[논문리뷰] Genie: Generative Interactive Environments
ICML 2024. [Paper] [Page]
Genie Team
Google DeepMind | University of British Columbia
23 Feb 2024
Introduction
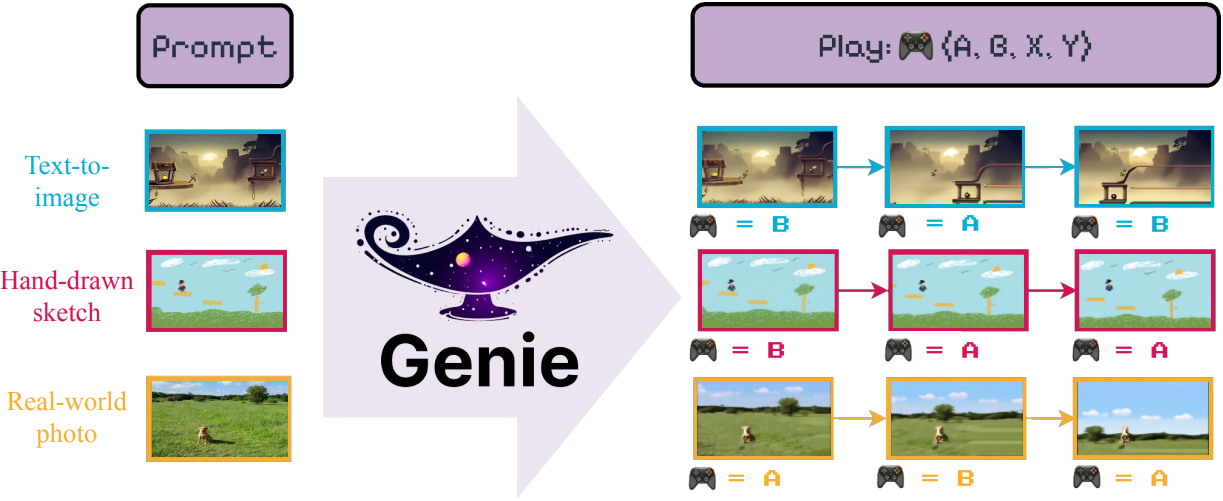
본 논문은 인터넷에서 얻은 방대한 양의 동영상을 활용하여 새로운 이미지나 동영상을 생성할 뿐만 아니라 완전한 인터랙티브 경험을 생성할 수 있는 새로운 패러다임인 generative interactive environment (Genie)를 제안하였다. Genie는 20만 시간 이상의 인터넷 게임 동영상으로 구성된 대규모 데이터셋을 기반으로 학습되었으며, action이나 텍스트 주석 없이 학습되었음에도 불구하고 학습된 latent action space를 통해 프레임 단위로 제어가 가능하다. 11B 파라미터의 Genie는 foundation model에서 일반적으로 나타나는 특성을 보이며, 처음 보는 이미지를 프롬프트로 사용하여 완전히 상상된 가상 세계를 만들고 플레이할 수 있다.
Genie는 SOTA 동영상 생성 모델의 아이디어를 기반으로 하며, 핵심 디자인은 모든 모델 구성 요소에 사용되는 spatiotemporal (ST) transformer이다. Genie는 새로운 video tokenizer를 활용하고 causal action model을 통해 latent action을 추출한다. 동영상 토큰과 latent action은 모두 MaskGIT을 사용하여 다음 프레임을 autoregressive하게 예측하는 dynamics model로 전달된다. Batch size와 모델 크기에 대한 아키텍처의 엄격한 scaling 분석 결과, 아키텍처는 추가 계산 리소스에 따라 원활하게 scaling되어 최종 11B 파라미터 모델이 되었다. 수백 개의 2D 플랫포머 게임에서 3만 시간 분량의 인터넷 게임플레이 동영상들을 사용하여 Genie를 학습시켜 이 설정에 대한 foundation world model을 생성한다.
저자들은 일반성을 입증하기 위해, RT1 데이터셋의 action-free 로봇 동영상에 대해 별도의 모델을 학습시켜 일관된 latent action을 갖는 환경을 학습시켰다. 또한, 인터넷 동영상에서 학습한 latent action을 시뮬레이션된 RL 환경의 action-free 동영상에서 policy를 추론하는 데 사용할 수 있음을 보여주었다. 이는 Genie가 차세대 범용 에이전트를 학습하는 데 필요한 무한한 데이터를 확보할 수 있는 열쇠를 쥐고 있음을 시사한다.
Method
Genie 아키텍처의 여러 구성 요소는 ViT를 기반으로 한다. Transformer의 quadratic한 메모리 비용은 최대 수 만개의 토큰을 포함할 수 있는 동영상에서 문제를 야기한다. 따라서 모든 모델 구성 요소에 메모리 효율적인 ST-transformer를 채택하여 모델 용량과 연산량 제약 간의 균형을 맞춘다.
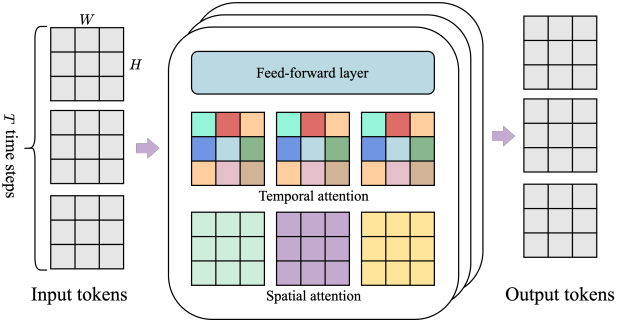
모든 토큰이 다른 모든 토큰에 대응하는 기존 transformer와 달리, ST-transformer는 spatial attention layer와 temporal attention layer가 인터리빙된 $L$개의 ST block과 그 뒤에 feed-forward layer (FFW)가 위치한다. Spatial layer의 self-attention은 각 timestep 내에서 $1 \times H \times W$개의 토큰에 대해 attention을 수행하고, temporal layer의 self-attention은 $T$개의 timestep에 걸쳐 $T \times 1 \times 1$개의 토큰에 대해 attention을 수행한다. Temporal layer는 causal mask를 가진 인과적인 구조로 가정한다.
본 아키텍처에서는 계산 복잡도를 지배하는 spatial attention layer가 프레임 수에 따라 이차적으로 증가하는 것이 아니라 선형적으로 증가하여, 확장된 상호작용에서 일관된 역학을 가진 동영상 생성에 훨씬 더 효율적이다. 또한 ST block에서는 공간적 요소와 시간적 요소 뒤에 하나의 FFW만 포함하고, 모델의 다른 구성 요소를 scaling할 수 있도록 공간적 요소 이후의 FFW를 생략했는데, 이를 통해 결과가 상당히 개선되었다.
1. Model Components
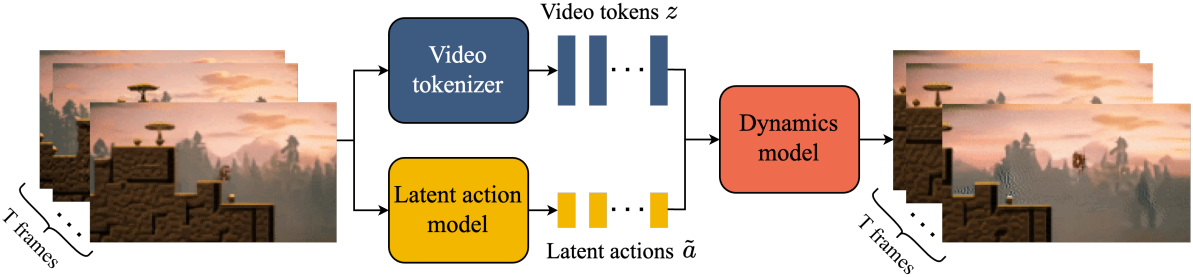
위 그림에서 볼 수 있듯이, 모델은 세 가지 핵심 구성 요소를 포함한다.
- Latent Action Model (LAM): 각 프레임 쌍 사이의 latent action $a$를 추론
- Video Tokenizer: 동영상 프레임을 개별 토큰 $z$로 변환
- Dynamics Model: latent action과 과거 프레임 토큰을 기반으로 동여상의 다음 프레임을 예측
이 모델은 표준 autoregressive 동영상 생성 파이프라인에 따라 두 단계로 학습된다. 먼저 dynamics model에 사용되는 video tokenizer를 학습시킨다. 그런 다음 픽셀에서 직접 추출한 latent action model과 동영상 토큰에서 추출한 dynamics model을 공동으로 학습시킨다.
Latent Action Model (LAM)
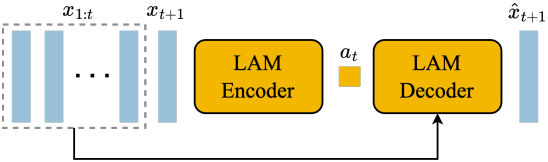
제어 가능한 동영상 생성을 위해, 각 미래 프레임 예측을 이전 프레임에서 수행된 action을 기반으로 한다. 그러나 인터넷에서 제공되는 동영상에서는 이러한 action 레이블을 얻기가 매우 어렵고, action 주석을 얻는 데 비용이 많이 들 수 있다. 따라서, 본 논문에서는 완전 unsupervised 방식으로 latent action을 학습시켰다.
먼저, 인코더는 이전의 모든 프레임 \(x_{1:t} = (x_1, \cdots, x_t)\)와 다음 프레임 $x_{t+1}$을 입력으로 받고, 이에 대응하는 continuous latent action의 집합 \(\tilde{a}_{1:t} = (\tilde{a}_1, \cdots, \tilde{a}_t)\)을 출력한다. 그런 다음 디코더는 이전의 모든 프레임과 latent action을 입력으로 받고 다음 프레임 \(\hat{x}_{t+1}\)을 예측한다.
모델을 학습시키기 위해 VQ-VAE 기반 objective를 활용한다. 이를 통해 예측되는 action의 수를 작은 discrete한 코드 세트로 제한할 수 있다. VQ codebook의 vocabulary 크기 $\vert A \vert$, 즉 가능한 latent action의 최대 개수를 작은 값으로 제한하여 사람이 플레이할 수 있도록 하고 제어 가능성을 더욱 강화한다 (실제로 $\vert A \vert = 8$을 사용). 디코더는 history와 latent action에만 접근할 수 있으므로, \(\tilde{a}_t\)는 디코더가 미래 프레임을 성공적으로 재구성할 수 있도록 과거와 미래 사이의 가장 의미 있는 변화를 인코딩해야 한다. 이 디코더는 LAM 학습 신호를 제공하기 위해서만 존재한다. 실제로 VQ codebook을 제외하고 전체 LAM은 inference 시점에 제거되고 사용자의 action으로 대체된다.
LAM은 ST-transformer 아키텍처를 활용한다. Temporal layer의 causal mask는 전체 동영상 $x_{1:T}$를 입력으로 받아 각 프레임 사이의 모든 latent action \(\tilde{a}_{1:T-1}\)을 생성할 수 있도록 한다.
Video Tokenizer

차원을 줄이고 더 높은 품질의 동영상 생성을 가능하게 하기 위해 동영상을 discrete한 토큰으로 압축한다. 여기에 VQ-VAE를 활용하며, 이 VQ-VAE는 $T$개의 동영상 프레임 $x_{1:T} = (x_1, \cdots, x_T) \in \mathbb{R}^{T \times H \times W \times C}$를 입력으로 받아, 각 프레임에 대한 discrete한 표현 $z_{1:T} = (z_1, \cdots, z_T) \in \mathbb{R}^{T \times D}$를 생성한다. Tokenizer는 전체 동영상 시퀀스에 걸쳐 표준 VQ-VQAE objective를 사용하여 학습된다.
Tokenization 단계에서 공간적 압축에만 집중했던 기존 방법들과 달리, 본 논문에서는 인코더와 디코더 모두에서 ST-transformer를 활용하여 인코딩에 시간적 역학을 통합함으로써 동영상 생성 품질을 향상시켰다. ST-transformer의 인과적 특성으로 인해, 각 $z_t$에는 이전에 확인된 동영상 $x_{1:t}$의 모든 프레임 정보가 포함된다. ST-transformer 기반 tokenizer는 프레임 수에 따라 비용이 선형적으로 증가하여 높은 계산 효율을 보인다.
Dynamics Model
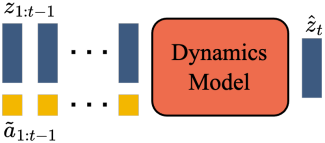
Dynamics model은 decoder-only MaskGIT transformer이다. 각 timestep $t \in [1, T]$에서 tokenize된 동영상 $z_{1:t-1}$과 stopgrad latent action \(\tilde{a}_{1:t-1}\)을 입력으로 받아 다음 프레임 토큰 \(\hat{z}_t\)를 예측한다. ST-transformer를 사용하는데, 인과적 구조에 의해 모든 $(T-1)$개의 프레임의 토큰 $z_{1:T-1}$과 latent action \(\tilde{a}_{1:T-1}\)을 입력으로 사용하여 모든 다음 프레임에 대한 예측 \(\hat{z}_{2:T}\)을 생성한다.
이 모델은 예측된 토큰 \(\hat{z}_{2:T}\)과 실제 토큰 \(z_{2:T}\)간의 cross-entropy loss를 사용하여 학습된다. 학습 시에 입력 토큰 $z_{2:T-1}$을 베르누이 분포 마스킹 비율에 따라 0.5에서 1 사이에서 균일하게 샘플링하여 무작위로 마스킹한다. 기존 transformer 기반 world model과 같이 시간 $t$에서의 action을 해당 프레임에 연결하는 대신, latent action을 LAM과 dynamics model 모두에 대해 가산 임베딩으로 처리하면 생성의 제어성을 향상시키는 데 도움이 된다.
2. Inference: Action-Controllable Video Generation
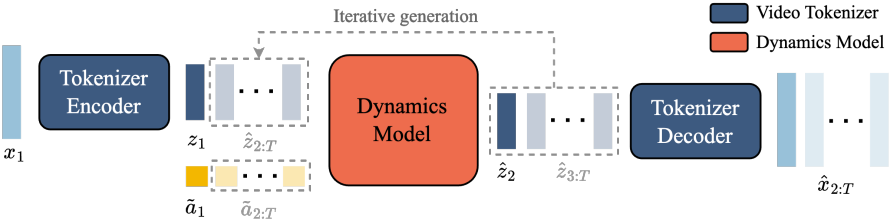
Inference 시에 Genie를 사용하여 action으로 제어한 가능한 동영상을 생성하는 방법은 다음과 같다.
- 플레이어는 먼저 초기 프레임 역할을 하는 이미지 $x_1$을 모델에 입력한다. 이 이미지는 tokenize되어 $z_1$이 된다.
- 플레이어는 $[0, \vert A \vert)$ 내의 정수 값을 선택하여 수행할 latent action $a_1$을 지정한다. $a_1$을 VQ codebook에서 인덱싱하여 latent action \(\tilde{a}_1\)을 얻는다.
- Dynamics model은 $z_1$과 \(\tilde{a}_1\)을 사용하여 다음 프레임 토큰 $z_2$를 예측한다.
이 과정이 autoregressive하게 반복되어 나머지 시퀀스 \(\hat{z}_{2:T}\)가 생성된다. Action은 모델로 계속 전달되고, 토큰은 tokenizer의 디코더를 통해 동영상 프레임 \(\hat{x}_{2:T}\)로 디코딩된다. 모델에 동영상의 시작 프레임과 추론된 action을 전달하여 데이터셋에서 실제 동영상을 재생성하거나, action을 변경하여 완전히 새로운 동영상 또는 궤적을 생성할 수 있다.
Experimental Results
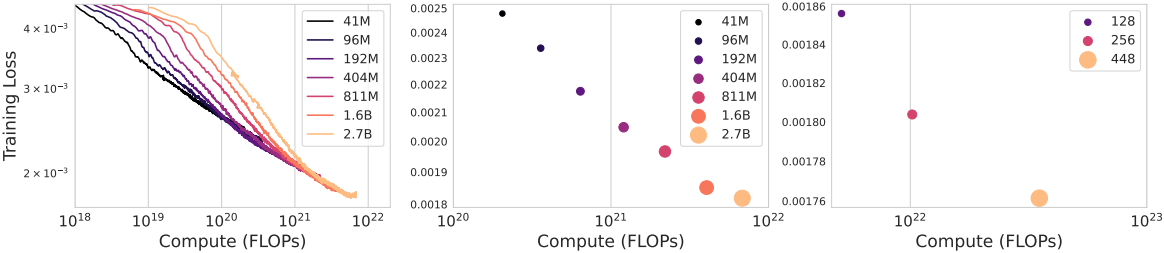
1. Scaling Results
다음은 (왼쪽, 중간) 모델 크기와 (오른쪽) batch size에 대한 scaling 결과이다.
2. Qualitative Results
다음은 이미지 프롬프트를 플레이하는 예시들이다.

다음은 Imagen2로 생성한 이미지에 대한 결과로, 플랫포머 게임의 일반적인 특징인 parallax를 테스트한 것이다. 전경은 가깝고 먼 중간 영역보다 더 많이 움직이는 반면, 배경은 아주 약간만 움직인다.

다음은 세 가지 서로 다른 시작 프레임에서 시작하는 궤적의 예시들이다. 각 열은 동일한 latent action을 5번 수행한 결과 프레임이다. Action 레이블 없이 학습했음에도 불구하고, 동일한 action은 다양한 프롬프트 프레임에서 일관되게 나타나며, 아래, 위, 왼쪽의 의미를 가진다.

다음은 변형 가능한 물체에 대한 시뮬레이션 예시이다.

3. Training Agents
다음은 처음 보는 RL 환경에 대한 플레이 예시이다.

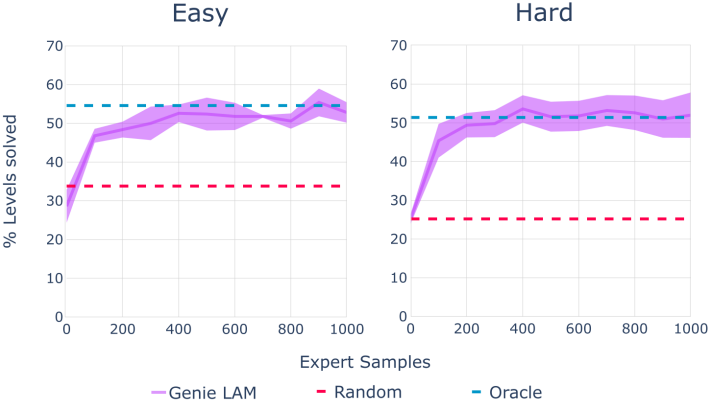
다음은 100개 샘플 중 해결된 레벨의 평균 백분율을 oracle behavioral cloning (BC)과 비교한 결과이다.
4. Ablation Studies
다음은 LAM 입력에 대한 ablation 결과이다.
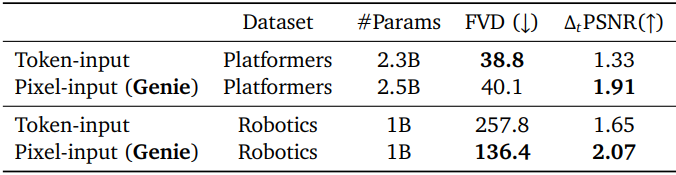
다음은 tokenizer 아키텍처에 대한 ablation 결과이다.
