[논문리뷰] LAPA: Latent Action Pretraining from Videos
ICLR 2025. [Paper] [Page] [Github] [Model]
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, Minjoon Seo
KAIST | University of Washington | Microsoft Research | NVIDIA | Allen Institute for AI
15 Oct 2024

Introduction
로봇 공학을 위한 Vision-Language-Action (VLA) 모델은 LLM을 비전 인코더에 맞춰 정렬한 후, 다양한 로봇 데이터셋에 대해 fine-tuning하여 학습시킨다. 이를 통해 새로운 명령, 처음 보는 물체, 분포 변화에 대한 일반화를 가능하게 한다. 그러나 다양한 실제 로봇 데이터셋은 대부분 인간의 원격 조작을 필요로 하므로 scaling이 어렵다. 반면 인터넷 동영상 데이터는 대규모로 인간의 행동과 물리적 상호작용에 대한 풍부한 사례를 제공하며, 소규모의 로봇 데이터셋의 한계를 극복할 수 있는 유망한 접근법을 제시한다. 그러나 인터넷 동영상 데이터에서 학습하는 것은 두 가지 주요 과제 때문에 어렵다.
- 명확한 action 레이블이 없다.
- 데이터 분포가 일반적인 로봇 시스템의 구현 및 환경과 근본적으로 다르다.
본 논문에서는 로봇 action 레이블 없이 로봇 foundation model을 사전 학습하는 unsupervised 학습 방식인 Latent Action Pretraining (LAPA)을 제안하였다.
LAPA는 순차적으로 학습되는 두 모델로 구성되며, 이후 latent action을 실제 로봇 action에 매핑하는 fine-tuning 단계가 이어진다. 첫 번째 사전 학습 단계에서는 VQ-VAE 기반 objective를 사용하여 이미지 프레임 간의 quantize된 latent action을 학습시킨다. 언어 모델링에 사용되는 BPE와 유사하게, 이는 미리 정의된 action prior (ex. end-effector 위치, joint 위치) 없이 action을 tokenize하는 학습으로 볼 수 있다. 두 번째 단계에서는 동영상 observation과 task 설명을 기반으로 첫 번째 단계에서 도출된 latent action을 예측하기 위해 VLM을 사전 학습하여 behavior cloning을 수행한다. 마지막으로, 로봇 action이 포함된 소규모 로봇 조작 데이터셋에서 모델을 fine-tuning하여 latent action에서 로봇 action으로의 매핑을 학습시킨다.
LAPA는 실제 조작 task에서 기존 SOTA VLA 모델인 OpenVLA보다 우수한 성능을 보였다. 특히 LAPA는 교차 환경 및 교차 구현 시나리오에서 상당히 우수한 성능을 보였다. 또한, 인간 조작 동영상만으로 사전 학습된 경우에도 효과적이며, Bridgev2에서 사전 학습된 모델보다 우수한 성능을 보였다. LAPA는 물체와 카메라의 움직임을 포함한 환경 중심의 동작을 효과적으로 포착하는 것으로 나타났으며, 이는 내비게이션이나 동적 task와 같은 후속 task에 유용할 수 있다.
Method
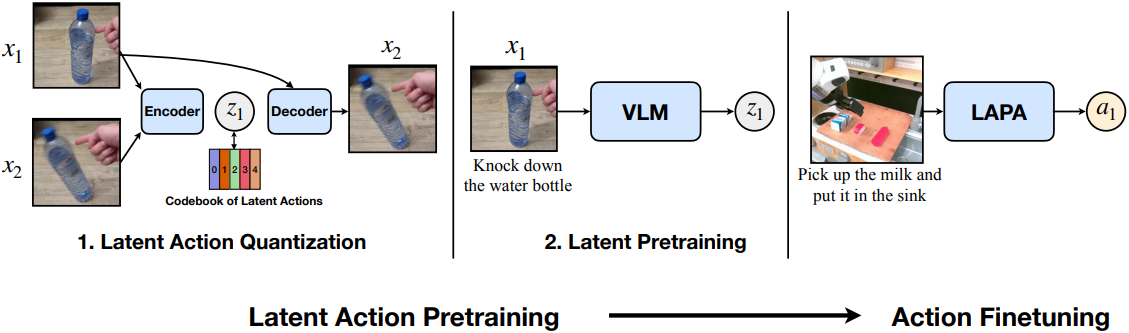
LAPA는 순차적으로 학습되는 두 가지 모델, latent action quantization과 latent pretraining으로 구성된다. 두 모델의 학습에 동일한 사전 학습 데이터셋을 사용한다.
1. Latent Action Quantization
Latent action을 완전히 unsupervised 방식으로 학습하기 위해 Genie에 약간의 수정을 가한 latent action quantization 모델을 학습시킨다. Latent action quantization 모델은 인코더-디코더 아키텍처로, 인코더는 고정된 윈도우 크기 $H$를 갖는 동영상의 현재 프레임 $x_t$와 미래 프레임 $x_{t+H}$를 입력으로 받아 latent action $z_t$를 출력한다. 디코더는 latent action $z_t$와 $x_t$를 입력으로 받아 $x_{t+H}$를 재구성하도록 학습된다.
Genie와 달리, additive embedding 대신 cross-attention을 사용하여 $x_t$가 주어졌을 때 $z_t$에 attention한다. 이는 경험적으로 더 semantic하게 유의미한 latent action을 포착한다. Quantization 모델은 C-ViViT tokenizer의 변형으로, 인코더는 spatial transformer와 temporal transformer를 모두 포함하는 반면, 디코더는 두 개의 이미지 프레임만 입력으로 사용하기 때문에 spatial transformer만 포함한다.
Latent action quantization 모델의 학습은 VQ-VAE objective에 기반하며, continuous한 임베딩에서 가장 가까운 quantize된 표현은 각 임베딩이 codebook에 해당하는 임베딩 공간에서 검색된다. VQ-VAE objective는 latent action $z_t$가 discrete한 토큰이 될 수 있도록 하여 VLM이 $z_t$를 쉽게 예측할 수 있게 한다. Latent action은 크기가 $\vert C \vert$인 codebook vocabulary 공간에서 $s$개의 시퀀스를 사용하여 표현된다. 시퀀스 길이 $s$는 VQ 프로세스 바로 전에 사용되는 CNN의 kernel size, stride, padding 값으로 지정된다.
VQ-VAE에서 종종 관찰되는 gradient collapse를 방지하기 위해 VQ 오차를 원래 오차와 정규화된 noise 벡터의 곱으로 대체하는 NSVQ를 활용한다. 또한 표현 붕괴를 방지하기 위해 디코딩 중에 프레임 $x_t$의 패치 임베딩에 stop gradient를 적용한다. NSVQ의 codebook 교체 테크닉은 codebook 활용도를 극대화하기 위해 초기 학습 단계에 적용된다.
본 논문에서는 latent action quantization의 인코더를 latent pretraining의 inverse dynamics model로 활용하고, 디코더를 신경망 기반 closed-loop rollout 생성에 활용한다. 기존 방법들과 달리, latent action으로부터 rollout을 생성하는 world model과 latent pretraining을 통해 이러한 latent action을 생성하는 policy model을 모두 학습시킨다.
2. Latent Pretraining
Latent action quantization 모델의 인코더를 inverse dynamics model로 사용하여 프레임 $x_{t+1}$이 주어졌을 때 모든 프레임 $x_t$에 latent action $z_t$를 레이블링한다. 그런 다음, 동영상 클립의 언어 명령과 현재 이미지 $x_t$를 고려하여 $z_t$를 예측하기 위해 사전 학습된 VLM을 사용하여 action pretraining을 수행한다. VLM의 기존 언어 모델 head를 사용하는 대신, vocabulary 크기가 $\vert C \vert$인 별도의 latent action head (단일 MLP layer)를 추가한다. 기본적으로 학습 중에는 비전 인코더만 고정하고 언어 모델은 고정하지 않는다. Latent pretraining은 GT action에 의존하지 않으므로, 언어 명령이 있는 모든 유형의 동영상을 사용할 수 있다. 또한, 로봇 공학에서 사용되는 기존의 action 세분성(ex. end-effector 위치, joint 위치, joint 토크 등)과 달리, action 세분성에 대한 사전 정보가 필요하지 않으며, 주어진 동영상 데이터셋에서 연속되는 observation들의 차이를 가장 잘 포착하도록 최적화하는 방식으로 end-to-end 학습을 수행한다.
3. Action Finetuning
Latent action을 예측하도록 사전 학습된 VLA는 latent action이 실제 end-effector action이나 joint action이 아니기 때문에 실제 로봇에서 직접 사용할 수 없다. Latent action을 실제 로봇 action에 매핑하기 위해 GT action이 있는 작은 궤적 집합에서 LAPA를 fine-tuning한다. Action 예측을 위해 로봇의 각 차원에 대한 continuous action space를 discretize하여 각 bin에 할당된 데이터 포인트 수가 동일하도록 한다.Latent action head를 삭제하고 새 action head로 대체하여 GT action을 생성한다. Latent pretraining과 마찬가지로 비전 인코더를 고정하고 기본 언어 모델의 모든 파라미터는 고정하지 않는다.
Experiments
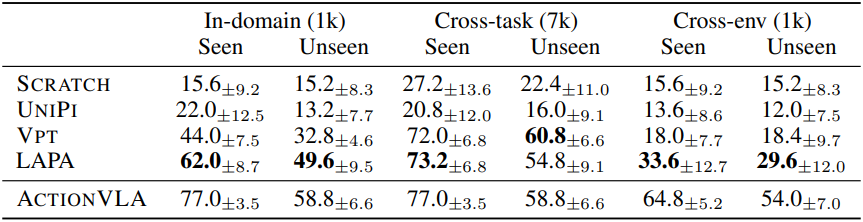
1. Language Table Results
다음은 Language Table 벤치마크에 대한 평균 성공률(%)을 비교한 결과이다.
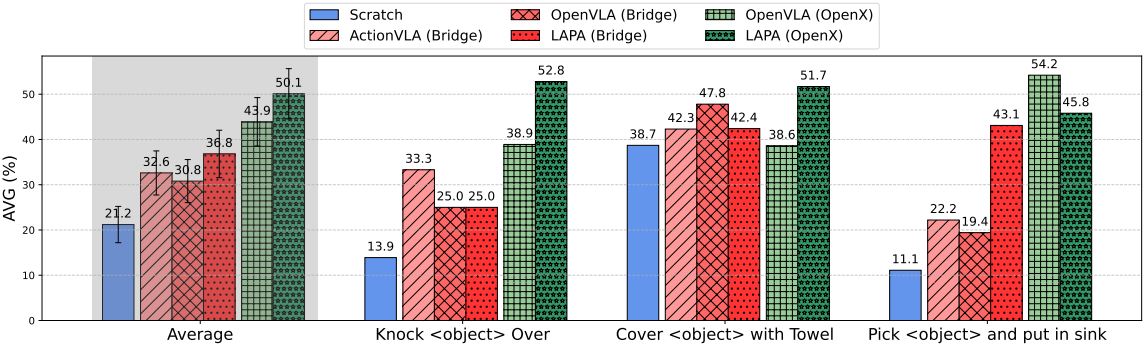
2. Real-world Results
다음은 실제 로봇 조작에 대한 평균 성공률(%)을 비교한 결과이다.
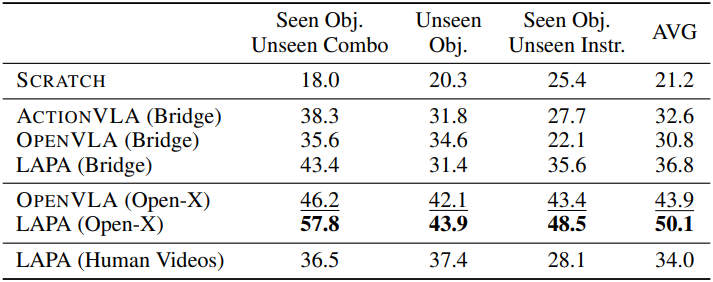
3. Learning from Human Manipulation Videos
다음은 인간이 조작하는 동영상으로 사전 학습하였을 때의 결과를 비교한 것이다.

4. Ablation and Analysis
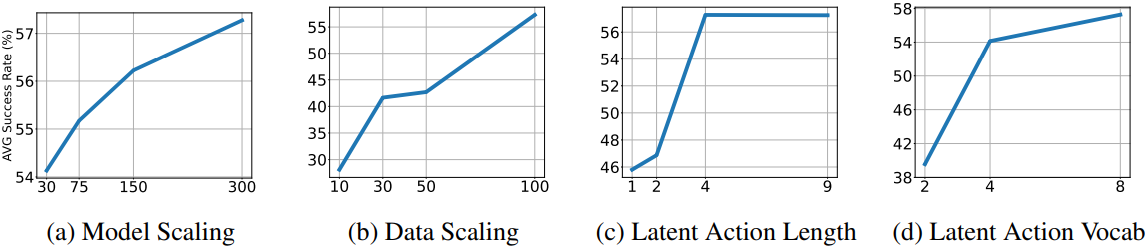
다음은 scaling ablation 결과이다.
다음은 latent action을 분석하기 위해, 현재 observation $x_1$과 quantize된 latent action을 latent action quantization의 디코더에 컨디셔닝한 결과이다.

LAPA에서 생성된 latent action으로 latent action quantization 모델을 컨디셔닝하여 rollout 이미지를 생성한 결과이다. LAPA는 현재 이미지 $x_1$과 ‘take the broccoli out of the pot’이라는 언어 명령으로 컨디셔닝되었다.

Limitations
- LAPA는 잡기와 같은 세밀한 action 생성 task에서 action pretraining보다 성능이 떨어진다.
- 기존 VLA와 마찬가지로 LAPA는 실시간 inference가 어렵다.
- 로봇 조작 동영상 이외의 영역에서 LAPA를 적용하는 방법은 아직 연구되지 않았다.