[논문리뷰] Training language models to follow instructions with human feedback (InstructGPT / RLHF)
arXiv 2023. [Paper]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe
OpenAI
4 Mar 2022
Introduction
대형 언어 모델(LM)은 task의 몇 가지 예를 입력으로 제공하여 다양한 자연어 처리(NLP) task를 수행하도록 “프롬프트”될 수 있다. 그러나 이러한 모델은 사실을 꾸며내거나 편파적이거나 유해한 텍스트를 생성하거나 단순히 사용자 명령을 따르지 않는 것과 같은 의도하지 않은 동작을 표현하는 경우가 많다. 이는 최근 많은 대형 LM에서 사용되는 언어 모델링 목적 함수(다음 토큰 예측)가 “사용자의 지시를 유용하고 안전하게 따르기”라는 목표와 다르기 때문이다. 따라서 저자들은 언어 모델링 목적 함수가 일치하지 않는다고 말한다. 이러한 의도하지 않은 동작을 방지하는 것은 수백 개의 애플리케이션에서 배포 및 사용되는 언어 모델에 특히 중요하다.
본 논문은 사용자의 의도에 따라 작동하도록 언어 모델을 학습시켜 일치시키는 작업을 진행한다. 여기에는 명령을 따르는 것과 같은 명시적 의도와 진실을 유지하고 편향되거나 유해한 것과 같은 암시적 의도가 모두 포함된다. 저자들은 언어 모델이 도움이 되고 (사용자가 문제를 해결하는 데 도움이 되어야 함) 정직하고 (정보를 조작하거나 사용자를 잘못 이끌어서는 안 됨) 무해하기를 (신체적, 심리적 또는 사회적 피해를 유발하지 않아야 함) 원한다.
본 논문은 언어 모델을 일치시키기 위한 fine-tuning 접근 방식에 중점을 둔다. 구체적으로 인간의 피드백을 통한 강화 학습 (RLHF)을 사용하여 GPT-3를 fine-tuning하여 광범위한 종류의 명령을 따르도록 한다. 이 테크닉은 인간의 선호도를 reward로 사용하여 모델을 fine-tuning한다. 저자들은 먼저 40명으로 구성된 팀을 고용하여 스크리닝 테스트의 성과에 따라 데이터에 레이블을 지정한다. 그런 다음 OpenAI API3에 제출된 프롬프트와 일부 레이블러가 작성한 프롬프트에서 원하는 출력 동작에 대한 사람이 작성한 데모 데이터셋을 수집하고 이를 사용하여 지도 학습 baseline을 학습시킨다. 다음으로 더 큰 API 프롬프트 셋에서 모델의 출력 사이에 사람이 레이블을 지정한 비교 데이터셋을 수집한다. 그런 다음 이 데이터셋에서 reward model(RM)을 학습시켜 레이블러가 선호하는 모델 출력을 예측한다. 마지막으로 이 RM을 PPO 알고리즘의 reward function으로 사용하고 지도 학습 baseline을 fine-tuning하여 이 reward를 최대화한다. 이 절차는 GPT-3의 동작을 “human values”라는 더 넓은 개념이 아닌 특정 그룹의 사람들(대부분 레이블러 및 연구원)의 명시된 선호도에 맞춘다. 결과 모델을 InstructGPT라고 한다.
저자들은 주로 레이블러가 테스트셋에서 모델 출력의 품질을 평가하도록 하여 모델을 평가한다. 이 테스트셋은 hold-out 고객(학습 데이터에 없음)의 프롬프트로 구성된다. 또한 다양한 공개 NLP 데이터셋에 대한 자동 평가를 수행한다. 세 가지 모델 크기(1.3B, 6B, 175B)로 학습시키고 모든 모델은 GPT-3 아키텍처를 사용한다. 본 논문의 주요 결과는 다음과 같다.
- 레이블러는 GPT-3의 출력보다 InstructGPT 출력을 상당히 선호한다.
- InstructGPT는 GPT-3보다 향상된 진실성을 보여준다.
- InstructGPT는 GPT-3에 비해 유해성이 약간 개선되었지만 편견은 없다.
- RLHF fine-tuning 절차를 수정하여 공개 NLP 데이터셋의 성능 회귀를 최소화할 수 있다.
- InstructGPT는 학습 데이터를 생성하지 않은 “hold-out” 레이블러의 선호도에 대해 일반화된다.
- 공개 NLP 데이터셋은 언어 모델이 사용되는 방식을 반영하지 않는다.
- InstructGPT는 RLHF fine-tuning 분포 외부의 명령에 대한 유망한 일반화를 보여준다.
- InstructGPT는 여전히 간단한 실수를 범한다.
전반적으로, 본 논문의 결과는 인간의 선호도를 사용하여 대규모 언어 모델을 fine-tuning하면 광범위한 task에서 동작이 크게 개선되지만 안전성과 신뢰성을 개선하기 위해 많은 연구가 남아 있음을 나타낸다.
Methods and experimental details
1. High-level methodology
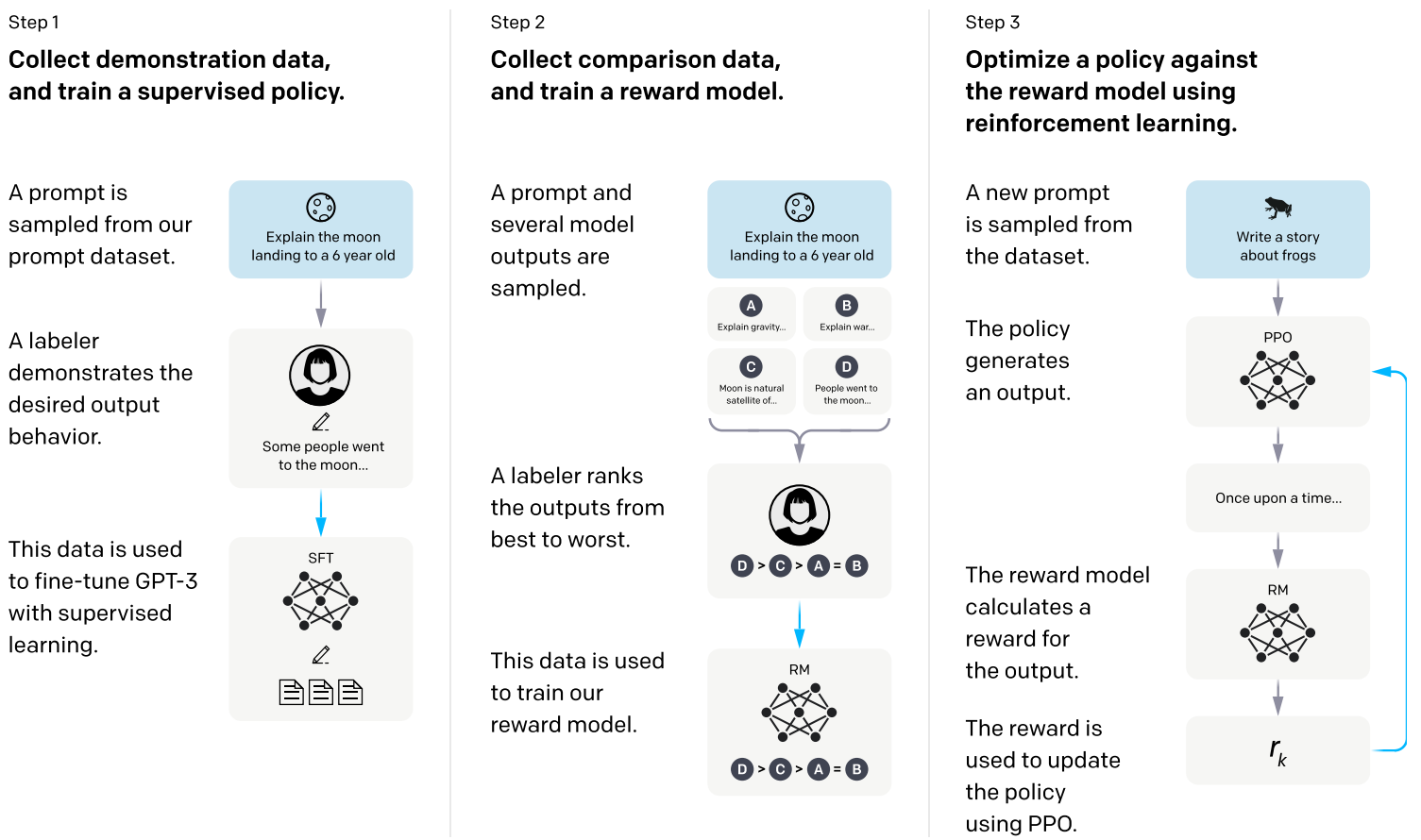
본 논문의 방법론은 Fine-tuning language models from human preferences 논문과 Learning to summarize from human feedback 논문의 방법론을 따른다. 사전 학습된 언어 모델부터 시작하며, 모델이 출력과 학습된 레이블러 팀을 일치시키는 생성을 원한다. 그런 다음 위 그림과 같이 다음 세 단계를 적용한다.
- Step 1: 시연 데이터를 모으고 supervised policy를 학습: 레이블러는 입력 프롬프트 분포에서 원하는 동작의 데모를 제공한다. 그런 다음 지도 학습을 사용하여 이 데이터에서 사전 학습된 GPT-3 모델을 fine-tuning한다.
- Step 2: 비교 데이터를 모으고 reward model을 학습: 주어진 입력에 대해 레이블러가 선호하는 출력을 나타내는 모델 출력들 사이의 비교 데이터셋을 수집한다. 그런 다음 reward model(RM)을 학습시켜 인간이 선호하는 출력을 예측한다.
- Step 3: PPO를 사용하여 reward model에 대한 policy 최적화: RM의 출력을 스칼라 보상으로 사용한다. PPO 알고리즘을 사용하여 이 reward를 최적화하기 위해 supervised policy를 fine-tuning한다.
Step 2와 Step 3는 계속해서 반복할 수 있다. 새로운 RM을 학습시킨 다음 새 policy를 학습시키는 데 사용되는 현재 최상의 policy에 대해 더 많은 비교 데이터가 수집된다. 실제로 대부분의 비교 데이터는 supervised policy에서 가져오며 일부는 PPO policy에서 가져온다.
2. Dataset
프롬프트 데이터셋은 주로 OpenAI API에 제출된 텍스트 프롬프트, 특히 Playground 인터페이스에서 이전 버전의 InstructGPT 모델(데모 데이터의 부분 집합에 대한 지도 학습을 통해 학습됨)을 사용하는 텍스트 프롬프트로 구성된다. Playground를 사용하는 고객은 InstructGPT 모델이 사용될 때마다 반복 알림을 통해 추가 모델을 학습시키는 데 데이터를 사용할 수 있다는 정보를 받았다. 본 논문에서는 프로덕션에서 API를 사용하는 고객의 데이터를 사용하지 않는다. 저자들은 긴 공통 접두사를 공유하는 프롬프트를 확인하여 프롬프트의 중복을 제거하고 프롬프트 수를 사용자 ID당 200개로 제한하였다. 또한 사용자 ID를 기반으로 train, evaluation, test split을 생성하므로 evaluation과 test set에는 데이터가 train set에 있는 사용자의 데이터가 포함되지 않는다. 모델이 잠재적으로 민감한 고객 세부 정보를 학습하지 않도록 하기 위해 개인 식별 정보(PII)에 대한 train split의 모든 프롬프트를 필터링한다.
최초의 InstructGPT 모델을 학습시키기 위해 레이블러에게 프롬프트를 직접 작성하도록 요청했다. 이는 프로세스를 부트스트랩하기 위해 명령과 같은 프롬프트의 초기 소스가 필요했고 이러한 종류의 프롬프트는 API의 일반 GPT-3 모델에 자주 제출되지 않았기 때문이다. 저자들은 레이블러에게 세 가지 유형의 프롬프트를 작성하도록 요청했다.
- Plain: 레이블러에게 task가 충분히 다양성을 갖도록 하면서 임의의 task를 제시하도록 요청
- Few-shot: 레이블러에게 명령과 해당 명령에 대한 여러 쿼리/응답 쌍을 제시하도록 요청
- User-based: 레이블러에게 OpenAI API의 여러 use-case에 해당하는 프롬프트를 제시하도록 요청
이러한 프롬프트에서 fine-tuning 절차에 사용되는 세 가지 데이터셋을 생성한다.
- SFT dataset: SFT model을 학습시키는 데 사용되는 레이블러 시연, 13,000개의 학습 프롬프트 포함, API와 레이블러에게 수집
- RM dataset: RM 학습에 사용되는 모델 출력의 레이블러 순위, 33,000개의 학습 프롬프트 포함, API와 레이블러에게 수집
- PPO dataset: RLHF fine-tuning의 입력으로 사용, 31,000개의 학습 프롬프트 포함, API로만 수집
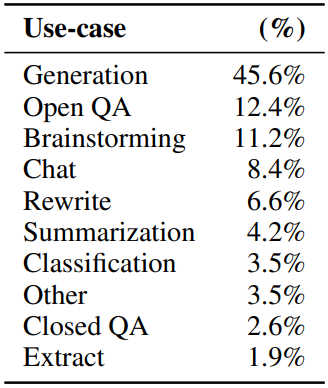
아래 표는 API 프롬프트의 use-case 카테고리의 분포(왼쪽)와 예시 프롬프트(오른쪽)이다.

3. Tasks
학습 task는 2개의 소스에서 나온다.
- 레이블러가 작성한 프롬프트의 데이터셋
- 초기 InstructGPT 모델에 제출된 API의 프롬프트 데이터셋
이러한 프롬프트는 매우 다양하며 생성, 질문 응답, 대화, 요약, 추출 및 기타 자연어 task를 포함한다. 데이터셋은 96%이상이 영어이다.
각 자연어 프롬프트에 대해 task는 자연어 명령(ex. “현명한 개구리에 대한 이야기 쓰기”)을 통해 직접적으로 지정되는 경우가 가장 많지만 몇 가지 예시나 (ex. 개구리 이야기의 두 가지 예시 제공하고 모델이 새 예시를 생성하도록 유도) 암시적 연속 (ex. 개구리에 대한 이야기의 시작 제공)을 통해 간접적으로 지정된다. 각각의 경우에 레이블러에게 프롬프트를 작성한 사용자의 의도를 추론하기 위해 최선을 다하고 task가 매우 불분명한 입력을 건너뛰도록 요청한다. 또한 레이블러는 응답의 진실성과 같은 암시적 의도와 편향되거나 유해한 언어와 같은 잠재적으로 유해한 결과를 고려하여 제공하는 명령과 최선의 판단에 따라 안내한다.
4. Human data collection
저자들은 데모 및 비교 데이터를 생성하고 주요 평가를 수행하기 위해 Upwork와 ScaleAI를 통해 약 40명으로 구성된 팀을 고용했다. 요약 task에 대한 인간의 선호도 데이터를 수집하는 이전 연구들과 비교할 때 본 논문의 입력은 훨씬 더 광범위한 task에 걸쳐 있으며 때때로 논란의 여지가 있고 민감한 주제를 포함할 수 있다. 저자들의 목표는 다양한 선호도에 민감하고 잠재적으로 유해한 출력을 식별하는 데 능숙한 레이블러 그룹을 선택하는 것이었다. 따라서 이러한 축에 대한 레이블러 성능을 측정하도록 설계된 스크리닝 테스트를 수행했으며, 이 테스트에서 좋은 성적을 거둔 레이블러를 선택했다.
학습과 평가 중에 기준이 충돌할 수 있다. 예를 들어 사용자가 잠재적으로 유해한 응답을 요청하는 경우가 있다. 학습하는 동안 사용자에 대한 도움을 우선시한다. 그러나 최종 평가에서 레이블러에게 진실성과 무해성을 우선시하도록 요청했다 (이것이 저자들이 진정으로 관심을 갖는 것이므로).
5. Models
사전 학습된 GPT-3 언어 모델에서 시작한다. GPT-3는 인터넷 데이터의 광범위한 분포에 대해 학습되었고 광범위한 downstream task에 적응할 수 있지만 특성화되지 않은 동작이 있다. GPT-3에서 시작하여 세 가지 테크닉으로 모델을 학습시킨다.
Supervised fine-tuning (SFT)
Supervised learning을 사용하여 레이블러 시연으로 GPT-3를 fine-tuning한다. Cosine learning rate decay와 residual dropout 0.2를 사용하여 16 epoch 동안 학습시켰다. Validation set의 RM 점수를 기반으로 최종 SFT 모델 선택을 수행한다. 저자들은 SFT 모델이 1 epoch 이후 validation loss에 대해 overfit되었음을 발견했다. 그러나 이러한 과적합에도 불구하고 더 많은 epoch에 대한 학습이 RM 점수와 인간 선호도 등급 모두에 도움이 된다는 것을 발견했다.
Reward modeling (RM)
최종 unembedding layer가 제거된 SFT 모델에서 시작하여 프롬프트와 응답을 받아 스칼라 reward를 출력하도록 모델을 학습시켰다. 본 논문에서는 많은 컴퓨팅을 절약하기 위해 6B RM만 사용하는데, 저자들은 175B RM 학습이 불안정할 수 있으므로 강화학습 동안 value function으로 사용하기에 적합하지 않음을 발견했다.
Learning to summarize from human feedback 논문을 따라 RM은 동일한 입력에 대한 두 모델 출력들 사이의 비교 데이터셋에 대해 학습된다. 비교를 레이블로 사용하여 cross-entropy loss를 사용한다. Reward의 차이는 인간 레이블러가 한 응답을 다른 응답보다 선호할 로그 확률을 나타낸다.
비교 수집 속도를 높이기 위해 순위에 대한 응답이 $K = 4$에서 $K = 9$ 사이인 레이블러를 제시한다. 이렇게 하면 레이블러에게 표시되는 각 프롬프트에 대해 $\binom{K}{2}$개의 비교가 생성된다. 비교는 각 레이블 지정 작업 내에서 매우 상관 관계가 있으므로 비교를 하나의 데이터셋으로 단순히 섞으면 데이터셋을 한 번 통과하면 RM이 overfit된다. 대신 각 프롬프트에서 모든 $\binom{K}{2}$개의 비교를 하나의 batch로서 학습한다. 이는 RM의 단일 forward pass만 필요하기 때문에 훨씬 더 계산 효율적이며 더 이상 overfit되지 않기 때문에 훨씬 향상된 validation 정확도와 log loss를 달성한다.
구체적으로 RM의 loss function은 다음과 같다.
\[\begin{equation} \textrm{loss} (\theta) = - \frac{1}{\binom{K}{2}} \mathbb{E}_{(x, y_w, y_l) \sim D} [\log (\sigma (r_\theta (x, y_w) - r_\theta (x, y_t)))] \end{equation}\]여기서 $r_\theta (x, y)$는 프롬프트 $x$와 응답 $y$에 대한 RM의 스칼라 출력이고 $y_w$는 $y_w$와 $y_l$ 쌍 중에 더 선호되는 응답이다. $D$는 인간 비교의 데이터셋이다.
마지막으로, RM loss는 reward의 shift에 불변하기 때문에 레이블러 시연이 RL을 수행하기 전에 평균 점수가 0이 되도록 bias를 사용하여 reward model을 정규화한다.
Reinforcement learning (RL)
다시 한번 Learning to summarize from human feedback 논문을 따라 PPO를 사용하여 환경에서 SFT 모델을 fine-tuning한다. 환경은 임의의 고객 프롬프트를 제시하고 프롬프트에 대한 응답을 기대하는 bandit environment이다. 프롬프트와 응답이 주어지면 RM에 따라 결정된 reward를 생성하고 에피소드를 종료한다. 또한 RM의 과도한 최적화를 완화하기 위해 각 토큰에서 SFT 모델에 토큰당 KL penalty를 추가한다. Value function은 RM에서 초기화된다. 이러한 모델을 “PPO”라고 부른다.
또한 저자들은 공개 NLP 데이터셋의 성능 회귀를 수정하기 위해 사전 학습 기울기를 PPO 기울기에 혼합하여 실험하였다. 이러한 모델을 “PPO-ptx”라고 부른다. RL 학습에서 다음과 같은 결합된 목적 함수를 최대화한다.
\[\begin{aligned} \textrm{objective} (\phi) &= \mathbb{E}_{(x, y) \sim D_{\pi_\phi^\textrm{RL}}} \bigg[ r_\theta (x, y) - \beta \log \frac{\pi_\phi^\textrm{RL} (y \vert x)}{\pi^\textrm{SFT} (y \vert x)} \bigg] \\ &+ \gamma \mathbb{E}_{x \sim D_\textrm{pretrain}} [\log (\pi_\phi^\textrm{RL} (x))] \end{aligned}\]여기서 $\pi_\phi^\textrm{RL}$는 학습된 RL policy, $\pi^\textrm{SFT}$는 지도 학습된 모델, $D_\textrm{pretrain}$은 사전 학습 분포이다. KL reward 계수 $\beta$와 pretraining loss 계수 $\gamma$는 KL penalty와 사전 학습 기울기의 강도를 각각 조절한다. “PPO” model의 경우 $\gamma = 0$으로 설정된다. 달리 명시되지 않는 한 본 논문에서 InstructGPT는 “PPO-ptx” 모델이다.
Results
1. Results on the API distribution
다음은 API 프롬프트 분포에서 다양한 모델에 대한 인간 평가 결과로, 175B SFT model와 비교할 때 얼마나 선호되는 지를 측정한 것이다.
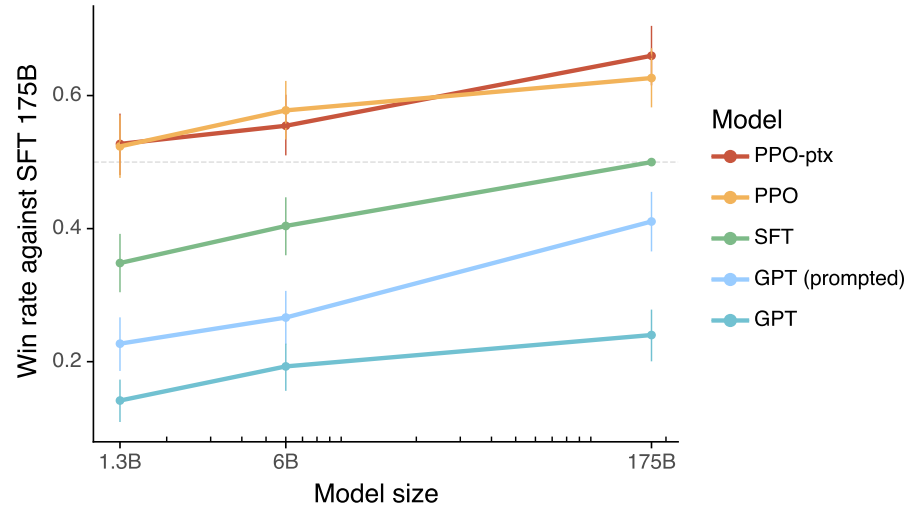
다음은 175B SFT model과 비교하여 측정한 선호도이다. 왼쪽은 GPT-3에 프롬프트를 제출했을 때의 결과이고 오른쪽은 InstructGPT에 프롬프트를 제출했을 때의 결과이다. 위는 hold-out 레이블러의 결과이고 아래는 training 레이블러의 결과이다. 프롬프트가 이미 GPT-3에서 잘 수행하도록 디자인되어 있기 때문에 GPT-3에 프롬프트를 제출했을 때의 평가에서 GPT (prompted)를 생략한다.

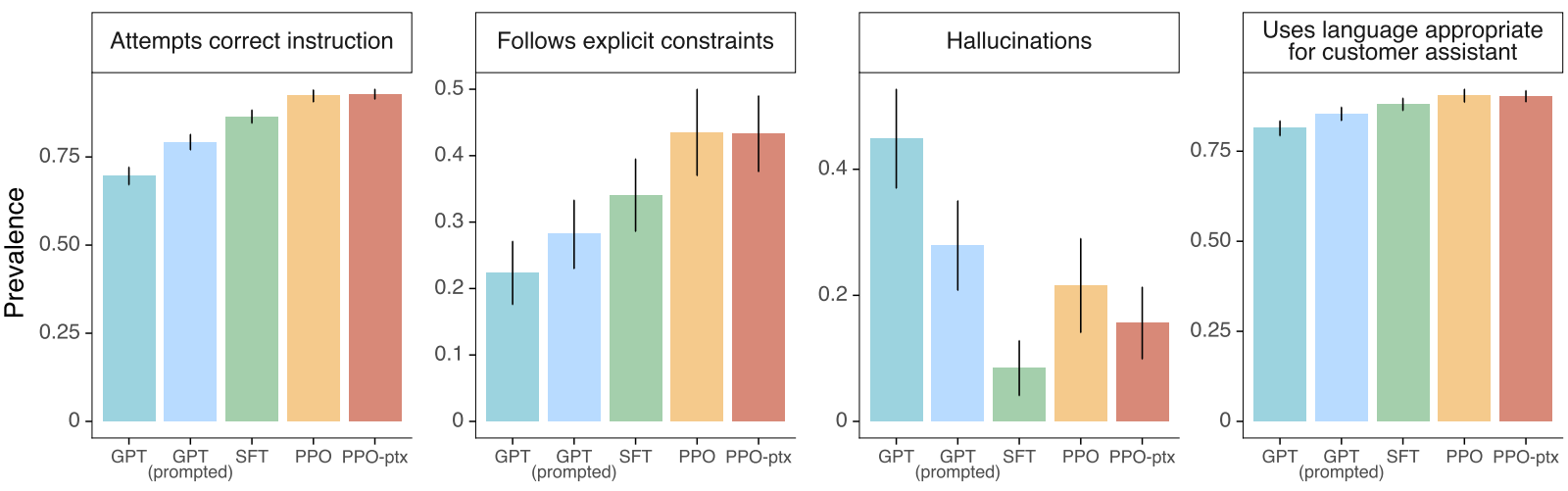
다음은 다양한 기준으로 본 논문의 모델들을 평가한 그래프이다.
다음은 본 논문의 모델들과 FLAN, T0를 1-7 scale Likert 점수로 비교한 그래프이다.
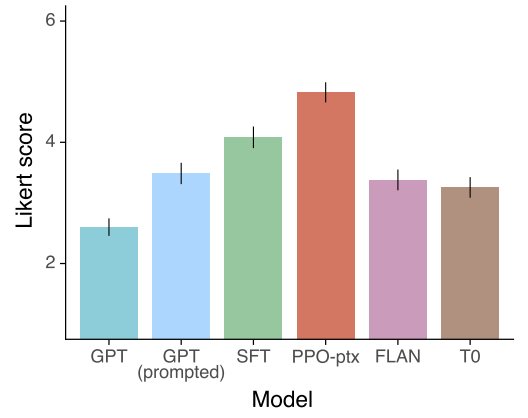
저자들은 InstructGPT가 두 가지 이유로 FLAN과 T0보다 성능이 우수하다고 생각한다.
- 공개 NLP 데이터셋은 분류, 질문 답변, 요약, 번역과 같은 자동 메트릭으로 쉽게 평가할 수 있는 task를 캡처하도록 설계되었다. 그러나 분류와 QA는 API 고객이 본 논문의 언어 모델을 사용하는 것의 작은 부분(약 18%)에 불과한 반면 개방형 생성과 브레인스토밍은 프롬프트 데이터셋의 약 57%로 구성된다.
- 공개 NLP 데이터셋이 매우 다양한 입력을 얻는 것이 어려울 수 있다. 물론 NLP 데이터셋에서 발견되는 task는 언어 모델이 해결할 수 있기를 바라는 일종의 지침을 나타내므로 가장 광범위한 유형의 지침을 따르는 모델은 두 유형의 데이터셋을 결합한다.
2. Results on public NLP datasets
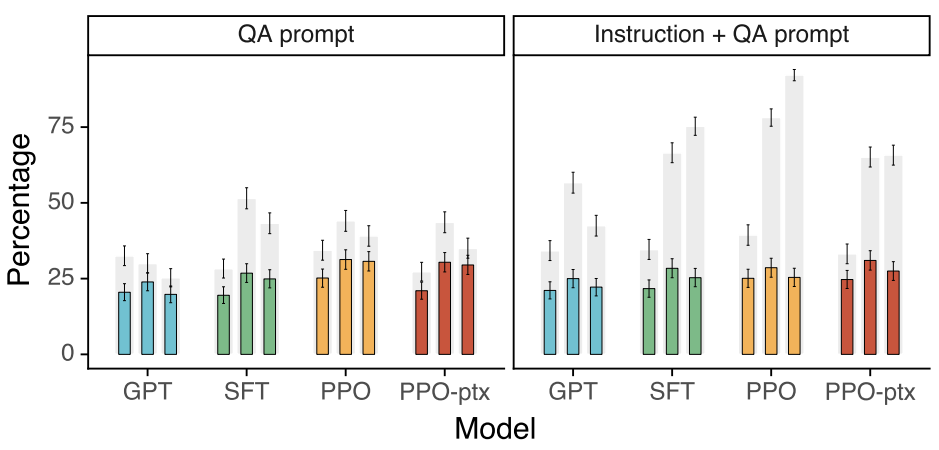
다음은 TruthfulQA dataset의 결과이다. 회색 막대는 신뢰도 등급을 나타내며, 색깔 막대는 신뢰도+정보성 등급을 나타낸다.
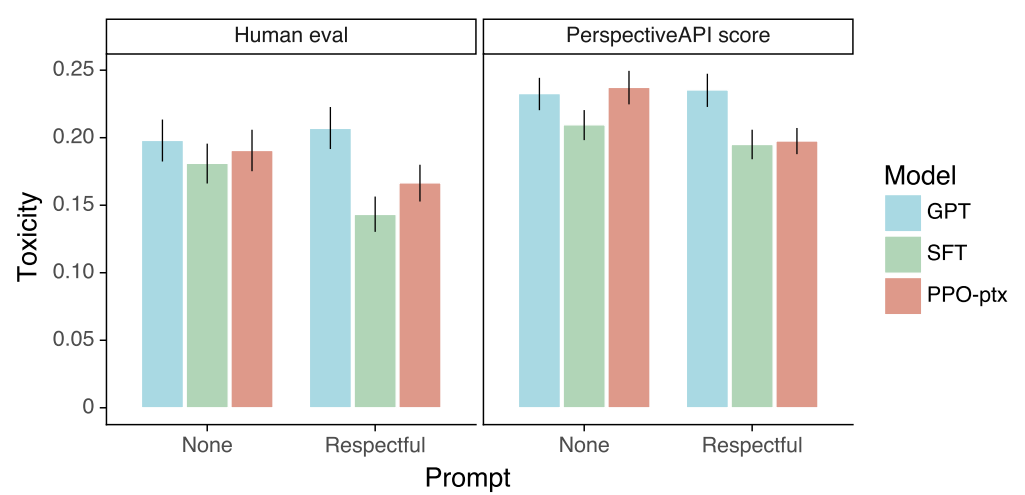
다음은 RealToxicityPrompts에서의 인간 평가와 자동 평가 결과이다.
3. Qualitative Results
다음은 InstructGPT 175B를 GPT-3 175B와 비교한 일반화의 예시이다.

InstructGPT는 때때로 영어로 출력을 생성하지만 다른 언어로 된 명령을 따를 수 있다. GPT-3는 영어와 유사하게 더 신중한 프롬프트가 필요하다. InstructGPT는 GPT-3보다 안정적으로 코드에 대한 질문을 요약하고 답변할 수 있다.
다음은 InstructGPT 175B를 GPT-3 175B와 비교한 간단한 실수의 예시이다. 프롬프트는 특정 동작을 보이기 위해 cherry-picking하였지만 출력은 cherry-picking하지 않았다고 한다.

InstructGPT는 잘못된 전제를 가정하고 그대로 따라가는 명령으로 인해 혼동될 수 있다. InstructGPT는 간단한 질문에 직접 답하기보다 지나치게 hedge할 수 있다.