[논문리뷰] In-Domain GAN Inversion for Real Image Editing
ECCV 2020. [Paper] [Project] [Github]
Jiapeng Zhu, Yujun Shen, Deli Zhao, Bolei Zhou
The Chinese University of Hong Kong
31 Mar 2020
Introduction
최근에 나온 GAN 모델들은 latent space 내부의 풍부한 semantics를 인코딩하는 방법을 학습하고 latent code를 변경하면 출력 이미지의 해당 속성의 조작이 가능하다. 하지만, GAN은 특정 이미지를 입력으로 받아 해당 이미지의 latent code를 추출하는 기능이 없기 때문에 latent code을 변경하여 출력 이미지를 조작하는 것이 실제 이미지에 적용하기 어렵다. 그래서 GAN의 생성 과정과는 정반대로 이미지 space에서 latent space로 역으로 매핑하는 GAN inversion이라 불리는 많은 시도가 있었다. GAN에 붙는 추가 encoder를 학습시키거나 직접 개별 이미지의 latent code를 찾는 시도들이 있었다. 하지만, 이런 방법들은 GAN의 output이 입력 이미지로 잘 복원되는지 픽셀 level에서만 초점이 맞춰있으며, 다음과 같은 다양한 질문을 할 수 있다.
- Inverted code가 원래 GAN의 latent space에 적합한지
- Inverted code가 target 이미지를 의미론적으로 잘 표현하는지
- Inverted code가 GAN에서 학습한 지식을 재사용하여 이미지 편집을 지원하는지
- 잘 학습된 GAN을 사용하여 임의의 이미지의 inverted code를 찾을 수 있는지
위의 질문들에 답할 수 있으면 GAN의 내부 메커니즘에 대한 이해가 깊어질 뿐만 아니라 다양한 이미지 편집을 위해 pre-trained GAN 모델을 활용할 수 있다.
이 논문에서는 좋은 GAN inversion 방법이 target 이미지를 복원할 뿐만 아니라 inverted code를 latent space에 인코딩된 semantic knowledge에 맞춰야함을 보여준다. 이러한 의미론적으로 유의미한 code는 GAN이 학습한 semantic domain에 종속되기 때문에 in-domain code라고 한다. 저자들은 in-domain code가 기존 GAN 모델의 풍부한 지식을 재사용하여 이미지 편집을 더 잘할 수 있음을 발견하였으며, 이를 위해 픽셀 level과 semantic level 모두에서 입력 이미지를 복구하는 in-domain GAN inversion을 제안하였다.
전체 학습 과정은 2단계로 되어 있다.
- 인코더에 의해 생성된 모든 code가 in-domain하기 위하여 image space를 latent space에 매핑하도록 domain-guided encoder를 먼저 학습시킨다.
- 그런 다음 inverted code의 semantic 속성이 달라지지 않고 픽셀 값을 더 잘 재구성하기 위해 인코더를 regularizer로 하여 instance-level domain-regularized optimization을 수행한다.
In-Domain GAN Inversion
GAN 모델을 반전시킬 때 입력 이미지를 픽셀 값으로 복원시키는 것 외에도 inverted code가 의미론적으로(semantically) 유의미한지도 고려해야 한다. 여기서 ‘semantic’은 GAN이 데이터로부터 학습한 지식이다. 이를 위해 domain-guided 인코더를 먼저 학습시킨 뒤 이 인코더를 domain-reularized optimization을 위한 regularizer로 사용한다.
기존 GAN 모델은 정규 분포 $\mathcal{Z}$에서 latent code $z$를 뽑아 generator에 넣었다면, StyleGAN 모델은 정규 분포 $\mathcal{Z}$와 latent space $\mathcal{W}$를 MLP로 매핑한 뒤 $\mathcal{W}$에서 뽑은 $w$를 generator에 넣어준다. 이러한 매핑은 disentangle한 semantics를 더 학습할 수 있어 일반적으로 disentangled space $\mathcal{W}$를 GAN inversion에 사용한다. 이 논문에서는 3가지 이유로 $\mathcal{W}$를 inversion space로 선택하였다.
- Inverted code의 semantic 속성에 대해 초점을 맞추고 있으므로 $\mathcal{W}$ space가 분석에 적합하다.
- $\mathcal{W}$ space로 반전시키는 것이 $\mathcal{Z}$ space보다 더 좋은 성능을 보인다.
- 어떤 GAN model이라도 MLP만 앞에 붙이면 $\mathcal{W}$ space를 사용할 수 있다.
1. Domain-Guided Encoder
인코더를 학습시키는 것은 Inference 속도가 빠르기 때문에 GAN inversion 문제를 풀 때 많이 사용한다. 하지만, 기존의 방법들은 인코더에서 생성된 코드가 GAN이 학습한 semantic knowledge과 일치하는 지 여부에 관계없이 단순히 결정론적 모델을 학습시킨다.
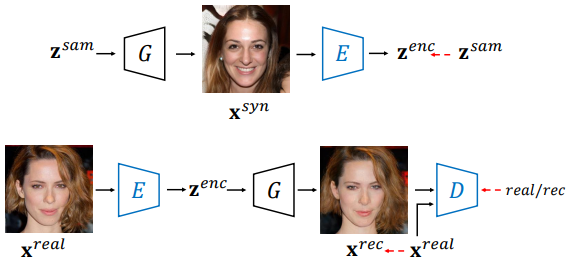
위 그림에서 위가 기존의 인코더의 학습 방법이며, 아래가 domain-guided encoder의 학습 방법이다. 파란색으로 표시된 모델 블록이 학습되는 블록이다.
기존의 방법들은 $z^{sam}$을 뽑아 generator에 넣어서 $x^{syn}$을 합성한 뒤, 다시 인코더에 넣어서 나온 $z^{enc}$가 ground truth $z^{sam}$에 가까워지도록 학습한다.
\[\begin{equation} \min_{\Theta_E} \mathcal{L}_E = \| z^{sam} - E(G(z^{sam})) \|_2 \end{equation}\]($\Theta_E$는 인코더의 파라미터, $|| \cdot ||_2$는 $l_2$ distance)
$z^{sam}$을 복원하는 것만으로는 정확한 인코더로 학습시키는데에 부족하다. 또한 generator의 기울기가 전혀 고려되지 않기 때문에 domain 지식을 제공할 수 없다. 이러한 문제를 해결하기 위해서는 domain-guided 인코더를 학습시켜야 한다. Domain-guided 인코더는 기존의 인코더와 3가지 차이점이 있다.
- 인코더의 output이 generator에 입력되어 이미지가 재구성되기 때문에 objective function이 latent space 대신 image space에서 나온다. 이는 generator가 학습한 semantic knowledge가 학습에 포함되며 보다 유익하고 정확한 supervision이 주어진다. 따라서 output code가 generator의 semantic domain에 포함되는 것을 보장된다.
- Domain-guided encoder는 generator로 합성한 이미지가 아닌 실제 이미지로 학습되므로 실제 application에 더 적합하다.
- 재구성된 이미지가 충분히 사실적인지 확인하기 위해 discriminator가 인코더와 경쟁하도록 한다.
이러한 방식으로 GAN 모델에서 가능한 많은 정보를 얻을 수 있다. 적대적 학습 방식은 generator의 semantic knowledge에 더 잘 맞도록 output code를 내놓는다.
저자들은 VGG로 feature를 추출하여 perceptual loss에 사용하였다. 학습 방식은 다음 식으로 표현할 수 있다.
\[\begin{aligned} \min_{\Theta_E} \mathcal{L}_E &= \| x^{real} - G(E(x^{real})) \|_2 + \lambda_{vgg} \| F(x^{real}) - F(G(E(x^{real}))) \|_2 - \lambda_{adv} \underset{x^{real} \sim P_{data}}{\mathbb{E}} [D(G(E(x^{real})))] \\ \min_{\Theta_D} \mathcal{L}_D &= \underset{x^{real} \sim P_{data}}{\mathbb{E}} [D(G(E(x^{real})))] - \underset{x^{real} \sim P_{data}}{\mathbb{E}} [D(x^{real})] + \frac{\gamma}{2} \underset{x^{real} \sim P_{data}}{\mathbb{E}} [\| \nabla_x D (x^{real}) \|_2^2 ] \end{aligned}\]($P_{data}$는 실제 데이터 분포, $\gamma$는 gradient regularization을 위한 hyper-parameter, $\lambda_{vgg}$와 $\lambda_{adv}$는 perceptual loss와 discriminator loss에 대한 가중치, $F$는 VGG feature 추출 모델)
Domain-Regularized Optimization
Latent 분포에서 실제 이미지 분포로의 매핑을 학습하는 GAN의 생성 프로세스와 달리 GAN inversion은 주어진 개별 이미지를 가장 잘 구성하는 instance-level task에 가깝다. 이러한 관점에서 인코더만으로는 표현 능력이 제한되어 완벽한 reverse 매핑을 학습하기 어렵다. 따라서 domain-guided encoder의 inverted code가 pre-trained generator를 기반으로 입력 이미지를 잘 재구성하고 의미론적으로 유의미한 code임을 보장할 수 있지만 여전히 code를 개별 target 이미지에 더 잘 맞도록 수정해야 한다.
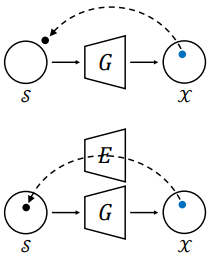
기존의 방법들은 gradient descent로 code를 최적화하였다. 위 그림에서 위의 경우는 latent code가 generator에만 기반하여 자유롭게 최적화되는 프로세스이다. Latent code에 대한 제약이 전혀 없기 때문에 domain 밖으로 inverted code를 생성할 가능성이 매우 높다. Domain-guided encoder를 사용하여 설계된 domain-regularized optimization의 2가지 개선 사항은 다음과 같다.
- Domain-guided encoder의 output을 이상적인 시작점으로 사용하여 latent code가 극소점에서 멈추는 것을 방지하고 최적화 프로세스를 크게 단축한다.
- Generator의 semantic domain 내에서 latent code를 보존하기 위해 regularizer로 domain-guided encoder를 포함한다.
최적화를 위한 objective function은 다음과 같다.
\[\begin{equation} z^{inv} = \underset{z}{\arg \min} \| x - G(z) \|_2 + \lambda_{vgg} \| F(x) - F(G(z)) \|_2 + \lambda_{dom} \| z - E(G(z)) \|_2 \end{equation}\]($x$는 반전시킬 target 이미지, $\lambda_{vgg}$와 $\lambda_{dom}$는 perceptual loss와 encoder regularizer에 대한 가중치)
Experiments
- Dataset: FFHQ (이미지 70,000개), LSUN (10개의 scene 종류)
- Generator: StyleGAN (고정하여 사용)
- Perceptual loss는 VGG의 conv4_3 사용
- Loss weight: $\lambda_{vgg} = 5\times 10^{-5}$, $\lambda_{adv} = 0.1$, $\gamma = 10$, $\lambda_{dom} = 2$
1. Semantic Analysis of the Inverted Codes
7,000개의 실제 얼굴 이미지를 속성 분류기로 나이(young vs. old), 성별, 안경 유무, 포즈(왼쪽, 오른쪽)을 예측하여 ground truth로 사용하였다. 그런 다음 state-of-the-art GAN inversion 모델인 Image2StyleGAN과 저자들이 제안한 in-domain GAN inversion 모델로 이미지들을 latent space로 invert했다. InterFaceGAN은 속성들의 의미론적 경계를 찾는 데 사용하였으며, 이 경계들과 inverted code를 사용하여 속성 분류 성능을 평가하였다.
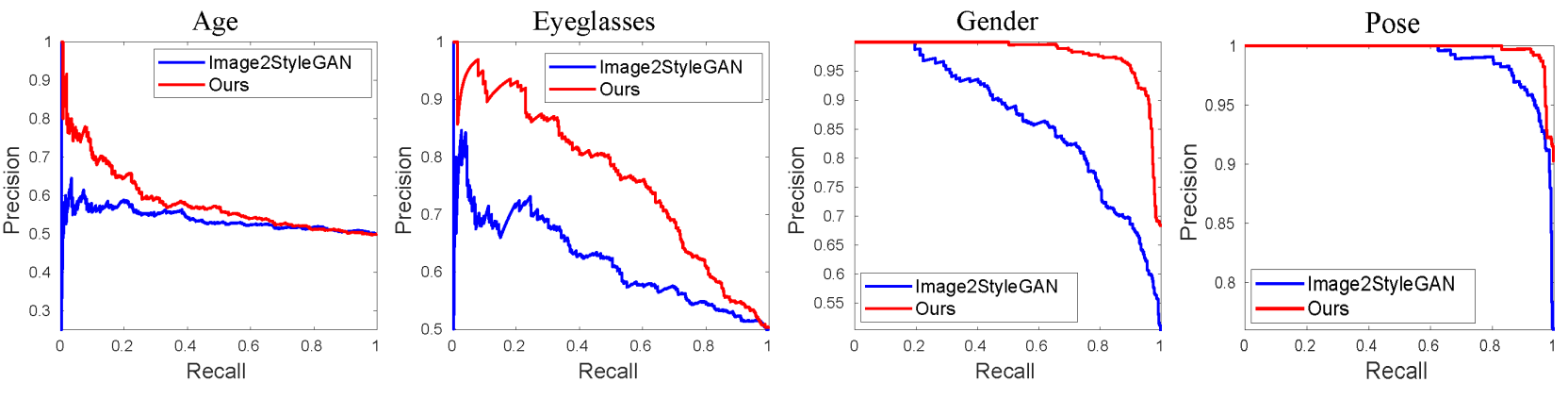
위 그래프는 각 semantic에 대한 precision-recall curve이다. 그래프에서 볼 수 있듯 in-domain GAN inversion 모델의 inverted code가 의미론적으로 유의미하다는 것을 알 수 있다. 이는 inverted code의 의미론적 속성의 보존을 위한 in-domain inversion의 효과를 정량적으로 입증한다.
2. Inversion Quality and Speed


3. Real Image Editing - Image Interpolation


4. Real Image Editing - Semantic Manipulation
특정 semantic에 대한 latent space에서의 normal direction을 $n$, manipulation 정도를 $\alpha$라 하면 다음과 같이 선형 변환으로 semantic manipulation이 가능하다.
\[\begin{equation} x^{edit} = G(z^{inv} + \alpha n) \end{equation}\]

각 그림의 윗줄이 Image2StyleGAN의 결과이고 아랫줄이 in-domain inversion의 결과이다.
다음은 target 이미지에 context 이미지의 semantic을 넣은 결과이다.

Ablation study

위 그림은 $\lambda_{dom}$의 값에 따른 결과이다. 맨 윗줄이 원본 이미지, 두번째 줄이 복원한 이미지, 맨 아랫줄이 manipulation을 한 이미지이다. $\lambda_{dom}$이 클수록 복원이 잘 안되지만 manipulation이 잘 된다.