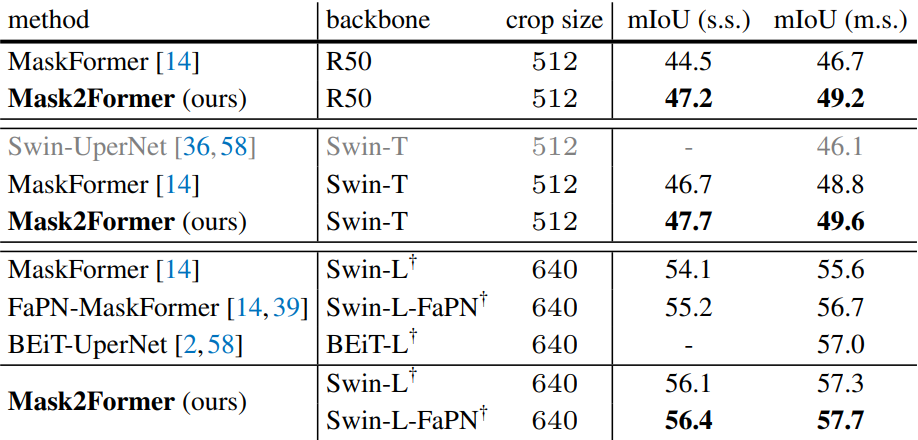
다음은 150개의 카테고리의 ADE20K val에서 semantic segmentation 성능을 비교한 표이다.
2. Ablation studies
Transformer decoder
다음은 masked attention과 고해상도 feature에 대한 ablation 결과이다.

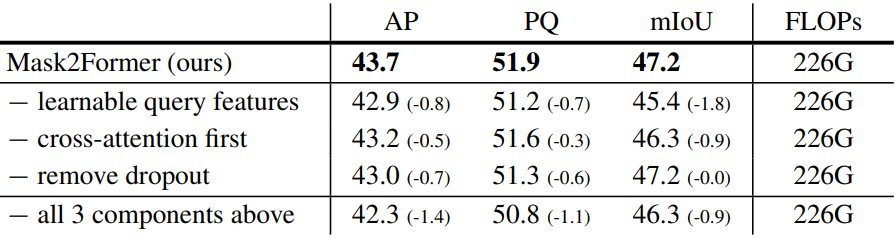
다음은 최적화 개선 사항에 대한 ablation 결과이다.
Masked attention
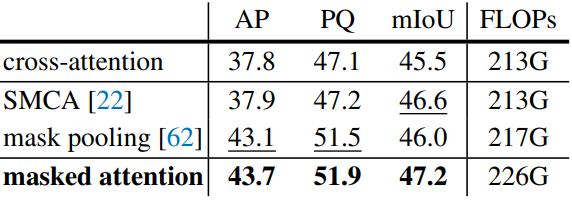
다음은 masked attention과 다른 cross-attention 변형을 비교한 표이다.
Feature resolution
다음은 feature 해상도에 대한 ablation 결과이다.
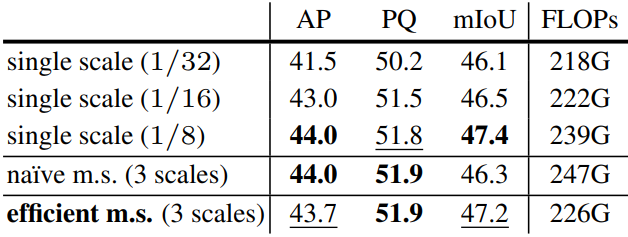
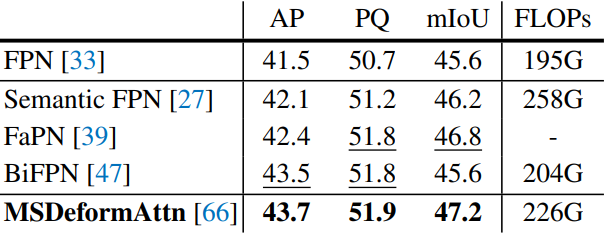
Pixel decoder
다음은 픽셀 디코더에 대한 ablation 결과이다.
Calculating loss with points vs. masks
다음은 포인트와 마스크를 사용한 loss 계산에 대한 성능과 메모리를 비교한 표이다.
Learnable queries as region proposals
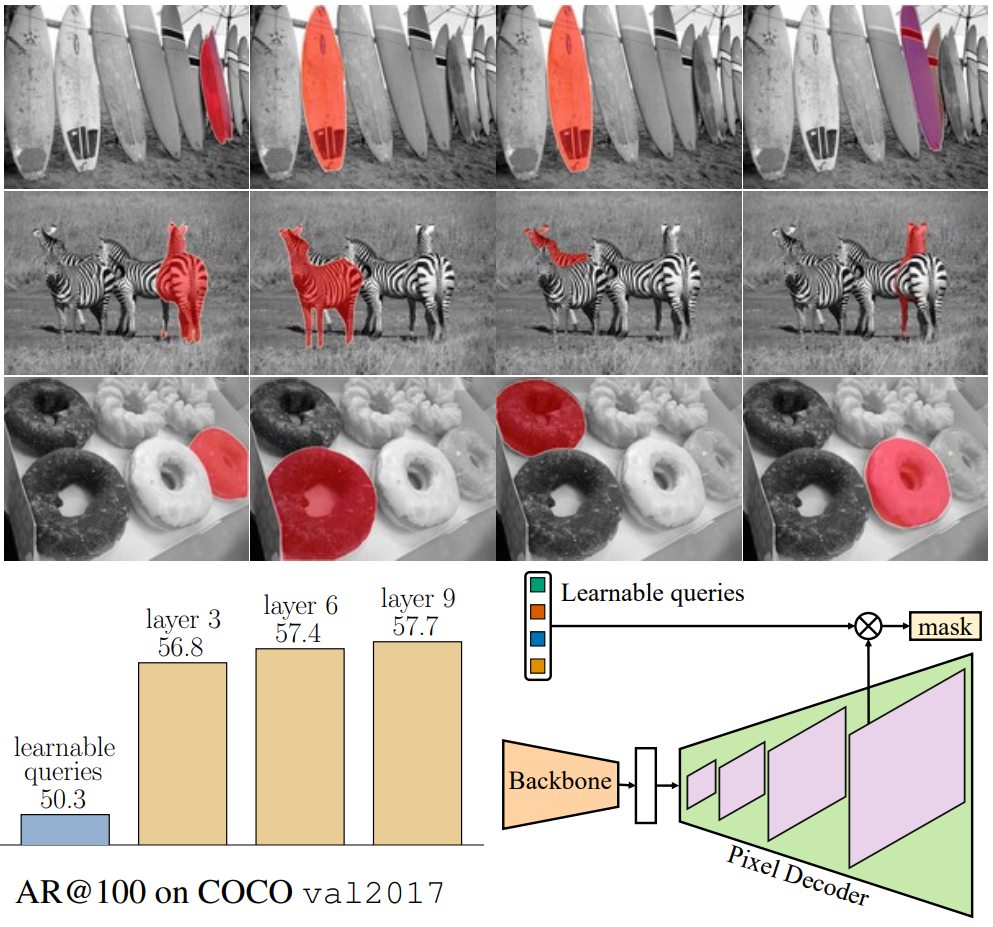
위 그림의 상단은 선택된 4개의 학습 가능한 query를 Transformer 디코더 (R50 backbone 사용)에 공급하기 전에 마스크 예측을 시각화한 것이다. 왼쪽 하단은 100개의 proposal로 클래스에 무관하게 평균 recall을 계산하고 이러한 학습 가능한 query가 Transformer 디코더 레이어 (레이어 9) 이후 Mask2Former의 최종 예측과 비교하여 좋은 proposal을 제공한다는 것을 보여준다. 오른쪽 하단은 proposal 생성 프로세스이다.
3. Generalization to other datasets
다음은 Cityscapes val에서의 성능을 비교한 표이다.
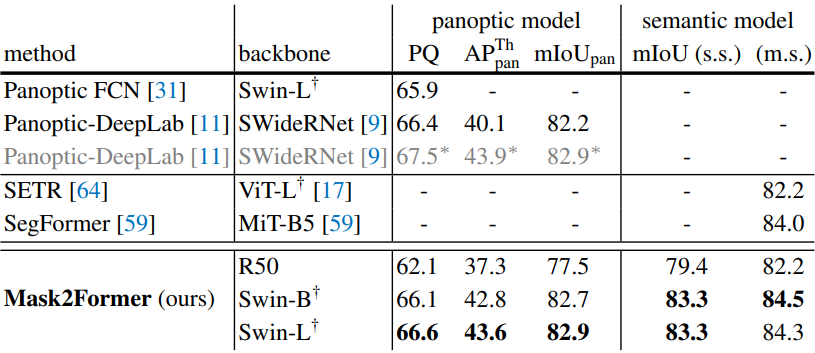
4. Limitations

궁극적인 목표는 모든 image segmenation task에 대해 단일 모델을 학습시키는 것이다. 위 표는 panoptic segmenation에 대해 학습된 Mask2Former가 3개의 데이터셋에 걸쳐 instance segmenation과 semantic segmenation에 대한 해당 주석으로 학습된 정확히 동일한 모델보다 성능이 약간 더 나쁘다는 것을 알 수 있다. 이는 Mask2Former가 다양한 task로 일반화할 수 있더라도 해당 특정 task에 대해서는 여전히 학습이 필요함을 의미한다.